
Después de crear un clúster de Managed Service para Apache Spark, lo puedes configurar (“escalar”) mediante el aumento o la disminución de la cantidad de nodos trabajadores primarios o secundarios (escalamiento horizontal) en el clúster. Puedes escalar un clúster de Managed Service para Apache Spark en cualquier momento, incluso cuando los trabajos están en ejecución. No puedes cambiar el tipo de máquina de un clúster existente (escalamiento vertical). Para escalar verticalmente, crea un clúster con un tipo de máquina compatible, luego, migra los trabajos al clúster nuevo.
Puedes escalar un clúster de Managed Service para Apache Spark para lo siguiente:
- Para aumentar la cantidad de trabajadores y hacer que un trabajo se ejecute más rápido
- Para disminuir la cantidad de trabajadores y ahorrar dinero (consulta Retiro de servicio ordenado como una opción que se usa cuando se reduce el tamaño de un clúster para evitar la pérdida de trabajo en progreso).
- Para aumentar la cantidad de nodos y expandir el almacenamiento disponible en el sistema de archivos distribuido de Hadoop (HDFS)
Como los clústeres se pueden escalar más de una vez, puedes necesitar aumentar o disminuir el tamaño del clúster en algún momento y volverlo a hacer después.
Usa el escalamiento
Hay tres formas de escalar tu clúster de Managed Service para Apache Spark:
- Usa la herramienta de línea de comandos de
gclouden gcloud CLI. - Edita la configuración del clúster en la Google Cloud consola.
- Usa la API de REST.
Los trabajadores nuevos que se agreguen a un clúster usarán el mismo tipo de máquina que los trabajadores existentes. Por ejemplo, si un clúster se crea con trabajadores que usan el tipo de máquina n1-standard-8, los trabajadores nuevos también usarán el tipo de máquina n1-standard-8.
Puedes escalar la cantidad de trabajadores principales o secundarios (interrumpibles), o ambos. Por ejemplo, si solo escalas la cantidad de trabajadores interrumpibles, la cantidad de trabajadores principales permanece igual.
gcloud
Para escalar un clúster congcloud dataproc clusters update,
ejecuta el siguiente comando:
gcloud dataproc clusters update cluster-name \ --region=region \ [--num-workers and/or --num-secondary-workers]=new-number-of-workers
gcloud dataproc clusters update dataproc-1 \
--region=region \
--num-workers=5
...
Waiting on operation [operations/projects/project-id/operations/...].
Waiting for cluster update operation...done.
Updated [https://dataproc.googleapis.com/...].
clusterName: my-test-cluster
...
masterDiskConfiguration:
bootDiskSizeGb: 500
masterName: dataproc-1-m
numWorkers: 5
...
workers:
- my-test-cluster-w-0
- my-test-cluster-w-1
- my-test-cluster-w-2
- my-test-cluster-w-3
- my-test-cluster-w-4
...
API de REST
Consulta clusters.patch.
Ejemplo
PATCH /v1/projects/project-id/regions/us-central1/clusters/example-cluster?updateMask=config.worker_config.num_instances,config.secondary_worker_config.num_instances
{
"config": {
"workerConfig": {
"numInstances": 4
},
"secondaryWorkerConfig": {
"numInstances": 2
}
},
"labels": null
}
Console
Después de crear un clúster, lo puedes escalar si abres la página Detalles del clúster desde la Google Cloud consola Clústeres y, luego, haces clic en el botón Editar en la pestaña Configuración. Ingresa un valor nuevo para la cantidad de nodos trabajadores o
nodos trabajadores interrumpibles (actualizados a "5" y "2", respectivamente,
en la captura de pantalla siguiente).
Ingresa un valor nuevo para la cantidad de nodos trabajadores o
nodos trabajadores interrumpibles (actualizados a "5" y "2", respectivamente,
en la captura de pantalla siguiente).
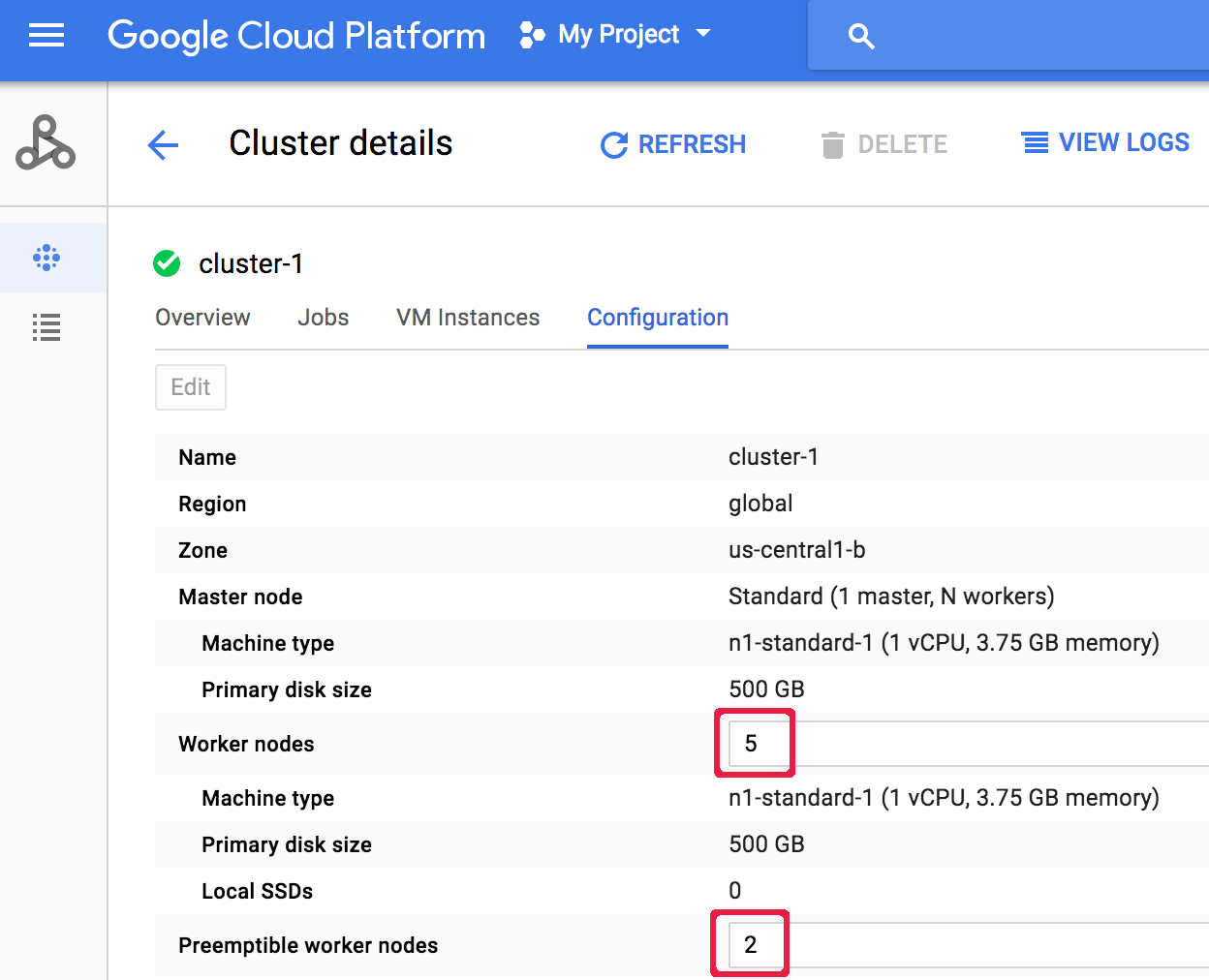 Haz clic en Guardar para actualizar el clúster.
Haz clic en Guardar para actualizar el clúster.
Cómo Managed Service para Apache Spark selecciona nodos de clúster para quitar
En los clústeres creados con versiones de imagen 1.5.83+, 2.0.57+, y 2.1.5+, cuando se reduce un clúster, Managed Service para Apache Spark intenta minimizar el impacto de la eliminación de nodos en las aplicaciones YARN en ejecución. Para ello, primero quita los nodos inactivos, en mal estado y en inactividad, y, luego, quita los nodos con la menor cantidad de instancias principales de aplicaciones YARN y contenedores en ejecución.
Retiro de servicio ordenado
Cuando realizas un escalamiento descendente de un clúster, el trabajo en progreso puede terminar antes de completarse. Si usas Managed Service para Apache Spark v 1.2 o una versión posterior, puedes usar el retiro de servicio ordenado, que incorpora el retiro de servicio ordenado de nodos YARN para terminar el trabajo en curso en un trabajador antes de quitarlo del clúster de Cloud Managed Service para Apache Spark.
Retiro de servicio ordenado y trabajadores secundarios
El grupo de trabajadores interrumpibles (secundarios) continúa con el aprovisionamiento o el borrado de trabajadores para alcanzar el tamaño esperado incluso después de que una operación de escalamiento de clúster se marcó como completada. Si intentas el retiro de servicio ordenado de un trabajador secundario
y recibes un mensaje de error similar al siguiente:
"El grupo de trabajadores secundarios
no se puede modificar fuera de Managed Service para Apache Spark. Si la creación o actualización de este clúster es reciente, espera unos minutos antes de realizar un retiro de servicio ordenado para permitir que todas las instancias secundarias se unan o abandonen el clúster.
Tamaño del grupo de trabajadores secundarios esperado: x. Tamaño real: y",
espera unos
minutos y, luego, repite la solicitud de retiro de servicio ordenado.
Usa el retiro de servicio ordenado
El retiro de servicio ordenado de Managed Service para Apache Spark incorpora el retiro de servicio ordenado de nodos YARN para finalizar un trabajo en curso en un trabajador antes de quitarlo del clúster de Cloud Managed Service para Apache Spark. Por configuración predeterminada, el retiro de servicio ordenado está inhabilitado. Lo inhabilitas mediante la configuración de un valor de tiempo de espera cuando actualizas tu clúster con el fin de quitar uno o más trabajadores del clúster.
gcloud
Cuando actualices un clúster para quitar uno o más trabajadores, usa el comando gcloud dataproc clusters update con la marca--graceful-decommission-timeout. Los valores del tiempo de espera (string) pueden ser un valor de “0s” (el predeterminado; retiro de servicio a la fuerza no ordenado) o una duración positiva relacionada con la hora actual (por ejemplo, “3s”).
La duración máxima es de 1 día.
gcloud dataproc clusters update cluster-name \ --region=region \ --graceful-decommission-timeout="timeout-value" \ [--num-workers and/or --num-secondary-workers]=decreased-number-of-workers \ ... other args ...
API de REST
Consulta clusters.patch.gracefulDecommissionTimeout. Los valores del tiempo de espera (string) pueden ser un valor de “0” (el predeterminado; retiro de servicio a la fuerza no ordenado) o una duración en segundos (por ejemplo, “3s”). La duración máxima es de 1 día.Console
Después de crear un clúster, puedes seleccionar el retiro de servicio ordenado de un clúster si abres la página Detalles del clúster (Cluster details) desde la página de la Google Cloud consola Clústeres (Clusters) y, luego, haces clic en el botón Editar (Edit) en la pestaña Configuración (Configuration) .
En la sección Retiro de servicio ordenado (Graceful Decommissioning), selecciona
Usa el retiro de servicio ordenado (Use graceful decommissioning) y, luego, selecciona un valor de tiempo de espera.
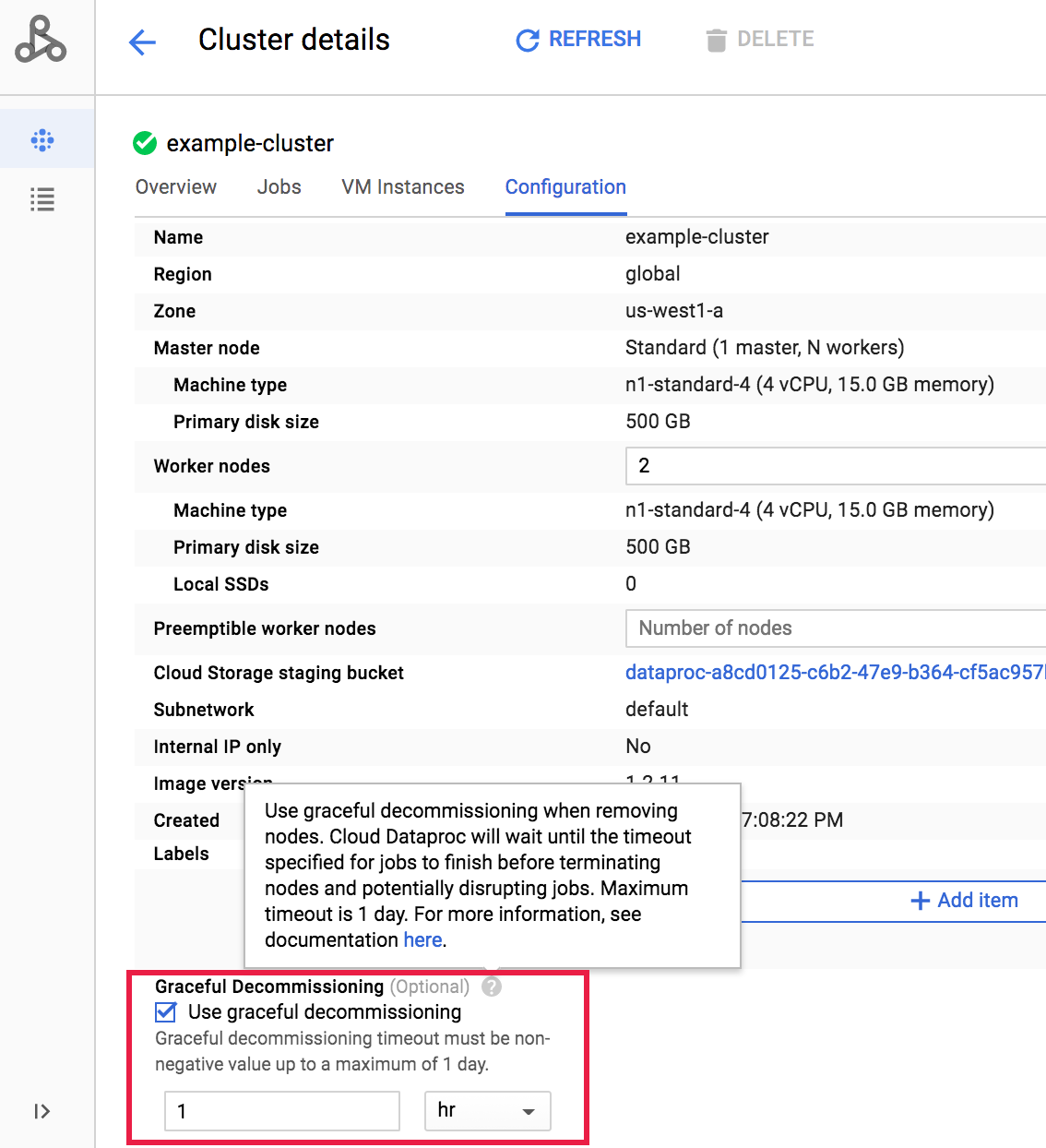 Haz clic en Guardar para actualizar el clúster.
Haz clic en Guardar para actualizar el clúster.
Cancela una operación de reducción de escala de retiro de servicio ordenado
En los clústeres de Managed Service para Apache Spark creados con versiones de imagen
2.0.57+
o 2.1.5+,
puedes ejecutar el comando gcloud dataproc operations cancel
o emitir una solicitud operations.cancel
de la API de Managed Service para Apache Spark para cancelar una operación de reducción de escala de retiro de servicio ordenado.
Esto es lo que sucede cuando cancelas una operación de reducción de escala de retiro de servicio ordenado:
Los trabajadores en estado
DECOMMISSIONINGse vuelven a poner en servicio y se vuelvenACTIVEcuando se completa la cancelación de la operación.Si la operación de reducción de escala incluye actualizaciones de etiquetas, es posible que las actualizaciones no entren en vigencia.
Para verificar el estado de la solicitud de cancelación, puedes
ejecutar el gcloud dataproc operations describe
comando o emitir una solicitud
operations.get
de la API de Managed Service para Apache Spark. Si la operación de cancelación se realiza correctamente, el estado de la operación interna se marca como CANCELLED.