
Managed Service for Apache Spark Granular IAM ist eine Funktion, mit der Sie Berechtigungen auf der Ebene von Clustern, Jobs, Vorgängen, Workflowvorlagen oder Autoscaling-Richtlinien gewähren können.
Beispiel: Sie können einem Nutzer eine Cluster-Betrachterrolle erteilen, die es ihm ermöglicht, einen Cluster innerhalb eines Projekts aufzurufen. Einem anderen Nutzer können Sie eine Job-Bearbeiterrolle zuweisen, mit der dieser Nutzer den Job aktualisieren, abbrechen und aufrufen kann. Informationen zu den spezifischen Google Cloud CLI-Befehlen, die durch jede Managed Service for Apache Spark Granular IAM-Rolle aktiviert werden, finden Sie unter Durch Granular IAM aktivierte SDK-Befehle.
Managed Service for Apache Spark Granular IAM-Rollen und -Berechtigungen
Mit Managed Service for Apache Spark Granular IAM können die folgenden Rollen mit den folgenden Berechtigungen für Managed Service for Apache Spark-Ressourcen festgelegt werden.
Clusterrollen
| Rolle | Berechtigungen |
|---|---|
| Betrachter | dataproc.clusters.get |
| Editor | dataproc.clusters.get dataproc.clusters.list dataproc.clusters.delete dataproc.clusters.update dataproc.clusters.use dataproc.clusters.start dataproc.clusters.stop |
| Inhaber | dataproc.clusters.get dataproc.clusters.list dataproc.clusters.delete dataproc.clusters.update dataproc.clusters.use dataproc.clusters.start dataproc.clusters.stop dataproc.clusters.setIamPolicy dataproc.clusters.getIamPolicy |
Jobrollen
| Rolle | Berechtigungen |
|---|---|
| Betrachter | dataproc.jobs.get |
| Editor | dataproc.jobs.get dataproc.jobs.cancel dataproc.jobs.delete dataproc.jobs.update |
| Inhaber | dataproc.jobs.get dataproc.jobs.cancel dataproc.jobs.delete dataproc.jobs.update dataproc.jobs.setIamPolicy dataproc.jobs.getIamPolicy |
Vorgangsrollen
| Rolle | Berechtigungen |
|---|---|
| Betrachter | dataproc.operations.get |
| Editor | dataproc.jobs.get dataproc.operations.cancel dataproc.operations.delete |
| Inhaber | dataproc.jobs.get dataproc.operations.cancel dataproc.operations.delete dataproc.operations.setIamPolicy dataproc.operations.getIamPolicy |
Rollen für Workflowvorlagen
| Rolle | Berechtigungen |
|---|---|
| Betrachter | dataproc.workflowTemplates.get |
| Editor | dataproc.workflowTemplates.get dataproc.workflowTemplates.delete dataproc.workflowTemplates.update |
| Inhaber | dataproc.workflowTemplates.get dataproc.workflowTemplates.delete dataproc.workflowTemplates.update dataproc.workflowTemplates.setIamPolicy dataproc.workflowTemplates.getIamPolicy |
Rollen für Autoscaling-Richtlinien
| Rolle | Berechtigungen |
|---|---|
| Betrachter | dataproc.autoscalingPolicies.get |
| Editor | dataproc.autoscalingPolicies.get dataproc.autoscalingPolicies.use dataproc.autoscalingPolicies.delete dataproc.autoscalingPolicies.update |
| Inhaber | dataproc.autoscalingPolicies.get dataproc.autoscalingPolicies.use dataproc.autoscalingPolicies.delete dataproc.autoscalingPolicies.update dataproc.autoscalingPolicies.setIamPolicy dataproc.autoscalingPolicies.getIamPolicy |
Managed Service for Apache Spark Granular IAM verwenden
In diesem Abschnitt wird erläutert, wie Sie Nutzern Rollen für eine vorhandene Managed Service for Apache Spark-Ressource mithilfe von Managed Service for Apache Spark Granular IAM zuweisen. Weitere Informationen zum Aktualisieren und Entfernen von IAM-Rollen (Identity and Access Management) finden Sie unter Zugriff auf Projekte, Ordner und Organisationen verwalten.
gcloud-Befehl
- Rufen Sie die IAM
Richtlinie der Ressource ab
und schreiben Sie sie in eine JSON-Datei. Dabei kann resource-type „clusters“, „jobs“, „operations“, „workflow-templates“ oder „autoscaling-policies“ sein:
gcloud dataproc resource-type get-iam-policy resource-id \ --region=region \ --format=json > iam.json
- Der Inhalt der JSON-Datei sieht in etwa so aus:
{ "bindings": [ { "role": "roles/editor", "members": [ "user:mike@example.com", "group:admins@example.com", "domain:google.com", "serviceAccount:my-other-app@appspot.gserviceaccount.com" ] } ], "etag": "string" } - Fügen Sie mithilfe eines Texteditors ein neues
Binding-Objekt
in das Array „bindings“ ein, das die Nutzer und die Ressourcenzugriffs
rolle für diese Nutzer definiert. Um beispielsweise dem Nutzer
sean@example.comdie Rolle „Betrachter“ (roles/viewer) zuzuweisen, würden Sie das vorherige Beispiel ändern, um ein neues Binding-Objekt hinzuzufügen (im folgenden Beispiel fett dargestellt). Hinweis: Achten Sie darauf, dass Sie denetagWert zurückgeben, den Sie vongcloud dataproc resource-type get-iam-policyerhalten haben. Weitere Informationen finden Sie in der etag-Dokumentation.{ "bindings": [ { "role": "roles/editor", "members": [ "user:mike@example.com", "group:admins@example.com", "domain:google.com", "serviceAccount:my-other-app@appspot.gserviceaccount.com" ] }, { "role": "roles/viewer", "members": [ "user:sean@example.com" ] } ], "etag": "value-from-get-iam-policy" } - Aktualisieren Sie die Richtlinie des Clusters mit dem neuen Bindings-Array. Führen Sie dazu den
folgenden Befehl aus. (resource-type kann dabei „clusters“, „jobs“, „operations“, „workflow-templates“ oder „autoscaling-policies“ sein):
gcloud dataproc resource-type set-iam-policy resource-name \ --region=region \ --format=json iam.json
- Der Befehl gibt die aktualisierte Richtlinie aus:
{ "bindings": [ { "role": "roles/editor", "members": [ "user:mike@example.com", "group:admins@example.com", "domain:google.com", "serviceAccount:my-other-app@appspot.gserviceaccount.com" ] }, { "role": "roles/viewer", "members": [ "user:sean@example.com" ] } ], "etag": "string" }
REST API
- Senden Sie eine resource-type ("clusters" or "jobs" or "operations" or "workflowTemplates" or "autoscalingPolicies") getIamPolicy-Anfrage, um die IAM
Richtlinie
für die Ressource abzurufen.
Beispiel für eine getIamPolicy-Anfrage auf Clusterebene:
GET https://dataproc.googleapis.com/v1/projects/projectName/regions/region/clusters/clusterName:getIamPolicy
- Der Inhalt der JSON-Datei sieht in etwa so aus:
{ "bindings": [ { "role": "roles/editor", "members": [ "user:mike@example.com", "group:admins@example.com", "domain:google.com", "serviceAccount:my-other-app@appspot.gserviceaccount.com" ] } ], "etag": "string" } - Erstellen Sie mithilfe eines Texteditors das folgende JSON
Richtlinien
objekt, um das Bindings-Array einzuschließen, das Sie gerade vom Managed Service for Apache Spark
Dienst erhalten haben. Achten Sie darauf, dass Sie den "etag"-Wert zurückgeben, den Sie in der getIamPolicy
Antwort erhalten haben (weitere Informationen finden Sie in der
etag-Dokumentation).
Fügen Sie jetzt ein neues Binding-Objekt in das Array "bindings" ein, durch das die Nutzer und die Cluster-Zugriffsrolle für diese Nutzer festgelegt werden. Um beispielsweise dem Nutzer
sean@example.comdie Rolle „Betrachter“ (roles/viewer) zuzuweisen, würden Sie das obige Beispiel ändern, um ein neues Binding-Objekt hinzuzufügen (unten fett dargestellt).{ "policy": { "version": "", "bindings": [ { "role": "roles/editor", "members": [ "user:mike@example.com", "group:admins@example.com", "domain:google.com", "serviceAccount:my-other-app@appspot.gserviceaccount.com" ] }, { "role": "roles/viewer", "members": [ "user:sean@example.com" ] } ], "etag": "value-from-getIamPolicy" } } - Legen Sie die aktualisierte Richtlinie für die Ressource fest, indem Sie eine
setIamPolicy-Anfrage ausgeben.POST https://dataproc.googleapis.com/v1/projects/projectName/regions/region/clusters/clusterName:setIamPolicy Request body
{ "policy": { "version": "", "bindings": [ { "role": "roles/editor", "members": [ "user:mike@example.com", "group:admins@example.com", "domain:google.com", "serviceAccount:my-other-app@appspot.gserviceaccount.com" ] }, { "role": "roles/viewer", "members": [ "user:sean@example.com" ] } ], "etag": "value-from-getIamPolicy" } } - Der Inhalt der JSON-Antwort sieht in etwa so aus:
Antwort
{ "bindings": [ { "role": "roles/editor", "members": [ "user:mike@example.com", "group:admins@example.com", "domain:google.com", "serviceAccount:my-other-app@appspot.gserviceaccount.com" ] }, { "role": "roles/viewer", "members": [ "user:sean@example.com" ] } ], "etag": "string" }
Console
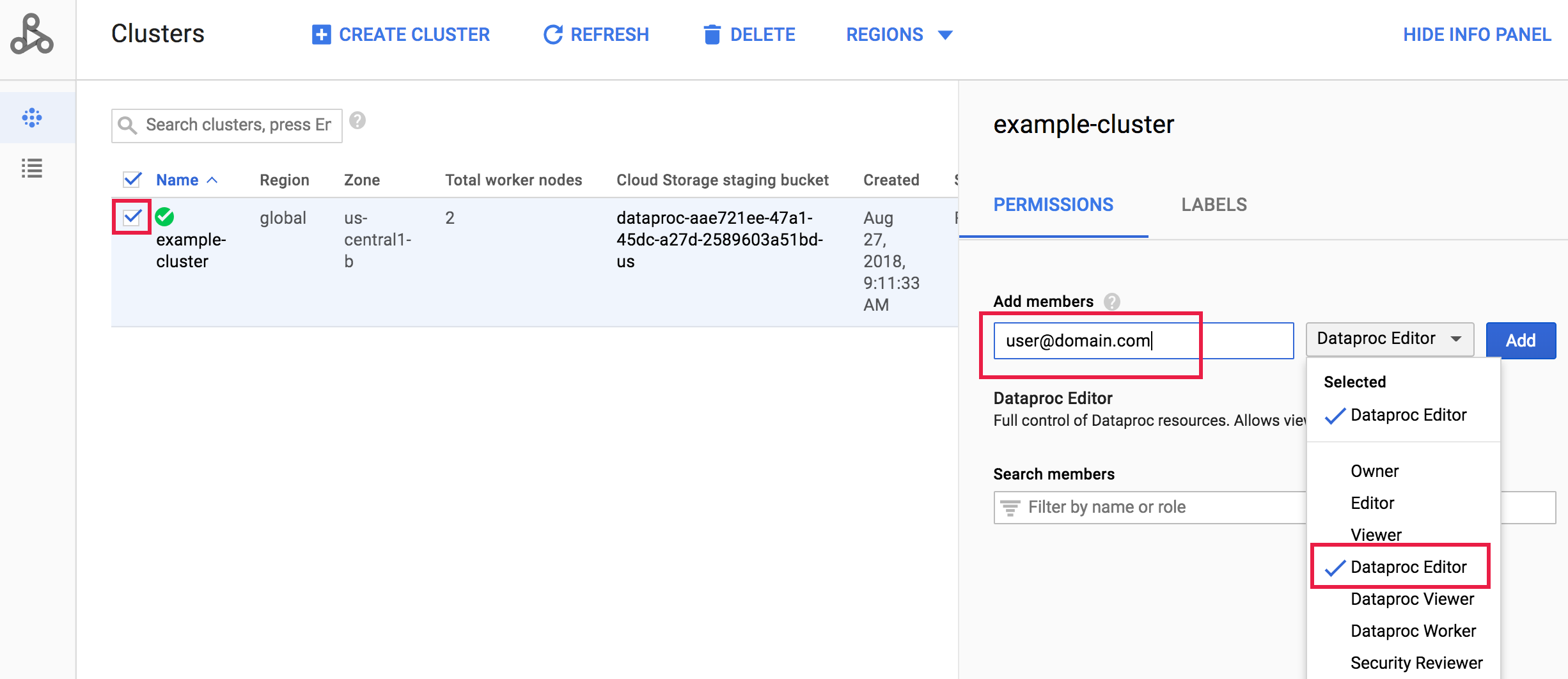
Gehen Sie in der Google Cloud Console zur Managed Service for Apache Spark-Cluster Seite und klicken Sie auf das Feld links neben dem Clusternamen, um das Berechtigungen/Labels Steuerfeld zu öffnen. Wenn das Steuerfeld nicht angezeigt wird, klicken Sie oben rechts auf der Seite auf INFO-STEUERFELD ANZEIGEN. Wählen Sie im Tab „Berechtigungen“ die Rolle „Managed Service for Apache Spark“ aus, fügen Sie im Feld Hauptkonten hinzufügen eine oder mehrere Kontoadressen hinzu und klicken Sie dann auf Hinzufügen.
Durch Granular IAM aktivierte SDK-Befehle
In diesem Abschnitt werden die gcloud dataproc-Befehle beschrieben, die für Managed Service for Apache Spark-Ressourcen nach jeder Granular IAM-Rolle aktiviert sind.
Cluster
| IAM-Rolle | Befehl |
|---|---|
| Betrachter | gcloud dataproc clusters describe cluster-name |
| Bearbeiter | gcloud dataproc clusters describe cluster-namegcloud dataproc clusters listgcloud dataproc clusters delete cluster-namegcloud dataproc clusters diagnose cluster-namegcloud dataproc clusters update cluster-namegcloud beta dataproc clusters start cluster-namegcloud beta dataproc clusters stop cluster-name |
| Inhaber | gcloud dataproc clusters describe cluster-namegcloud dataproc clusters listgcloud dataproc clusters delete cluster-namegcloud dataproc clusters diagnose cluster-namegcloud dataproc clusters update cluster-namegcloud beta dataproc clusters start cluster-namegcloud beta dataproc clusters stop cluster-namegcloud dataproc clusters get-iam-policy cluster-namegcloud dataproc clusters set-iam-policy cluster-name |
Jobs
| IAM-Rolle | Befehl |
|---|---|
| Betrachter | gcloud dataproc jobs describe job-id |
| Bearbeiter | gcloud dataproc jobs delete job-idgcloud dataproc jobs describe job-idgcloud dataproc jobs kill job-idgcloud dataproc jobs update job-idgcloud dataproc jobs wait job-id |
| Inhaber | gcloud dataproc jobs delete job-idgcloud dataproc jobs describe job-idgcloud dataproc jobs kill job-idgcloud dataproc jobs update job-idgcloud dataproc jobs wait job-idgcloud dataproc jobs get-iam-policy job-idgcloud dataproc jobs set-iam-policy job-id |
Betrieb
| IAM-Rolle | Befehl |
|---|---|
| Betrachter | gcloud dataproc operations describe operation-id |
| Bearbeiter | gcloud dataproc operations delete operation-idgcloud dataproc operations describe operation-idgcloud dataproc operations cancel operation-id |
| Inhaber | gcloud dataproc operations delete operation-idgcloud dataproc operations describe operation-idgcloud dataproc operations cancel operation-idgcloud dataproc operations get-iam-policy operation-idgcloud dataproc operations set-iam-policy operation-id |
Workflowvorlagen
| IAM-Rolle | Befehl |
|---|---|
| Betrachter | gcloud dataproc workflow-templates describe template-id |
| Bearbeiter | gcloud dataproc workflow-templates delete template-idgcloud dataproc workflow-templates describe template-idgcloud dataproc workflow-templates remove-job template-idgcloud dataproc workflow-templates run template-id |
| Inhaber | gcloud dataproc workflow-templates delete template-idgcloud dataproc workflow-templates describe template-idgcloud dataproc workflow-templates remove-job template-idgcloud dataproc workflow-templates run template-idgcloud dataproc workflow-templates get-iam-policy template-idgcloud dataproc workflow-templates set-iam-policy template-id |
Autoscaling-Richtlinien
| IAM-Rolle | Befehl |
|---|---|
| Betrachter | gcloud dataproc autoscaling-policies describe policy-id |
| Bearbeiter | gcloud dataproc autoscaling-policies delete policy-idgcloud dataproc autoscaling-policies describe policy-idgcloud dataproc autoscaling-policies update policy-idgcloud dataproc clusters create cluster-name --autoscaling-policy policy-id |
| Inhaber | gcloud dataproc autoscaling-policies delete policy-idgcloud dataproc autoscaling-policies describe policy-idgcloud dataproc autoscaling-policies update policy-idgcloud dataproc clusters create cluster-name --autoscaling-policy policy-idgcloud dataproc autoscaling-policies get-iam-policy policy-idgcloud dataproc autoscaling-policies set-iam-policy policy-id |
Jobs mit Granular IAM senden
Damit ein Hauptkonto (Nutzer, Gruppe oder Dienstkonto) Jobs mit Managed Service for Apache Spark Granular IAM an einen angegebenen Cluster senden kann, müssen dem Nutzer zusätzlich zur Editor-Rolle in einem Cluster zusätzliche Berechtigungen auf Projektebene gewährt werden. Im Folgenden sind die Schritte beschrieben, wie Sie einem Hauptkonto das Senden von Jobs auf einem bestimmten Managed Service for Apache Spark-Cluster gestatten:
- Erstellen Sie einen Cloud Storage-Bucket, mit dem der Cluster eine Verbindung zu Cloud Storage herstellen kann.
- Fügen Sie das Hauptkonto der Richtlinie auf Bucket-Ebene hinzu,
wählen Sie die Rolle „Storage-Objektbetrachter“ für das Hauptkonto aus
(siehe
roles/storage.objectViewer), die die folgenden Berechtigungen umfasst:storage.objects.getstorage.objects.list
- Übergeben Sie, wenn Sie den Cluster erstellen, den Namen des soeben erstellten Buckets
mithilfe des
--bucketParameters an den Cluster. Weitere Informationen finden Sie untergcloud dataproc clusters create --bucket. - Legen Sie nach dem Erstellen des Clusters eine Richtlinie für den Cluster fest, der dem Hauptkonto eine Bearbeiter- oder Eigentümerrolle erteilt. Weitere Informationen finden Sie unter Managed Service for Apache Spark Granular IAM verwenden.
- Erstellen Sie eine benutzerdefinierte IAM-Rolle
mit den folgenden Berechtigungen:
dataproc.jobs.createdataproc.jobs.get
- Wählen Sie das Hauptkonto auf der Google Cloud Console IAM-Seite aus oder fügen Sie es hinzu und wählen Sie dann die benutzerdefinierte Rolle aus, um sie dem Hauptkonto hinzuzufügen.