
Ce document vous aide à migrer vos charges de travail Apache Kafka vers Google Cloud Managed Service pour Apache Kafka, qui est un service géré dans Google Cloud.
Managed Service pour Apache Kafka vous aide à exécuter Apache Kafka sur Google Cloud. Dans cette solution documentée, vous allez transférer des données d'un cluster Apache Kafka externe vers un cluster Managed Service pour Apache Kafka.
Pour en savoir plus sur Managed Service pour Apache Kafka, consultez Présentation de Managed Service pour Apache Kafka.
Nous vous recommandons d'utiliser Apache Kafka MirrorMaker 2.0 pour cette migration.
MirrorMaker 2.0 est un outil permettant de répliquer des données entre des clusters Apache Kafka en temps réel. Il peut être utilisé pour les migrations de données, la reprise après sinistre, l'isolation des données et l'agrégation de données.
Pour en savoir plus sur MirrorMaker 2.0, consultez la section suivante.
Qu'est-ce que MirrorMaker 2.0 ?
MirrorMaker 2.0 utilise le framework Kafka Connect pour répliquer les données entre les clusters Kafka. Kafka Connect est un framework permettant de diffuser des données en flux continu entre des clusters Kafka et d'autres systèmes. Il agit comme un pipeline évolutif et fiable. Ce framework simplifie l'intégration de Kafka à divers systèmes externes, tels que des bases de données, des files d'attente de messages et des espaces de stockage en ligne, grâce à l'utilisation de connecteurs facilement disponibles. Voici une liste de scénarios possibles dans lesquels vous pouvez utiliser MirrorMaker 2.0 :
Migrations de données : migrez votre charge de travail Kafka vers un nouveau cluster, comme indiqué dans ce guide.
Reprise après sinistre : créez un cluster de sauvegarde pour assurer la continuité de l'activité en cas de défaillance.
Isolation des données : répliquez sélectivement des thèmes dans un cluster public tout en gardant les données sensibles en sécurité dans un cluster privé.
Agrégation de données : consolidez les données de plusieurs clusters Kafka dans un cluster central à des fins d'analyse.
MirrorMaker 2.0 est compatible avec Kafka version 2.4.0 et ultérieure, et offre les fonctionnalités clés suivantes :
Réplication complète : réplique tous les composants nécessaires, y compris les thèmes, les données et les configurations, les groupes de consommateurs avec des décalages et les LCA.
Préservation des partitions : le même schéma de partitionnement est conservé dans le cluster cible, ce qui simplifie la transition pour les applications.
Création automatique de sujets et de partitions : détecte et réplique automatiquement les nouveaux sujets et partitions, ce qui minimise la configuration manuelle.
Fonctionnalités de surveillance : fournissent des métriques essentielles telles que la latence de réplication de bout en bout, ce qui vous permet de suivre l'état et les performances du processus de réplication.
Tolérance aux pannes et évolutivité : garantissent un fonctionnement fiable, même avec des volumes de données élevés, et peuvent être mises à l'échelle horizontalement pour gérer des charges de travail croissantes.
Sujets internes pour la robustesse : utilise des sujets internes pour la synchronisation des décalages, les points de contrôle et les signaux de présence. Ces sujets ont des facteurs de réplication configurables tels que
offset.syncs.topic.replication.factorpour assurer une haute disponibilité et une tolérance aux pannes.
MirrorMaker 2.0 propose deux modes de déploiement :
Mode cluster dédié : MirrorMaker 2.0 s'exécute en tant que cluster autonome, gérant ses propres nœuds de calcul. Ce document se concentre sur ce mode et fournit un exemple pratique de son déploiement et de sa configuration.
Mode cluster Kafka Connect : MirrorMaker 2.0 s'exécute en tant que connecteurs dans un cluster Kafka Connect existant.
Workflow général
Le diagramme suivant illustre l'architecture permettant de migrer des données d'un cluster Apache Kafka source vers un cluster Managed Service pour Apache Kafka à l'aide de MirrorMaker 2.0.
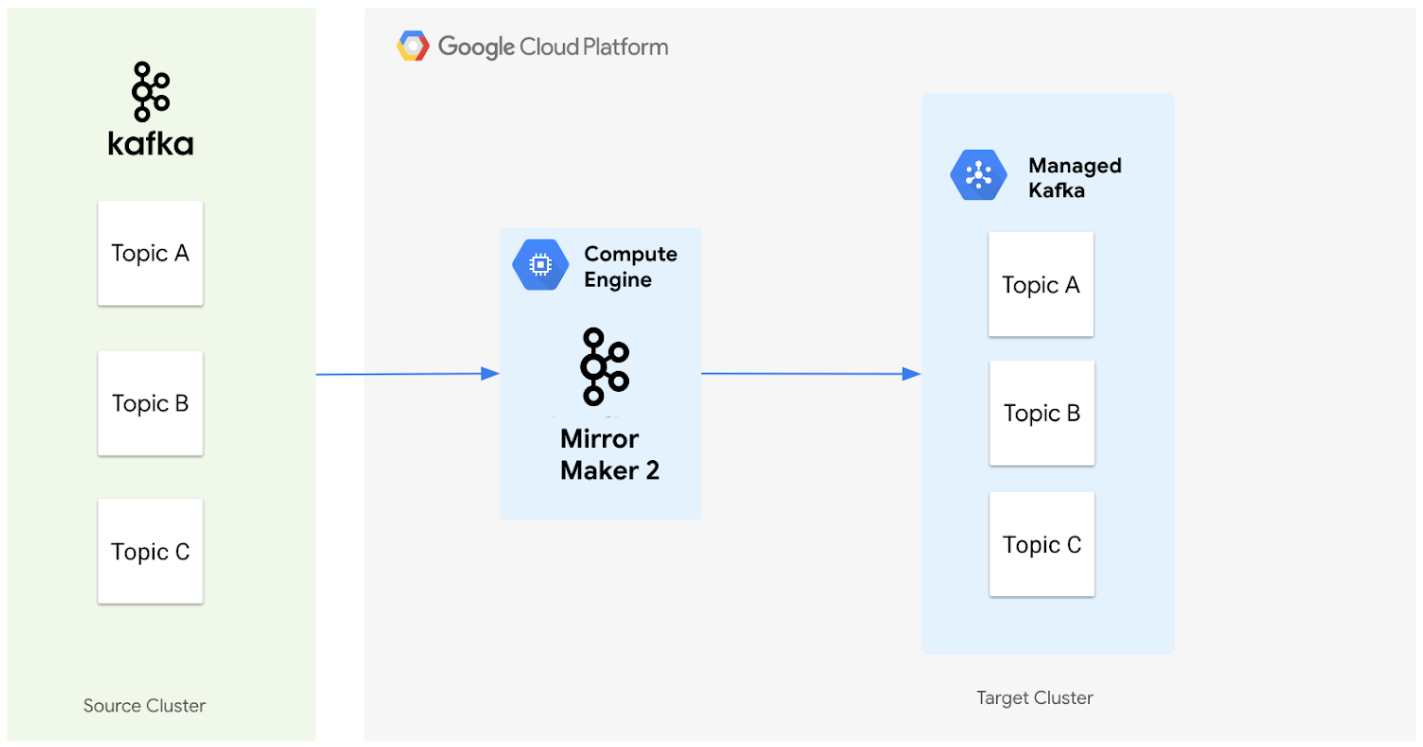
Voici comment les composants interagissent :
Cluster source : il s'agit de votre cluster Apache Kafka existant, qui peut être situé sur site ou dans un autre environnement cloud. Il contient les thèmes que vous souhaitez migrer. Dans ce schéma, le cluster Apache Kafka source contient trois sujets : les sujets A, B et C.
MirrorMaker 2.0 : ce composant principal, déployé sur une VM Compute Engine en tant que cluster MirrorMaker 2.0 dédié, réplique activement les données du cluster Apache Kafka source vers le cluster Managed Service pour Apache Kafka cible. Il est important de noter qu'il crée également automatiquement les rubriques et partitions correspondantes dans le cluster cible si elles n'existent pas, en reproduisant la configuration du cluster source.
Cluster cible : il s'agit de votre cluster Managed Service pour Apache Kafka. Il devient le nouvel emplacement de vos données Kafka, MirrorMaker 2.0 veillant à ce que les sujets et les partitions soient créés pour correspondre à votre environnement source.
Voici un workflow général pour le processus de migration.
Évaluation initiale
Documentez votre configuration Kafka existante, y compris la taille des clusters, les sujets, le débit et les groupes de consommateurs.
Planifiez vos objectifs et votre stratégie de migration, y compris la tolérance aux temps d'arrêt et l'approche de transition.
Estimez les ressources requises pour votre cluster Managed Service pour Apache Kafka.
Préparation
Créez un cluster Managed Service pour Apache Kafka.
Configurez la connectivité réseau entre votre cluster Kafka existant et le cluster Managed Service pour Apache Kafka que vous venez de créer.
Déployez MirrorMaker 2.0 sur une VM Google Cloud .
Exécution de la migration
Configurez MirrorMaker 2.0 pour répliquer les données de votre cluster Kafka existant vers le cluster Managed Service pour Apache Kafka.
Surveillez le processus de réplication à l'aide des métriques MirrorMaker 2.0.
Migrez progressivement les consommateurs et les producteurs vers le nouveau cluster Managed Service pour Apache Kafka.
Validation et transition
Validez l'intégrité des données et les fonctionnalités de l'application dans le cluster Managed Service pour Apache Kafka.
Effectuez la migration finale en redirigeant le trafic vers le cluster Managed Service pour Apache Kafka.
Mettez hors service votre ancien cluster Kafka.
Après la migration
Surveillez en continu les performances de votre cluster Managed Service pour Apache Kafka.
Examiner et mettre à jour la documentation pour refléter les modifications
Minimiser le temps d'arrêt de la migration
Cette section présente quelques points à prendre en compte pour migrer vos données Kafka Open Source vers Managed Service pour Apache Kafka à l'aide de MirrorMaker 2.0. MirrorMaker 2.0 facilite la réplication des données et des décalages, ce qui permet aux consommateurs de reprendre la lecture à partir du bon point dans le nouveau cluster. Toutefois, une planification minutieuse est essentielle pour minimiser les temps d'arrêt pendant le processus de migration. Voici quelques stratégies à envisager :
Déploiements parallèles : pour minimiser les temps d'arrêt lors du passage au nouveau cluster Managed Service pour Apache Kafka, vous pouvez exécuter des instances parallèles de vos applications sur les anciens et nouveaux clusters. Pendant cette transition, désactivez temporairement toutes les actions de votre application qui ne doivent se produire qu'une seule fois par message, comme l'envoi d'une notification. Désactivez ces effets secondaires pour éviter des conséquences indésirables liées au traitement du même message deux fois. Une fois les nouvelles instances entièrement synchronisées, redirigez tout le trafic vers le nouveau cluster et réactivez toutes les fonctionnalités.
Déploiements progressifs : migrez par phases plus petites et plus faciles à gérer, en commençant par les applications moins critiques. Cette approche permet d'isoler les problèmes potentiels et de minimiser l'impact des éventuelles perturbations.
Déploiements bleu et vert : créez une réplique complète de votre environnement de production (vert) à côté de l'environnement existant (bleu). Déplacez progressivement le trafic du bleu vers le vert, ce qui vous permet de tester et de valider le déploiement avant le basculement final. Cette approche minimise les temps d'arrêt, mais nécessite une utilisation accrue des ressources.
Exigences de traitement des messages : comprenez la tolérance de votre application aux messages en double ou manquants, et configurez les consommateurs en conséquence. MirrorMaker 2.0 propose des configurations permettant de gérer la sémantique de diffusion des messages. Par exemple,
sync.group.offsets.enabledest compatible avec la synchronisation des décalages de consommateur. Les consommateurs peuvent utiliser les décalages synchronisés pour reprendre la lecture là où ils l'avaient laissée dans le cluster source. Cela peut éviter la perte de messages ou la réception de trop de doublons.Communication et coordination : une communication efficace avec les équipes chargées des applications est essentielle pour une migration fluide. Définissez des canaux de communication clairs et coordonnez les délais de transition.
Connecter Apache Kafka sur site à Google Cloud
Si votre cluster Apache Kafka source est situé sur site, vous devrez établir une connexion sécurisée entre votre réseau sur site et votre réseau VPC (Virtual Private Cloud) où réside votre cluster Managed Service pour Apache Kafka. Utilisez l'une des options suivantes à partir de Google Cloud.
Cloud VPN : solution économique adaptée aux besoins de bande passante plus faibles ou aux premiers tests de migration. Il crée un tunnel chiffré sur l'Internet public. Pour en savoir plus sur Cloud VPN, consultez la présentation de Cloud VPN.
Cloud Interconnect : fournit une connexion dédiée à bande passante élevée entre votre réseau sur site et Google Cloud. Cette option est idéale pour les déploiements de niveau Enterprise qui nécessitent un débit plus élevé et une latence plus faible. Vous pouvez choisir entre interconnexion dédiée (pour une connexion physique directe) et interconnexion partenaire (connexion via un fournisseur de services compatible). Pour en savoir plus sur la documentation Google Cloud Interconnect, consultez la présentation de Cloud Interconnect.
Lorsque vous créez un cluster Managed Service pour Apache Kafka, vous devez sélectionner au moins un sous-réseau dans votre VPC. Ce sous-réseau fournit les adresses IP que votre cluster utilise pour communiquer avec d'autres ressources de votre VPC, ce qui rend le cluster accessible au sein de votre réseau VPC.
Pour vous connecter de manière sécurisée à votre cluster Managed Service for Apache Kafka depuis des réseaux sur site ou d'autres réseaux VPC, vous pouvez utiliser Private Service Connect (PSC) via Cloud VPN ou Cloud Interconnect. Vous n'avez pas besoin de configurer explicitement les points de terminaison PSC. Lorsque vous sélectionnez un sous-réseau lors de la création d'un cluster, le service Managed Service pour Apache Kafka crée automatiquement les points de terminaison PSC nécessaires. Cela simplifie la configuration du réseau en vous permettant d'accéder à votre cluster à l'aide d'adresses IP internes dans votre VPC, sans avoir à gérer des règles de pare-feu complexes ni des adresses IP publiques.
Pour en savoir plus sur la configuration réseau de Managed Service pour Apache Kafka, consultez Mise en réseau pour Managed Service pour Apache Kafka.
Avant de commencer
Avant de commencer à configurer la migration, vous devez documenter votre configuration Apache Kafka actuelle. Vous en aurez besoin pour calculer les ressources (vCPU, mémoire et stockage, par exemple) requises pour votre nouveau cluster Managed Service pour Apache Kafka. Rassemblez les informations suivantes sur votre environnement Apache Kafka source :
Assurez-vous que la version d'Apache Kafka est la version 2.4.0 ou ultérieure.
Pour vérifier la version de votre cluster Apache Kafka, accédez à votre répertoire d'installation Kafka et exécutez la commande
bin/kafka-topics.sh --version.Identifiez les clusters et les thèmes à migrer.
Identifiez les producteurs et les consommateurs associés à chaque thème.
Identifiez tous les groupes de consommateurs.
Déterminez le débit de messages au niveau du cluster et du sujet.
Déterminez le facteur de réplication pour vos clusters et vos sujets.
Documentez les configurations des consommateurs, en particulier les protocoles de sécurité et toute intégration avec d'autres services Google Cloud .
Pour éviter toute interruption pendant la migration, cartographiez toutes les dépendances d'application liées à votre cluster Kafka source. Avant de migrer votre environnement de production, effectuez une migration test à l'aide d'un cluster non critique dans un environnement de développement. Validez le processus et identifiez les problèmes potentiels. Enfin, créez un plan de rollback complet pour revenir à votre cluster d'origine si nécessaire.
Calculer la taille du cluster de destination
Pour estimer le nombre de vCPU et la taille de la mémoire requis pour votre cluster Managed Service pour Apache Kafka, consultez Planifier la taille de votre cluster Kafka. La configuration des disques et des courtiers est automatique et ne peut pas être ajustée.
Kafka Open Source fournit des métriques JMX. Pour calculer précisément la taille de cluster requise pour votre Managed Service pour Apache Kafka, vous pouvez utiliser les métriques JMX suivantes. Ces métriques sont enregistrées au niveau du courtier. Vous devez agréger les données de tous les courtiers pour calculer le débit du cluster.
kafka.server:type=BrokerTopicMetrics,name=BytesInPerSec: cette métrique indique le débit d'octets entrants des clients pour tous les thèmes. Omettez le paramètretopic={...}pour obtenir le taux global pour tous les thèmes.kafka.server:type=BrokerTopicMetrics,name=BytesOutPerSec: cette métrique indique le débit d'octets sortants vers les clients pour tous les thèmes. Omettez le paramètretopic={...}pour obtenir le taux global.
En surveillant ces métriques JMX sur une période donnée, vous pouvez collecter des points de données pour calculer les éléments suivants :
Débit moyen des données entrantes (Mo/s) : cette métrique représente le débit moyen auquel les données sont ingérées dans le cluster Kafka.
Débit de données maximal en entrée (MB/s) : cette métrique représente le débit le plus élevé auquel les données sont ingérées dans le cluster Kafka.
Données sortantes moyennes, Mo/s : cette métrique représente le taux moyen de données consommées à partir du cluster Kafka.
Débit de données maximal (Mo/s) : cette métrique représente le débit le plus élevé auquel les données sont consommées à partir du cluster Kafka.
Il peut être nécessaire d'effectuer des calculs sur les métriques pour agréger les données et convertir les octets en Mo. À l'aide de ces valeurs calculées, vous pouvez ensuite estimer le taux d'équivalence d'écriture comme suit :
Write-equivalent rate (Avg/Peak) = (total write bandwidth) + (total read bandwidth / 4)
Ce taux équivalent en écriture permet de déterminer la charge d'écriture globale sur le cluster, ce qui est nécessaire pour dimensionner correctement votre cluster Managed Service pour Apache Kafka.
Créer un cluster Managed Service pour Apache Kafka
Un cluster Managed Service pour Apache Kafka est situé dans unGoogle Cloud projet et une région spécifiques. Il est accessible à l'aide d'un ensemble d'adresses IP dans un ou plusieurs sous-réseaux de n'importe quel cloud privé virtuel (VPC).
La taille du cluster est déterminée par le nombre de processeurs et la quantité totale de RAM que vous lui allouez. Dans ce cas, la taille du cluster doit correspondre à celle du cluster Apache Kafka source. Pour savoir comment effectuer ce calcul, consultez Calculer la taille du cluster de destination.
Pour obtenir les autorisations nécessaires pour créer un cluster, demandez à votre administrateur de vous accorder le rôle IAM Administrateur Kafka géré (roles/managedkafka.admin) sur votre projet, ou de l'accorder au compte de service qui crée le cluster. Pour en savoir plus sur l'attribution de rôles, consultez Gérer l'accès aux projets, aux dossiers et aux organisations.
Pour créer un cluster Managed Service pour Apache Kafka, suivez les instructions du guide de démarrage rapide Produire et consommer des messages avec la CLI. La création d'un cluster prend généralement entre 20 et 30 minutes.
Configurer MirrorMaker 2.0 en mode cluster autonome
Pour obtenir un document de validation du concept et un exemple de code montrant comment utiliser MirrorMaker 2.0 et Terraform pour transférer des données Kafka vers Google Cloud, consultez ce dépôt GitHub.
Cette section vous guide dans l'installation et la configuration de MirrorMaker 2.0 en mode cluster autonome sur une VM Google Cloud . Cette configuration vous permet de répliquer les données de votre cluster Apache Kafka existant vers un cluster Managed Service pour Apache Kafka.
Créez une VM sur le même réseau que celui auquel l'accès au cluster Managed Service pour Apache Kafka a été accordé. Utilisez la commande gcloud compute instances create.
gcloud compute instances create VM_NAME\ --zone=ZONE\ [--image=IMAGE | --image-family=IMAGE_FAMILY]\ --image-project=IMAGE_PROJECT\ --machine-type=MACHINE_TYPE
Remplacez les éléments suivants :
VM_NAME: nom de la VM que vous souhaitez créer.ZONE: zone dans laquelle vous souhaitez créer la VM.IMAGEouIMAGE_FAMILY: image ou famille d'images que vous souhaitez utiliser pour la VM.IMAGE_PROJECT: projet dans lequel se trouve l'image.MACHINE_TYPE: type de machine que vous souhaitez utiliser pour la VM.
Pour accéder à la VM que vous venez de créer, vous pouvez utiliser SSH.
Pour en savoir plus sur les connexions SSH, consultez À propos des connexions SSH.
Pour télécharger Kafka, puis l'extraire, exécutez les commandes suivantes dans la fenêtre de terminal de la nouvelle VM :
wget https://downloads.apache.org/kafka/3.7.1/kafka_2.13-3.7.1.tgz tar -xzvf kafka_2.13-3.7.1.tgzTéléchargez Java, extrayez le package, puis définissez le chemin d'accès à Java.
# Download Java wget https://download.java.net/java/GA/jdk11/9/GPL/openjdk-11.0.2_linux-x64_bin.tar.gz # Extract Java tar -xzvf openjdk-11.0.2_linux-x64_bin.tar.gz # Set Java path export PATH=$PATH:/java/jdk-11.0.2/bin/Modifiez le fichier
path/to/kafka/config/mm2.propertieset mettez à jour les propriétés suivantes :clusters = source, target source.bootstrap.servers = <source_kafka_bootstrap_servers> target.bootstrap.servers = <target_kafka_bootstrap_servers> source.security.protocol = SASL_SSL source.sasl.mechanism = PLAIN source.sasl.jaas.config = org.apache.kafka.common.security.plain.PlainLoginModule required username="<source_kafka_username>" password="<source_kafka_password>"; target.security.protocol = SASL_SSL target.sasl.mechanism = PLAIN target.sasl.jaas.config = org.apache.kafka.common.security.plain.PlainLoginModule required username="<target_kafka_username>" password="<target_kafka_password>"; mirrors = source->target source->target.enabled=true topics = .* groups = .* offset.syncs.topic.replication.factor = 3 checkpoints.topic.replication.factor = 3 heartbeats.topic.replication.factor = 3 emit.checkpoints.interval.seconds = 10Remplacez
source_kafka_bootstrap_serversettarget_kafka_bootstrap_serverspar les adresses du serveur d'amorçage de vos clusters Kafka source et cible, respectivement. Vous pouvez obtenir l'adresse du serveur d'amorçage pour Managed Service pour Apache Kafka à l'aide de la commande Google Cloud CLImanaged-kafka clusters describe.Remplacez
source_kafka_usernameetsource_kafka_passwordpar les identifiants de votre cluster Kafka source.Remplacez
target_kafka_usernameettarget_kafka_passwordpar les identifiants de votre cluster Managed Service pour Apache Kafka cible. Pour configurer le nom d'utilisateur et le mot de passe, consultez Authentification SASL/PLAIN.Les paramètres
topics = .\*etgroups = .\*répliquent tous les sujets et groupes de consommateurs. Si nécessaire, vous pouvez modifier ces paramètres pour être plus précis.Le paramètre
offset.syncs.topic.replication.factor = 3définit le facteur de réplication pour le sujet interne utilisé par MirrorMaker 2.0 afin de synchroniser les décalages des clients entre les clusters source et cible. Un facteur de réplication de3signifie que les données de décalage sont répliquées sur trois courtiers du cluster cible, ce qui garantit une disponibilité et une tolérance aux pannes plus élevées.Le paramètre
checkpoints.topic.replication.factor = 3définit le facteur de réplication pour un autre sujet interne utilisé par MirrorMaker 2.0 pour stocker les points de contrôle. Les points de contrôle aident MirrorMaker 2.0 à suivre sa progression et à reprendre la réplication au bon endroit en cas d'échec ou de redémarrage.Le paramètre
heartbeats.topic.replication.factor = 3définit le facteur de réplication pour le sujet interne utilisé par MirrorMaker 2.0 pour envoyer des pulsations. Les pulsations indiquent que le processus MirrorMaker 2.0 est actif et en cours d'exécution. Un facteur de réplication plus élevé garantit que ces pulsations sont stockées de manière fiable et peuvent être utilisées pour surveiller l'état du processus de réplication.Le paramètre
emit.checkpoints.interval.seconds = 10contrôle la fréquence à laquelle MirrorMaker 2.0 émet des points de contrôle. Dans ce cas, les points de contrôle sont émis toutes les 10 secondes. Cette fréquence permet de trouver un équilibre entre le suivi de la progression et la minimisation de la surcharge liée à l'écriture des points de contrôle.
Démarrez MirrorMaker 2.0. Utilisez le script
connect-mirror-maker.shpour lancer le processus.Le script démarre MirrorMaker 2.0 en mode autonome et commence à répliquer les données de votre cluster Kafka source vers votre cluster Managed Service pour Apache Kafka.
Autres points à prendre en compte :
Mise en réseau : assurez-vous que votre VM Google Cloud dispose d'une connectivité réseau à la fois vers votre cluster Kafka source et vers votre cluster Managed Service pour Apache Kafka cible. Si votre cluster source est sur site, vous devrez peut-être configurer un VPN ou Interconnect.
Sécurité : configurez les protocoles de sécurité et les règles de pare-feu appropriés pour sécuriser votre instance MirrorMaker 2.0 et vos clusters Kafka.
En suivant ces étapes, vous pourrez installer et configurer MirrorMaker 2.0 en mode cluster autonome sur une VM Google Cloud pour faciliter la migration de vos données Kafka vers Managed Service pour Apache Kafka.
Surveillance
Surveillez le processus MirrorMaker 2.0 pour vous assurer qu'il s'exécute correctement et qu'il réplique les données comme prévu. Vous pouvez utiliser les métriques intégrées de MirrorMaker 2 ou d'autres outils de surveillance. Après avoir migré vos applications, surveillez les éléments suivants pour vérifier que la migration a réussi :
Débits en aval : assurez-vous qu'il n'y a pas de changements importants dans les débits en aval. Par exemple, si vous utilisez Dataflow en aval, le débit et les métriques liées à Kafka doivent rester cohérents.
Utilisation du processeur et de la mémoire : surveillez l'utilisation du processeur et de la mémoire de votre cluster Managed Service pour Apache Kafka à l'aide de Cloud Monitoring. Idéalement, l'utilisation doit rester inférieure à 75 % pour garantir des performances optimales.
Journaux d'erreurs : vérifiez régulièrement Cloud Logging pour détecter les journaux d'erreurs liés à votre cluster Managed Service pour Apache Kafka ou à vos applications. Corrigez rapidement les erreurs pour éviter toute interruption.
Limites
- MirrorMaker 2.0 nécessite que votre cluster Apache Kafka source soit en version 2.4.0 ou ultérieure.