
בדף הזה מוסברים המושגים והתכונות העיקריים של Google Kubernetes Engine (GKE) Inference Gateway, תוסף ל-GKE Gateway שמאפשר להפעיל אפליקציות של AI גנרטיבי בצורה אופטימלית.
בדף הזה אנחנו יוצאים מנקודת הנחה שאתם מכירים את הנושאים הבאים:
- תזמור של AI/ML ב-GKE
- טרמינולוגיה של AI גנרטיבי
- מושגים של רשתות GKE, כולל Services ו-GKE Gateway API
- איזון עומסים ב- Google Cloud, ובמיוחד איך מאזני עומסים פועלים עם GKE
הדף הזה מיועד לאנשים עם הפרופילים הבאים:
- מהנדסי למידת מכונה (ML), אדמינים ומפעילים של פלטפורמות ומומחים לנתונים ול-AI שמעוניינים להשתמש ביכולות של Kubernetes לארגון קונטיינרים כדי להציג עומסי עבודה של AI/ML.
- אדריכלי ענן ומומחי רשתות שיוצרים אינטראקציה עם רשתות Kubernetes.
סקירה כללית
GKE Inference Gateway הוא תוסף ל-GKE Gateway שמספק ניתוב אופטימלי ואיזון עומסים להצגת עומסי עבודה (workloads) של בינה מלאכותית (AI) גנרטיבית. הוא מפשט את הפריסה, הניהול והמעקב של עומסי עבודה של הסקת מסקנות מ-AI.
כדי לבחור את אסטרטגיית איזון העומסים האופטימלית לעומסי העבודה של AI/ML, אפשר לעיין במאמר בנושא בחירת אסטרטגיית איזון עומסים להסקת מסקנות מ-AI ב-GKE.
תכונות ויתרונות
GKE Inference Gateway מספק את היכולות המרכזיות הבאות כדי להפעיל ביעילות מודלים של AI גנרטיבי עבור אפליקציות AI גנרטיבי ב-GKE:
- מדדים נתמכים:
-
KV cache hits: מספר החיפושים המוצלחים במטמון של זוגות מפתח/ערך (KV). - GPU or TPU utilization: אחוז הזמן שבו ה-GPU או ה-TPU מעבדים באופן פעיל.
- אורך תור הבקשות: מספר הבקשות שממתינות לעיבוד.
-
- איזון עומסים אופטימלי להסקת מסקנות: חלוקת הבקשות כדי לשפר את הביצועים של מודל ה-AI. הוא משתמש במדדים משרתי מודלים, כמו
KV cache hitsו-queue length of pending requests, כדי לצרוך מאיצים (כמו מעבדי GPU ו-TPU) בצורה יעילה יותר עבור עומסי עבודה של AI גנרטיבי. ההגדרה הזו מפעילה את התכונה Prefix-Cache Aware Routing, תכונה חשובה ששולחת בקשות עם הקשר משותף, שזוהה על ידי ניתוח גוף הבקשה, לאותו עותק של המודל על ידי הגדלת מספר הפעמים שבהן נשלפת תשובה מהמטמון. הגישה הזו מצמצמת באופן משמעותי את החישובים המיותרים ומשפרת את הזמן עד לטוקן הראשון, ולכן היא יעילה מאוד ל-AI בממשק שיחה, ל-Retrieval-Augmented Generation (יצירה משולבת-אחזור, RAG) ולעומסי עבודה אחרים של AI גנרטיבי שמבוססים על תבניות. - פרסום מודלים דינמיים שעברו כוונון עדין של LoRA: תמיכה בפרסום מודלים דינמיים שעברו כוונון עדין של LoRA במאיץ משותף. הגישה הזו מצמצמת את מספר המעבדים הגרפיים (GPU) ומעבדי ה-TPU שנדרשים להפעלת מודלים, באמצעות ריבוב של כמה מודלים שעברו כוונון עדין של LoRA על מודל בסיס משותף ומאיץ.
- שינוי גודל אוטומטי אופטימלי להסקת מסקנות: ה-GKE Horizontal Pod Autoscaler (HPA) משתמש במדדים של שרת המודלים כדי לשנות את הגודל באופן אוטומטי, וכך עוזר להבטיח שימוש יעיל במשאבי מחשוב וביצועים אופטימליים של הסקת מסקנות.
- ניתוב מודע-מודל: ניתוב של בקשות הסקה על סמך שמות המודלים שמוגדרים ב
OpenAI APIמפרטים באשכול GKE. אתם יכולים להגדיר מדיניות ניתוב של שערים, כמו פיצול תנועה ושיקוף בקשות, כדי לנהל גרסאות שונות של מודלים ולפשט את ההשקה של מודלים. לדוגמה, אפשר להפנות בקשות לשם דגם ספציפי לInferencePoolאובייקטים שונים, כשכל אחד מהם מציג גרסה שונה של המודל. למידע נוסף על הגדרת האפשרות הזו, אפשר לעיין במאמר הגדרת ניתוב לפי גוף ההודעה. - סינון תוכן ואמצעי בטיחות משולבים של AI: GKE Inference Gateway משולב עם Google Cloud הגנה מוגברת על המודל כדי להחיל בדיקות בטיחות של AI וסינון תוכן על הנחיות ותשובות בשער. אפשר גם להשתמש ב-NVIDIA NeMo Guardrails. הגנה מוגברת על המודל מספקת יומנים של בקשות, תגובות ועיבוד לניתוח ולאופטימיזציה רטרוספקטיביים. הממשקים הפתוחים של GKE Inference Gateway מאפשרים לספקי צד שלישי ולמפתחים לשלב שירותים בהתאמה אישית בתהליך של בקשת ההסקה.
- פרסום מודלים ספציפיים
Priority: מאפשר לציין את הפרסוםPriorityשל מודלים של AI. תעדוף בקשות שרגישות לזמן הטעינה על פני משימות באצווה של הסקת מסקנות שסובלות זמן טעינה. לדוגמה, אתם יכולים לתת עדיפות לבקשות מאפליקציות שרגישות לזמן האחזור, ולבטל משימות שפחות רגישות לזמן האחזור כשיש מגבלות על המשאבים. - יכולת מעקב אחר הסקת מסקנות: מספקת מדדי מעקב אחר בקשות להסקת מסקנות, כמו קצב בקשות, זמן אחזור, שגיאות ורוויה. מעקב אחרי הביצועים וההתנהגות של שירותי ההסקה באמצעות Cloud Monitoring ו-Cloud Logging, תוך שימוש בלוחות בקרה מיוחדים שנוצרו מראש לקבלת תובנות מפורטות. מידע נוסף זמין במאמר בנושא הצגת לוח הבקרה של GKE Inference Gateway.
- ניהול מתקדם של API באמצעות Apigee: משתלב עם Apigee כדי לשפר את שער ההסקה באמצעות תכונות כמו אבטחת API, הגבלת קצב של יצירת בקשות ומכסות. הוראות מפורטות זמינות במאמר הגדרת Apigee לאימות ולניהול API.
- יכולת הרחבה: בנוי על תוסף של API להסקת מסקנות של Kubernetes Gateway בקוד פתוח, שניתן להרחבה ותומך באלגוריתם לבחירת נקודות קצה בניהול המשתמש.
הסבר על מושגי מפתח
GKE Inference Gateway הוא שיפור של GKE Gateway הקיים, שמשתמש באובייקטים של GatewayClass. ב-GKE Inference Gateway מוצגים ההגדרות החדשות הבאות של משאבים מותאמים אישית (CRD) של Gateway API, בהתאם להרחבת OSS Kubernetes Gateway API ל-Inference:
- אובייקט
InferencePool: מייצג קבוצה של Pods (קונטיינרים) שחולקים את אותה הגדרת מחשוב, סוג מאיץ, מודל שפה בסיסי ושרת מודלים. הוא מאגד באופן לוגי את משאבי פרסום המודל של ה-AI ומנהל אותם. אובייקטInferencePoolיחיד יכול להתפרס על פני כמה פודים בצמתים שונים של GKE, ומספק יכולת הרחבה וזמינות גבוהה. - אובייקט
InferenceObjective: מציין את שם מודל הצגת המודעות מתוךInferencePoolבהתאם למפרטOpenAI API. האובייקטInferenceObjectiveמציין גם את מאפייני ההצגה של המודל, כמוPriorityשל מודל ה-AI. GKE Inference Gateway נותן עדיפות לעומסי עבודה עם ערך עדיפות גבוה יותר. כך תוכלו לבצע מולטיפלקסינג של עומסי עבודה של AI שרגישים לזמן אחזור ועומסי עבודה של AI שסובלניים לזמן אחזור באשכול GKE. אפשר גם להגדיר אתInferenceObjectiveהאובייקט כך שיציג מודלים שעברו כוונון עדין של LoRA.
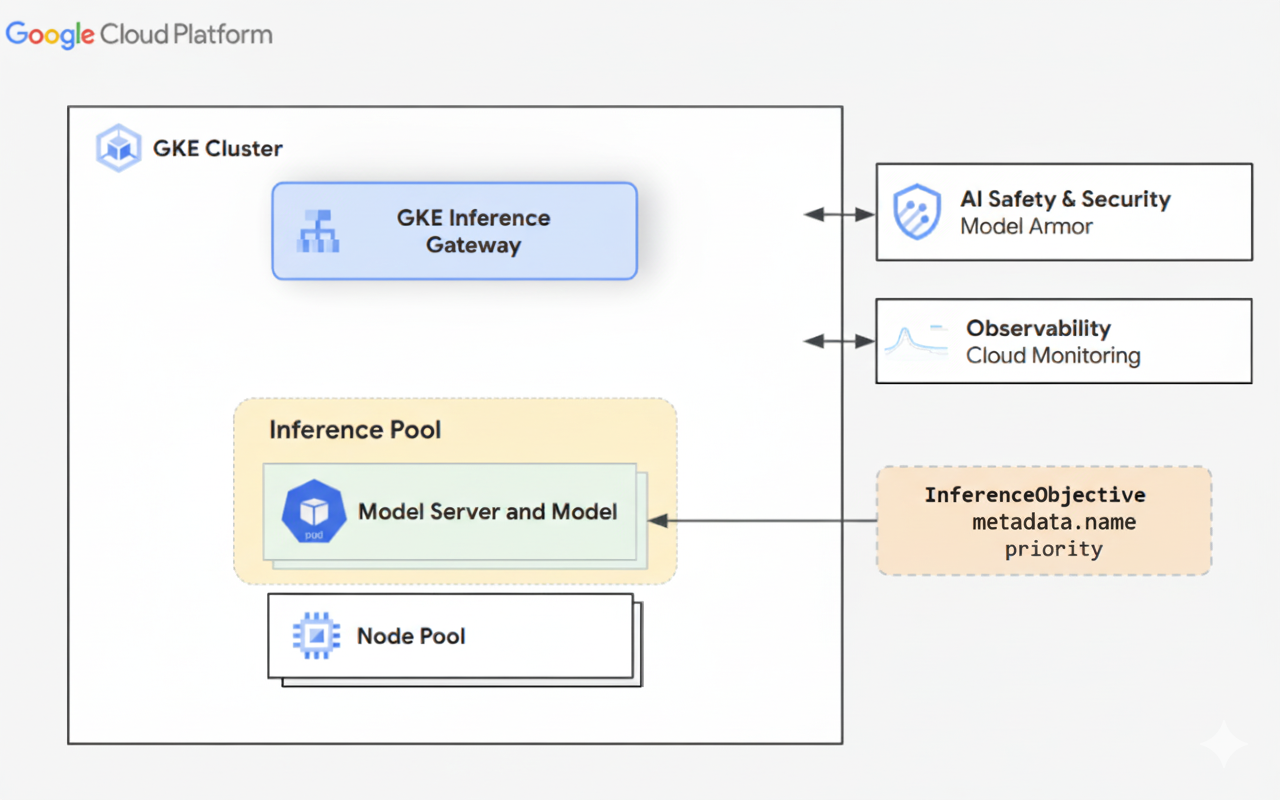
הדיאגרמה הבאה ממחישה את GKE Inference Gateway ואת השילוב שלו עם AI Safety, ניראות (observability) ופרסום המודל בתוך אשכול GKE.
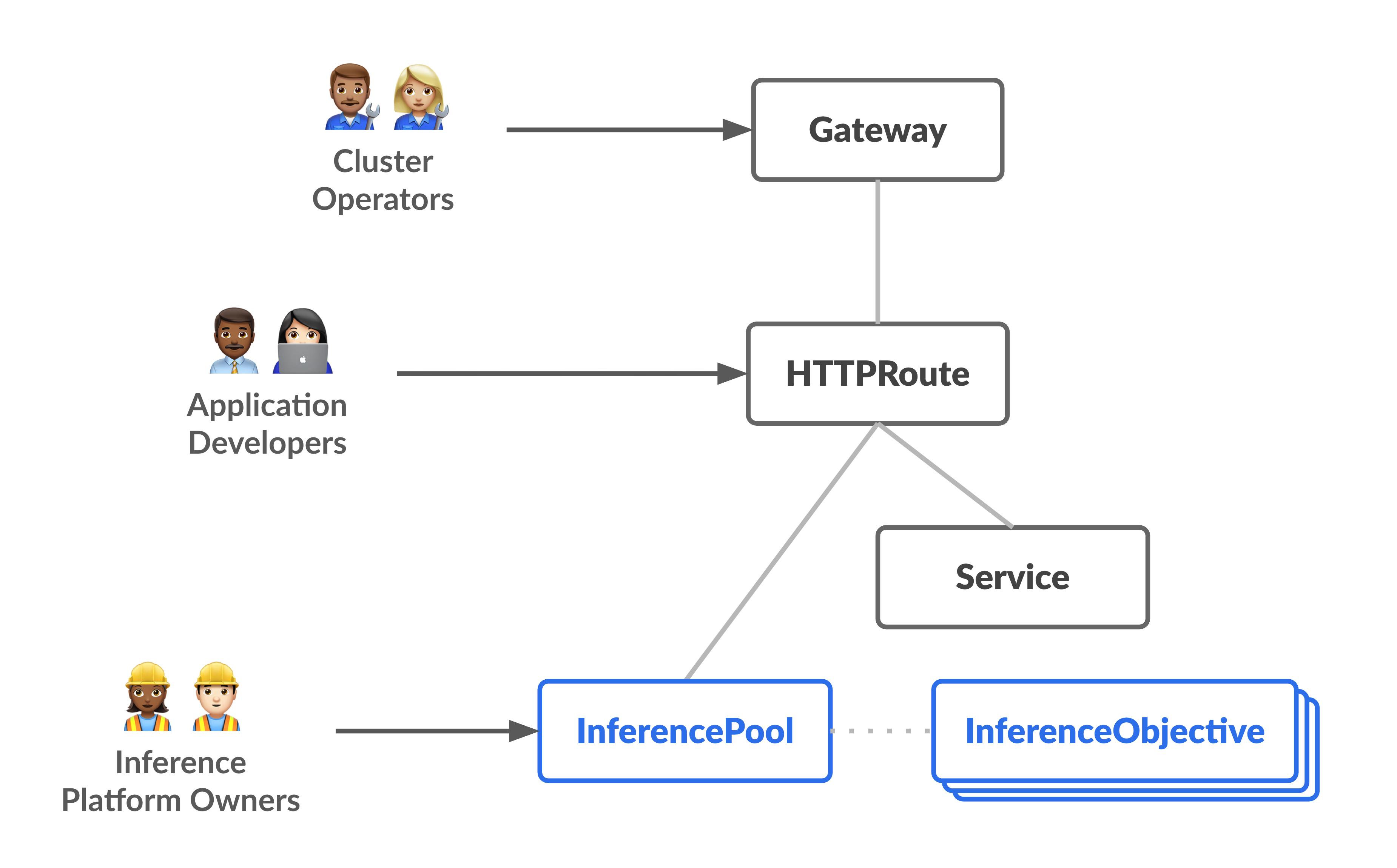
הדיאגרמה הבאה ממחישה את מודל המשאבים שמתמקד ב-2 פרסונות חדשות שמתמקדות בהיקש ובמשאבים שהן מנהלות.
איך פועל GKE Inference Gateway
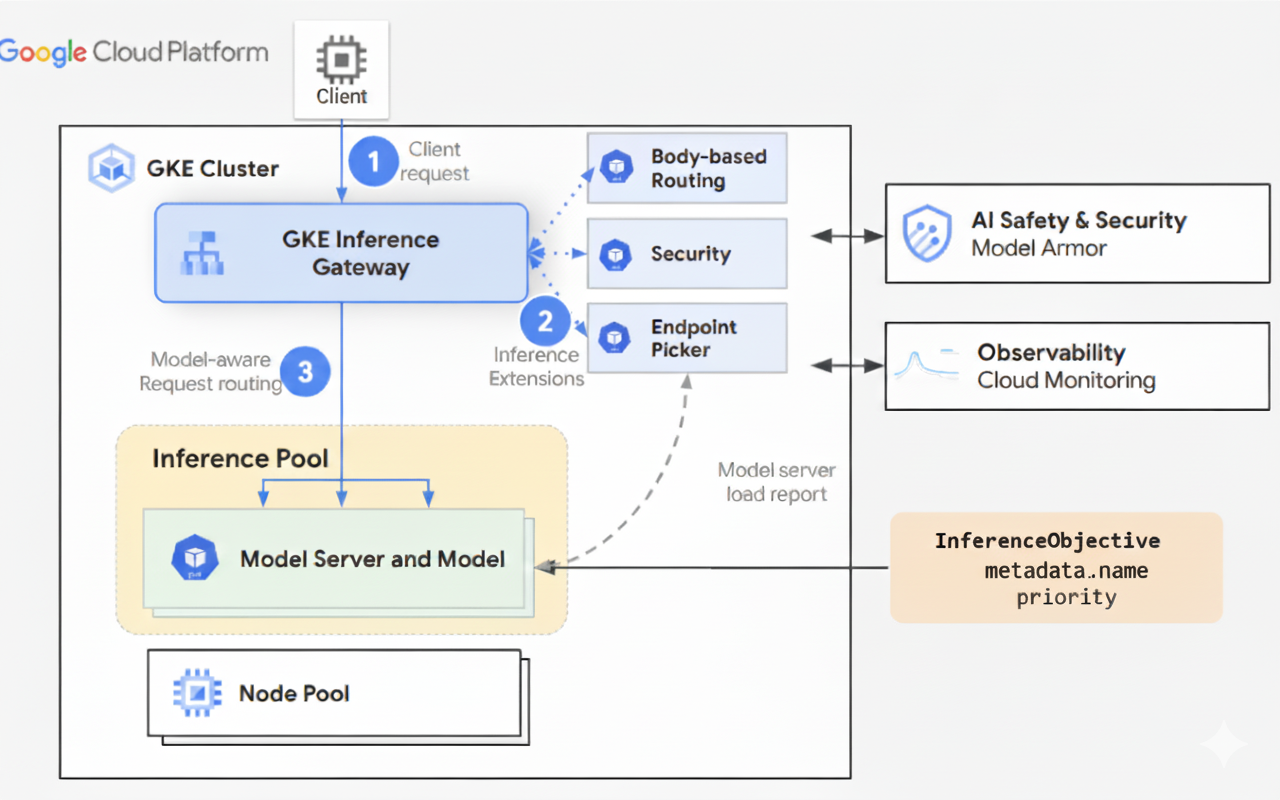
GKE Inference Gateway משתמש בתוספים של Gateway API ובלוגיקת ניתוב ספציפית למודל כדי לטפל בבקשות של לקוחות למודל AI. בשלבים הבאים מתואר תהליך הבקשה.
איך מתנהל תהליך הבקשה
GKE Inference Gateway מנתב בקשות של לקוחות מהבקשה הראשונית למופע של מודל. בקטע הזה מוסבר איך GKE Inference Gateway מטפל בבקשות. תהליך הבקשה הזה משותף לכל הלקוחות.
- הלקוח שולח בקשה בפורמט שמתואר במפרט של OpenAI API, למודל שפועל ב-GKE.
- GKE Inference Gateway מעבד את הבקשה באמצעות תוספי ההסקה הבאים:
- תוסף לניתוב מבוסס-גוף: מחלץ את מזהה המודל מגוף בקשת הלקוח ושולח אותו ל-GKE Inference Gateway.
לאחר מכן, GKE Inference Gateway משתמש במזהה הזה כדי לנתב את הבקשה על סמך כללים שמוגדרים באובייקט Gateway API
HTTPRoute. ניתוב גוף הבקשה דומה לניתוב שמבוסס על נתיב כתובת ה-URL. ההבדל הוא שבניתוב של גוף הבקשה נעשה שימוש בנתונים מגוף הבקשה. - תוסף אבטחה: משתמש ב-הגנה מוגברת על המודל, ב-NVIDIA NeMo Guardrails או בפתרונות נתמכים של צד שלישי כדי לאכוף מדיניות אבטחה ספציפית למודל, שכוללת סינון תוכן, זיהוי איומים, ניקוי ורישום ביומן. תוסף האבטחה מחיל את כללי המדיניות האלה על נתיבי העיבוד של הבקשות ושל התגובות.
- תוסף לבחירת נקודות קצה: עוקב אחרי מדדי מפתח משרתי מודלים בתוך
InferencePool. הוא עוקב אחרי השימוש במטמון של צמדי מפתח/ערך (KV-cache), אורך התור של בקשות בהמתנה, אינדקסים של מטמון קידומות ומתאמי LoRA פעילים בכל שרת מודל. לאחר מכן המערכת מנתבת את הבקשה לשכפול האופטימלי של המודל על סמך המדדים האלה, כדי לצמצם את זמן האחזור ולמקסם את קצב העברת הנתונים עבור הסקת מסקנות מ-AI.
- תוסף לניתוב מבוסס-גוף: מחלץ את מזהה המודל מגוף בקשת הלקוח ושולח אותו ל-GKE Inference Gateway.
לאחר מכן, GKE Inference Gateway משתמש במזהה הזה כדי לנתב את הבקשה על סמך כללים שמוגדרים באובייקט Gateway API
- GKE Inference Gateway מנתב את הבקשה אל הרפליקה של המודל שהוחזרה על ידי התוסף לבחירת נקודת הקצה.
התרשים הבא מציג את זרימת הבקשות מלקוח למופע של מודל דרך GKE Inference Gateway.
איך חלוקת התנועה פועלת
GKE Inference Gateway מחלק באופן דינמי בקשות הסקה לשרתי מודלים באובייקט InferencePool. כך אפשר לבצע אופטימיזציה של ניצול המשאבים ולשמור על רמת הביצועים בתנאי עומס משתנים.
שער ההסקה של GKE משתמש בשני המנגנונים הבאים כדי לנהל את חלוקת התנועה:
בחירת נקודת קצה: בחירה דינמית של שרת המודל המתאים ביותר לטיפול בבקשת הסקה. הוא עוקב אחרי עומס השרתים והזמינות שלהם, ואז מקבל החלטות אופטימליות לגבי ניתוב על ידי חישוב
scoreלכל שרת, בשילוב של מספר היוריסטיקות לאופטימיזציה:- ניתוב עם מודעות למטמון של קידומות: GKE Inference Gateway עוקב אחרי אינדקסים זמינים של מטמון קידומות בכל שרת מודל, ונותן ניקוד גבוה יותר לשרת עם התאמה ארוכה יותר של מטמון קידומות.
- ניתוב מודע לעומס: GKE Inference Gateway עוקב אחרי עומס השרת (ניצול מטמון KV ועומק התור בהמתנה), ונותן ניקוד גבוה יותר לשרת עם עומס נמוך יותר.
- LoRA aware routing: כשמופעלת הקצאת LoRA דינמית, GKE Inference Gateway עוקב אחרי מתאמי LoRA פעילים לכל שרת, ומעניק ניקוד גבוה יותר לשרת עם מתאם LoRA פעיל שנדרש, או מקום נוסף לטעינה דינמית של מתאם LoRA שנדרש. נבחר שרת עם הציון הכולל הכי גבוה מבין כל השרתים הקודמים.
הוספה לתור והסרה: ניהול של זרימת הבקשות ומניעת עומס יתר בתנועה. GKE Inference Gateway מאחסן בקשות נכנסות בתור ומדרג את הבקשות לפי העדיפות שהוגדרה.
GKE Inference Gateway משתמש במערכת מספרית Priority, שנקראת גם Criticality, כדי לנהל את זרימת הבקשות ולמנוע עומס יתר. השדה Priority הוא שדה אופציונלי של מספר שלם שמוגדר על ידי המשתמש לכל InferenceObjective. ערך גבוה יותר מציין בקשה חשובה יותר. כשהמערכת נמצאת בעומס, בקשות עם Priority נמוך מ-0 נחשבות בעדיפות נמוכה יותר והן הראשונות שייפסלו, ותוחזר שגיאת 429 כדי להגן על עומסי עבודה קריטיים יותר. ערך ברירת המחדל של Priority הוא 0. בקשות נפסלות בגלל עדיפות רק אם הערך של Priority מוגדר במפורש כערך נמוך מ-0. המערכת הזו מאפשרת לתת עדיפות לתנועת נתונים של הסקת מסקנות אונליין שרגישה לזמן האחזור, על פני עבודות אצווה שפחות רגישות לזמן.
שער ההסקה של GKE תומך בהסקה בסטרימינג לאפליקציות כמו צ'אטבוטים ותרגום בזמן אמת, שדורשות עדכונים רציפים או כמעט בזמן אמת. הסקת מסקנות בזמן אמת מספקת תשובות במקטעים מצטברים, במקום פלט מלא אחד. אם מתרחשת שגיאה במהלך תגובה של סטרימינג, הסטרימינג מסתיים והלקוח מקבל הודעת שגיאה. GKE Inference Gateway לא מנסה שוב לשלוח תגובות בסטרימינג.
דוגמאות לשימוש באפליקציה
בקטע הזה מוצגות דוגמאות לשימוש ב-GKE Inference Gateway כדי לטפל בתרחישי שימוש שונים באפליקציות של AI גנרטיבי.
דוגמה 1: הצגת כמה מודלים של AI גנרטיבי באשכול GKE
חברה רוצה לפרוס כמה מודלים גדולים של שפה (LLM) כדי לשרת עומסי עבודה שונים. לדוגמה, הם יכולים לפרוס מודל Gemma3 לממשק צ'אטבוט ומודל Deepseek לאפליקציית המלצות. החברה צריכה להבטיח ביצועים אופטימליים של הצגת המודעות עבור מודלים גדולים של שפה (LLM).
באמצעות GKE Inference Gateway, תוכלו לפרוס את מודלי ה-LLM האלה באשכול GKE עם תצורת ההאצה שבחרתם ב-InferencePool. לאחר מכן תוכלו להפנות בקשות על סמך שם המודל (כמו chatbot ו-recommender) והמאפיין Priority.
בתרשים הבא מוצג אופן הניתוב של בקשות על ידי GKE Inference Gateway למודלים שונים, על סמך שם המודל ו-Priority.
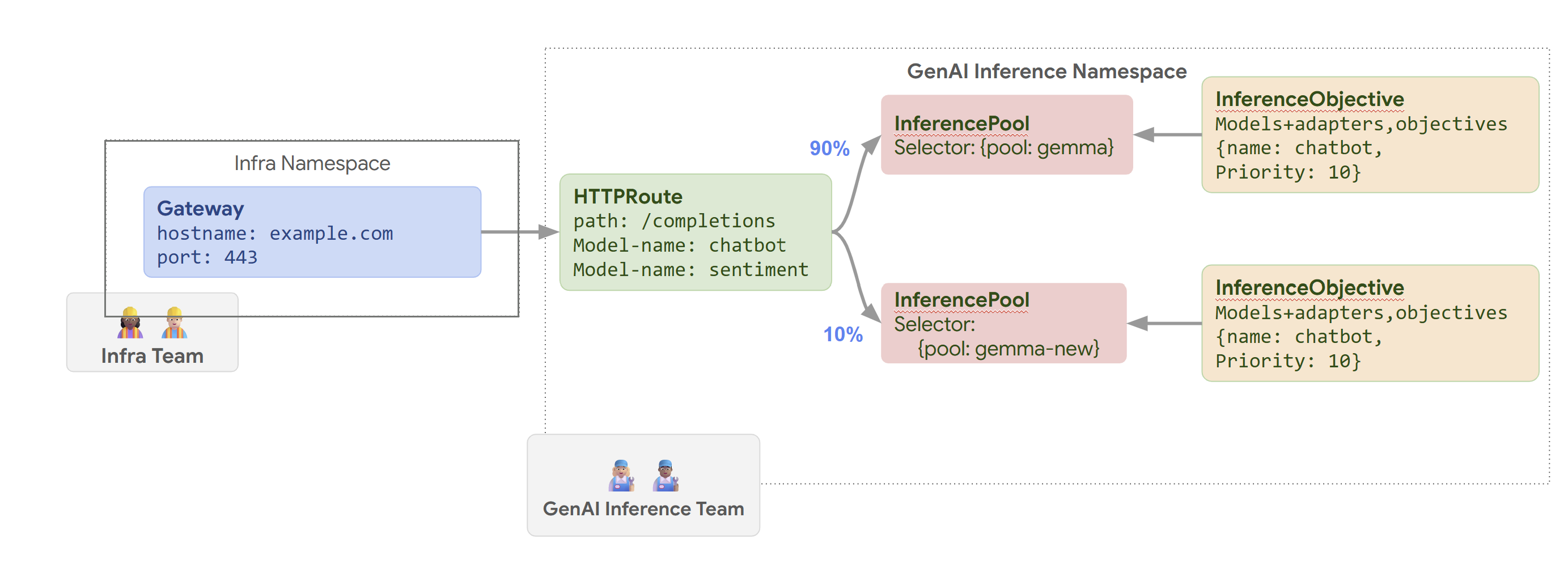
בתרשים הזה מוצג אופן הטיפול בבקשה לשירות AI גנרטיבי ב-example.com/completions על ידי GKE Inference Gateway. הבקשה מגיעה קודם ל-Gateway במרחב השמות Infra. ה-Gateway הזה מעביר את הבקשה אל HTTPRoute במרחב השמות GenAI Inference, שמוגדר לטפל בבקשות למודלים של צ'אטבוט וניתוח סנטימנט. במודל הצ'אט בוט, HTTPRoute מפצל את התנועה: 90% מופנים אל InferencePool שמריץ את גרסת המודל הנוכחית (שנבחרה על ידי {pool: gemma}), ו-10% מופנים אל מאגר עם גרסה חדשה יותר ({pool: gemma-new}), בדרך כלל לבדיקת גרסה ראשונית (canary).
שני המאגרים מקושרים ל-InferenceObjective שמקצה Priority של 10 לבקשות של מודל הצ'אטבוט, כדי להבטיח שהבקשות האלה יטופלו בעדיפות גבוהה.
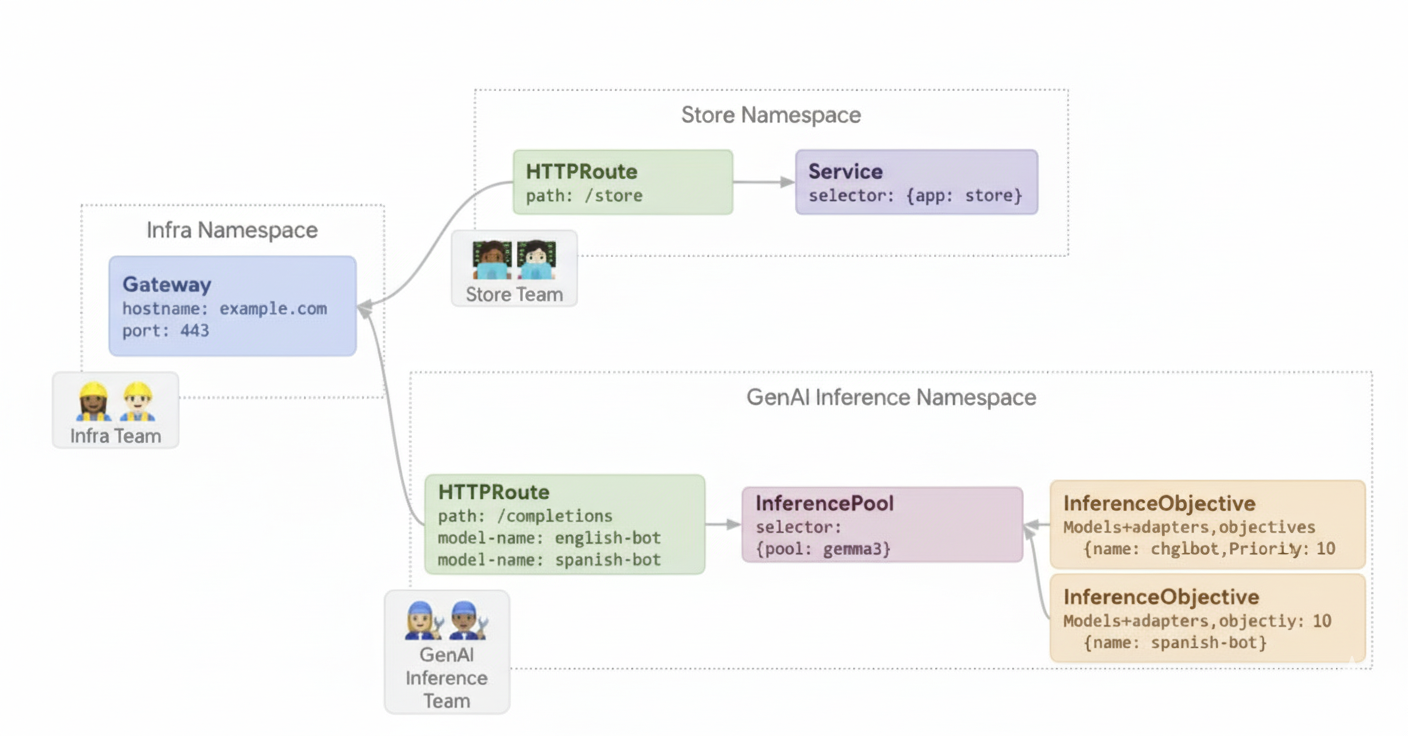
דוגמה 2: הצגת מתאמי LoRA במאיץ משותף
חברה רוצה להשתמש במודלים של שפה גדולה (LLM) לניתוח מסמכים, ומתמקדת בקהלים בכמה שפות, כמו אנגלית וספרדית. הם כוונו במדויק את המודלים לכל שפה, אבל הם צריכים להשתמש ביעילות בקיבולת של ה-GPU וה-TPU שלהם. אפשר להשתמש ב-GKE Inference Gateway כדי לפרוס מתאמים דינמיים של LoRA שעברו כוונון עדין לכל שפה (לדוגמה, english-bot ו-spanish-bot) במודל בסיס משותף (לדוגמה, llm-base) ובמאיץ. כך תוכלו לצמצם את מספר המאיצים הנדרשים על ידי אריזה צפופה של כמה מודלים במאיץ משותף.
הדיאגרמה הבאה ממחישה איך GKE Inference Gateway משרת כמה מתאמי LoRA במאיץ משותף.
המאמרים הבאים
- פריסת GKE Inference Gateway
- התאמה אישית של ההגדרות של GKE Inference Gateway
- הצגת מודל LLM באמצעות GKE Inference Gateway