
Questa pagina spiega i concetti e le funzionalità chiave di GKE Inference Gateway, un'estensione di Google Kubernetes Engine Gateway per la pubblicazione ottimizzata di applicazioni di AI generativa.
Questa pagina presuppone che tu conosca i seguenti argomenti:
- Orchestrazione di AI/ML su GKE
- Terminologia di AI generativa
- Concetti di networking GKE, inclusi i servizi, e l' API GKE Gateway
- Bilanciamento del carico in Google Cloud, in particolare come i bilanciatori del carico interagiscono con GKE
Questa pagina è destinata ai seguenti ruoli:
- Ingegneri di machine learning (ML), amministratori e operatori di piattaforme e specialisti di dati e AI interessati a utilizzare le funzionalità di orchestrazione dei container Kubernetes per la pubblicazione di carichi di lavoro di AI/ML.
- Architetti cloud e specialisti di networking che interagiscono con il networking Kubernetes.
Panoramica
GKE Inference Gateway è un'estensione di GKE Gateway che fornisce routing e bilanciamento del carico ottimizzati per la pubblicazione di carichi di lavoro di AI generativa. Semplifica il deployment, la gestione e l'osservabilità dei carichi di lavoro di inferenza AI.
Per scegliere la strategia di bilanciamento del carico ottimale per i carichi di lavoro di AI/ML, consulta Scegliere una strategia di bilanciamento del carico per l'inferenza AI su GKE.
Funzionalità e vantaggi
GKE Inference Gateway fornisce le seguenti funzionalità chiave per erogare in modo efficiente i modelli di AI generativa per le applicazioni di AI generativa su GKE:
- Metriche supportate:
KV cache hits: il numero di ricerche riuscite nella cache della coppia chiave-valore (KV).- Utilizzo di GPU o TPU: la percentuale di tempo in cui la GPU o la TPU elabora attivamente.
- Lunghezza della coda delle richieste: il numero di richieste in attesa di essere elaborate.
- Bilanciamento del carico ottimizzato per l'inferenza: distribuisce le richieste per ottimizzare
le prestazioni di erogazione del modello di AI. Utilizza le metriche dei server dei modelli, come
KV cache hitse laqueue length of pending requestsper utilizzare gli acceleratori (come GPU e TPU) in modo più efficiente per i carichi di lavoro di AI generativa. Ciò consente il routing con riconoscimento della cache dei prefissi, una funzionalità chiave che invia le richieste con contesto condiviso, identificate analizzando il corpo della richiesta, alla stessa replica del modello massimizzando gli hit della cache. Questo approccio riduce drasticamente i calcoli ridondanti e migliora il tempo al primo token, rendendolo molto efficace per l'AI conversazionale, la generazione RAG (Retrieval-Augmented Generation) e altri carichi di lavoro di AI generativa basati su modelli. - Erogazione dinamica di modelli ottimizzati con LoRA: supporta l'erogazione di modelli ottimizzati con LoRA dinamici su un acceleratore comune. In questo modo si riduce il numero di GPU e TPU necessarie per pubblicare i modelli eseguendo il multiplexing di più modelli ottimizzati con LoRA su un modello di base e un acceleratore comuni.
- Scalabilità automatica ottimizzata per l'inferenza: GKE Horizontal Pod Autoscaler (HPA) utilizza le metriche del server dei modelli per la scalabilità automatica, il che contribuisce a garantire un utilizzo efficiente delle risorse di calcolo e prestazioni di inferenza ottimizzate.
- Routing basato sul modello: instrada le richieste di inferenza in base ai nomi dei modelli
definiti nelle
OpenAI APIspecifiche all'interno del cluster GKE. Puoi definire le policy di routing del gateway, come la suddivisione del traffico e il mirroring delle richieste, per gestire diverse versioni del modello e semplificare i rollout dei modelli. Ad esempio, puoi instradare le richieste per un nome di modello specifico a diversi oggetti InferencePool, ognuno dei quali pubblica una versione diversa del modello. Per ulteriori informazioni su come configurare questa funzionalità, consulta Configurare il routing basato sul corpo del messaggio. - Sicurezza AI integrata e filtro dei contenuti: GKE Inference Gateway si integra con Google Cloud Model Armor per applicare controlli di sicurezza AI e filtri dei contenuti a prompt e risposte nel gateway. Puoi anche utilizzare NVIDIA NeMo Guardrails. Model Armor fornisce log di richieste, risposte ed elaborazione per l'analisi e l'ottimizzazione retrospettive. Le interfacce aperte di GKE Inference Gateway consentono a fornitori e sviluppatori di terze parti di integrare servizi personalizzati nel processo di richiesta di inferenza.
- Pubblicazione specifica del modello
Priority: consente di specificare la pubblicazionePrioritydei modelli di AI. Dai la priorità alle richieste sensibili alla latenza rispetto ai job di inferenza batch tolleranti alla latenza. Ad esempio, puoi dare la priorità alle richieste provenienti da applicazioni sensibili alla latenza ed eliminare le attività meno sensibili al tempo quando le risorse sono limitate. - Routing basato sulla latenza prevista: instrada le richieste di inferenza utilizzando un modello XGBoost addestrato continuamente sul traffico in tempo reale, ottimizzando gli obiettivi di tempo al primo token (TTFT) e tempo per token di output (TPOT) per richiesta. Più preciso delle euristiche statiche per i carichi di lavoro con varianza elevata. Consulta Utilizzare il routing basato sulla latenza prevista con GKE Inference Gateway.
- Osservabilità dell'inferenza: fornisce metriche di osservabilità per le richieste di inferenza, come tasso di richieste, latenza, errori e saturazione. Monitora le prestazioni e il comportamento dei servizi di inferenza tramite Cloud Monitoring e Cloud Logging, sfruttando dashboard predefinite specializzate per informazioni dettagliate. Per ulteriori informazioni, consulta Visualizzare la dashboard di GKE Inference Gateway.
- Gestione avanzata delle API con Apigee: si integra con Apigee per migliorare il gateway di inferenza con funzionalità come sicurezza delle API, limitazione di frequenza e quote. Per istruzioni dettagliate, consulta Configurare Apigee per l'autenticazione e la gestione delle API management.
- Estensibilità: basato su un'estensione di inferenza dell'API Gateway di Kubernetes estensibile e open source che supporta un algoritmo di selezione dell'endpoint (EPP) llm-d gestito dall'utente, basato su llm-d. L'algoritmo llm-d Endpoint Picker (EPP), basato su llm-d, fornisce l'intelligenza di routing di base per questa estensione.
- Supporto multiporta: supporta i server dei modelli che espongono più porte, il che è essenziale per scenari di pubblicazione avanzati come l'attenzione parallela ai dati.
- Limiti dei gruppi di endpoint di rete (NEG): ha un limite di 50 NEG per Google Cloud servizio di backend. Quando utilizzi un InferencePool multiporta, ogni porta in ogni zona crea un NEG dedicato. Ad esempio, un InferencePool con otto porte in un cluster regionale tipico (tre zone) genera 24 NEG. Pertanto, un gateway multi-cluster può aggregare un InferencePool di questo tipo da un massimo di due cluster (due cluster × 24 NEG = 48 NEG) prima di raggiungere il limite di 50 NEG.
Comprendere i concetti chiave
GKE Inference Gateway migliora l'esistente GKE
Gateway che utilizza
GatewayClass
oggetti. GKE Inference Gateway introduce le seguenti nuove
definizioni di risorse personalizzate (CRD) dell'API Gateway, allineate all'estensione dell'API Gateway di Kubernetes OSS
per l'
inferenza:
- Oggetto InferencePool: rappresenta un gruppo di pod (container) che
condividono la stessa configurazione di calcolo, il tipo di acceleratore, il modello linguistico di base
e il server dei modelli. Raggruppa e gestisce logicamente le risorse di erogazione del modello di AI. Un singolo oggetto InferencePool può estendersi su più pod su diversi nodi GKE e fornisce scalabilità e alta disponibilità. Puoi specificare fino a otto
targetPortsin una risorsa InferencePool per supportare i server dei modelli che richiedono più porte. - Oggetto InferenceObjective: specifica il nome del modello di pubblicazione da
InferencePool in base alla specifica
OpenAI API. L'oggetto InferenceObjective specifica anche le proprietà di pubblicazione del modello, come laPrioritydel modello di AI. GKE Inference Gateway dà la preferenza ai carichi di lavoro con un valore di priorità più elevato. In questo modo puoi eseguire il multiplexing dei carichi di lavoro di AI sensibili alla latenza e tolleranti alla latenza su un cluster GKE. Puoi anche configurare l'oggetto InferenceObjective per pubblicare i modelli ottimizzati con LoRA.
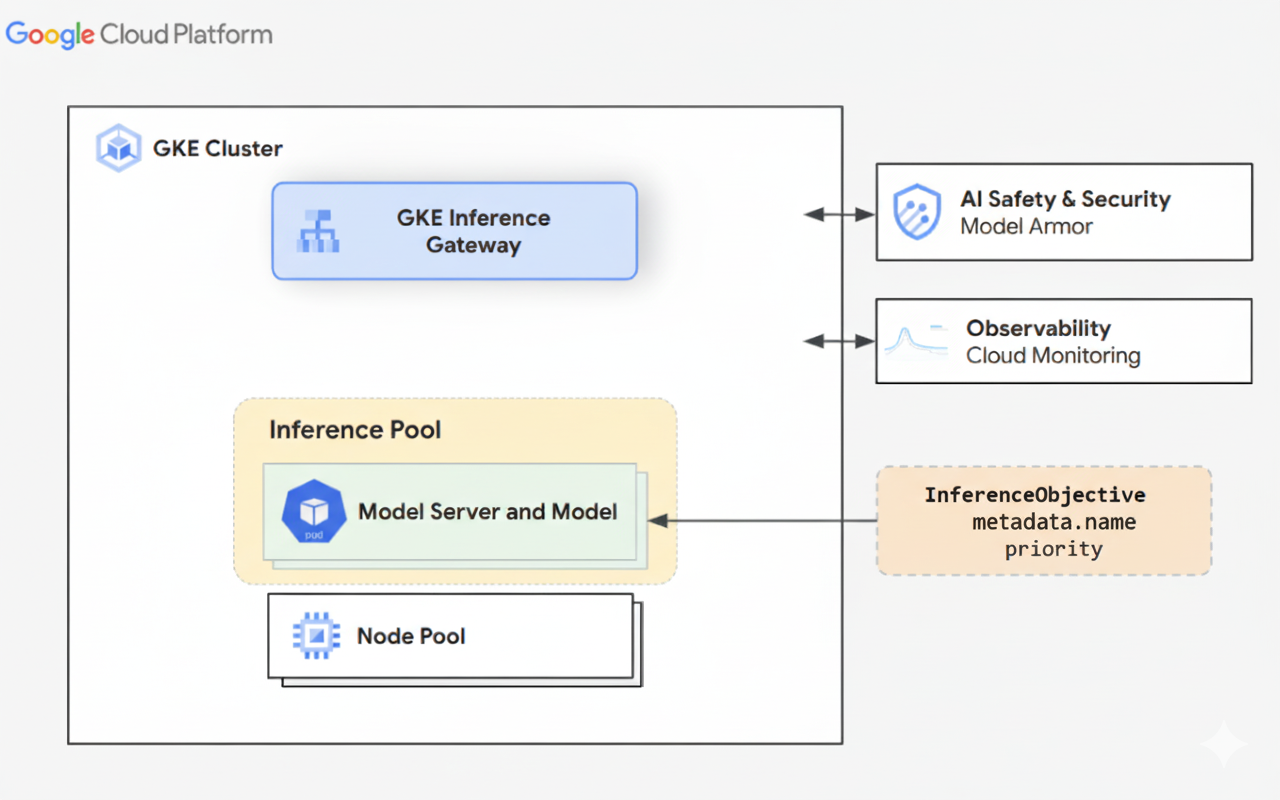
Il seguente diagramma illustra GKE Inference Gateway e la sua integrazione con la sicurezza AI, l'osservabilità e l'erogazione del modello all'interno di un cluster GKE.
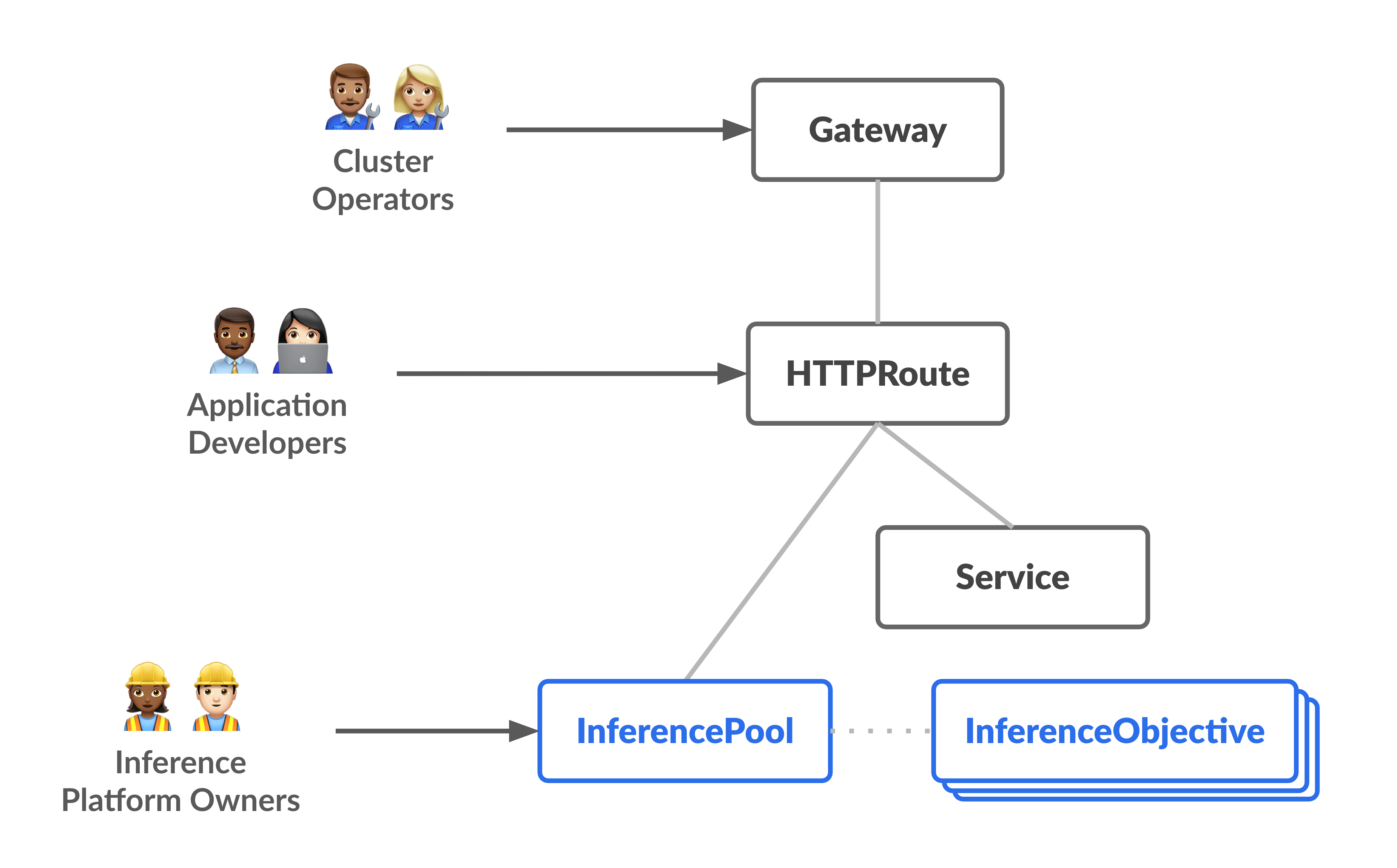
Il seguente diagramma illustra il modello di risorse che si concentra su due nuovi ruoli incentrati sull'inferenza e sulle risorse che gestiscono.
Router llm-d
Il router llm-d è il componente di routing intelligente delle richieste che Inference Gateway utilizza per prendere decisioni sugli endpoint per ogni richiesta. È composto da due sottocomponenti:
| Sottocomponente | Descrizione |
|---|---|
| L7 Proxy | Qualsiasi proxy L7 di livello industriale conforme (in genere Envoy) che gestisce il piano dati: gestione delle connessioni, terminazione TLS e forwarding delle richieste. In GKE Inference Gateway (modalità gateway), il proxy è GKE Gateway. |
| llm-d Endpoint Picker (EPP) | Un servizio specializzato che il proxy consulta per ogni richiesta
utilizzando il ext-proc protocollo. L'EPP contiene l'intelligenza di routing
intelligence. Utilizza i segnali in tempo reale dai server dei modelli
(utilizzo della cache KV, lunghezza della coda, stato della cache dei prefissi e affinità dell'adattatore LoRA
dell'adattatore) per selezionare il pod del server dei modelli ottimale per ogni
richiesta. |
Modalità gateway
GKE Inference Gateway è il llm-d Router che opera in modalità gateway. In modalità gateway, il proxy è un gateway Kubernetes formale di cui viene eseguito il provisioning e la gestione separatamente dal servizio EPP. Il gateway chiama l'EPP tramite ext-proc per prendere decisioni di routing, quindi inoltra la richiesta direttamente al pod del server dei modelli selezionato.
Questa separazione del gateway (piano dati) dall'EPP (intelligenza di routing) consente di:
- Infrastruttura condivisa: un singolo GKE Gateway pubblica più InferencePool insieme ai servizi Kubernetes standard.
- Gestione avanzata del traffico:
HTTPRoutele policy supportano la suddivisione ponderata , i rollout graduali e il mirroring delle richieste. - Scalabilità indipendente: il servizio EPP viene scalato indipendentemente dal gateway.
- Integrazione cloud-native: funziona con il controller del gateway gestito di GKE , Cloud Load Balancing e gli strumenti di osservabilità esistenti.
Come funziona GKE Inference Gateway
GKE Inference Gateway utilizza le estensioni dell'API Gateway e la logica di routing specifica del modello per gestire le richieste dei client a un modello di AI. I passaggi seguenti descrivono il flusso delle richieste.
Come funziona il flusso delle richieste
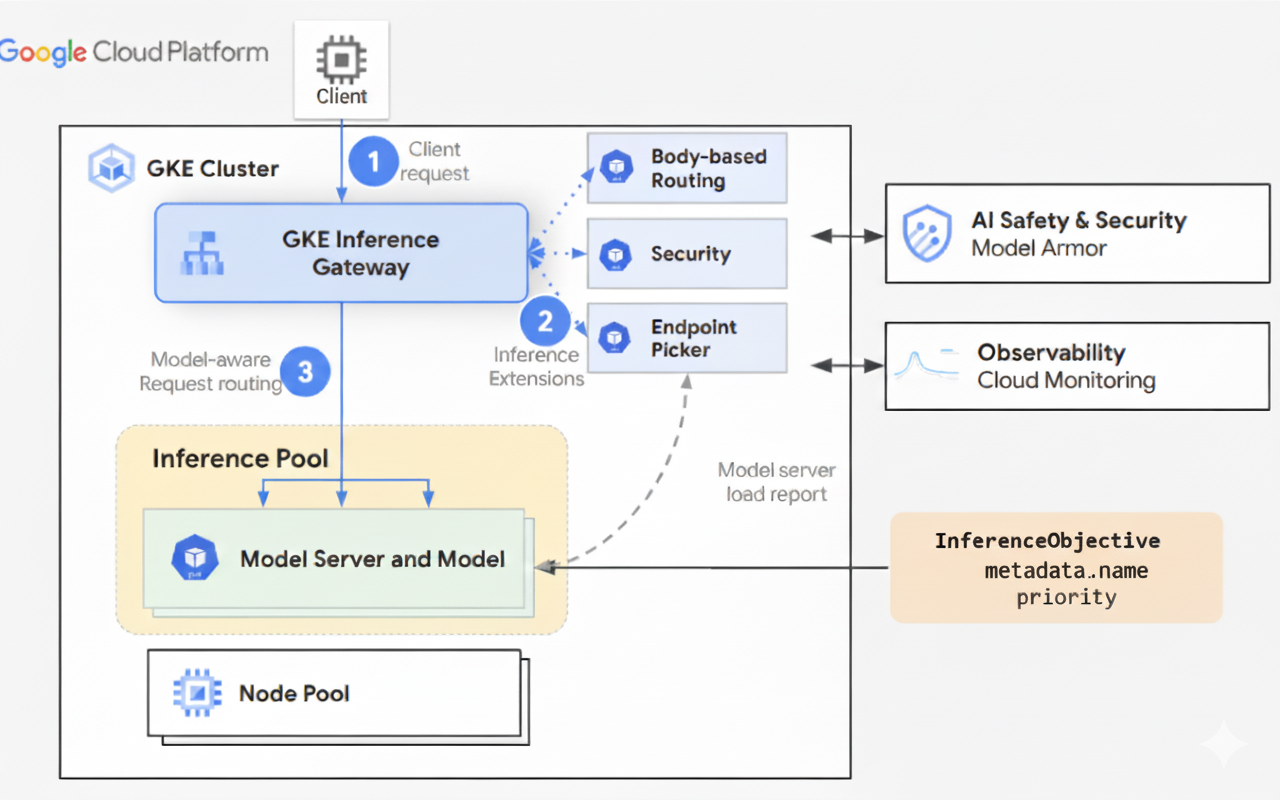
GKE Inference Gateway instrada le richieste dei client dalla richiesta iniziale a un'istanza del modello. Questa sezione descrive come GKE Inference Gateway gestisce le richieste. Questo flusso di richieste è comune a tutti i client.
- Il client invia una richiesta, formattata come descritto nella OpenAI API specifica, a il modello in esecuzione in GKE.
GKE Inference Gateway elabora la richiesta utilizzando le seguenti estensioni di inferenza:
- Estensione di routing basata sul corpo: estrae l'identificatore del modello dal
corpo della richiesta del client e lo invia a GKE Inference Gateway.
GKE Inference Gateway utilizza quindi questo identificatore per instradare la richiesta in base alle regole definite nell'oggetto
HTTPRoutedell'API Gateway. Il routing del corpo della richiesta è simile al routing basato sul percorso dell'URL. La differenza è che il routing del corpo della richiesta utilizza i dati del corpo della richiesta. - Estensione di sicurezza: utilizza Model Armor, NVIDIA NeMo Guardrails, o soluzioni di terze parti supportate per applicare policy di sicurezza specifiche del modello, che includono filtro dei contenuti, rilevamento delle minacce, sanificazione e logging. L'estensione di sicurezza applica queste policy ai percorsi di elaborazione di richieste e risposte.
- llm-d Endpoint Picker (EPP): monitora le metriche chiave dei server dei modelli all'interno di InferencePool e instrada la richiesta alla replica del modello ottimale. Per ulteriori informazioni, consulta Router llm-d.
- Estensione di routing basata sul corpo: estrae l'identificatore del modello dal
corpo della richiesta del client e lo invia a GKE Inference Gateway.
GKE Inference Gateway utilizza quindi questo identificatore per instradare la richiesta in base alle regole definite nell'oggetto
GKE Inference Gateway instrada la richiesta alla replica del modello restituita dall'estensione di selezione dell'endpoint.
Il seguente diagramma illustra il flusso delle richieste da un client a un'istanza del modello tramite GKE Inference Gateway.
Come funziona la distribuzione del traffico
GKE Inference Gateway distribuisce dinamicamente le richieste di inferenza ai server dei modelli all'interno dell'oggetto InferencePool. Ciò contribuisce a ottimizzare l'utilizzo delle risorse e a mantenere le prestazioni in condizioni di carico variabili. GKE Inference Gateway utilizza i seguenti due meccanismi per gestire la distribuzione del traffico:
Selezione dell'endpoint: seleziona dinamicamente il server dei modelli più adatto per gestire una richiesta di inferenza. Monitora il carico e la disponibilità del server, quindi prende decisioni di routing ottimali calcolando un
scoreper ogni server combinando una serie di euristiche di ottimizzazione:- Routing con riconoscimento della cache dei prefissi: GKE Inference Gateway tiene traccia degli indici della cache dei prefissi disponibili su ogni server dei modelli e assegna un punteggio più alto a un server con una corrispondenza della cache dei prefissi più lunga.
- Routing con riconoscimento del carico: GKE Inference Gateway monitora il carico del server (utilizzo della cache KV e profondità della coda in attesa) e assegna un punteggio più alto a un server con un carico inferiore.
- Routing con riconoscimento di LoRA: quando la pubblicazione dinamica di LoRA è abilitata, GKE Inference Gateway monitora gli adattatori LoRA attivi per server e assegna un punteggio più alto a un server con l'adattatore LoRA richiesto attivo o spazio aggiuntivo per caricare dinamicamente l'adattatore LoRA richiesto. Viene selezionato un server con il punteggio totale più alto di tutti i precedenti.
Accodamento e eliminazione: gestisce il flusso delle richieste e impedisce il sovraccarico del traffico. GKE Inference Gateway archivia le richieste in entrata in una coda e assegna la priorità alle richieste in base alla priorità definita.
GKE Inference Gateway utilizza un sistema di Priority numerico, noto anche come Criticality, per gestire il flusso delle richieste e prevenire il sovraccarico. Questa Priority è un campo intero facoltativo definito dall'utente per ogni InferenceObjective. Un valore più alto indica una richiesta più importante. Quando il sistema è sotto pressione, le richieste con una Priority inferiore a 0 vengono considerate a priorità inferiore e vengono eliminate per prime, restituendo un errore 429 per proteggere i carichi di lavoro più critici. Per impostazione predefinita, la Priority è 0. Le richieste vengono eliminate a causa della priorità solo se la relativa Priority è impostata esplicitamente su un valore inferiore a 0. Questo sistema ti consente di dare la priorità al traffico di inferenza online sensibile alla latenza rispetto ai job batch meno sensibili al tempo.
GKE Inference Gateway supporta l'inferenza di streaming per applicazioni come chatbot e traduzione live, che richiedono aggiornamenti continui o quasi in tempo reale. L'inferenza di streaming fornisce risposte in blocchi o segmenti incrementali, anziché un singolo output completo. Se si verifica un errore durante una risposta di streaming, lo stream viene terminato e il client riceve un messaggio di errore. GKE Inference Gateway non riprova le risposte di streaming.
Esplorare esempi di applicazioni
Questa sezione fornisce esempi di utilizzo di GKE Inference Gateway per affrontare vari scenari di applicazioni di AI generativa.
Esempio 1: pubblicare più modelli di AI generativa su un cluster GKE
Un'azienda vuole eseguire il deployment di più modelli linguistici di grandi dimensioni (LLM) per pubblicare diversi carichi di lavoro. Ad esempio, potrebbe voler eseguire il deployment di un modello Gemma3 per un'interfaccia chatbot e di un modello DeepSeek per un'applicazione di consigli. L'azienda deve garantire prestazioni di pubblicazione ottimali per questi LLM.
Utilizzando GKE Inference Gateway, puoi eseguire il deployment di questi LLM sul tuo cluster GKE con la configurazione dell'acceleratore scelta in un InferencePool. Puoi quindi instradare le richieste in base al nome del modello (ad esempio chatbot e recommender) e alla proprietà Priority.
Il seguente diagramma illustra come GKE Inference Gateway instrada le richieste a modelli diversi in base al nome del modello e alla Priority.
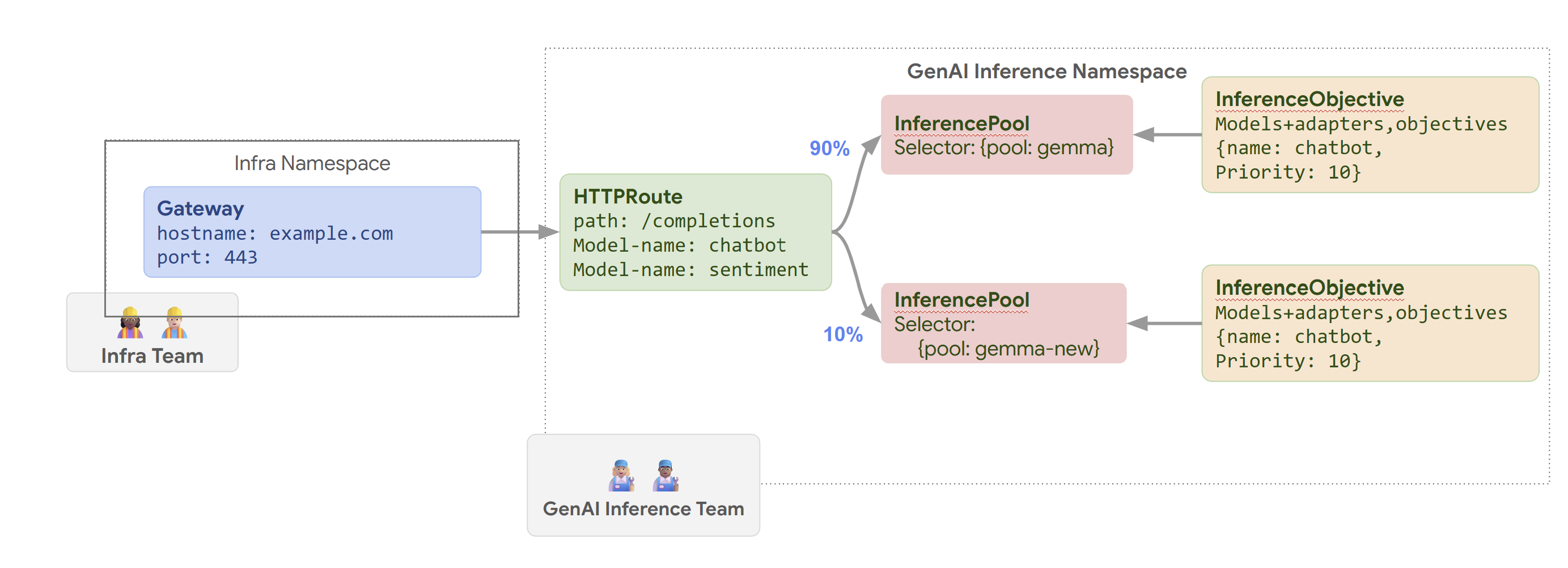
Questo diagramma illustra come una richiesta a un servizio GenAI su example.com/completions viene gestita da GKE Inference Gateway. La richiesta raggiunge prima un Gateway nello spazio dei nomi Infra. Questo Gateway inoltra la richiesta a un HTTPRoute nello spazio dei nomi GenAI Inference, configurato per gestire le richieste per i modelli di chatbot e sentiment. Per il modello di chatbot, HTTPRoute suddivide il traffico: il 90% viene indirizzato a un InferencePool che esegue la versione corrente del modello (selezionata da {pool: gemma}), mentre il 10% va a un pool con una versione più recente ({pool: gemma-new}), in genere per i test canary.
Entrambi i pool sono collegati a un InferenceObjective che assegna una Priority di 10 alle richieste per il modello di chatbot, garantendo che queste richieste vengano trattate come ad alta priorità.
Esempio 2: pubblicare gli adattatori LoRA su un acceleratore condiviso
Un'azienda vuole erogare LLM per l'analisi dei documenti e si concentra sui segmenti di pubblico in più lingue, come inglese e spagnolo. Ha ottimizzato i modelli per ogni lingua, ma deve utilizzare in modo efficiente la capacità di GPU e TPU. Puoi utilizzare GKE Inference Gateway per eseguire il deployment di adattatori ottimizzati con LoRA dinamici per ogni lingua (ad esempio, english-bot e spanish-bot) su un modello di base comune (ad esempio, llm-base) e un acceleratore. In questo modo puoi ridurre il numero di acceleratori richiesti comprimendo più modelli su un acceleratore comune.
Il seguente diagramma illustra come GKE Inference Gateway pubblica più adattatori LoRA su un acceleratore condiviso.

Passaggi successivi
- Eseguire il deployment di GKE Inference Gateway
- Personalizzare la configurazione di GKE Inference Gateway
- Erogare un LLM con GKE Inference Gateway
- Utilizzare il routing basato sulla latenza prevista con GKE Inference Gateway(anteprima)