
Halaman ini menjelaskan cara menggunakan Mulai Cepat Inferensi GKE (GIQ) untuk menyederhanakan deployment workload inferensi AI/ML di Google Kubernetes Engine (GKE). Inference Quickstart adalah utilitas yang memungkinkan Anda menentukan persyaratan bisnis inferensi dan mendapatkan konfigurasi Kubernetes yang dioptimalkan berdasarkan praktik terbaik dan tolok ukur Google untuk model, server model, akselerator (GPU, TPU), penskalaan, dan penyimpanan. Hal ini membantu Anda menghindari proses penyesuaian dan pengujian konfigurasi secara manual yang memakan waktu.
Halaman ini ditujukan untuk engineer Machine learning (ML), admin dan operator Platform, serta spesialis Data dan AI yang ingin memahami cara mengelola dan mengoptimalkan GKE secara efisien untuk inferensi AI/ML. Untuk mempelajari lebih lanjut peran umum dan contoh tugas yang kami referensikan dalam konten, lihat Peran dan tugas pengguna GKE umum. Google Cloud
Untuk mempelajari lebih lanjut konsep dan terminologi penyajian model, serta cara kemampuan AI Generatif GKE meningkatkan dan mendukung performa penyajian model Anda, lihat Tentang inferensi model di GKE.
Sebelum membaca halaman ini, pastikan Anda memahami Kubernetes, GKE, dan penyajian model.
Menggunakan Panduan Memulai Inferensi
Mulai Cepat Inferensi memungkinkan Anda menganalisis performa dan efisiensi biaya workload inferensi, serta membuat keputusan berbasis data tentang alokasi resource dan strategi deployment model.
Langkah-langkah umum untuk menggunakan Mulai Cepat Inferensi adalah sebagai berikut:
Menganalisis performa dan biaya: jelajahi konfigurasi yang tersedia dan filter berdasarkan persyaratan performa dan biaya Anda, dengan menggunakan perintah
gcloud container ai profiles list. Untuk melihat kumpulan lengkap data tolok ukur untuk konfigurasi tertentu, gunakan perintahgcloud container ai profiles benchmarks list. Dengan perintah ini, Anda dapat mengidentifikasi hardware yang paling hemat biaya untuk persyaratan performa spesifik Anda.Selain itu, Anda dapat memfilter rekomendasi Panduan Memulai Inferensi berdasarkan karakteristik workload seperti kasus penggunaan dan ukuran input/output, serta berdasarkan stack penayangan. Stack penayangan adalah kumpulan lengkap teknologi yang digunakan untuk menghosting model, menangani inferensi, dan merutekan permintaan pengguna untuk memberikan prediksi. Misalnya, stack penayangan
llm-dmenggunakan vLLM sebagai server model dasarnya, dengan menambahkan lapisan orkestrasi dan perutean di atas mesin inferensi inti.Men-deploy manifes: setelah analisis, Anda dapat membuat dan men-deploy manifes Kubernetes yang dioptimalkan. Secara opsional, Anda dapat mengaktifkan pengoptimalan untuk penyimpanan dan penskalaan otomatis. Anda dapat men-deploy dari konsol Google Cloud atau dengan menggunakan perintah
kubectl apply. Sebelum men-deploy, Anda harus memastikan bahwa Anda memiliki kuota akselerator yang cukup untuk GPU atau TPU yang dipilih di project Anda. Google Cloud(Opsional) Jalankan tolok ukur Anda sendiri: konfigurasi dan data performa yang disediakan oleh Panduan Memulai Inferensi didasarkan pada tolok ukur yang dihasilkan oleh alat
inference-perf. Karena performa beban kerja Anda mungkin berbeda dari dasar pengukuran ini, sebaiknya gunakan alatinference-perfuntuk mengukur performa model Anda dengan set data yang paling sesuai dengan kasus penggunaan Anda.
Manfaat
Panduan Memulai Inferensi membantu Anda menghemat waktu dan sumber daya dengan memberikan konfigurasi yang dioptimalkan. Pengoptimalan ini meningkatkan performa dan mengurangi biaya infrastruktur dengan cara berikut:
- Anda akan menerima praktik terbaik mendetail yang disesuaikan untuk menyetel konfigurasi akselerator (GPU dan TPU), server model, dan penskalaan. GKE secara rutin mengupdate Panduan Memulai Inferensi dengan perbaikan, image, dan tolok ukur performa terbaru.
- Anda dapat menentukan persyaratan latensi dan throughput beban kerja menggunakan UI konsol atau antarmuka command line, dan mendapatkan praktik terbaik yang disesuaikan secara mendetail sebagai manifes deployment Kubernetes.Google Cloud
Cara kerjanya
Mulai Cepat Inferensi memberikan praktik terbaik yang disesuaikan berdasarkan tolok ukur internal Google yang komprehensif tentang performa replika tunggal untuk kombinasi model, server model, dan topologi akselerator. Grafik tolok ukur ini menampilkan latensi versus throughput, termasuk metrik ukuran antrean dan cache KV, yang memetakan kurva performa untuk setiap kombinasi.
Cara praktik terbaik yang disesuaikan dibuat
Kami mengukur latensi dalam Waktu yang Dinormalisasi per Token Output (NTPOT) dan Waktu hingga Token Pertama (TTFT) dalam milidetik, serta throughput dalam token output per detik, dengan membebani akselerator. Untuk mempelajari lebih lanjut metrik performa ini, lihat Tentang inferensi model di GKE.
Profil latensi contoh berikut menggambarkan titik infleksi saat throughput mencapai titik stabil (hijau), titik pasca-infleksi saat latensi memburuk (merah), dan zona ideal (biru) untuk throughput optimal pada target latensi. Panduan Memulai Inferensi memberikan data dan konfigurasi performa untuk zona ideal ini.
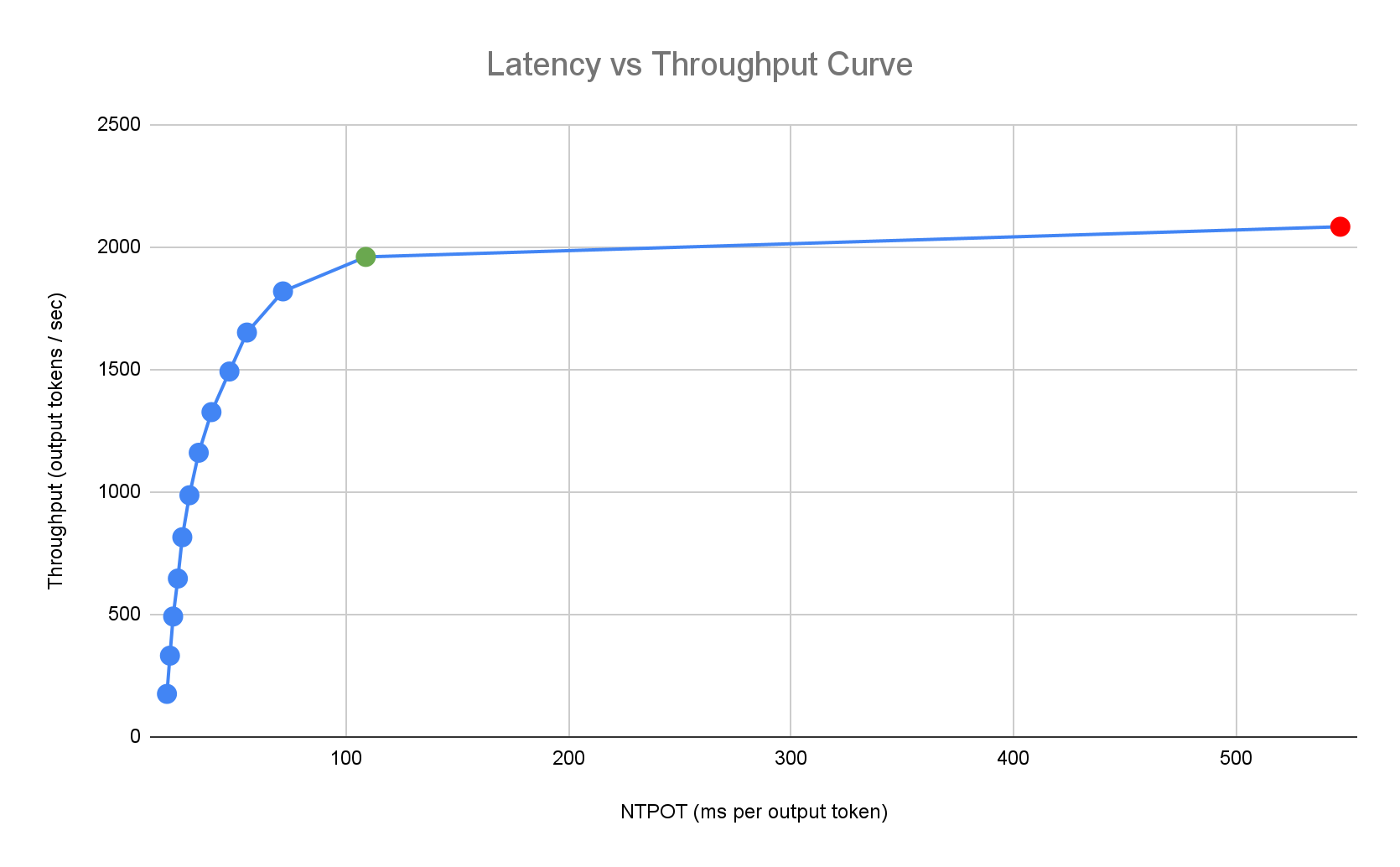
Berdasarkan persyaratan latensi aplikasi inferensi, Mulai Cepat Inferensi mengidentifikasi kombinasi yang sesuai dan menentukan titik operasi yang optimal pada kurva latensi-throughput. Titik ini menetapkan batas Horizontal Pod Autoscaler (HPA), dengan buffer untuk memperhitungkan latensi penskalaan. Nilai minimum keseluruhan juga menginformasikan jumlah awal replika yang diperlukan, meskipun HPA menyesuaikan jumlah ini secara dinamis berdasarkan workload.
Estimasi biaya
Untuk memperkirakan biaya per token VM akselerator Anda, Panduan Memulai Inferensi menggunakan rasio biaya output-ke-input yang dapat dikonfigurasi. Misalnya, jika rasio ini ditetapkan ke 4, diasumsikan bahwa setiap token output berharga empat kali lebih mahal daripada token input. Persamaan berikut digunakan untuk menghitung metrik biaya per token:
\[ \$/\text{output token} = \frac{\text{GPU \$/s}}{(\frac{1}{\text{output-to-input-cost-ratio}} \cdot \text{input tokens/s} + \text{output tokens/s})} \]
di mana
\[ \$/\text{input token} = \frac{\text{\$/output token}}{\text{output-to-input-cost-ratio}} \]
Tolok ukur
Konfigurasi dan data performa yang diberikan didasarkan pada tolok ukur yang dihasilkan oleh alat inference-perf untuk mengirim traffic dengan distribusi input dan output berikut.
| Token Input | Token Output | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Mnt | Median | Rata-rata | P90 | P99 | Maks | Mnt | Median | Rata-rata | P90 | P99 | Maks |
| 4 | 108 | 226 | 635 | 887 | 1024 | 1 | 132 | 195 | 488 | 778 | 1024 |
Sebelum memulai
Sebelum memulai, pastikan Anda telah melakukan tugas berikut:
- Aktifkan Google Kubernetes Engine API. Aktifkan Google Kubernetes Engine API
- Untuk menggunakan Google Cloud CLI untuk tugas ini,
instal lalu
lakukan inisialisasi
gcloud CLI. Jika sebelumnya Anda telah menginstal gcloud CLI, dapatkan versi terbaru dengan menjalankan perintah
gcloud components update. Versi gcloud CLI yang lebih lama mungkin tidak mendukung menjalankan perintah dalam dokumen ini.
Di konsol Google Cloud , pada halaman pemilih project, pilih atau buat project Google Cloud .
Pastikan penagihan diaktifkan untuk Google Cloud project Anda.
Pastikan Anda memiliki kapasitas akselerator yang memadai untuk project Anda:
- Jika Anda menggunakan GPU: Periksa halaman Kuota.
- Jika Anda menggunakan TPU: Lihat Memastikan kuota untuk TPU dan resource GKE lainnya.
Bersiap menggunakan antarmuka pengguna AI/ML GKE
Jika menggunakan konsol Google Cloud , Anda juga perlu membuat cluster Autopilot, jika cluster belum dibuat di project Anda. Ikuti petunjuk di Membuat cluster Autopilot.
Bersiap untuk menggunakan antarmuka command line
Jika Anda menggunakan gcloud CLI untuk menjalankan Panduan Memulai Inferensi, Anda juga perlu menjalankan perintah tambahan berikut:
Aktifkan API
gkerecommender.googleapis.com:gcloud services enable gkerecommender.googleapis.comTetapkan project kuota penagihan yang Anda gunakan untuk panggilan API:
gcloud config set billing/quota_project PROJECT_IDPastikan versi gcloud CLI Anda minimal 536.0.1. Jika tidak, jalankan perintah berikut:
gcloud components update
Batasan
Perhatikan batasan berikut sebelum Anda mulai menggunakan Panduan Memulai Inferensi:
- Deployment model konsolGoogle Cloud hanya mendukung deployment ke cluster Autopilot.
- Panduan Memulai Inferensi tidak menyediakan profil untuk semua model yang didukung oleh server model tertentu.
- Jika Anda tidak menyetel variabel lingkungan
HF_HOMEsaat menggunakan manifes yang dihasilkan untuk model besar (90 GiB atau lebih besar) dari Hugging Face, Anda harus menggunakan cluster dengan disk booting yang lebih besar dari default atau mengubah manifes untuk menyetelHF_HOMEke/dev/shm/hf_cache. Tindakan ini akan menggunakan RAM untuk cache, bukan boot disk node. Untuk mengetahui informasi selengkapnya, lihat bagian Pemecahan masalah. - Memuat model dari Cloud Storage memerlukan
Workload Identity Federation for GKE. Driver CSI Cloud Storage FUSE juga diperlukan untuk semua workload TPU dan sebagai penggantian untuk versi server model tertentu yang lebih lama dari
v0.11.1. Workload Identity Federation untuk GKE dan driver CSI Cloud Storage FUSE diaktifkan secara default di cluster Autopilot. Untuk mengetahui detail selengkapnya, lihat Menyiapkan driver CSI FUSE Cloud Storage untuk GKE.
Menganalisis dan melihat konfigurasi yang dioptimalkan untuk inferensi model
Bagian ini menjelaskan cara menjelajahi dan menganalisis rekomendasi konfigurasi dengan menggunakan Google Cloud CLI.
Gunakan perintah gcloud container ai profiles
untuk menjelajahi dan menganalisis profil yang dioptimalkan (kombinasi model, server model,
versi server model, dan akselerator):
Model
Untuk menjelajahi dan memilih model, gunakan opsi models.
gcloud container ai profiles models list
Profil
Gunakan perintah list
untuk menjelajahi profil yang dibuat dan memfilternya berdasarkan
persyaratan performa dan biaya Anda. Contoh:
gcloud container ai profiles list \
--model=openai/gpt-oss-20b \
--pricing-model=on-demand \
--target-ttft-milliseconds=300
Output menampilkan profil yang didukung dengan metrik performa seperti throughput, latensi, dan biaya per juta token pada titik infleksi. Tampilannya akan terlihat mirip dengan berikut ini:
Instance Type Accelerator Cost/M Input Tokens Cost/M Output Tokens Output Tokens/s NTPOT(ms) TTFT(ms) Model Server Model Server Version Model
a3-highgpu-1g nvidia-h100-80gb 0.009 0.035 13335 67 297 vllm gptoss openai/gpt-oss-20b
Nilai ini mewakili performa yang diamati pada titik saat throughput berhenti meningkat dan latensi mulai meningkat secara signifikan (yaitu, titik infleksi atau saturasi) untuk profil tertentu dengan jenis akselerator ini. Untuk mempelajari lebih lanjut metrik performa ini, lihat Tentang inferensi model di GKE.
Untuk mengetahui daftar lengkap flag yang dapat Anda tetapkan, lihat dokumentasi perintah list.
Semua informasi harga hanya tersedia dalam mata uang USD dan secara default menggunakan region us-east5, kecuali untuk konfigurasi yang menggunakan mesin A3, yang secara default menggunakan region us-central1.
Tolok ukur
Untuk mendapatkan semua data tolok ukur untuk profil tertentu, gunakan perintah
benchmarks list.
Contoh:
gcloud container ai profiles benchmarks list \
--model=deepseek-ai/DeepSeek-R1-Distill-Qwen-7B \
--model-server=vllm
Output berisi daftar metrik performa dari benchmark yang dijalankan pada berbagai kecepatan permintaan.
Perintah ini menampilkan output dalam format CSV. Untuk menyimpan output sebagai file, gunakan pengalihan output. Contoh: gcloud container ai profiles benchmarks list > profiles.csv
Untuk mengetahui daftar lengkap flag yang dapat Anda tetapkan, lihat dokumentasi perintah benchmarks list.
Setelah memilih model, server model, versi server model, dan akselerator, Anda dapat melanjutkan untuk membuat manifes deployment.
Melihat rekomendasi menurut kasus penggunaan
Panduan Memulai Inferensi memberikan rekomendasi untuk berbagai kasus penggunaan yang mewakili workload AI/ML umum. Kasus penggunaan ini dicirikan oleh berbagai panjang token input dan output berdasarkan beban kerja pelanggan di dunia nyata, yang dapat memengaruhi performa stack penayangan inferensi yang mendasarinya.
Tabel berikut memberikan ringkasan kasus penggunaan yang tersedia dan karakteristiknya:
| Kasus penggunaan | Token input | Token output | Rasio | Deskripsi |
|---|---|---|---|---|
| Dukungan Pelanggan Lanjutan | 8.192 | 256 | 32:1 | Selesaikan masalah pelanggan yang kompleks dengan jawaban komprehensif yang disintesis untuk menskalakan operasi dukungan dan meningkatkan kepuasan pengguna. |
| Penyelesaian Kode | 512 | 32 | 16:1 | Mempercepat pengembangan software dengan menyarankan dan melengkapi kode secara otomatis. |
| Peringkasan Teks | 1.024 | 128 | 8:1 | Meringkas dokumen, artikel, atau percakapan panjang menjadi ringkasan yang ringkas. |
| Chatbot (ShareGPT) | 128 | 128 | 1:1 | Memberikan bantuan percakapan instan untuk menjawab pertanyaan, melakukan tugas, atau memberikan panduan. |
| Pembuatan Teks | 512 | 2.048 | 1:4 | Mengotomatiskan pembuatan konten tertulis baru, mulai dari membuat draf email dan laporan hingga membuat cerita kreatif. |
| Deep Research | 256 | 4.096 | 1:16 | Memungkinkan penyelidikan dan studi mendetail dengan menganalisis dan menyintesis data dalam jumlah besar untuk menemukan informasi tertentu, mengidentifikasi pola, dan mengungkap insight. |
Untuk menemukan daftar lengkap kasus penggunaan yang didukung oleh
Panduan Mulai Cepat Inferensi, gunakan perintah
gcloud container ai profiles use-cases list.
Untuk memfilter rekomendasi menurut kasus penggunaan, gunakan flag --use-case. Saat Anda membuat manifes, jika Anda tidak menentukan tanda ini, tanda ini akan ditetapkan ke Chatbot secara default.
Contoh:
gcloud container ai profiles list \
--use-case="Text Summarization"
Men-deploy konfigurasi yang direkomendasikan
Bagian ini menjelaskan cara membuat dan men-deploy rekomendasi konfigurasi menggunakan konsol Google Cloud atau command line.
Konsol
- Di konsol Google Cloud , buka halaman GKE AI/ML.
- Klik Deploy Models.
Pilih model yang ingin Anda deploy. Model yang didukung oleh Panduan Memulai Inferensi ditampilkan dengan tag Dioptimalkan.
- Jika Anda memilih model dasar, halaman model akan terbuka. Klik Deploy. Anda masih dapat mengubah konfigurasi sebelum deployment sebenarnya.
- Anda akan diminta untuk membuat cluster Autopilot, jika belum ada di project Anda. Ikuti petunjuk di Membuat cluster Autopilot. Setelah membuat cluster, kembali ke halaman AI/ML GKE di konsol Google Cloud untuk memilih model.
- Untuk men-deploy model yang memerlukan izin seperti Gemma atau Llama, Anda harus
membuat token Hugging Face terlebih dahulu dan menambahkannya sebagai Secret Kubernetes. Jika tidak dilakukan, error
"Does not have minimum availability"mungkin terjadi dan mencegah Deployment dibuat. Untuk mengetahui petunjuk mendetail, buka tab gcloud di halaman dokumentasi ini.
Halaman deployment model akan diisi otomatis dengan model yang Anda pilih, serta server model dan akselerator yang direkomendasikan. Anda juga dapat mengonfigurasi setelan seperti latensi maksimum dan sumber model.
(Opsional) Untuk melihat manifes dengan konfigurasi yang direkomendasikan, klik View YAML.
Untuk men-deploy manifes dengan konfigurasi yang direkomendasikan, klik Deploy. Mungkin perlu waktu beberapa menit hingga operasi deployment selesai.
Untuk melihat deployment Anda, buka halaman Kubernetes Engine > Workloads.
gcloud
Bersiap untuk memuat model dari registry model Anda: Panduan memulai Inferensi mendukung pemuatan model dari Hugging Face atau Cloud Storage.
Hugging Face
Jika Anda belum memilikinya, buat token akses Hugging Face dan Secret Kubernetes yang sesuai.
Untuk membuat Secret Kubernetes yang berisi token Hugging Face, jalankan perintah berikut:
kubectl create secret generic hf-secret \ --from-literal=hf_api_token=HUGGING_FACE_TOKEN \ --namespace=NAMESPACEGanti nilai berikut:
- HUGGING_FACE_TOKEN: token Hugging Face yang Anda buat sebelumnya.
- NAMESPACE: namespace Kubernetes tempat Anda ingin men-deploy server model.
Beberapa model juga mungkin mengharuskan Anda menyetujui dan menandatangani perjanjian lisensi izin mereka.
Cloud Storage
Anda dapat memuat model yang didukung dari Cloud Storage dengan penyiapan Cloud Storage FUSE yang dioptimalkan. Untuk melakukannya, Anda harus memuat model dari Hugging Face ke bucket Cloud Storage terlebih dahulu.
Anda dapat men-deploy Tugas Kubernetes ini untuk mentransfer model, dengan mengubah
MODEL_IDke model yang didukung Panduan Memulai Inferensi.Buat manifes: Anda memiliki opsi berikut untuk membuat manifes:
- Konfigurasi dasar: membuat manifes Deployment, Service, dan PodMonitoring Kubernetes standar untuk men-deploy server inferensi replika tunggal.
- (Opsional) Konfigurasi yang dioptimalkan untuk penyimpanan: membuat manifes yang dioptimalkan untuk pemuatan Cloud Storage. Konfigurasi ini memprioritaskan
Run:ai Model Streamer untuk meningkatkan performa pada versi vLLM yang didukung,
sekaligus menggunakan penyiapan Cloud Storage FUSE yang dioptimalkan untuk versi sebelumnya. Anda dapat mengaktifkan konfigurasi ini menggunakan flag
--model-bucket-uri. Pengoptimalan ini dapat meningkatkan waktu startup Pod LLM lebih dari 7 kali lipat. (Opsional) Konfigurasi yang dioptimalkan untuk penskalaan otomatis: membuat manifest dengan Horizontal Pod Autoscaler (HPA) untuk menyesuaikan jumlah replika server model secara otomatis berdasarkan traffic. Anda dapat mengaktifkan konfigurasi ini dengan menentukan target latensi menggunakan tanda seperti
--target-ntpot-milliseconds.
Konfigurasi dasar
Di terminal, gunakan opsi
manifestsuntuk membuat manifes Deployment, Service, dan PodMonitoring:gcloud container ai profiles manifests createGunakan parameter
--model,--model-server, dan--accelerator-typeyang diperlukan untuk menyesuaikan manifes Anda.Secara opsional, Anda dapat menetapkan parameter berikut:
--target-ntpot-milliseconds: tetapkan parameter ini untuk menentukan nilai minimum HPA. Dengan parameter ini, Anda dapat menentukan nilai minimum penskalaan untuk menjaga latensi P50 Normalized Time Per Output Token (NTPOT), yang diukur pada persentil ke-50, di bawah nilai yang ditentukan. Pilih nilai di atas latensi minimum akselerator Anda. HPA dikonfigurasi untuk throughput maksimum jika Anda menentukan nilai NTPOT di atas latensi maksimum akselerator. Contoh:gcloud container ai profiles manifests create \ --model=google/gemma-2-27b-it \ --model-server=vllm \ --model-server-version=v0.7.2 \ --accelerator-type=nvidia-l4 \ --target-ntpot-milliseconds=200--target-ttft-milliseconds: target waktu ke token pertama (TTFT) dalam milidetik. Jika disetel, manifes akan menyertakan resource Horizontal Pod Autoscaler (HPA) untuk menjaga TTFT p50 di bawah nilai minimum yang ditentukan.--output-path: jika ditentukan, output akan disimpan ke jalur yang diberikan, bukan dicetak ke terminal sehingga Anda dapat mengedit output sebelum men-deploy-nya. Misalnya, Anda dapat menggunakan opsi ini dengan--output=manifestjika ingin menyimpan manifes dalam file YAML. Contoh:gcloud container ai profiles manifests create \ --model deepseek-ai/DeepSeek-R1-Distill-Qwen-7B \ --model-server vllm \ --accelerator-type=nvidia-tesla-a100 \ --output=manifest \ --output-path /tmp/manifests.yaml--target-itl-milliseconds: latensi antar-token (ITL) target dalam milidetik. Jika ini disetel, manifes akan menyertakan resource Horizontal Pod Autoscaler (HPA) untuk menjaga ITL p50 di bawah nilai minimum yang ditentukan.--use-case: manifes akan dioptimalkan untuk kasus penggunaan ini. Jika tidak ditentukan, tanda ini akan ditetapkan secara default keChatbot. Untuk mengetahui informasi selengkapnya, lihat Melihat rekomendasi menurut kasus penggunaan.
Untuk mengetahui daftar lengkap flag yang dapat Anda tetapkan, lihat dokumentasi perintah
manifests create.Dioptimalkan untuk penyimpanan
Anda dapat meningkatkan waktu mulai Pod dengan memuat model dari Cloud Storage. Mulai Cepat Inferensi secara otomatis memilih backend penyimpanan dengan performa tertinggi untuk konfigurasi Anda:
- Run:ai Model Streamer: solusi streaming yang digunakan secara otomatis untuk vLLM versi 0.11.1 dan yang lebih baru di GPU serta 0.14.0 dan yang lebih baru di TPU.
- Driver CSI Cloud Storage FUSE: Pengoptimalan penyimpanan standar, digunakan untuk vLLM versi sebelum 0.11.1 dan untuk server model lainnya.
Memuat dari Cloud Storage memerlukan GKE versi 1.29.6-gke.1254000, 1.30.2-gke.1394000, atau yang lebih baru
Untuk melakukannya, ikuti langkah-langkah ini:
- Muat model dari repositori Hugging Face ke bucket Cloud Storage Anda.
Tetapkan tanda
--model-bucket-urisaat membuat manifes. Tindakan ini mengonfigurasi model untuk dimuat dari bucket Cloud Storage. Model ini otomatis menggunakan Run:ai Model Streamer berperforma tinggi untuk versi vLLM yang didukung, dan kembali menggunakan driver CSI Cloud Storage FUSE untuk versi lainnya. URI harus mengarah ke jalur yang berisi fileconfig.jsondan bobot model. Anda dapat menentukan jalur ke direktori dalam bucket dengan menambahkannya ke URI bucket.Contoh:
gcloud container ai profiles manifests create \ --model=openai/gpt-oss-120b \ --model-server=vllm \ --model-server-version=v0.11.2 \ --accelerator-type=nvidia-h100-80gb \ --model-bucket-uri=gs://BUCKET_NAME \ --output-path=manifests.yamlGanti
BUCKET_NAMEdengan nama bucket Cloud Storage Anda.Sebelum menerapkan manifes, Anda harus menjalankan perintah
gcloud storage buckets add-iam-policy-bindingyang ada di komentar manifes. Perintah ini diperlukan untuk memberikan izin akun layanan GKE untuk mengakses bucket Cloud Storage menggunakan Workload Identity Federation for GKE.Jika Anda ingin menskalakan Deployment ke lebih dari satu replika di TPU, Anda harus memilih salah satu opsi berikut untuk mencegah error penulisan serentak ke jalur cache XLA (
VLLM_XLA_CACHE_PATH):- Opsi 1 (Direkomendasikan): Pertama, skala Deployment ke 1 replika. Tunggu hingga Pod siap, yang memungkinkannya menulis ke cache XLA. Kemudian, lakukan penskalaan ke jumlah replika yang Anda inginkan. Replika berikutnya akan membaca dari cache yang terisi tanpa konflik penulisan.
- Opsi 2: Hapus variabel lingkungan
VLLM_XLA_CACHE_PATHdari manifest sepenuhnya. Pendekatan ini lebih sederhana, tetapi menonaktifkan caching untuk semua replika.
Pada jenis akselerator TPU, jalur cache ini digunakan untuk menyimpan cache kompilasi XLA, yang mempercepat penyiapan model untuk deployment berulang.
Untuk mengetahui tips selengkapnya tentang cara meningkatkan performa, lihat artikel Mengoptimalkan driver CSI FUSE Cloud Storage untuk performa GKE.
Dioptimalkan untuk penskalaan otomatis
Anda dapat mengonfigurasi Horizontal Pod Autoscaler (HPA) untuk menyesuaikan jumlah replika server model secara otomatis berdasarkan beban. Hal ini membantu server model Anda menangani berbagai beban secara efisien dengan meningkatkan atau menurunkan skala sesuai kebutuhan. Konfigurasi HPA mengikuti panduan praktik terbaik penskalaan otomatis untuk GPU dan TPU.
Untuk menyertakan konfigurasi HPA saat membuat manifes, gunakan satu atau kedua flag
--target-ntpot-millisecondsdan--target-ttft-milliseconds. Parameter ini menentukan batas penskalaan untuk HPA agar latensi P50 untuk NTPOT atau TTFT tetap di bawah nilai yang ditentukan. Jika Anda hanya menetapkan salah satu tanda ini, hanya metrik tersebut yang akan diperhitungkan untuk penskalaan.Pilih nilai di atas latensi minimum akselerator Anda. HPA dikonfigurasi untuk throughput maksimum jika Anda menentukan nilai di atas latensi maksimum akselerator Anda.
Contoh:
gcloud container ai profiles manifests create \ --model=google/gemma-2-27b-it \ --accelerator-type=nvidia-l4 \ --target-ntpot-milliseconds=250Membuat cluster: Anda dapat menayangkan model di cluster GKE Autopilot atau Standard. Sebaiknya gunakan cluster Autopilot untuk pengalaman Kubernetes yang terkelola sepenuhnya. Untuk memilih mode operasi GKE yang paling sesuai untuk workload Anda, lihat Memilih mode operasi GKE.
Jika Anda tidak memiliki cluster yang ada, ikuti langkah-langkah berikut:
Autopilot
Ikuti petunjuk berikut untuk membuat cluster Autopilot. GKE menangani penyediaan node dengan kapasitas GPU atau TPU berdasarkan manifes deployment, jika Anda memiliki kuota yang diperlukan di project Anda.
Standar
- Buat cluster zonal atau regional.
Buat node pool dengan akselerator yang sesuai. Ikuti langkah-langkah berikut berdasarkan jenis akselerator yang Anda pilih:
- GPU: Pertama, periksa halaman Kuota di konsol Google Cloud untuk memastikan Anda memiliki kapasitas GPU yang memadai. Kemudian, ikuti petunjuk di Membuat node pool GPU.
- TPU: Pertama, pastikan Anda memiliki TPU yang cukup dengan mengikuti petunjuk di Memastikan kuota untuk TPU dan resource GKE lainnya. Kemudian, lanjutkan ke Membuat node pool TPU.
(Opsional, tetapi direkomendasikan) Aktifkan fitur pengamatan: Di bagian komentar manifes yang dihasilkan, perintah tambahan disediakan untuk mengaktifkan fitur pengamatan yang disarankan. Dengan mengaktifkan fitur ini, Anda akan mendapatkan lebih banyak insight untuk membantu memantau performa dan status beban kerja serta infrastruktur yang mendasarinya.
Berikut adalah contoh perintah untuk mengaktifkan fitur kemampuan pengamatan:
gcloud container clusters update $CLUSTER_NAME \ --project=$PROJECT_ID \ --location=$LOCATION \ --enable-managed-prometheus \ --logging=SYSTEM,WORKLOAD \ --monitoring=SYSTEM,DEPLOYMENT,HPA,POD,DCGM \ --auto-monitoring-scope=ALLUntuk mengetahui informasi selengkapnya, lihat Memantau workload inferensi Anda.
(Khusus HPA) Deploy adaptor metrik: Adaptor metrik, seperti Custom Metrics Stackdriver Adapter, diperlukan jika resource HPA dibuat dalam manifes deployment. Adaptor metrik memungkinkan HPA mengakses metrik server model yang menggunakan kube external metrics API. Untuk men-deploy adaptor, lihat dokumentasi adaptor di GitHub.
Deploy manifes: jalankan perintah
kubectl applydan teruskan file YAML untuk manifes Anda. Contoh:kubectl apply -f ./manifests.yaml
Men-deploy konfigurasi yang direkomendasikan untuk stack inferensi llm-d
llm-d adalah stack inferensi terdistribusi native Kubernetes yang menyediakan "jalur yang jelas" yang telah diuji dan diukur untuk membantu Anda menyajikan model AI generatif besar dalam skala besar dengan tingkat performa yang tinggi. Untuk mengetahui informasi selengkapnya, lihat dokumentasi llm-d.
Untuk membuat dan men-deploy konfigurasi yang direkomendasikan untuk stack penayangan llm-d
dengan menggunakan Panduan Memulai Inferensi, gunakan
flag --serving-stack
dengan nilai yang ditetapkan ke llm-d. Contoh:
gcloud container ai profiles manifests create \
--accelerator-type=nvidia-h100-80gb \
--model=openai/gpt-oss-120b \
--model-server=vllm \
--serving-stack=llm-d \
--use-case 'Multi Agent Large Document Summarization'
Periksa output manifests create untuk mengetahui petunjuk tambahan tentang pembuatan cluster dan penginstalan dependensi guna menyiapkan lingkungan Anda dengan benar untuk llm-d.
Menguji endpoint deployment Anda
Setelah men-deploy manifes, layanan akan diekspos di
http://SERVICE_NAME:8000, dengan
SERVICE_NAME adalah nama deployment Anda.
Untuk mengonfirmasi nama layanan, Anda dapat mencantumkan layanan di namespace Anda
(misalnya, default):
kubectl get services --namespace NAMESPACE
Untuk menguji deployment, gunakan perintah kubectl port-forward untuk meneruskan port lokal ke
port layanan. Di terminal terpisah, jalankan perintah berikut:
kubectl port-forward service/SERVICE_NAME 8000:8000
Kemudian, Anda dapat mengirim permintaan ke http://localhost:8000. Untuk contoh cara membuat dan mengirim permintaan ke endpoint Anda, lihat dokumentasi vLLM.
Pembuatan versi manifes
Panduan Memulai Inferensi menyediakan manifes terbaru yang divalidasi pada versi cluster GKE terbaru. Manifes yang ditampilkan untuk profil dapat berubah dari waktu ke waktu sehingga Anda menerima konfigurasi yang dioptimalkan saat deployment. Jika Anda memerlukan manifes yang stabil, simpan dan simpan secara terpisah.
Manifes menyertakan komentar dan anotasi recommender.ai.gke.io/version
dalam format berikut:
# Generated on DATE using:
# GKE cluster CLUSTER_VERSION
# GPU_DRIVER_VERSION GPU driver for node version NODE_VERSION
# Model server MODEL_SERVER MODEL_SERVER_VERSION
Anotasi sebelumnya memiliki nilai berikut:
- DATE: tanggal manifes dibuat.
- CLUSTER_VERSION: versi cluster GKE yang digunakan untuk validasi.
- NODE_VERSION: versi node GKE yang digunakan untuk validasi.
- GPU_DRIVER_VERSION: (Khusus GPU) versi driver GPU yang digunakan untuk validasi.
- MODEL_SERVER: server model yang digunakan dalam manifes.
- MODEL_SERVER_VERSION: versi server model yang digunakan dalam manifes.
Memantau workload inferensi Anda
Untuk memantau workload inferensi yang di-deploy, buka Metrics Explorer di konsol Google Cloud .
Mengaktifkan pemantauan otomatis
GKE menyertakan fitur pemantauan otomatis yang merupakan bagian dari fitur observabilitas yang lebih luas. Fitur ini memindai cluster untuk menemukan workload yang berjalan di server model yang didukung dan men-deploy resource PodMonitoring yang memungkinkan metrik workload ini terlihat di Cloud Monitoring. Untuk mengetahui informasi selengkapnya tentang cara mengaktifkan dan mengonfigurasi pemantauan otomatis, lihat Mengonfigurasi pemantauan aplikasi otomatis untuk workload.
Setelah mengaktifkan fitur ini, GKE akan menginstal dasbor yang telah dibuat sebelumnya untuk memantau aplikasi untuk workload yang didukung.
Jika Anda men-deploy dari halaman AI/ML GKE di konsol Google Cloud , resource PodMonitoring dan HPA akan otomatis dibuat untuk Anda menggunakan konfigurasitargetNtpot.
Pemecahan masalah
- Jika Anda menetapkan latensi terlalu rendah, Panduan Memulai Inferensi mungkin tidak menghasilkan rekomendasi. Untuk memperbaiki masalah ini, pilih target latensi antara latensi minimum dan maksimum yang diamati untuk akselerator yang Anda pilih.
- Panduan Memulai Inferensi ada secara terpisah dari komponen GKE, sehingga versi cluster Anda tidak secara langsung relevan untuk menggunakan layanan ini. Namun, sebaiknya gunakan cluster baru atau yang sudah diupdate untuk menghindari perbedaan performa.
- Jika Anda mendapatkan error
PERMISSION_DENIEDuntuk perintahgkerecommender.googleapis.comyang menyatakan bahwa project kuota tidak ada, Anda harus menyetelnya secara manual. Jalankangcloud config set billing/quota_project PROJECT_IDuntuk memperbaikinya.
Pod dikeluarkan karena penyimpanan sementara hampir habis
Saat men-deploy model besar (90 GiB atau lebih) dari Hugging Face, Pod Anda mungkin dikeluarkan dengan pesan error yang mirip dengan ini:
Fails because inference server consumes too much ephemeral storage, and gets evicted low resources: Warning Evicted 3m24s kubelet The node was low on resource: ephemeral-storage. Threshold quantity: 10120387530, available: 303108Ki. Container inference-server was using 92343412Ki, request is 0, has larger consumption of ephemeral-storage..,
Error ini terjadi karena model di-cache di boot disk node, yaitu bentuk penyimpanan sementara. Disk boot digunakan untuk penyimpanan sementara saat manifes deployment tidak menyetel variabel lingkungan HF_HOME ke direktori di RAM node.
- Secara default, node GKE memiliki boot disk 100 GiB.
- GKE mencadangkan 10% boot disk untuk overhead sistem, sehingga menyisakan 90 GiB untuk workload Anda.
- Jika ukuran modelnya 90 GiB atau lebih besar, dan dijalankan di boot disk berukuran default, kubelet akan mengeluarkan Pod untuk mengosongkan penyimpanan sementara.
Untuk mengatasi masalah ini, pilih salah satu opsi berikut:
- Gunakan RAM untuk caching model: Dalam manifes deployment, tetapkan variabel lingkungan
HF_HOMEke/dev/shm/hf_cache. Tindakan ini menggunakan RAM node untuk menyimpan model dalam cache, bukan boot disk. - Perbesar ukuran boot disk:
- GKE Standard: Tingkatkan ukuran boot disk saat Anda membuat cluster, membuat node pool, atau memperbarui node pool.
- Autopilot: Untuk meminta disk booting yang lebih besar, buat Class Komputasi Kustom dan tetapkan kolom
bootDiskSizedalam aturanmachineType.
Pod memasuki loop error saat memuat model dari Cloud Storage
Setelah Anda men-deploy manifes yang dibuat dengan tanda --model-bucket-uri, Deployment mungkin macet dan Pod memasuki status CrashLoopBackOff.
Memeriksa log untuk container inference-server mungkin menunjukkan error yang menyesatkan, seperti huggingface_hub.errors.HFValidationError. Contoh:
huggingface_hub.errors.HFValidationError: Repo id must use alphanumeric chars or '-', '_', '.', '--' and '..' are forbidden, '-' and '.' cannot start or end the name, max length is 96: '/data'.
Error ini biasanya terjadi jika jalur Cloud Storage yang diberikan di flag --model-bucket-uri salah. Server inferensi, seperti vLLM,
tidak dapat menemukan file model yang diperlukan (seperti config.json) di jalur yang terpasang.
Jika gagal menemukan file lokal, server akan kembali mengasumsikan bahwa jalur tersebut adalah ID repositori Hugging Face Hub. Karena jalur bukan ID repositori yang valid, server gagal dengan error validasi dan memasuki loop error.
Untuk mengatasi masalah ini, pastikan jalur yang Anda berikan ke tanda --model-bucket-uri
menunjuk ke direktori yang tepat di bucket Cloud Storage Anda yang
berisi file config.json model dan semua bobot model terkait.
Langkah berikutnya
- Buka portal orkestrasi AI/ML di GKE untuk mempelajari panduan, tutorial, dan kasus penggunaan resmi kami untuk menjalankan workload AI/ML di GKE.
- Untuk mengetahui informasi selengkapnya tentang pengoptimalan penyajian model, lihat Praktik terbaik untuk mengoptimalkan inferensi model bahasa besar dengan GPU. Modul ini membahas praktik terbaik untuk penayangan LLM dengan GPU di GKE, seperti kuantisasi, paralelisme tensor, dan pengelolaan memori.
- Untuk mengetahui informasi selengkapnya tentang praktik terbaik untuk penskalaan otomatis, lihat panduan berikut:
- Untuk mengetahui informasi tentang praktik terbaik penyimpanan, lihat Mengoptimalkan driver CSI FUSE Cloud Storage untuk performa GKE.
- Jelajahi contoh eksperimental untuk memanfaatkan GKE dalam mempercepat inisiatif AI/ML Anda di GKE AI Labs.