
Este documento ajuda você a migrar suas cargas de trabalho do Apache Kafka para o serviço gerenciado do Google Cloud para Apache Kafka, que é um serviço gerenciado no Google Cloud.
O Managed Service para Apache Kafka ajuda você a executar o Apache Kafka no Google Cloud. Nesta solução documentada, você move dados de um cluster externo do Apache Kafka para um cluster do Serviço Gerenciado para Apache Kafka.
Para mais informações sobre o Serviço gerenciado para Apache Kafka, consulte a visão geral do Serviço gerenciado para Apache Kafka.
Recomendamos usar o MirrorMaker 2.0 do Apache Kafka para essa migração.
O MirrorMaker 2.0 é uma ferramenta para replicar dados entre clusters do Apache Kafka em tempo real. Ele pode ser usado para migrações de dados, recuperação de desastres, isolamento e agregação de dados.
Para mais informações sobre o MirrorMaker 2.0, consulte a próxima seção.
O que é o MirrorMaker 2.0
O MirrorMaker 2.0 usa a estrutura Kafka Connect para replicar dados entre clusters do Kafka. O Kafka Connect é uma estrutura para fazer streaming de dados entre clusters do Kafka e outros sistemas. Ele funciona como um pipeline escalonável e confiável. Esse framework simplifica a integração do Kafka com vários sistemas externos, como bancos de dados, filas de mensagens e armazenamento on-line, usando conectores disponíveis. Confira uma lista de possíveis cenários em que você pode usar o MirrorMaker 2.0:
Migrações de dados: mova sua carga de trabalho do Kafka para um novo cluster, conforme demonstrado neste guia.
Recuperação de desastres: crie um cluster de backup para garantir a continuidade dos negócios em caso de falhas.
Isolamento de dados: replique seletivamente tópicos em um cluster público enquanto mantém os dados sensíveis seguros em um cluster particular.
Agregação de dados: consolide dados de vários clusters do Kafka em um cluster central para fins analíticos.
O MirrorMaker 2.0 é compatível com a versão 2.4.0 e mais recentes do Kafka, oferecendo estes recursos principais:
Replicação abrangente: replica todos os componentes necessários, incluindo tópicos, dados e configurações, grupos de consumidores com offsets e ACLs.
Preservação de partições: mantém o mesmo esquema de particionamento no cluster de destino, simplificando a transição para aplicativos.
Criação automática de tópicos e partições: detecta e replica automaticamente novos tópicos e partições, minimizando a configuração manual.
Recursos de monitoramento: fornecem métricas essenciais, como latência de replicação de ponta a ponta, permitindo acompanhar a integridade e o desempenho do processo de replicação.
Tolerância a falhas e escalonabilidade: garante uma operação confiável mesmo com altos volumes de dados e pode ser escalonado horizontalmente para lidar com cargas de trabalho crescentes.
Tópicos internos para robustez: usa tópicos internos para sincronização de deslocamento, pontos de verificação e pulsações. Esses tópicos têm fatores de replicação configuráveis, como
offset.syncs.topic.replication.factor, para garantir alta disponibilidade e tolerância a falhas.
O MirrorMaker 2.0 oferece dois modos de implantação:
Modo de cluster dedicado: o MirrorMaker 2.0 é executado como um cluster independente, gerenciando os próprios workers. Este documento se concentra nesse modo, fornecendo um exemplo prático de implantação e configuração.
Modo de cluster do Kafka Connect: o MirrorMaker 2.0 é executado como conectores em um cluster do Kafka Connect.
Fluxo de trabalho de alto nível
O diagrama a seguir ilustra a arquitetura para migrar dados de um cluster de origem do Apache Kafka para um cluster do Serviço Gerenciado para Apache Kafka usando o MirrorMaker 2.0.
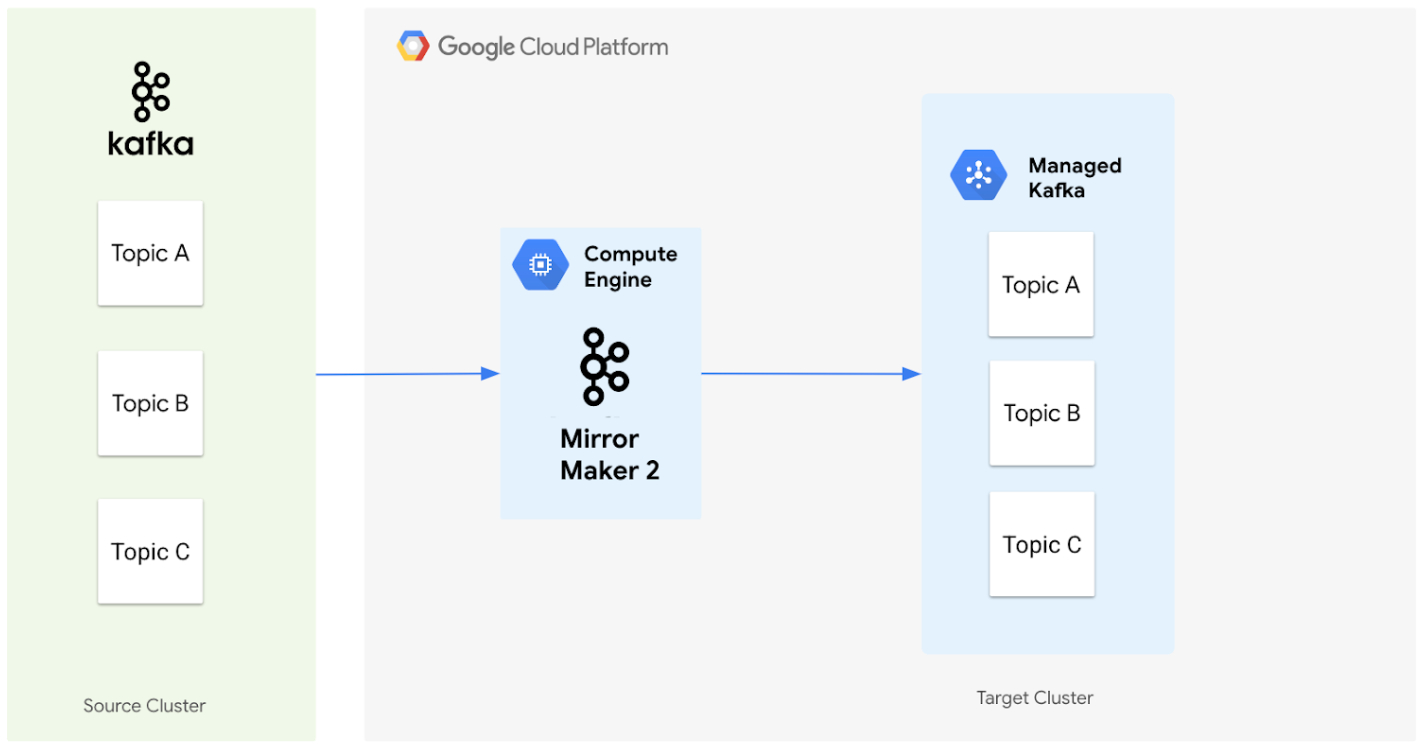
Veja como os componentes funcionam juntos:
Cluster de origem: representa seu cluster atual do Apache Kafka, que pode estar no local ou em outro ambiente de nuvem. Ele contém os tópicos que você quer migrar. Neste diagrama, o cluster de origem do Apache Kafka contém três tópicos: A, B e C.
MirrorMaker 2.0: esse componente principal, implantado em uma VM do Compute Engine como um cluster dedicado do MirrorMaker 2.0, replica ativamente os dados do cluster de origem do Apache Kafka para o cluster de destino do Serviço Gerenciado para Apache Kafka. Além disso, ele cria automaticamente os tópicos e partições correspondentes no cluster de destino, caso eles não existam, espelhando a configuração do cluster de origem.
Cluster de destino: é o cluster do Serviço gerenciado para Apache Kafka. Ele se torna o novo lar dos seus dados do Kafka, com o MirrorMaker 2.0 garantindo que os tópicos e partições sejam criados para corresponder ao seu ambiente de origem.
Confira um fluxo de trabalho geral para o processo de migração.
Avaliação inicial
Documente a configuração atual do Kafka, incluindo o tamanho do cluster, os tópicos, a capacidade de processamento e os grupos de consumidores.
Planeje suas metas e estratégias de migração, incluindo tolerância a inatividade e abordagem de transferência.
Estime os recursos necessários para seu cluster do Serviço gerenciado para Apache Kafka.
Preparação
Crie um cluster do Serviço gerenciado para Apache Kafka.
Configure a conectividade de rede entre o cluster do Kafka atual e o cluster do Managed Service para Apache Kafka que você acabou de criar.
Implante o MirrorMaker 2.0 em uma VM Google Cloud .
Execução da migração
Configure o MirrorMaker 2.0 para replicar dados do cluster do Kafka para o cluster do Serviço Gerenciado para Apache Kafka.
Monitore o processo de replicação usando métricas do MirrorMaker 2.0.
Migre gradualmente os consumidores e produtores para o novo cluster do Serviço Gerenciado para Apache Kafka.
Validação e migração
Valide a integridade dos dados e os recursos do aplicativo no cluster do Serviço gerenciado para Apache Kafka.
Faça a migração final, redirecionando o tráfego para o cluster do Serviço gerenciado para Apache Kafka.
Desative o cluster antigo do Kafka.
Pós-migração
Monitore continuamente a performance do seu cluster do Serviço gerenciado para Apache Kafka.
Revise e atualize a documentação para refletir as mudanças.
Minimizar o tempo de inatividade da migração
Esta seção descreve algumas considerações sobre a migração dos dados do Kafka de código aberto para o Serviço gerenciado para Apache Kafka usando o MirrorMaker 2.0. O MirrorMaker 2.0 facilita a replicação de dados e de offsets, permitindo que os consumidores retomem do ponto correto no novo cluster. No entanto, um planejamento cuidadoso é essencial para minimizar o tempo de inatividade durante o processo de migração. Considere estas estratégias:
Implantações paralelas: para minimizar o tempo de inatividade ao mudar para o novo cluster do Serviço gerenciado para Apache Kafka, é possível executar instâncias paralelas dos aplicativos nos clusters antigos e novos. Durante essa transição, desative temporariamente as ações no seu aplicativo que precisam acontecer apenas uma vez por mensagem, como o envio de uma notificação. Desative esses efeitos colaterais para evitar consequências não intencionais de processar a mesma mensagem duas vezes. Depois que as novas instâncias estiverem totalmente atualizadas, redirecione todo o tráfego para o novo cluster e reative todos os recursos.
Implantações graduais: migre em fases menores e gerenciáveis, começando com aplicativos menos críticos. Essa abordagem ajuda a isolar possíveis problemas e minimiza o impacto de interrupções.
Implantações azul e verde: crie uma réplica completa do ambiente de produção (verde) ao lado do ambiente atual (azul). Mude gradualmente o tráfego do azul para o verde, permitindo testes e validação antes da transferência final. Essa abordagem minimiza o tempo de inatividade, mas exige maior utilização de recursos.
Requisitos de processamento de mensagens: entenda a tolerância do aplicativo para mensagens duplicadas ou ausentes e configure os consumidores de acordo. O MirrorMaker 2.0 oferece configurações para processar a semântica de entrega de mensagens. Por exemplo,
sync.group.offsets.enabledoferece suporte à sincronização de compensação do consumidor. Os consumidores podem usar os offsets sincronizados para retomar a leitura de onde pararam no cluster de origem. Isso evita a perda de mensagens ou o recebimento de muitos duplicados.Comunicação e coordenação: a comunicação eficaz com as equipes de aplicativos é essencial para uma migração tranquila. Estabeleça canais de comunicação claros e coordene os horários de transferência.
Conectar o Apache Kafka local ao Google Cloud
Se o cluster de origem do Apache Kafka estiver localizado no local, será necessário estabelecer uma conexão segura entre sua rede local e a nuvem privada virtual (VPC) em que o cluster do Managed Service para Apache Kafka está localizado. Use uma das seguintes opções em Google Cloud.
Cloud VPN: uma solução econômica adequada para necessidades de largura de banda menores ou experimentos iniciais de migração. Ele cria um túnel criptografado na Internet pública. Para mais informações sobre o Cloud VPN, consulte Visão geral do Cloud VPN.
Cloud Interconnect: fornece uma conexão dedicada de alta largura de banda entre sua rede local e Google Cloud. Isso é ideal para implantações de nível empresarial que exigem maior capacidade de processamento e menor latência. Você pode escolher entre a Interconexão dedicada (para conexão física direta) ou a Interconexão por parceiro (conexão por um provedor de serviços autorizado). Para mais informações sobre a documentação do Google Cloud Interconnect, consulte a visão geral do Cloud Interconnect.
Ao criar um cluster do Managed Service para Apache Kafka, é preciso selecionar pelo menos uma sub-rede na VPC. Essa sub-rede fornece os endereços IP que seu cluster usa para se comunicar com outros recursos na VPC, tornando o cluster acessível na rede VPC.
Para se conectar com segurança ao cluster do Managed Service for Apache Kafka de redes locais ou outras redes VPC, use o Private Service Connect (PSC) pelo Cloud VPN ou Cloud Interconnect. Não é necessário configurar endpoints do PSC explicitamente. Ao selecionar uma sub-rede durante a criação do cluster, o serviço gerenciado para Apache Kafka cria automaticamente os endpoints necessários do PSC. Isso simplifica a configuração da rede, permitindo que você acesse o cluster usando endereços IP internos na VPC, sem precisar gerenciar regras de firewall complexas ou endereços IP públicos.
Para mais informações sobre a configuração de rede do serviço gerenciado para Apache Kafka, consulte Rede para o serviço gerenciado para Apache Kafka.
Antes de começar
Antes de começar a criar a configuração de migração, documente sua configuração atual do Apache Kafka. Isso é necessário para calcular os recursos, como vCPUs, memória e armazenamento, necessários para seu novo cluster do Serviço gerenciado para Apache Kafka. Reúna as seguintes informações sobre seu ambiente de origem do Apache Kafka:
Verifique se a versão do Apache Kafka é 2.4.0 ou mais recente.
Para verificar a versão do cluster do Apache Kafka, navegue até o diretório de instalação do Kafka e execute o comando
bin/kafka-topics.sh --version.Identifique os clusters e tópicos que precisam ser migrados.
Identifique os produtores e consumidores associados a cada tópico.
Identifique todos os grupos de consumidores.
Determine a capacidade de processamento de mensagens no nível do cluster e do tópico.
Determine o fator de replicação dos clusters e tópicos.
Documente as configurações do consumidor, principalmente protocolos de segurança e qualquer integração com outros serviços do Google Cloud .
Para evitar interrupções durante a migração, mapeie todas as dependências de aplicativos relacionadas ao cluster Kafka de origem. Antes de migrar seu ambiente de produção, faça um teste usando um cluster não crítico em um ambiente de desenvolvimento. Valide o processo e identifique possíveis problemas. Por fim, crie um plano de reversão abrangente para voltar ao cluster original, se necessário.
Calcular o tamanho do cluster de destino
Para estimar o número de vCPUs e o tamanho da memória necessários para seu cluster do Serviço gerenciado para Apache Kafka, consulte Planejar o tamanho do cluster do Kafka. A configuração do disco e do broker é automática e não pode ser ajustada.
O Kafka de código aberto fornece métricas JMX. Para calcular com precisão o tamanho necessário do cluster para o Managed Service para Apache Kafka, use as seguintes métricas JMX. Essas métricas são informadas no nível do corretor. É preciso agregar os dados de todos os brokers para calcular a taxa de transferência do cluster.
kafka.server:type=BrokerTopicMetrics,name=BytesInPerSec: Essa métrica informa a taxa de bytes de entrada dos clientes em todos os tópicos. Omita o parâmetrotopic={...}para receber a taxa agregada de todos os temas.kafka.server:type=BrokerTopicMetrics,name=BytesOutPerSec: Essa métrica informa a taxa de bytes de saída para clientes em todos os tópicos. Omita o parâmetrotopic={...}para receber a taxa geral.
Ao monitorar essas métricas do JMX por um período, é possível coletar pontos de dados para calcular o seguinte:
Média de dados de entrada, MB/s: representa a taxa média de ingestão de dados no cluster do Kafka.
Pico de dados de entrada, MB/s: representa a taxa mais alta em que os dados são ingeridos no cluster do Kafka.
Média de saída de dados, MB/s: essa métrica representa a taxa média em que os dados são consumidos do cluster do Kafka.
Saída de dados máxima, MB/s: essa métrica representa a taxa mais alta em que os dados estão sendo consumidos do cluster do Kafka.
Talvez seja necessário usar algumas operações matemáticas para agregar os dados e converter bytes em MB. Usando esses valores calculados, você pode estimar a taxa de gravação equivalente da seguinte forma:
Write-equivalent rate (Avg/Peak) = (total write bandwidth) + (total read bandwidth / 4)
Essa taxa equivalente de gravação ajuda a determinar a carga geral de gravação no cluster, o que é necessário para dimensionar adequadamente o cluster do Serviço gerenciado para Apache Kafka.
Criar um cluster do Serviço gerenciado para Apache Kafka
Um cluster do Managed Service para Apache Kafka está localizado em umGoogle Cloud projeto e uma região específicos. É possível acessar usando um conjunto de endereços IP em uma ou mais sub-redes em qualquer nuvem privada virtual (VPC).
O tamanho do cluster é determinado pelo número de CPUs e pela RAM total alocada a ele. Nesse caso, o tamanho do cluster precisa ser igual ao do cluster de origem do Apache Kafka. Para mais informações sobre como fazer esse cálculo, consulte Calcular o tamanho do cluster de destino.
Para receber as permissões necessárias para criar um cluster, peça ao administrador que conceda a você ou à conta de serviço que está criando o cluster o papel do IAM de administrador do Kafka gerenciado (roles/managedkafka.admin) no seu projeto. Para mais
informações sobre a concessão de papéis, consulte
Gerenciar o acesso a projetos, pastas e organizações.
Para criar um cluster do Managed Service para Apache Kafka, siga as instruções do início rápido em Produzir e consumir mensagens com a CLI. A criação de um cluster geralmente leva de 20 a 30 minutos.
Configurar o MirrorMaker 2.0 no modo de cluster independente
Para conferir um documento de prova de conceito e um exemplo de código que mostram como usar o MirrorMaker 2.0 e o Terraform para transferir dados do Kafka para o Google Cloud, consulte este repositório do GitHub.
Nesta seção, você vai aprender a instalar e configurar o MirrorMaker 2.0 em um modo de cluster independente em uma VM Google Cloud . Essa configuração permite replicar dados do seu cluster do Apache Kafka para um cluster do Serviço Gerenciado para Apache Kafka.
Crie uma VM na mesma rede que recebeu acesso ao cluster do Managed Service para Apache Kafka. Use o comando gcloud compute instances create.
gcloud compute instances create VM_NAME\ --zone=ZONE\ [--image=IMAGE | --image-family=IMAGE_FAMILY]\ --image-project=IMAGE_PROJECT\ --machine-type=MACHINE_TYPE
Substitua:
VM_NAME: o nome da VM que você quer criar.ZONE: a zona em que você quer criar a VM.IMAGEouIMAGE_FAMILY: a imagem ou família de imagens que você quer usar para a VM.IMAGE_PROJECT: o projeto em que a imagem está localizada.MACHINE_TYPE: o tipo de máquina que você quer usar para a VM.
Para acessar a VM recém-criada, use SSH.
Para mais informações sobre conexões SSH, consulte Sobre conexões SSH.
Para fazer o download e extrair o Kafka, execute os seguintes comandos na janela de terminal da nova VM:
wget https://downloads.apache.org/kafka/3.7.1/kafka_2.13-3.7.1.tgz tar -xzvf kafka_2.13-3.7.1.tgzFaça o download do Java, extraia o pacote e defina o caminho do Java.
# Download Java wget https://download.java.net/java/GA/jdk11/9/GPL/openjdk-11.0.2_linux-x64_bin.tar.gz # Extract Java tar -xzvf openjdk-11.0.2_linux-x64_bin.tar.gz # Set Java path export PATH=$PATH:/java/jdk-11.0.2/bin/Edite o arquivo
path/to/kafka/config/mm2.propertiese atualize as seguintes propriedades:clusters = source, target source.bootstrap.servers = <source_kafka_bootstrap_servers> target.bootstrap.servers = <target_kafka_bootstrap_servers> source.security.protocol = SASL_SSL source.sasl.mechanism = PLAIN source.sasl.jaas.config = org.apache.kafka.common.security.plain.PlainLoginModule required username="<source_kafka_username>" password="<source_kafka_password>"; target.security.protocol = SASL_SSL target.sasl.mechanism = PLAIN target.sasl.jaas.config = org.apache.kafka.common.security.plain.PlainLoginModule required username="<target_kafka_username>" password="<target_kafka_password>"; mirrors = source->target source->target.enabled=true topics = .* groups = .* offset.syncs.topic.replication.factor = 3 checkpoints.topic.replication.factor = 3 heartbeats.topic.replication.factor = 3 emit.checkpoints.interval.seconds = 10Substitua
source_kafka_bootstrap_serversetarget_kafka_bootstrap_serverspelos endereços do servidor de inicialização dos clusters de origem e destino do Kafka, respectivamente. É possível acessar o endereço do servidor de bootstrap do Serviço gerenciado para Apache Kafka usando o comando da Google Cloud CLImanaged-kafka clusters describe.Substitua
source_kafka_usernameesource_kafka_passwordpelas credenciais do cluster Kafka de origem.Substitua
target_kafka_usernameetarget_kafka_passwordpelas credenciais do cluster de destino do Serviço gerenciado para Apache Kafka. Para configurar o nome de usuário e a senha, consulte Autenticação SASL/PLAIN.As configurações
topics = .\*egroups = .\*replicam todos os temas e grupos de consumidores. Se necessário, você pode modificar essas configurações para serem mais específicas.A configuração
offset.syncs.topic.replication.factor = 3define o fator de replicação do tópico interno usado pelo MirrorMaker 2.0 para sincronizar os deslocamentos de consumidores entre os clusters de origem e de destino. Um fator de replicação de3significa que os dados de deslocamento são replicados para três agentes no cluster de destino, garantindo maior disponibilidade e tolerância a falhas.A configuração
checkpoints.topic.replication.factor = 3define o fator de replicação para outro tópico interno usado pelo MirrorMaker 2.0 para armazenar pontos de verificação. Os checkpoints ajudam o MirrorMaker 2.0 a acompanhar o progresso e retomar a replicação do ponto correto em caso de falhas ou reinicializações.A configuração
heartbeats.topic.replication.factor = 3define o fator de replicação do tópico interno usado pelo MirrorMaker 2.0 para enviar sinais de funcionamento. Os heartbeats indicam que o processo do MirrorMaker 2.0 está ativo. Um fator de replicação maior garante que esses heartbeats sejam armazenados de forma confiável e possam ser usados para monitorar a integridade do processo de replicação.A configuração
emit.checkpoints.interval.seconds = 10controla a frequência com que o MirrorMaker 2.0 emite pontos de verificação. Nesse caso, os pontos de verificação são emitidos a cada 10 segundos. Essa frequência oferece um equilíbrio entre o acompanhamento do progresso e a minimização da sobrecarga de gravação de checkpoints.
Inicie o MirrorMaker 2.0. Use o script
connect-mirror-maker.shpara iniciar o processo.O script inicia o MirrorMaker 2.0 no modo independente e começa a replicar dados do cluster de origem do Kafka para o cluster do Serviço Gerenciado para Apache Kafka.
Outras considerações:
Rede: verifique se a VM Google Cloud tem conectividade de rede com o cluster de origem do Kafka e com o cluster de destino do Serviço gerenciado para Apache Kafka. Se o cluster de origem for local, talvez seja necessário configurar uma VPN ou o Interconnect.
Segurança: configure protocolos de segurança e regras de firewall adequados para proteger sua instância do MirrorMaker 2.0 e seus clusters do Kafka.
Ao seguir estas etapas, você pode instalar e configurar o MirrorMaker 2.0 no modo de cluster independente em uma VM Google Cloud para facilitar a migração de dados do Kafka para o Serviço gerenciado para Apache Kafka.
Monitoramento
Monitore o processo do MirrorMaker 2.0 para garantir que ele esteja sendo executado corretamente e replicando os dados conforme o esperado. É possível usar as métricas integradas do MirrorMaker 2 ou outras ferramentas de monitoramento. Depois de migrar os aplicativos, monitore o seguinte para validar o sucesso:
Taxas de transferência de dados downstream: verifique se não há mudanças significativas nas taxas de transferência de dados downstream. Por exemplo, se você estiver usando o Dataflow downstream, a taxa de transferência e as métricas relacionadas ao Kafka precisarão permanecer consistentes.
Utilização de CPU e memória: monitore a utilização de CPU e memória do cluster do Serviço Gerenciado para Apache Kafka usando o Cloud Monitoring. O ideal é que a utilização permaneça abaixo de 75% para garantir a performance ideal.
Registros de erros: verifique regularmente o Cloud Logging para encontrar registros de erros relacionados ao cluster do Serviço gerenciado para Apache Kafka ou aos seus aplicativos. Corrija todos os erros imediatamente para evitar interrupções.
Limitações
- O MirrorMaker 2.0 exige que o cluster de origem do Apache Kafka seja da versão 2.4.0 ou mais recente.