
במסמך הזה מוסברות שיטות מומלצות להרצת עומסי עבודה של הסקת מסקנות באצווה ב-Google Kubernetes Engine (GKE). הסקת מסקנות (inference) באצווה היא תהליך שבו משתמשים במודל של למידת מכונה כדי ליצור תחזיות לגבי מערכי נתונים גדולים, תוך מתן עדיפות לתפוקה גבוהה ולחיסכון בעלויות על פני תגובות מיידיות עם זמן אחזור נמוך.
במדריך הזה אנחנו מבחינים בין הסקת מסקנות באצווה לבין אצווה של בקשות (או אצווה דינמית) – טכניקה בצד השרת במנועים כמו vLLM או SGLang שמקבצת בקשות מקבילות בזמן אמת כדי לייעל את היעילות של המאיץ. אפשר להשתמש בבקשות אצווה כדי להסיק מסקנות לגבי עומסי עבודה של אצווה.
השיטות המומלצות במדריך הזה מתייחסות לשני סוגים נפוצים של דפוסי הסקה באצווה:
- הסקת מסקנות אסינכרונית: מעבדת נתונים במקטעים זמן קצר אחרי שהם נוצרים. בגישה הזו, זמן האחזור הוא בדרך כלל שניות עד דקות, כך שמתקבל איזון בין הצורך בנתונים עדכניים לבין היעילות של עיבוד כמה פריטים בו-זמנית. הסקת מסקנות אסינכרונית נקראת לפעמים הסקת מסקנות כמעט בזמן אמת.
- הסקת מסקנות באצווה: עיבוד של נפחים גדולים של נתונים שנצברו במרווחי זמן מתוזמנים (לדוגמה, מדי לילה או מדי שבוע). ההשהיה בדרך כלל נעה בין שעות לימים, כי העבודות האלה מתבצעות לרוב בשעות שבהן העומס נמוך כדי למקסם את זמינות המשאבים.
ההמלצות האלה הן שכבת אופטימיזציה מיוחדת שמבוססת על העקרונות שמתוארים בסקירה הכללית של השיטות המומלצות להסקת מסקנות ב-GKE. לפני שמבצעים אופטימיזציה לעומסי עבודה של אצווה, חשוב לוודא שפעלתם לפי השיטות המומלצות העיקריות לבחירת מודל, לכמת ולבחור מאיץ.
בחירת תבנית ארכיטקטונית לעיבוד של הסקת מסקנות באצווה
בחירת דפוס הארכיטקטורה הנכון היא ההחלטה החשובה ביותר כשפורסים עומסי עבודה של הסקת מסקנות באצווה, כי היא משפיעה על האיזון בין זמן האחזור, התפוקה והעלות. כדי לשמור על יעילות, חשוב לוודא שקצב העברת הנתונים של ההסקות גבוה מקצב האילתות הנכנסות בשעות השפל, כדי למנוע מצב שבו התורים יגדלו ללא הגבלה.
שימוש בהסקת מסקנות אסינכרונית לעבודה עם עומס משתנה
הסקת מסקנות אסינכרונית מתאימה לתרחישי שימוש שבהם נדרשים עדכונים תכופים ומצטברים, כמו:
- עדכון פרופילי ההמלצות למשתמשים כל כמה דקות על סמך אינטראקציות מהזמן האחרון.
- עיבוד של אזכורים ברשתות החברתיות במרווחי זמן של דקה אחת לצורך מעקב בזמן אמת.
- זיהוי אותות שמשפיעים על השוק ממקורות של נתונים פיננסיים בתדירות גבוהה.
- ביצוע ניתוח סנטימנט על משוב מלקוחות או על פידים של חדשות.
בוחרים בתבנית הזו אם עומס העבודה יכול לסבול השהיה של כמה שניות עד כמה דקות.
כשמטמיעים הסקה אסינכרונית, חשוב להביא בחשבון את המאפיינים הבאים:
- זמן אחזור: אפשר לצפות לזמן עד לטוקן הראשון שנע בין עשרות שניות לדקות.
- מקורות נתונים: בדרך כלל מעבדים מערכי נתונים בגודל של מגה-בייט עד גיגה-בייט, כמו הודעות מ-Pub/Sub או קבצים מ-Cloud Storage שנצברו בחלון זמן קצר.
- דפוס שימוש ב-Compute: התשתית שלכם צריכה לתמוך בשירות רציף שמטפל בפרצי עבודה תכופים.
- אופטימיזציה של העלויות: התבנית הזו מציעה איזון בין הסקה בזמן אמת עם חביון נמוך לבין עיבוד אצווה עם תפוקה גבוהה.
שימוש בהסקת מסקנות באצווה לקבוצות נתונים גדולות
הסקת מסקנות באצווה מתאימה במיוחד למשימות אפיזודיות בקנה מידה גדול, שיכולות לסבול עיכובים של שעות או ימים, כמו המשימות הבאות:
- יצירת דוחות יומיים של הערכת סיכונים על סמך עסקאות פיננסיות מהיום הקודם.
- יצירת הטמעות של מוצרים בקטלוג שלם כדי להפעיל מערכות חיפוש והמלצות בהמשך.
- תיוג של מערכי נתונים גדולים של תמונות לצורך אימון מודלים או סיווג לארכיון.
מומלץ לבחור בדפוס הזה אם מעבדים נפחים גדולים של נתונים ויכולים להסתדר עם השהיות של כמה שעות עד כמה ימים.
כשמטמיעים הסקה באצווה, חשוב להתייחס למאפיינים הבאים:
- זמן אחזור: זמן האחזור של התחלת עומס עבודה נע בדרך כלל בין דקות לימים, כי לעיתים קרובות העבודות מתוזמנות לשעות שבהן העומס נמוך.
- מקורות נתונים: אתם מעבדים מערכי נתונים גדולים מגיגה-בייט ועד פטה-בייט, שבדרך כלל מאוחסנים ב-Cloud Storage או בטבלאות BigQuery.
- דפוס שימוש במחשוב: אתם משתמשים במשימות אפיזודיות ואינטנסיביות שמתחילות, מעבדות את הנתונים ואז מסתיימות.
- אופטימיזציה של עלויות: אפשר לבצע אופטימיזציה של הדפוס הזה באמצעות מודל של תשלום לפי שימוש. מכיוון שלמשימות באצווה יש חלונות סיום גמישים, מומלץ להשתמש במכונות וירטואליות זמניות כדי להוזיל את העלויות.
אופטימיזציה של התפוקה והיעילות מבחינת עלות
עומסי עבודה של הסקת מסקנות באצווה מתאימים במיוחד לתשתית שמאפשרת חיסכון בעלויות, ועשויה לכלול הפרעות.
שימוש במכונות וירטואליות מסוג Spot כדי לצמצם את עלויות החישוב
כדאי להשתמש בהנחות של מכונות Spot VM למשימות באצווה. מכיוון שעומסי עבודה של הסקת מסקנות באצווה בדרך כלל סובלים השהיה והפרעות, הם מועמדים טובים לשימוש בקיבולת Spot במחיר מוזל.
חשוב לוודא שקוד ההסקה באצווה מטמיע שמירת נקודות ביקורת כדי לטפל באירועי קדימות פוטנציאליים. אם VM במודל Spot נדחית, אפשר ליצור צומת חדש ולהמשיך את עומס העבודה מהאצווה האחרונה שעברה עיבוד, במקום להתחיל מחדש.
שיפור גודל האצווה של עומס העבודה וגודל האצווה של הבקשה
כדי להימנע ממצב של תחרות על משאבים ופסק זמן של עבודות, חשוב לוודא שמספר הפריטים שנשלחים למנוע (קבוצת עומס עבודה) גדול לפחות כמו מספר הבקשות המקבילות שהשרת יכול לעבד (קבוצת בקשות), כדי למנוע שימוש חלקי במאיצים.
שינוי גודל האצווה של עומס העבודה
גודל אצווה של עומס עבודה הוא המספר הכולל של פריטים שנשלחים למנוע ההסקה ביחידת עבודה אחת. כדי להגדיר את זה, צריך להשתמש בלוגיקה של שליחת הנתונים ללקוח או בהגדרות של Kubernetes Job, על ידי חלוקת הנתונים או קיבוץ של כמה פריטים לבקשה אחת.
כדי לקבוע את גודל אצווה האופטימלי של עומס העבודה, משתמשים בגבולות הבאים:
- חישוב גודל האצווה המינימלי: מוודאים שגודל האצווה של עומס העבודה גדול לפחות כמו גודל האצווה של הבקשה. לדוגמה, שליחת פריט אחד לשרת שיכול לעבד 256 פריטים בו-זמנית תגרום לניצול חלקי בלבד של השרת. כדי לגלות מה הגודל המינימלי, בודקים את ההגדרה של שרת ההסקה, כמו הארגומנט
max_num_seqsב-vLLM. אתם יכולים להגדיר את הלוגיקה של הלקוח כך שתקבץ כמה פריטים לבקשה אחת, או לפצל את הנתונים כך שכל משימה תקבל כמות מינימלית של נתונים שעומדת בדרישות של גודל אצווה הבקשות או עולה עליהן. - חישוב הגודל המקסימלי של אצווה: מוודאים שגודל האצווה של עומס העבודה מאפשר ל-Pod לסיים לפני שמגיעים לזמן הקצוב לתפוגה
activeDeadlineSecondsשמוגדר בKubernetes Job. כדאי להעריך את הזמן שנדרש לעיבוד של קבוצת בקשות אחת ולהגדיר את גודל עומס העבודה כך שה-Pod יסיים את העיבוד הרבה לפני המועד האחרון. לדוגמה, אםactiveDeadlineSecondsהוא 3,600 שניות, והתקורה של האתחול היא 600 שניות, צריך לוודא שזמן הביצוע המקסימלי מאפשר ל-Pod להסתיים תוך פחות מ-3,000 שניות.
אם גודל האצווה של עומס העבודה קטן מדי, המשימה תבזבז זמן על תקורה של הפעלת ה-Pod (הורדת משקלים, הקצאת משאבים, הפעלת המאיץ). אם גודל האצווה גדול מדי, קיים סיכון שהמשימה תופסק על ידי GKE בגלל פסק הזמן של activeDeadlineSeconds, מה שיגרום לכך שהמשימה תיכשל וההתקדמות שלה תאבד.
שינוי גודל האצווה של הבקשה
גודל אצווה הבקשות הוא מספר הבקשות בו-זמנית ששרת ההסקה מעבד במקביל במאיץ. כדי לבצע אופטימיזציה של הפרמטר הזה, צריך לשנות את ההגדרות של דגלים ספציפיים לשרת בהגדרות של שרת ההסקה (לדוגמה, הדגל --max-num-seqs ב-vLLM).
המטרה היא למקסם את השימוש ב-GPU בלי להפעיל שגיאות של חוסר זיכרון (OOM). אם גודל אצווה של הבקשות לא מכויל, המערכת תנצל פחות את המאיץ או תגרום לקריסת שרת המודל. ב-vLLM, אפשר להשתמש בכלים כמו סקריפט auto_tune של vLLM כדי למצוא את הערכים הכי טובים להגדרות max_num_seqs ו-max_num_batched_tokens עבור החומרה הספציפית שלכם. מידע נוסף זמין במאמר אופטימיזציה של ההגדרה של שרת ההסקה במדריך 'סקירה כללית של שיטות מומלצות להסקה ב-GKE'.
הטמעה של רכיבים אסינכרוניים להסקת מסקנות אסינכרונית
לצורך הסקת מסקנות אסינכרונית, מומלץ להשתמש במאגרי הודעות כדי להפריד בין שכבת ההטמעה לבין שכבת הסקת המסקנות.
בתרשים הארכיטקטורה הבא מוצגת דוגמה לפלטפורמה של הסקת מסקנות אסינכרונית. הארכיטקטורה הזו מגנה על שרתי ההסקה מפני עליות חדות בתנועת הנתונים, מנהלת את עומסי העבודה ומבטיחה ניצול גבוה של המאיצים.
בתרשים מוצג התהליך מ-Pub/Sub למנויים, לשער הסקה ולשרת הסקה, כשהתוצאות נשמרות ב-AlloyDB והודעות שנכשלו נשלחות לנושא של הודעות שלא ניתן למסור.
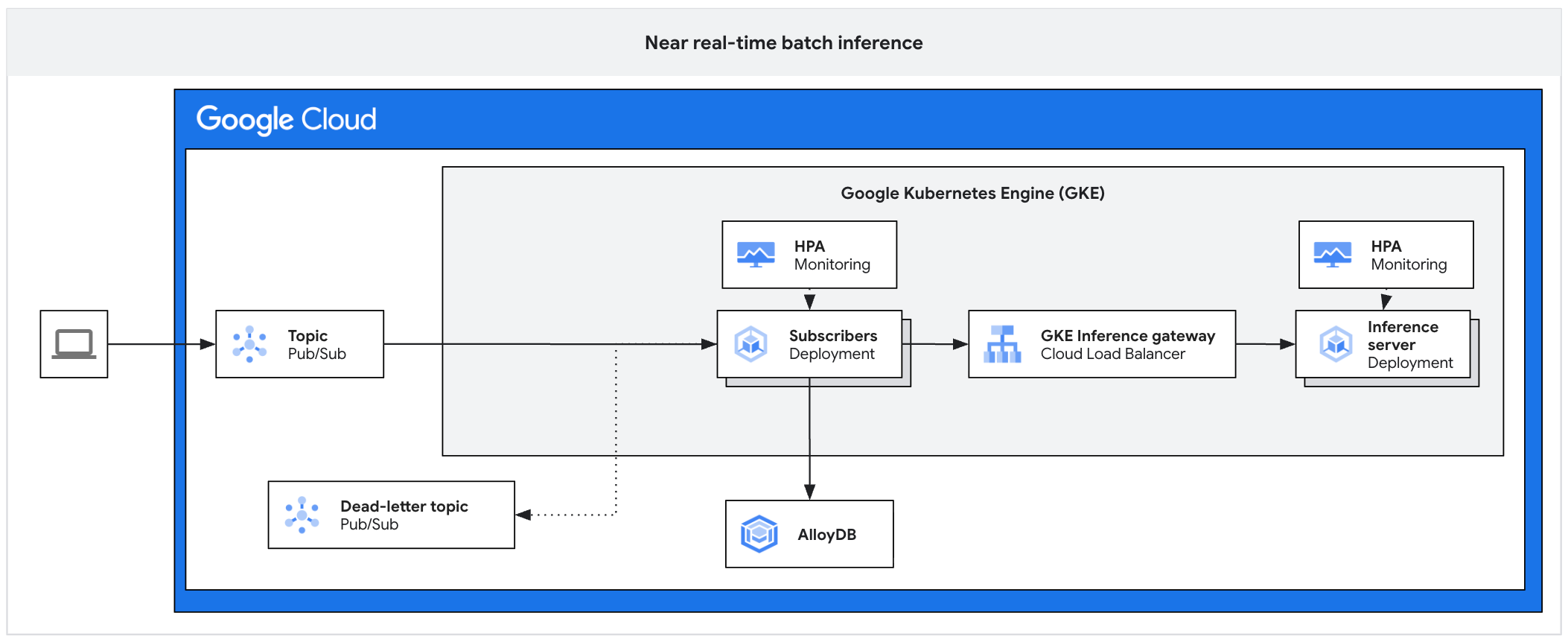
הארכיטקטורה מורכבת מהרכיבים הבאים:
- נושא Pub/Sub: משמש כמאגר זמני קבוע להודעות נכנסות מלקוחות, עם תקופת שמירה של 7 עד 31 ימים.
- רכיב Subscriber: רכיב שקורא חבילות של הודעות, שולח בקשות לשרת ההסקה ומאשר את העיבוד.
- Subscriber HPA: משנה את גודל הפריסה של ה-Subscriber בהתאם למדד
num_undelivered_messages(מספר ההודעות שלא אושרו). - אחסון: כדי לשמור את תוצאות ההסקה, צריך להשתמש במסד נתונים (כמו AlloyDB) או באחסון אובייקטים (כמו Cloud Storage) .
- Inference Gateway: חושף את עומסי העבודה של ההסקות למנוי.
- שרת הסקה: מעבד את בקשות ההסקה באצווה (לדוגמה, vLLM).
- Server HPA: שינוי קנה המידה של מנוע ההסקה על סמך מדדים ספציפיים למנוע כמו
vllm:num_requests_waiting. - נושא להודעות ללא מוצא: כולל הודעות שלא ניתן לעבד אחרי מספר מסוים של ניסיונות חוזרים עם השהיה מעריכית לפני ניסיון חוזר (exponential backoff).
מידע נוסף זמין ביישום לדוגמה ב-GitHub.
אגירת בקשות וצירוף שלהן
כדי לנהל את זרימת הבקשות:
- שימוש ב-Pub/Sub כמאגר זמני עמיד: הטמעת Pub/Sub לאחסון עמיד של בקשות הסקה. ההגדרה הזו פועלת כמאגר FIFO שמכיל בקשות עד שלצרכן יש קיבולת לעבד אותן, וכך מונעת עומס יתר על השרת בזמן תנועה גבוהה.
- שימוש במנויי משיכה עם בקרה על זרימת נתונים בצד הלקוח: הגדרת מודל מנוי משיכה. כך אפליקציית המנויים יכולה לבקש הודעות באופן מפורש רק כשיש לה יכולת לעבד אותן, ואתם מקבלים שליטה מלאה על קצב הצריכה.
- צריך לצבור הודעות כדי למלא את גודל האצווה של השרת: לא מומלץ לשלוח הודעת Pub/Sub אחת כבקשת הסקה אחת. במקום זאת, המנוי צריך לאגד כמה הודעות לבקשת Batch אחת שתואמת לגודל אצווה האופטימלי של שרת ההסקה (לדוגמה, התאמה להגדרות
max_num_seqsב-vLLM). הגישה הזו עוזרת לוודא שההאצות מגיעות לרוויה מלאה וממקסמת את קצב העברת הנתונים. במיוחד, צריך להגדיר אתmax_messagesהגדרת השליפה של המנוי למספר שהוא כפולה שלmax_num_seqsכדי להבטיח שכל העברה קדימה של המודל תהיה רוויה לחלוטין.
הגדלה אוטומטית של מספר המנויים והשרתים
כדי להסיק מסקנות יעילות על קבוצות של נתונים, צריך לשנות את קנה המידה של המשתמשים הרשומים (מוגבלים על ידי CPU) באופן שונה משינוי קנה המידה של שרתי ההסקה (מוגבלים על ידי GPU או TPU).
התאמת מספר המנויים בהתאם לעומס העבודה: הגדרת HorizontalPodAutoscaler (HPA) לפריסת המנויים על סמך מדד
num_undelivered_messagesמ-Pub/Sub. מידע נוסף זמין במאמר בנושא אופטימיזציה של שינוי גודל אוטומטי של Pod על סמך מדדים. כדי לחשב את מספר הרפליקות שרוצים להשתמש בהן, משתמשים במשוואה הבאה:\[ desiredReplicas = \frac{num\_undelivered\_messages}{target\_latency\_seconds \times throughput\_per\_replica} \]
הקפדה על מכסות התשתית: הגבלת מספר העותקים המקסימלי של המנויים על ידי הגדרת הערך
maxReplicasב-HPA. אל תגדילו את מספר המנויים מעבר למכסת ה-GPU או ה-TPU של שרתי ההסקה. הקצאת יתר של מינויים תגרום לצוואר הבקבוק לעבור לשרת ההסקה, ותגדיל את התחרות על המשאבים בלי להגדיל את קצב העברת הנתונים.התאמת גודל השרתים של ההסקה על סמך מדדי המנוע: התאמת גודל הפריסה של שרת ההסקה על סמך מדדים שמיוצאים ישירות על ידי מנוע ההסקה (ולא רק על סמך CPU/זיכרון). לדוגמה, אפשר להשתמש בהגדרה של vLLM, שמודדת ישירות את הפיגור בעיבוד ברמת שרת המודל.
vllm:num_requests_waitingמידע נוסף מופיע במאמר בנושא שינוי אוטומטי של גודל ה-Pods.
טיפול בשגיאות ובזמני קצובים לתפוגה
כדי לטפל בשגיאות ובפסק זמן, מבצעים את הפעולות הבאות:
- הארכת המועדים האחרונים לאישור באופן יזום: הגדרת המנוי להארכת המועד האחרון לאישור (ack) של Pub/Sub באופן יזום עבור הודעות שעוברות עיבוד, כדי למנוע לולאות של מסירה חוזרת ועיבוד כפול. הגישה הזו נדרשת כי משימות הסקה לרוב נמשכות יותר מהחלונות של פסק הזמן שמוגדר כברירת מחדל. ככלל, כדאי להגדיר את תקופת ההארכה כך שתהיה ארוכה יותר מזמן ההסקה של אצווה במקרה הגרוע ביותר.
- בידוד כשלים באמצעות נושא להודעות ללא מוצא: הפעלה של נושא להודעות ללא מוצא מאפשרת לבודד באופן אוטומטי הודעות פגומות שלא נמסרו שוב ושוב. הגישה הזו מונעת מהודעות מסוג "כדור רעל" לחסום את התור ולהפסיק את כל הצינור.
- הטמעת אסטרטגיות השהיה לפני ניסיון חוזר: אם שרת ההסקה מחזיר שגיאות
429(Too Many Requests) או503(Service Unavailable), המנוי צריך לזהות את השגיאות האלה ולהטמיע אסטרטגיית השהיה מעריכית לפני ניסיון חוזר. במסגרת האסטרטגיה הזו, צריכת הנתונים מ-Pub/Sub מושהית באופן זמני עד שהשרת חוזר לפעולה.
תזמור משימות באצווה בקנה מידה גדול
כדי למקסם את קצב העברת הנתונים, להבטיח יעילות מבחינת עלויות, ליישם מעקב מקיף לצורך ביקורת, וליישם ניהול מתקדם של מכסות ותעדוף משימות כשמעבדים מערכי נתונים גדולים, מומלץ לפעול לפי השיטות המומלצות הבאות.
שימוש ב-JobSet להסקת מסקנות מבוזרת בכמה צמתים
מומלץ להשתמש במשאב JobSet של Kubernetes כדי לתזמן עומסי עבודה של הסקת מסקנות מבוזרת שדורשים שיתוף פעולה בין כמה צמתים, כמו מודלים גדולים שפועלים ב-TPU Pods או באשכולות GPU מרובי-צמתים. ב-Kubernetes Jobs רגילים אי אפשר להבטיח שכל ה-Pods הנדרשים יתחילו לפעול בו-זמנית, מה שעלול להוביל לקיפאון בעומסי עבודה מבוזרים.
JobSet הוא API מקורי של Kubernetes שמנהל קבוצות של משימות כיחידה אחת, ומספק את היתרונות הבאים להסקת מסקנות באצווה:
- תזמון קבוצתי: עוזר לוודא שכל המשאבים הנדרשים, כמו חלקי TPU או צמתי GPU, זמינים לפני הפעלת עומס העבודה כדי למנוע מצבים של חסימה הדדית.
- מיקום בלעדי: עוזר להבטיח של-JobSet יחיד תהיה גישה בלעדית לטופולוגיית הרשת (לדוגמה, חלוקת TPU) כדי למקסם את ביצועי הקישוריות.
- שחזור לאחר כשל: מאפשר להפעיל מחדש משימות משוכפלות ספציפיות או את כל המערך אם יש כשל בעובד, בהתאם להגדרה.
שימוש במשימות עם אינדקס לצורך חלוקת נתונים
כשמשתמשים ב-JobSet, צריך להגדיר את ReplicatedJob לשימוש בהגדרה completionMode:
Indexed. ההגדרה הזו מחדירה באופן אוטומטי משתנה סביבה JOB_COMPLETION_INDEX לכל Pod. קוד ההסקה יכול להשתמש באינדקס הזה כדי לבחור באופן דטרמיניסטי נתח נתונים ייחודי לעיבוד.
לדוגמה, אם יש לכם קטגוריה של Cloud Storage עם 100,000 תמונות ואתם פורסים JobSet עם מקביליות של 10, כל אחד מ-10 ה-Pods קורא את האינדקס שלו (0-9) בהפעלה. לאחר מכן, Pod 0 יכול לחשב שהוא צריך לעבד את התמונות 0 עד 9,999, בעוד ש-Pod 1 מעבד את התמונות 10,000 עד 19,999. הגישה הזו מצמצמת את הצורך בשירות נפרד של תור משימות.
שימוש בתבנית sidecar לשיפור הביצועים של השרת
כדי למקסם את השימוש במאיץ, צריך להגדיר את ה-Pods של JobSet עם שני קונטיינרים באמצעות תבנית sidecar:
- שרת הסקה: שרת שעבר אופטימיזציה (כמו vLLM) שמתמקד כולו בחישובים של GPU או TPU.
- מנהל התקן של הלקוח: מאגר לוגיקה ששולח באופן אסינכרוני נפח גבוה של בקשות לשרת במארח המקומי.
ההפרדה הזו עוזרת לוודא שה-GPU או ה-TPU עסוקים כל הזמן ולא נמצאים במצב המתנה בזמן שמתבצעות פעולות קלט/פלט ברשת או עיבוד מקדים של נתונים. בלי הגישה הזו, מודלים שמעמיסים נתונים באופן עוקב עלולים לגרום להמתנה של המאיץ להשלמת פעולות קלט/פלט, וכתוצאה מכך לניצול חלקי של המשאבים. לדוגמה, במקום לחכות לעיבוד הנתונים, מנהל ההתקן של הלקוח יכול לבצע אחזור מראש של נתונים ולשלוח באופן רציף בקשות אסינכרוניות לשרת ההסקה, וכך לוודא שתור הבקשות של המאיץ יישאר מלא.
סיכום רשימת המשימות
| קטגוריה | שיטה מומלצת |
|---|---|
| דפוסי ארכיטקטורה |
|
| עלות וקצב העברת נתונים |
|
| העברת הודעות והתאמה לעומס |
|
| Orchestration |
|