
Cette page explique comment migrer votre configuration de passerelle GKE Inference de l'API v1alpha2 en preview vers l'API v1 disponible de manière générale.
Ce document est destiné aux administrateurs de plate-forme et aux spécialistes de la mise en réseau qui utilisent la version v1alpha2 de GKE Inference Gateway et souhaitent passer à la version 1 pour profiter des dernières fonctionnalités.
Avant de commencer la migration, assurez-vous de bien connaître les concepts et le déploiement de la passerelle d'inférence GKE. Nous vous recommandons de consulter Déployer GKE Inference Gateway.
Avant de commencer
Avant de commencer la migration, déterminez si vous devez suivre ce guide.
Rechercher les API v1alpha2 existantes
Pour vérifier si vous utilisez l'API v1alpha2 GKE Inference Gateway, exécutez les commandes suivantes :
kubectl get inferencepools.inference.networking.x-k8s.io --all-namespaces
kubectl get inferencemodels.inference.networking.x-k8s.io --all-namespaces
Le résultat de ces commandes détermine si vous devez migrer :
- Si l'une ou l'autre commande renvoie une ou plusieurs ressources
InferencePoolouInferenceModel, vous utilisez l'APIv1alpha2et devez suivre ce guide. - Si les deux commandes renvoient
No resources found, vous n'utilisez pas l'APIv1alpha2. Vous pouvez procéder à une nouvelle installation de la passerelle d'inférencev1.
Chemins de migration
Deux options s'offrent à vous pour migrer de v1alpha2 vers v1 :
- Migration simple (avec temps d'arrêt) : ce chemin est plus rapide et plus simple, mais entraîne un bref temps d'arrêt. Il s'agit de la méthode recommandée si vous n'avez pas besoin d'une migration sans temps d'arrêt.
- Migration sans temps d'arrêt : ce chemin est destiné aux utilisateurs qui ne peuvent pas se permettre d'interrompre le service. Il s'agit d'exécuter les piles
v1alpha2etv1côte à côte et de déplacer progressivement le trafic.
Migration simple (avec temps d'arrêt)
Cette section explique comment effectuer une migration simple avec temps d'arrêt.
Supprimer les ressources
v1alpha2existantes : pour supprimer les ressourcesv1alpha2, choisissez l'une des options suivantes :Option 1 : Désinstaller à l'aide de Helm
helm uninstall HELM_PREVIEW_INFERENCEPOOL_NAMEOption 2 : Supprimer manuellement les ressources
Si vous n'utilisez pas Helm, supprimez manuellement toutes les ressources associées à votre déploiement
v1alpha2:- Modifiez ou supprimez
HTTPRoutepour supprimerbackendRefqui pointe versv1alpha2InferencePool. - Supprimez le
InferencePool, toutes les ressourcesInferenceModelqui y font référence, ainsi que le déploiement et le service EPP (Endpoint Picker) correspondants.v1alpha2
Une fois toutes les ressources personnalisées
v1alpha2supprimées, supprimez les définitions de ressources personnalisées (CRD) de votre cluster :kubectl delete -f https://github.com/kubernetes-sigs/gateway-api-inference-extension/releases/download/v0.3.0/manifests.yaml- Modifiez ou supprimez
Installez les ressources v1 : après avoir nettoyé les anciennes ressources, installez la passerelle d'inférence GKE Inference.
v1Ce processus implique les actions suivantes :- Installez les nouvelles définitions de ressources personnalisées (CRD)
v1. - Créez une
v1InferencePoolet les ressourcesInferenceObjectivecorrespondantes. La ressourceInferenceObjectiveest toujours définie dans l'APIv1alpha2. - Créez un
HTTPRoutequi redirige le trafic vers votre nouveauv1InferencePool.
- Installez les nouvelles définitions de ressources personnalisées (CRD)
Vérifiez le déploiement : après quelques minutes, vérifiez que votre nouvelle pile
v1diffuse correctement le trafic.Vérifiez que l'état de la passerelle est
PROGRAMMED:kubectl get gateway -o wideLe résultat devrait ressembler à ceci :
NAME CLASS ADDRESS PROGRAMMED AGE inference-gateway gke-l7-regional-external-managed <IP_ADDRESS> True 10mVérifiez le point de terminaison en envoyant une requête :
IP=$(kubectl get gateway/inference-gateway -o jsonpath='{.status.addresses[0].value}') PORT=80 curl -i ${IP}:${PORT}/v1/completions -H 'Content-Type: application/json' -d '{"model": "<var>YOUR_MODEL</var>","prompt": "<var>YOUR_PROMPT</var>","max_tokens": 100,"temperature": 0}'Assurez-vous de recevoir une réponse positive avec un code de réponse
200.
Migration sans temps d'arrêt
Ce chemin de migration est conçu pour les utilisateurs qui ne peuvent pas se permettre d'interrompre le service. Le schéma suivant illustre comment GKE Inference Gateway facilite la diffusion de plusieurs modèles d'IA générative, un aspect clé d'une stratégie de migration sans temps d'arrêt.
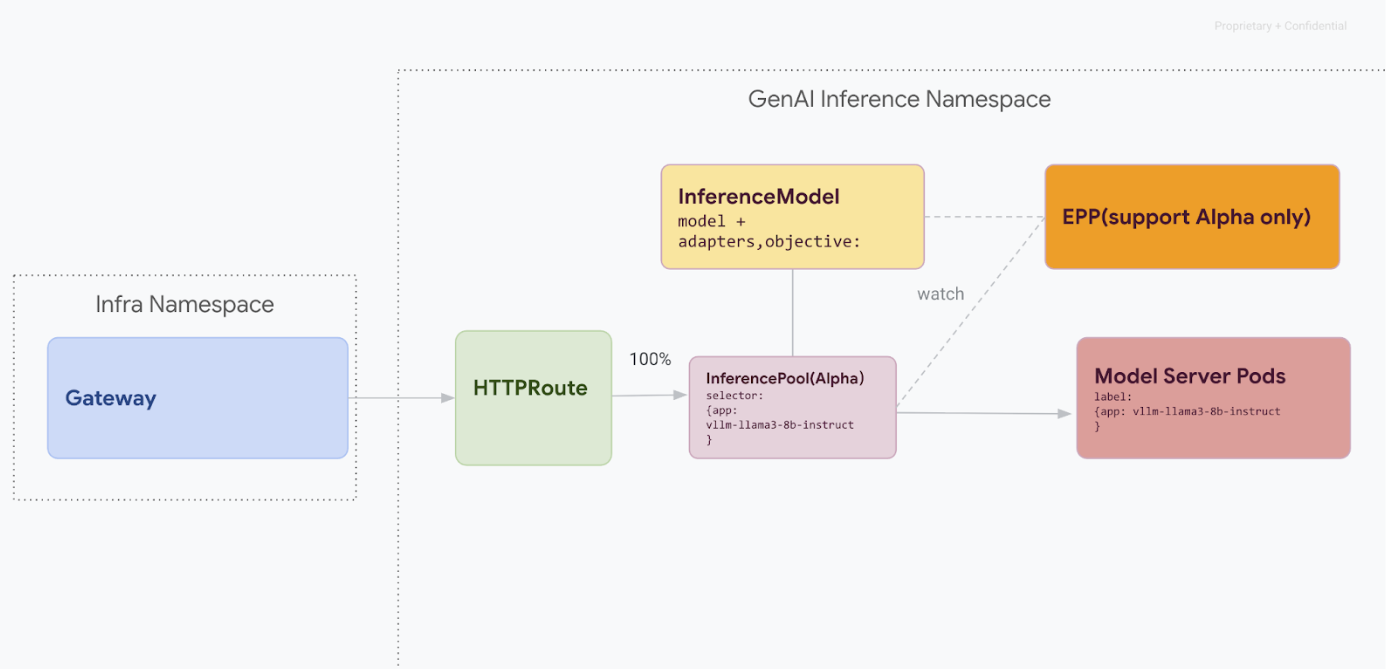
Distinguer les versions d'API avec kubectl
Lors de la migration sans temps d'arrêt, les CRD v1alpha2 et v1 sont installés sur votre cluster. Cela peut créer une ambiguïté lors de l'utilisation de kubectl pour interroger les ressources InferencePool. Pour vous assurer d'interagir avec la bonne version, vous devez utiliser le nom complet de la ressource :
Pour
v1alpha2:kubectl get inferencepools.inference.networking.x-k8s.ioPour
v1:kubectl get inferencepools.inference.networking.k8s.io
L'API v1 fournit également un nom court pratique, infpool, que vous pouvez utiliser pour interroger spécifiquement les ressources v1 :
kubectl get infpool
Étape 1 : Déploiement côte à côte de la version 1
À cette étape, vous déployez la nouvelle pile InferencePool v1 aux côtés de la pile v1alpha2 existante, ce qui permet une migration sûre et progressive.
Une fois toutes les étapes de cette phase terminées, vous disposez de l'infrastructure suivante, illustrée dans le diagramme ci-dessous :
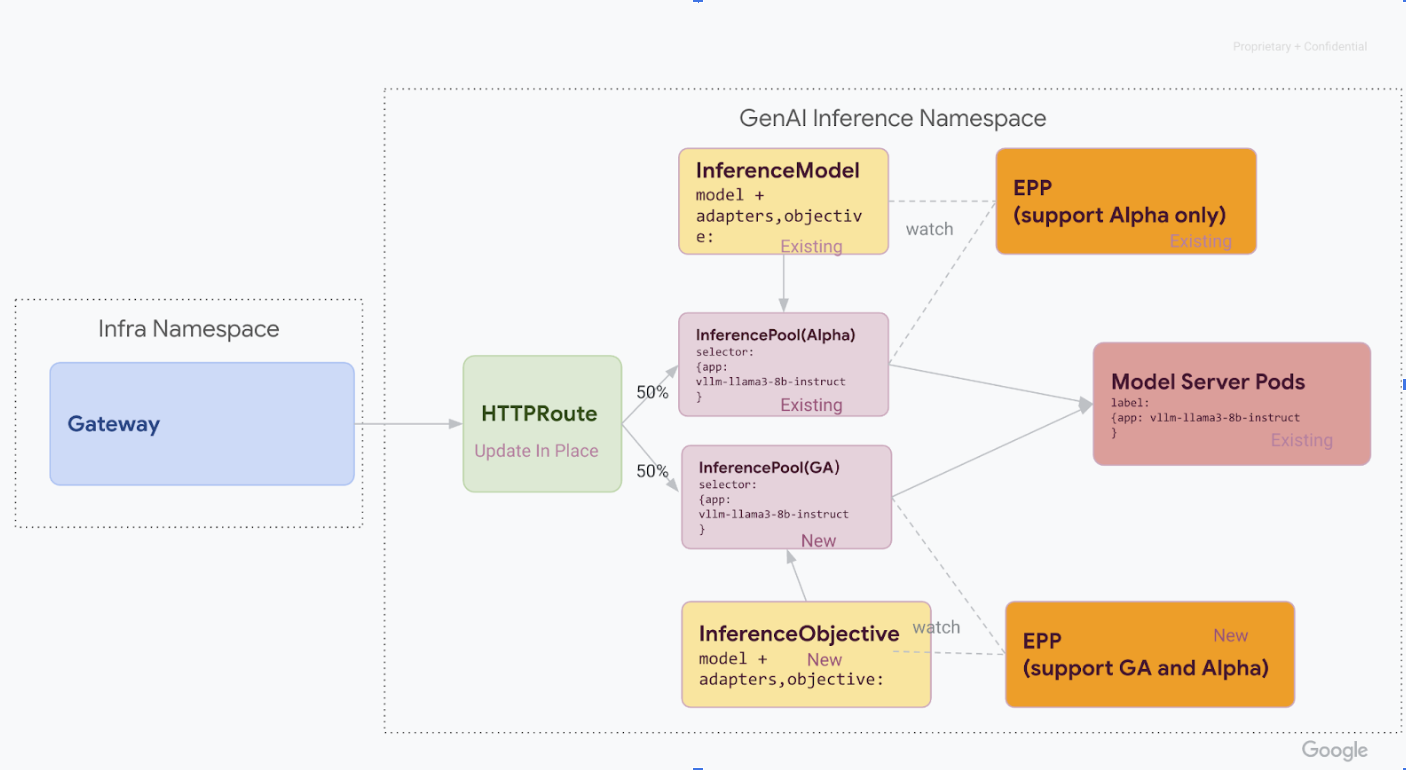
Installez les définitions de ressources personnalisées (CRD) nécessaires dans votre cluster GKE :
- Pour les versions GKE antérieures à
1.34.0-gke.1626000, exécutez la commande suivante pour installer les CRD v1InferencePoolet alphaInferenceObjective:
kubectl apply -f https://github.com/kubernetes-sigs/gateway-api-inference-extension/releases/download/v1.0.0/manifests.yaml- Pour les versions
1.34.0-gke.1626000ou ultérieures de GKE, n'installez que la CRD alphaInferenceObjectiveen exécutant la commande suivante :
kubectl apply -f https://github.com/kubernetes-sigs/gateway-api-inference-extension/raw/v1.0.0/config/crd/bases/inference.networking.x-k8s.io_inferenceobjectives.yaml- Pour les versions GKE antérieures à
Installez
v1 InferencePool.Utilisez Helm pour installer un nouveau
v1 InferencePoolavec un nom de version distinct, tel quevllm-llama3-8b-instruct-ga. LeInferencePooldoit cibler les mêmes pods Model Server que leInferencePoolalpha à l'aide deinferencePool.modelServers.matchLabels.app.Pour installer
InferencePool, utilisez la commande suivante :helm install vllm-llama3-8b-instruct-ga \ --set inferencePool.modelServers.matchLabels.app=MODEL_SERVER_DEPLOYMENT_LABEL \ --set provider.name=gke \ --version RELEASE \ oci://registry.k8s.io/gateway-api-inference-extension/charts/inferencepoolCréez des ressources
v1alpha2 InferenceObjective.Pour migrer vers la version 1.0 de l'extension d'inférence de l'API Gateway, nous devons également migrer de l'API alpha
InferenceModelvers la nouvelle APIInferenceObjective.Appliquez le fichier YAML suivant pour créer les ressources
InferenceObjective:kubectl apply -f - <<EOF --- apiVersion: inference.networking.x-k8s.io/v1alpha2 kind: InferenceObjective metadata: name: food-review spec: priority: 2 poolRef: group: inference.networking.k8s.io name: vllm-llama3-8b-instruct-ga --- apiVersion: inference.networking.x-k8s.io/v1alpha2 kind: InferenceObjective metadata: name: base-model spec: priority: 2 poolRef: group: inference.networking.k8s.io name: vllm-llama3-8b-instruct-ga --- EOF
Étape 2 : Transfert du trafic
Une fois les deux piles en cours d'exécution, vous pouvez commencer à transférer le trafic de v1alpha2 vers v1 en mettant à jour HTTPRoute pour répartir le trafic. Cet exemple montre une répartition à 50/50.
Mettez à jour HTTPRoute pour la répartition du trafic.
Pour mettre à jour
HTTPRoutepour la répartition du trafic, exécutez la commande suivante :kubectl apply -f - <<EOF --- apiVersion: gateway.networking.k8s.io/v1 kind: HTTPRoute metadata: name: llm-route spec: parentRefs: - group: gateway.networking.k8s.io kind: Gateway name: inference-gateway rules: - backendRefs: - group: inference.networking.x-k8s.io kind: InferencePool name: vllm-llama3-8b-instruct-preview weight: 50 - group: inference.networking.k8s.io kind: InferencePool name: vllm-llama3-8b-instruct-ga weight: 50 --- EOFVérifiez et surveillez.
Après avoir appliqué les modifications, surveillez les performances et la stabilité de la nouvelle pile
v1. Vérifiez que la passerelleinference-gatewaya l'étatPROGRAMMEDTRUE.
Étape 3 : Finalisation et nettoyage
Une fois que vous avez vérifié que v1 InferencePool est stable, vous pouvez y rediriger tout le trafic et mettre hors service les anciennes ressources v1alpha2.
Redirigez 100 % du trafic vers
v1 InferencePool.Pour transférer 100 % du trafic vers
v1 InferencePool, exécutez la commande suivante :kubectl apply -f - <<EOF --- apiVersion: gateway.networking.k8s.io/v1 kind: HTTPRoute metadata: name: llm-route spec: parentRefs: - group: gateway.networking.k8s.io kind: Gateway name: inference-gateway rules: - backendRefs: - group: inference.networking.k8s.io kind: InferencePool name: vllm-llama3-8b-instruct-ga weight: 100 --- EOFEffectuez la validation finale.
Après avoir redirigé tout le trafic vers la pile
v1, vérifiez qu'elle gère tout le trafic comme prévu.Vérifiez que l'état de la passerelle est
PROGRAMMED:kubectl get gateway -o wideLe résultat devrait ressembler à ceci :
NAME CLASS ADDRESS PROGRAMMED AGE inference-gateway gke-l7-regional-external-managed <IP_ADDRESS> True 10mVérifiez le point de terminaison en envoyant une requête :
IP=$(kubectl get gateway/inference-gateway -o jsonpath='{.status.addresses[0].value}') PORT=80 curl -i ${IP}:${PORT}/v1/completions -H 'Content-Type: application/json' -d '{ "model": "YOUR_MODEL, "prompt": YOUR_PROMPT, "max_tokens": 100, "temperature": 0 }'Assurez-vous de recevoir une réponse positive avec un code de réponse
200.
Nettoyez les ressources v1alpha2.
Après avoir confirmé que la pile
v1est entièrement opérationnelle, supprimez les anciennes ressourcesv1alpha2en toute sécurité.Vérifiez s'il reste des ressources
v1alpha2.Maintenant que vous avez migré vers l'API
v1InferencePool, vous pouvez supprimer les anciens CRD sans risque. Vérifiez s'il existe des API v1alpha2 pour vous assurer que vous n'utilisez plus de ressourcesv1alpha2. S'il vous en reste, vous pouvez poursuivre le processus de migration pour ceux-ci.Supprimez les CRD
v1alpha2.Une fois toutes les ressources personnalisées
v1alpha2supprimées, supprimez les définitions de ressources personnalisées (CRD) de votre cluster :kubectl delete -f https://github.com/kubernetes-sigs/gateway-api-inference-extension/releases/download/v0.3.0/manifests.yamlUne fois toutes les étapes terminées, votre infrastructure devrait ressembler au diagramme suivant :
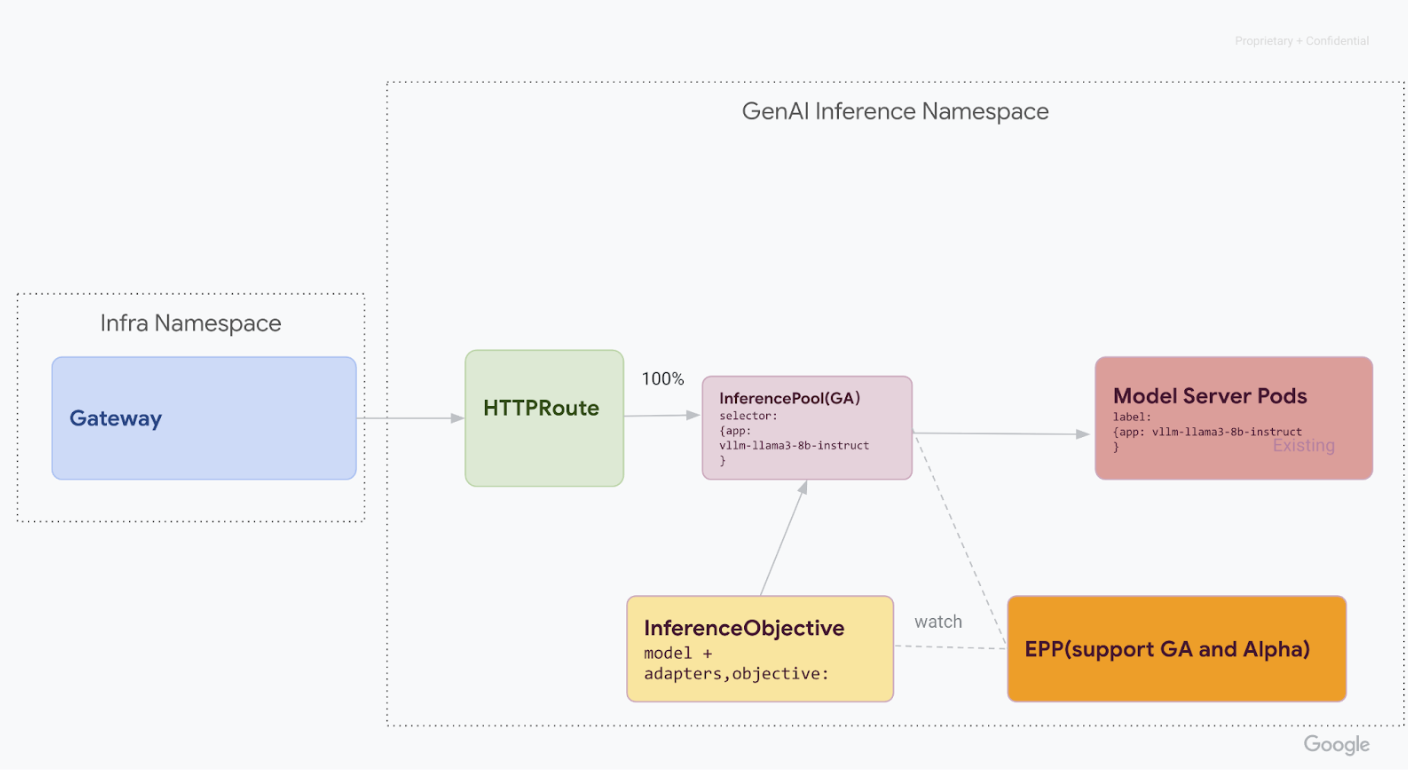
Figure : GKE Inference Gateway route les requêtes vers différents modèles d'IA générative en fonction du nom et de la priorité du modèle.
Étapes suivantes
- En savoir plus sur le déploiement de la passerelle d'inférence GKE
- Découvrez d'autres fonctionnalités de mise en réseau GKE.