
このドキュメントでは、Google Kubernetes Engine(GKE)でバッチ推論ワークロードを実行するためのベスト プラクティスについて説明します。バッチ 推論は、機械学習モデルを使用して大規模な データセットに対する予測を生成するプロセスです。即時性のある 低レイテンシのレスポンスよりも、高スループットと費用対効果を優先します。
このガイドでは、バッチ推論とリクエスト バッチ処理(または動的バッチ処理)を区別します。リクエスト バッチ処理は、vLLM や SGLang などのエンジンでアクセラレータの効率を最適化するために、同時リアルタイム リクエストをグループ化するサーバーサイドの手法です。リクエスト バッチ処理は、バッチ推論ワークロードに適用できます。
このガイドのベスト プラクティスでは、次の 2 種類の一般的なバッチ推論パターンについて説明します。
- 非同期推論: データが生成された直後に チャンク単位で処理します。通常、レイテンシは数秒から数分です。このアプローチでは、最新のデータを必要とするニーズと、複数のアイテムを同時に処理する効率のバランスを取ります。非同期推論は、ニアリアルタイム推論と呼ばれることもあります。
- バッチ推論: スケジュールされた間隔(夜間や週単位など)で、大量の蓄積データを処理します。リソースの可用性を最大化するために、これらのジョブはピーク時以外にスケジュールされることが多いため、通常、レイテンシは数時間から数日になります。
これらの推奨事項は、 GKE での推論に関するベスト プラクティスの概要で説明されている基盤の上に構築された最適化の特殊なレイヤです。バッチ ワークロードの最適化を行う前に、モデルの選択、量子化、アクセラレータの選択に関するコアのベスト プラクティスに従っていることを確認してください。
バッチ推論処理のアーキテクチャ パターンを選択する
適切なアーキテクチャ パターンを選択することは、バッチ推論ワークロードのデプロイにおいて最も重要な決定です。レイテンシ、スループット、費用のトレードオフに影響するためです。効率を維持するには、ピーク時以外に推論スループットが受信クエリのレートを超えていることを確認して、キューが際限なく増大しないようにします。
バースト ワークには非同期推論を使用する
非同期推論は、次のように頻繁な増分更新が必要なユースケースに適しています。
- 最近のインタラクションに基づいて、数分ごとにユーザーのレコメンデーション プロファイルを更新する。
- ソーシャル メディアのメンションを 1 分間隔で処理して、リアルタイム モニタリングを行う。
- 高頻度の金融データ ストリームから市場を動かすシグナルを検出する。
- 受信した顧客フィードバックやニュース フィードの感情分析を行う。
ワークロードで数秒から数分のレイテンシが許容される場合は、このパターンを選択します。
非同期推論を実装する場合は、次の特性を考慮してください。
- レイテンシ: 最初のトークンまでの時間は、数十 秒から数分になります。
- データソース: 通常、数メガバイトから 数ギガバイトのデータセットを処理します。たとえば、Pub/Sub からのメッセージや、 短い時間枠で蓄積された Cloud Storage のファイルなどです。
- コンピューティング パターン: インフラストラクチャは、頻繁なバースト ワークを処理する継続的なサービス をサポートする必要があります。
- 費用の最適化: このパターンでは、低レイテンシのリアルタイム推論と高スループットのバッチ処理のバランスが取れています。
大規模なデータセットにはバッチ推論を使用する
バッチ推論は、次のように数時間から数日の遅延が許容される大規模なエピソード ジョブに最適です。
- 前日の金融取引に基づいて、夜間のリスク評価レポートを生成する。
- カタログ全体のプロダクト エンベディングを作成して、ダウンストリームの検索システムとレコメンデーション システムを強化する。
- モデル トレーニングまたはアーカイブ分類のために、画像の大規模なデータセットにラベルを付ける。
大量のデータを処理していて、数時間から数日のレイテンシが許容される場合は、このパターンを選択します。
バッチ推論を実装する場合は、次の特性を考慮してください。
- レイテンシ: ジョブはピーク時以外にスケジュールされることが多いため、ワークロードの開始レイテンシは通常、数分から数日になります 。
- データソース: ギガバイトからペタバイトまでの大規模なデータセットを処理します。 通常、Cloud Storage または BigQuery テーブルに保存されます。
- コンピューティング パターン: 初期化、データの処理、終了を行うエピソード バースト ジョブを使用します。
- 費用の最適化: このパターンは、従量課金制モデルで高度に最適化できます。バッチジョブには柔軟な完了ウィンドウがあるため、 Spot VM を使用して 費用を削減することをおすすめします。
スループットと費用対効果を最適化する
バッチ推論ワークロードは、中断が発生する可能性のある費用対効果の高いインフラストラクチャに最適です。
Spot VM を使用してコンピューティング費用を削減する
バッチジョブには Spot VM の割引を使用します。 通常、バッチ推論ワークロードはレイテンシと中断を許容できるため、Spot 容量の低価格に適しています。
バッチ推論コードで チェックポイント処理を 実装して、プリエンプション イベントを処理できるようにします。Spot VM がプリエンプトされた場合は、新しいノードを作成し、ゼロから再起動するのではなく、最後に処理されたバッチからワークロードを再開できます。
ワークロード バッチサイズとリクエスト バッチサイズを調整する
リソースの競合とジョブのタイムアウトを回避するには、エンジンに送信されるアイテム数(ワークロード バッチ)が、サーバーが処理できる同時リクエスト数(リクエスト バッチ)以上になるようにして、アクセラレータの使用率が低下しないようにします。
ワークロード バッチサイズを調整する
ワークロード バッチサイズは、1 つの作業単位で推論エンジンに送信されるアイテムの合計数です。これは、クライアント送信ロジックまたは Kubernetes Job 構成で、データをシャーディングするか、複数のアイテムを 1 つのリクエストにグループ化することで構成します。
最適なワークロード バッチサイズを決定するには、次の境界を使用します。
- 最小バッチサイズを計算する: ワークロード バッチサイズがリクエスト バッチサイズ以上になるようにします。たとえば、256 個のアイテムを同時に処理できるサーバーに 1 つのアイテムを送信すると、使用率が大幅に低下します。最小サイズを確認するには、vLLM の
max_num_seqs引数など、推論サーバーの構成を確認します。 複数のアイテムを 1 つのリクエストにグループ化するようにクライアント ロジックを構成することも、各ジョブがリクエスト バッチサイズを満たすか超える最小量のデータを受け取るようにデータをシャーディングすることもできます。 - 最大バッチサイズを計算する: ワークロード バッチサイズにより、
Kubernetes
Jobで定義された
activeDeadlineSecondsタイムアウト に達する前に Pod が完了するようにします。 1 つのリクエスト バッチの処理に必要な時間を見積もり、Pod が期限内に完了するようにワークロード サイズを設定します。たとえば、activeDeadlineSecondsが 3,600 秒で、起動オーバーヘッドが 600 秒の場合、最大実行時間で Pod が 3,000 秒以内に完了するようにします。
ワークロードのバッチサイズが小さすぎると、ジョブは Pod の起動オーバーヘッド(重みのダウンロード、プロビジョニング、アクセラレータの初期化)に時間を費やします。大きすぎると、GKE によって activeDeadlineSeconds タイムアウトが原因でジョブが終了し、ジョブが失敗して進行状況が失われる可能性があります。
リクエスト バッチサイズを調整する
リクエスト バッチサイズは、推論サーバーがアクセラレータで同時に処理する同時リクエストの数です。このパラメータを最適化するには、推論サーバー構成でサーバー固有のフラグ(vLLM の --max-num-seqs フラグなど)を調整します。
目標は、メモリ不足(OOM)エラーをトリガーせずに GPU 使用率を最大化することです。リクエスト バッチサイズが調整されていない場合、システムはアクセラレータの使用率が低下するか、モデルサーバーがクラッシュします。vLLM の場合は、
vLLM auto_tune
スクリプトなどのツールを使用して、特定のハードウェアの max_num_seqs 設定と max_num_batched_tokens 設定の最適な値を見つけることができます。詳細については、GKE での推論に関するベスト プラクティスの概要ガイドの
推論サーバーの構成を最適化する
をご覧ください。
非同期推論の非同期コンポーネントを実装する
非同期推論では、メッセージ バッファを使用して、取り込みレイヤを推論レイヤから切り離すことをおすすめします。
次のアーキテクチャ図は、非同期推論プラットフォームの例を示しています。このアーキテクチャは、トラフィックの急増から推論サーバーを保護し、ワーク バックログを管理し、アクセラレータの使用率を高めます。
この図は、Pub/Sub からサブスクライバー、推論ゲートウェイ、推論サーバーへのフローを示しています。結果は AlloyDB に永続化され、失敗したメッセージはデッドレター トピックに送信されます。
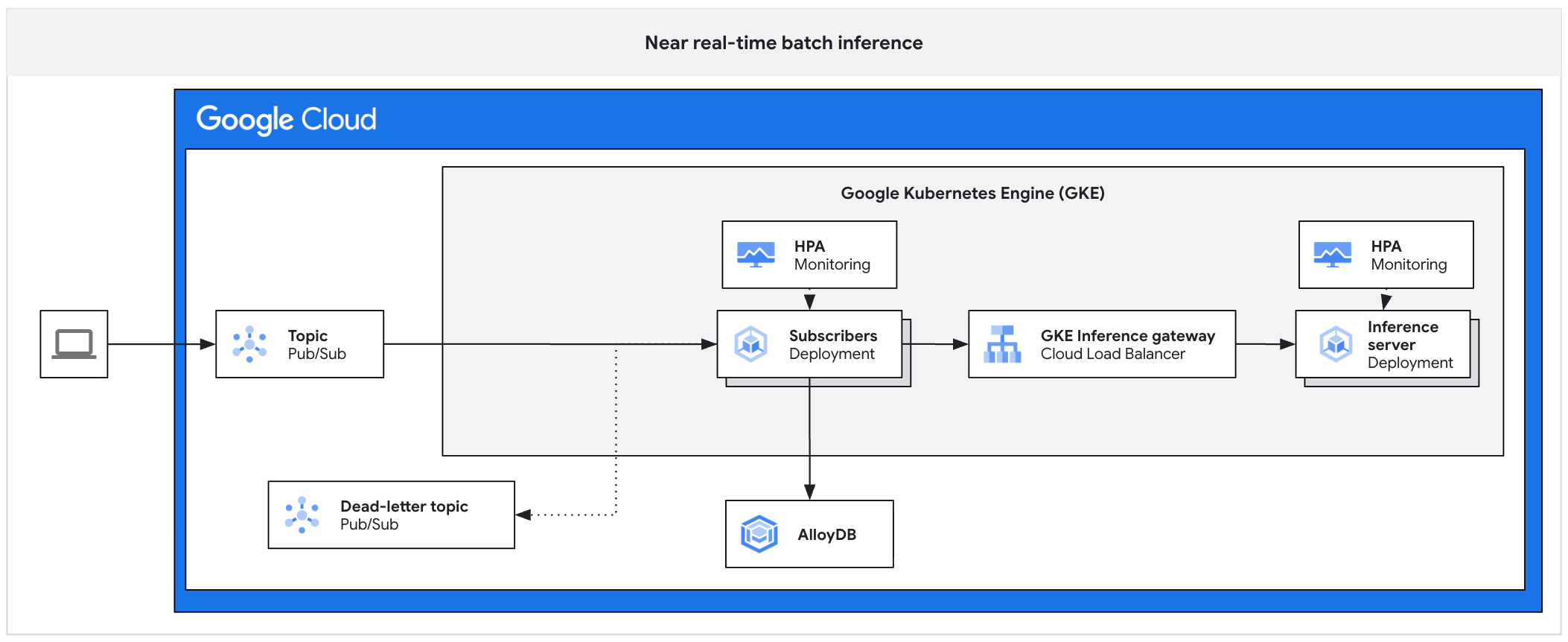
このアーキテクチャは、次のコンポーネントで構成されています。
- Pub/Sub トピック: 受信したクライアント メッセージの永続バッファとして機能し、保持期間は 7 ~ 31 日です。
- サブスクライバー: メッセージ バッチを読み取り、推論サーバーにリクエストを送信し、処理を確認するコンポーネント。
- サブスクライバー HPA:
num_undelivered_messages指標(未確認のメッセージ数)に基づいてサブスクライバー デプロイをスケーリングします。 - ストレージ: データベース(AlloyDB など)またはオブジェクト ストレージ(Cloud Storage など)を使用して推論結果を永続化します。
- 推論ゲートウェイ: 推論ワークロードをサブスクライバーに公開します。
- 推論サーバー: バッチ推論リクエストを処理します(vLLM など)。
- サーバー HPA:
vllm:num_requests_waitingなどのエンジン固有の指標に基づいて推論エンジンをスケーリングします。 - デッドレター トピック: 指数バックオフの再試行回数が設定された後に処理に失敗したメッセージをキャプチャします。
詳細については、GitHub のリファレンス実装をご覧ください。
リクエストをバッファリングして集約する
リクエストのフローを管理するには、次の操作を行います。
- Pub/Sub を永続バッファとして使用する: Pub/Sub を実装して、推論リクエストを永続的に保存します。この設定は、コンシューマーが処理できるまでリクエストを保持する FIFO バッファとして機能し、バースト トラフィック時のサーバーの過負荷を防ぎます。
- クライアントサイドのフロー制御で pull サブスクリプションを使用する: pull サブスクリプション モデルを構成します。これにより、サブスクライバー アプリケーションは、処理できる場合にのみメッセージを明示的にリクエストできるため、消費率を完全に制御できます。
- メッセージを集約してサーバー バッチサイズを埋める: 1 つの Pub/Sub メッセージを 1 つの推論リクエストとして送信しないようにします。代わりに、サブスクライバーは、推論サーバーの最適なバッチサイズ(vLLM の
max_num_seqs設定など)に合わせた 1 つのバッチ リクエストに複数のメッセージをバンドルする必要があります。このアプローチにより、アクセラレータが完全に飽和し、スループットが最大化されます。具体的には、サブスクライバーのmax_messagespull 設定をmax_num_seqsの倍数に構成して、すべてのモデルの順方向パスが完全に飽和するようにします。
サブスクライバーとサーバーを自動スケーリングする
効果的なバッチ推論では、サブスクライバー(CPU バウンド)を 推論サーバー(GPU または TPU バウンド)とは異なる方法でスケーリングする必要があります。
ワーク バックログに基づいてサブスクライバーをスケーリングする: Pub/Sub の
num_undelivered_messages指標に基づいて、サブスクライバー デプロイの HorizontalPodAutoscaler(HPA)を構成します。詳細については、指標に基づいて Pod の自動スケーリングを最適化するをご覧ください。次の式を使用して、使用するレプリカを計算します。\[ desiredReplicas = \frac{num\_undelivered\_messages}{target\_latency\_seconds \times throughput\_per\_replica} \]
インフラストラクチャの割り当てを尊重する: HPA の
maxReplicas設定を構成して、サブスクライバーの最大レプリカ数を明示的に上限設定します。推論サーバーの GPU または TPU の割り当てでサポートできる範囲を超えてサブスクライバーをスケーリングしないでください。サブスクライバーをオーバープロビジョニングすると、ボトルネックが推論サーバーに移行し、スループットを向上させることなくリソースの競合が増加します。エンジン指標に基づいて推論サーバーをスケーリングする: 推論エンジンによって直接エクスポートされた指標(CPU/メモリだけでなく)に基づいて推論サーバー デプロイをスケーリングします。たとえば、vLLM の
vllm:num_requests_waiting設定を使用します。これは、モデルサーバー レベルでの処理バックログを直接測定します。詳細については、 Pod を自動的にスケーリングするをご覧ください。
エラーとタイムアウトを処理する
エラーとタイムアウトを処理するには、次の操作を行います。
- 確認応答期限を事前に延長する: 処理中のメッセージの Pub/Sub 確認応答(ack)期限を事前に延長するようにサブスクライバーを構成して、再配信ループと重複処理を防ぎます。推論タスクはデフォルトのタイムアウト ウィンドウよりも時間がかかることが多いため、このアプローチが必要です。原則として、延長期間は最悪のケースのバッチ推論時間よりも長く設定します。
- デッドレター トピックを使用して障害を分離する: デッドレター トピックを有効にして、配信に繰り返し失敗した不正な形式のメッセージを自動的に分離します。このアプローチにより、「ポイズン ピル」メッセージがキューをブロックしてパイプライン全体を停止するのを防ぎます。
- バックオフ戦略を実装する: 推論サーバーが
429(リクエストが多すぎます)または503(サービスを利用できません)エラーを返した場合、サブスクライバーはこれらのエラーをキャッチし、サーバーが復旧するまで Pub/Sub からの消費を一時的に停止する指数バックオフ戦略を実装する必要があります。
大規模なバッチジョブをオーケストレートする
大規模なデータセットを処理する場合は、次のベスト プラクティスに従って、スループットを最大化し、費用対効果を高め、監査のための包括的なトレーサビリティを実装し、高度な割り当て管理とジョブの優先順位付けを適用します。
マルチノード分散推論に JobSet を使用する
複数の ノードが連携して動作する必要がある分散推論ワークロード(TPU Pod で実行される大規模なモデルやマルチノード GPU クラスタなど)をオーケストレートするには、Kubernetes JobSet リソースを使用することをおすすめします。標準の Kubernetes Job では、必要なすべての Pod が同時に起動することを保証できないため、分散ワークロードでデッドロックが発生する可能性があります。
JobSet は、Job のグループをユニットとして管理する Kubernetes ネイティブ API であり、バッチ推論に次のメリットがあります。
- ギャング スケジューリング: デッドロックを防ぐために、ワークロードを開始する前に、TPU スライスや GPU ノードなど、必要なすべてのリソースが使用可能であることを確認します。
- 排他的配置: 1 つの JobSet がネットワーク トポロジ(TPU スライスなど)に排他的にアクセスできるようにして、相互接続のパフォーマンスを最大化します。
- 障害復旧: ワーカーが失敗した場合、構成に応じて、特定のレプリケートされたジョブまたはセット全体を再起動できます。
データ シャーディングにインデックス付きジョブを使用する
JobSet を使用する場合は、ReplicatedJob 設定を使用するように completionMode:
Indexed を構成します。この設定により、JOB_COMPLETION_INDEX 環境変数が各 Pod に自動的に挿入されます。推論コードでは、このインデックスを使用して、処理するデータの固有のシャードを決定的に選択できます。
たとえば、100,000 個の画像を含む Cloud Storage バケットがあり、並列処理が 10 の JobSet をデプロイする場合、10 個の Pod はそれぞれ起動時にインデックス(0 ~ 9)を読み取ります。Pod 0 は画像 0 ~ 9,999 を処理し、Pod 1 は 10,000 ~ 19,999 を処理します。このアプローチにより、個別のタスクキュー サービスが不要になります。
サーバーの飽和にサイドカー パターンを使用する
アクセラレータの使用率を最大化するには、サイドカー パターンを使用して 2 つのコンテナで JobSet Pod を構成します。
- 推論サーバー: GPU または TPU の計算に完全に焦点を当てた最適化されたサーバー(vLLM など)。
- クライアント ドライバ: localhost のサーバーに大量のリクエストを非同期で送信するロジック コンテナ。
この分離により、GPU または TPU はネットワーク I/O またはデータの前処理を待機している間もビジー状態になり、アイドル状態になることはありません。このアプローチを使用しない場合、データを順番に読み込むモデルでは、アクセラレータが I/O オペレーションの完了を待機し、使用率が低下する可能性があります。たとえば、クライアント ドライバはデータの処理を待機するのではなく、データをプリフェッチして、推論サーバーに非同期リクエストを継続的に送信できます。これにより、アクセラレータのリクエスト キューが飽和状態に保たれます。
チェックリストの概要
| カテゴリ | 効果的な手法 |
|---|---|
| アーキテクチャ パターン | |
| 費用とスループット |
|
| メッセージングとスケーリング |
|
| オーケストレーション |
|