
사용
explore: explore_name {
aggregate_table: table_name {
query: {
dimensions: [dimension1, dimension2, ... ]
measures: [measure1, measure2, ... ]
sorts: [field1: asc, field2: desc, ... ]
filters: [field1: "value1", field2: "value2", ... ]
timezone: timezone
}
materialization: {
...
}
}
...
}
|
계층 구조
aggregate_table |
기본값
없음
수락
집계 테이블의 이름, 테이블을 정의하는 query 하위 매개변수, 테이블의 지속성 전략을 정의하는 materialization 하위 매개변수
특별 규칙
|
정의
aggregate_table 매개변수는 데이터베이스의 큰 테이블에 필요한 쿼리 수를 최소화하는 집계 테이블을 만드는 데 사용됩니다.
Looker는 집계 인식 로직을 사용하여 데이터베이스에서 정확성을 유지하면서도 쿼리를 실행하는 데 사용할 수 있는 가장 작고 효율적인 집계 테이블을 찾습니다. (집계 테이블 생성 개요 및 전략은 집계 인식 문서 페이지를 참고하세요.)
데이터베이스에 있는 매우 큰 테이블의 경우 다양한 속성 조합으로 그룹화된 더 작은 집계 데이터 테이블을 만들 수 있습니다. 집계 테이블은 원본 대형 테이블 대신 가능한 경우 Looker가 쿼리에 사용할 수 있는 롤업 또는 요약 테이블 역할을 합니다.
집계 테이블을 만든 후 Explore에서 쿼리를 실행하여 Looker가 어느 집계 테이블을 사용하는지 알아볼 수 있습니다. 자세한 내용은 집계 인식 문서 페이지의 쿼리에 사용할 집계 테이블 확인 섹션을 참고하세요.
집계 테이블이 사용되지 않는 일반적인 이유는 집계 인식 문서 페이지의 문제 해결 섹션을 참고하세요.
LookML에서 집계 테이블 정의
각 aggregate_table 매개변수에는 지정된 explore 내에서 고유한 이름이 있어야 합니다.
aggregate_table 매개변수에는 query 및 materialization 하위 매개변수가 있습니다.
query
query 매개변수는 사용할 측정기준과 측정값을 포함하여 총괄 표의 쿼리를 정의합니다. query 파라미터에는 다음 하위 파라미터가 포함됩니다.
| 파라미터 이름 | 설명 | 예 |
|---|---|---|
dimensions |
집계 테이블에 포함할 Explore의 측정기준을 쉼표로 구분한 목록입니다. dimensions 필드는 다음 형식을 사용합니다. dimensions: [dimension1, dimension2, ...]
이 목록의 각 측정기준은 쿼리의 Explore에 대한 뷰 파일에서 dimension로 정의되어야 합니다. Explore 쿼리에서 filter 필드로 정의된 필드를 포함하려면 집계 테이블 쿼리의 filters 목록에 추가하면 됩니다.
|
dimensions: [orders.created_month, orders.country] |
measures |
총괄 표에 포함할 Explore의 측정값의 쉼표로 구분된 목록입니다. measures 필드는 다음 형식을 사용합니다. measures: [measure1, measure2, ...]
집계 인식에서 지원되는 측정 유형에 대한 자세한 내용은 집계 인식 문서 페이지의 측정 유형 요소 섹션을 참고하세요.
|
measures: [orders.count] |
filters |
선택적으로 query에 필터를 추가합니다. 집계 테이블을 생성하는 SQL의 WHERE 절에 필터가 추가됩니다.
filters 필드는 다음 형식을 사용합니다. filters: [field1: "value1", field2: "value2", ...]
필터로 인해 집계 테이블이 사용되지 않는 방법에 관한 자세한 내용은 집계 인식 문서 페이지의 필터 요소 섹션을 참고하세요. |
filters: [orders.country: "United States", orders.state: "California"]
|
sorts |
선택적으로 query의 정렬 필드와 정렬 방향 (오름차순 또는 내림차순)을 지정합니다.
sorts 필드는 다음 형식을 사용합니다. sorts: [field1: asc|desc, field2: asc|desc, ...]
|
[orders.country: asc, orders.state: desc] |
timezone |
query의 시간대를 설정합니다. 시간대를 지정하지 않으면 집계 테이블은 시간대를 변환하지 않으며, 대신 데이터베이스 시간대를 사용합니다.
집계 테이블이 쿼리 소스로 사용되도록 시간대를 설정하는 방법은 집계 인식 문서 페이지의 시간대 요소 섹션을 참고하세요.
IDE에서 timezone 매개변수를 입력하면 IDE에서 시간대 값을 자동 제안합니다. IDE는 빠른 도움말 패널에 지원되는 시간대 값 목록도 표시합니다. |
timezone: America/Los_Angeles |
materialization
materialization 매개변수는 집계 테이블의 지속성 전략과 SQL 언어에서 지원할 수 있는 분산, 파티셔닝, 색인, 클러스터링의 기타 옵션을 지정합니다.
집계 인식에 액세스하려면 데이터베이스에 집계 테이블이 유지되어야 합니다. 총괄 표의 materialization 파라미터에는 지속성 전략을 지정하는 다음 하위 매개변수 중 하나가 있어야 합니다.
datagroup_triggersql_trigger_valuepersist_for(권장하지 않음)
또한 SQL 언어에 따라 집계 테이블에 다음 materialization 하위 매개변수가 지원될 수 있습니다.
증분 집계 테이블을 만들려면 다음 materialization 하위 매개변수를 사용하세요.
datagroup_trigger
datagroup_trigger 파라미터를 사용하여 모델 파일에 정의된 기존 데이터 그룹을 기반으로 집계 테이블의 재생성을 트리거합니다.
explore: event {
aggregate_table: monthly_orders {
materialization: {
datagroup_trigger: order_datagroup
}
query: {
...
}
}
...
}
sql_trigger_value
sql_trigger_value 매개변수를 사용하여 제공된 SQL 문을 기반으로 집계 테이블의 재생성을 트리거합니다. SQL 문의 결과가 이전 값과 다른 경우 테이블이 다시 생성됩니다. 이 sql_trigger_value 문은 날짜가 변경되면 재생성을 트리거합니다.
explore: event {
aggregate_table: monthly_orders {
materialization: {
sql_trigger_value: SELECT CURDATE() ;;
}
query: {
...
}
}
...
}
persist_for
persist_for 매개변수는 집계 테이블에서도 지원됩니다. 하지만 persist_for 전략은 집계된 인지도에 최적의 실적을 제공하지 않을 수 있습니다. 이는 사용자가 persist_for 테이블을 사용하는 쿼리를 실행할 때 Looker가 persist_for 설정에 따라 테이블의 기간을 확인하기 때문입니다. 테이블이 persist_for 설정보다 오래된 경우 쿼리가 실행되기 전에 테이블이 재생성됩니다. 연령이 persist_for 설정보다 작으면 기존 테이블이 사용됩니다. 따라서 사용자가 persist_for 시간 내에 쿼리를 실행하지 않으면 집계 인식을 위해 집계 테이블을 사용하기 전에 다시 빌드해야 합니다.
explore: event {
aggregate_table: monthly_orders {
materialization: {
persist_for: "90 minutes"
}
query: {
...
}
}
...
}
제한사항을 이해하고 persist_for 구현에 대한 구체적인 사용 사례가 없는 한, 집계 테이블의 지속성 전략으로 datagroup_trigger 또는 sql_trigger_value를 사용하는 것이 좋습니다.
cluster_keys
cluster_keys 매개변수를 사용하면 BigQuery 또는 Snowflake의 파티션을 나눈 테이블에 클러스터링된 열을 추가할 수 있습니다. 클러스터링은 클러스터링된 열의 값을 기준으로 파티션의 데이터를 정렬하고 클러스터링된 열을 최적 크기의 스토리지 블록으로 정리합니다.
자세한 내용은 cluster_keys 파라미터 문서 페이지를 참조하세요.
distribution
distribution 파라미터를 사용하면 집계 테이블에서 분포 키를 적용할 열을 지정할 수 있습니다. distribution는 Redshift 및 Aster 데이터베이스에서만 작동합니다. MySQL, Postgres와 같은 다른 SQL 언어의 경우 indexes을 대신 사용하세요.
자세한 내용은 distribution 파라미터 문서 페이지를 참조하세요.
distribution_style
distribution_style 매개변수를 사용하면 집계 테이블의 쿼리가 Redshift 데이터베이스의 노드에 분산되는 방식을 지정할 수 있습니다.
distribution_style: all는 모든 행이 각 노드에 완전히 복사되었음을 나타냅니다.distribution_style: even는 균등한 분산을 지정하므로 행이 라운드 로빈 방식으로 여러 노드에 분산됩니다.
자세한 내용은 distribution_style 파라미터 문서 페이지를 참조하세요.
indexes
indexes 매개변수를 사용하면 집계 테이블의 열에 색인을 적용할 수 있습니다.
자세한 내용은 indexes 파라미터 문서 페이지를 참조하세요.
partition_keys
partition_keys 매개변수는 총괄 표가 파티션으로 나뉘는 열의 배열을 정의합니다. partition_keys는 열을 파티션으로 나눌 수 있는 데이터베이스 언어를 지원합니다. 파티션으로 나눈 열에서 필터링된 쿼리가 실행되면 데이터베이스는 전체 테이블을 스캔하는 대신 필터링된 데이터가 포함된 파티션만 스캔합니다. partition_keys는 Presto 및 BigQuery 언어에서만 지원됩니다.
자세한 내용은 partition_keys 파라미터 문서 페이지를 참조하세요.
publish_as_db_view
publish_as_db_view 파라미터를 사용하면 Looker 외부에서 쿼리할 총괄 표를 플래그할 수 있습니다. publish_as_db_view이 yes로 설정된 총괄 표의 경우 Looker는 총괄 표의 데이터베이스에 안정적인 데이터베이스 뷰를 만듭니다. 안정적인 데이터베이스 뷰는 데이터베이스 자체에 생성되므로 Looker 외부에서 쿼리할 수 있습니다.
자세한 내용은 publish_as_db_view 파라미터 문서 페이지를 참조하세요.
sortkeys
sortkeys 매개변수를 사용하면 총괄 표에서 일반 정렬 키를 적용할 열을 하나 이상 지정할 수 있습니다.
자세한 내용은 sortkeys 파라미터 문서 페이지를 참조하세요.
increment_key
언어가 PDT를 지원하는 경우 프로젝트에 증분 PDT를 만들 수 있습니다. 증분 PDT는 테이블 전체를 다시 빌드하는 대신 Looker가 테이블에 새 데이터를 추가하여 빌드하는 영구 파생 테이블 (PDT)입니다. 자세한 내용은 증분 PDT 문서 페이지를 참고하세요.
집계 테이블은 PDT의 한 유형이며 increment_key 매개변수를 추가하여 증분식으로 빌드할 수 있습니다. increment_key 매개변수는 새 데이터를 쿼리하여 집계 테이블에 추가해야 하는 시간 증분값을 지정합니다.
자세한 내용은 increment_key 파라미터 문서 페이지를 참조하세요.
increment_offset
increment_offset 매개변수는 집계 테이블에 데이터를 추가할 때 다시 빌드되는 이전 기간 수 (증분 키의 세분성 적용)를 정의합니다. increment_offset 파라미터는 증분 PDT 및 집계 테이블의 선택사항입니다.
자세한 내용은 increment_offset 파라미터 문서 페이지를 참조하세요.
Explore에서 집계 테이블 LookML 가져오기
Looker 개발자는 단축키로 Explore 쿼리를 사용하여 집계 테이블을 만든 다음 LookML을 LookML 프로젝트에 복사할 수 있습니다.
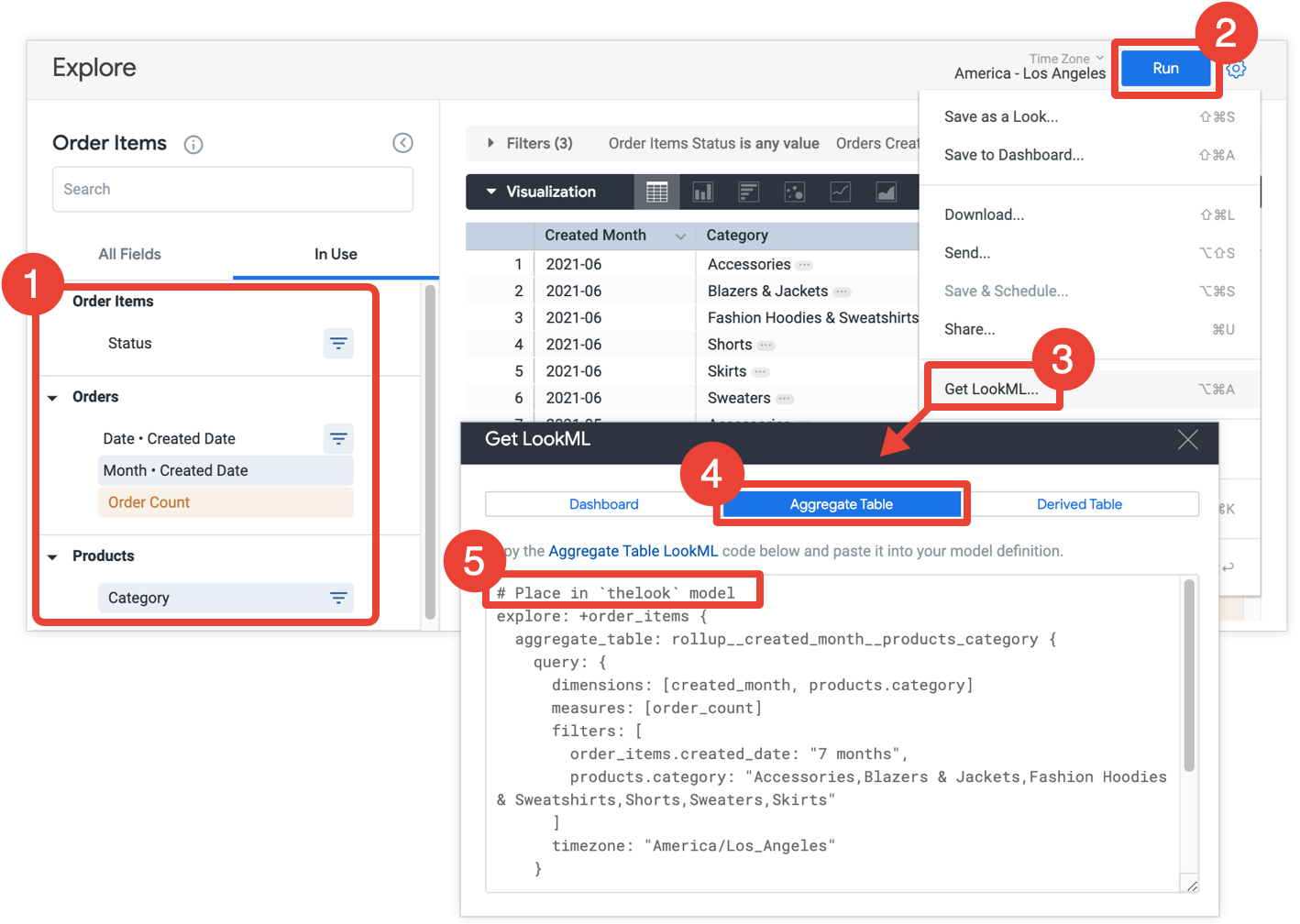
- Explore에서 집계 테이블에 포함할 모든 필드와 필터를 선택합니다.
- 실행을 클릭하여 결과를 확인합니다.
- Explore의 톱니바퀴 메뉴에서 LookML 가져오기를 선택합니다. 이 옵션은 Looker 개발자만 사용할 수 있습니다.
- 집계 표 탭을 클릭합니다.
- Looker는 Explore에 총괄 표를 추가하는 Explore 리파인먼트의 LookML을 제공합니다. LookML을 복사하여 Explore 리파인먼트 앞에 있는 주석에 표시된 연결된 모델 파일에 붙여넣습니다. Explore가 모델 파일이 아닌 Explore 파일에 정의된 경우 모델 파일 대신 Explore 파일에 리파인먼트를 추가할 수 있습니다. 어느 위치에 추가해도 됩니다.
총괄 표 LookML을 수정해야 하는 경우 이 페이지의 LookML에서 총괄 표 정의 섹션에 설명된 파라미터를 사용하여 수정할 수 있습니다. 원래 Explore 쿼리에 대한 적용 가능성을 변경하지 않고 집계 테이블의 이름을 바꿀 수 있습니다. 하지만 집계 테이블을 다른 방식으로 변경하면 Looker가 Explore 쿼리에 집계 테이블을 사용하지 못할 수 있습니다. 집계 테이블이 집계 인식에 사용되도록 최적화하는 팁은 집계 인식 문서 페이지의 집계 테이블 설계 섹션을 참고하세요.
대시보드에서 집계 테이블 LookML 가져오기
Looker 개발자를 위한 또 다른 옵션은 대시보드의 모든 타일에 대한 집계 테이블 LookML을 가져온 다음 LookML을 LookML 프로젝트에 복사하는 것입니다.
집계 테이블을 만들면 특히 대규모 데이터 세트를 쿼리하는 타일의 경우 대시보드 성능을 대폭 개선할 수 있습니다.
develop 권한이 있는 경우 대시보드를 열고 대시보드의 점 3개 메뉴에서 LookML 가져오기를 선택한 다음 집계 테이블 탭을 선택하여 대시보드의 집계 테이블을 만드는 LookML을 가져올 수 있습니다.
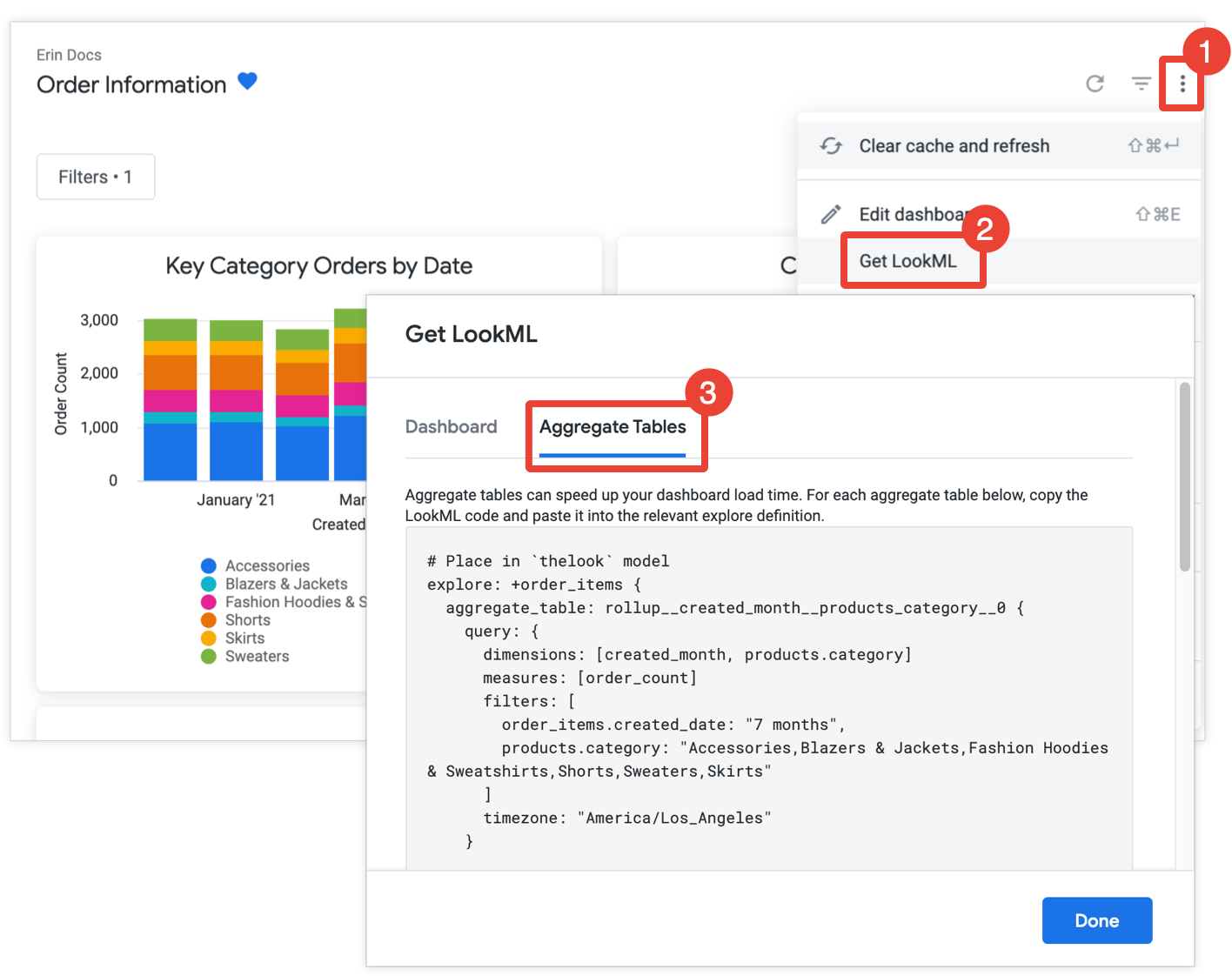
집계 인식을 사용하여 아직 최적화되지 않은 각 타일에 대해 Looker는 Explore에 총괄 표를 추가하는 Explore 리파인먼트의 LookML을 제공합니다. 대시보드에 동일한 Explore의 타일이 여러 개 포함된 경우 Looker는 모든 총괄 표를 단일 Explore 리파인먼트에 배치합니다. 생성된 총괄 표 수를 줄이기 위해 Looker는 생성된 총괄 표를 두 개 이상의 타일에 사용할 수 있는지 확인하고, 사용할 수 있으면 더 적은 수의 타일에 사용할 수 있는 중복된 총괄 표를 삭제합니다.
각 Explore 상세검색을 복사하여 Explore 상세검색 앞에 있는 주석에 표시된 연결된 모델 파일에 붙여넣습니다. Explore가 모델 파일이 아닌 별도의 Explore 파일에 정의된 경우 모델 파일 대신 Explore 파일에 상세검색을 추가할 수 있습니다. 어느 위치에 추가해도 됩니다.
대시보드 필터가 타일에 적용되면 Looker는 타일의 총괄 표에 필터 측정기준을 추가하여 타일에 총괄 표를 사용할 수 있도록 합니다. 이는 쿼리의 필터가 집계 테이블에서 측정기준으로 사용 가능한 필드를 참조하는 경우에만 집계 테이블을 쿼리에 사용할 수 있기 때문입니다. 자세한 내용은 집계 인식 문서 페이지를 참고하세요.
총괄 표 LookML을 수정해야 하는 경우 이 페이지의 LookML에서 총괄 표 정의 섹션에 설명된 파라미터를 사용하여 수정할 수 있습니다. 원본 대시보드 타일에 대한 적용 가능성을 변경하지 않고 집계 테이블의 이름을 바꿀 수 있지만 집계 테이블의 다른 변경사항은 Looker가 대시보드에 집계 테이블을 사용하는 기능에 영향을 줄 수 있습니다. 집계 테이블이 집계 인식에 사용되도록 최적화하는 팁은 집계 인식 문서 페이지의 집계 테이블 설계 섹션을 참고하세요.
예
다음 예에서는 event Explore에 대한 monthly_orders 집계 테이블을 만듭니다. 집계 테이블은 월별 주문 수를 만듭니다. Looker는 월별 세부사항을 활용할 수 있는 주문 수 쿼리(예: 연간, 분기별, 월별 주문 수 쿼리)에 집계 테이블을 사용합니다.
총괄 표는 데이터 그룹 orders_datagroup를 사용하여 지속성으로 설정됩니다. 또한 총괄 표는 publish_as_db_view: yes로 정의되므로 Looker는 총괄 표의 데이터베이스에 안정적인 데이터베이스 뷰를 만듭니다.
집계 테이블 정의는 다음과 같습니다.
explore: event {
aggregate_table: monthly_orders {
materialization: {
datagroup_trigger: orders_datagroup
publish_as_db_view: yes
}
query: {
dimensions: [orders.created_month]
measures: [orders.count]
filters: [orders.created_date: "1 year", orders.status: "fulfilled"]
timezone: America/Los_Angeles
}
}
}
고려사항
집계 테이블을 전략적으로 만드는 방법에 관한 팁은 집계 인식 문서 페이지의 집계 테이블 설계 섹션을 참고하세요.
집계 인식을 위한 언어 지원
집계 인식을 사용할 수 있는지 여부는 Looker 연결에서 사용하는 데이터베이스 언어에 따라 다릅니다. 최신 버전의 Looker에서는 다음 언어가 집계 인식을 지원합니다.
| 언어 | 지원 여부 |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13+ | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |