
En este documento, se proporcionan prácticas recomendadas para ejecutar cargas de trabajo de inferencia por lotes en Google Kubernetes Engine (GKE). La inferencia por lotes es el proceso de usar un modelo de aprendizaje automático para generar predicciones en grandes conjuntos de datos, lo que prioriza la alta capacidad de procesamiento y la eficiencia en el costo por sobre las respuestas inmediatas de baja latencia.
En esta guía, se distingue la inferencia por lotes del procesamiento por lotes de solicitudes (o procesamiento por lotes dinámico), una técnica del servidor en motores como vLLM o SGLang que agrupa solicitudes simultáneas en tiempo real para optimizar la eficiencia del acelerador. Puedes aplicar el procesamiento por lotes de solicitudes a las cargas de trabajo de inferencia por lotes.
Las prácticas recomendadas de esta guía abarcan dos tipos comunes de patrones de inferencia por lotes:
- Inferencia asíncrona: Procesa los datos en fragmentos poco después de que se generan. Con una latencia típica de segundos a minutos, este enfoque equilibra la necesidad de datos actualizados con la eficiencia del procesamiento de varios elementos de forma simultánea. A veces, la inferencia asíncrona se denomina inferencia casi en tiempo real.
- Inferencia por lotes: Procesa grandes volúmenes de datos acumulados en intervalos programados (por ejemplo, todas las noches o todas las semanas). Por lo general, la latencia varía de horas a días, ya que estos trabajos suelen programarse durante las horas de menor actividad para maximizar la disponibilidad de recursos.
Estas recomendaciones son una capa especializada de optimización creada sobre los fundamentos que se describen en la Descripción general de las prácticas recomendadas de inferencia en GKE. Antes de optimizar las cargas de trabajo por lotes, asegúrate de haber seguido las principales prácticas recomendadas para la selección de modelos, la cuantificación y la elección de aceleradores.
Elige un patrón arquitectónico para el procesamiento de la inferencia por lotes
Seleccionar el patrón de arquitectura correcto es la decisión más importante para implementar tus cargas de trabajo de inferencia por lotes, ya que afecta las compensaciones entre la latencia, el procesamiento y el costo. Para mantener la eficiencia, asegúrate de que la capacidad de procesamiento de inferencia supere la tasa de consultas entrantes durante las horas no pico para evitar que las colas crezcan de forma indefinida.
Usa la inferencia asíncrona para el trabajo con picos
La inferencia asíncrona funciona bien para los casos de uso que requieren actualizaciones incrementales frecuentes, como los siguientes:
- Actualizar los perfiles de recomendación de los usuarios cada pocos minutos en función de las interacciones recientes
- Procesamiento de menciones en redes sociales en intervalos de un minuto para la supervisión en tiempo real
- Detectar señales que mueven el mercado a partir de flujos de datos financieros de alta frecuencia
- Realizar análisis de sentimiento sobre los comentarios de los clientes o los feeds de noticias entrantes.
Elige este patrón si tu carga de trabajo puede tolerar una latencia que varía de varios segundos a unos minutos.
Cuando implementes la inferencia asíncrona, ten en cuenta las siguientes características:
- Latencia: Puedes esperar un tiempo hasta el primer token que oscile entre decenas de segundos y minutos.
- Fuentes de datos: Por lo general, procesas conjuntos de datos que varían de megabytes a gigabytes, como mensajes de Pub/Sub o archivos de Cloud Storage acumulados durante un período corto.
- Patrón de procesamiento: Tu infraestructura debe admitir un servicio continuo que controle ráfagas frecuentes de trabajo.
- Optimización de costos: Este patrón ofrece un equilibrio entre la inferencia en tiempo real de baja latencia y el procesamiento por lotes de alta capacidad de procesamiento.
Usa la inferencia por lotes para conjuntos de datos masivos
La inferencia por lotes es ideal para trabajos episódicos a gran escala que pueden tolerar demoras de horas o días, como los siguientes:
- Generar informes de evaluación de riesgos nocturnos basados en las transacciones financieras del día anterior
- Crear incorporaciones de productos para un catálogo completo que impulse los sistemas de recomendación y búsqueda posteriores.
- Etiquetar grandes conjuntos de datos de imágenes para el entrenamiento de modelos o la categorización de archivos
Elige este patrón si procesas grandes volúmenes de datos y puedes tolerar latencias que van desde horas hasta varios días.
Cuando implementes la inferencia por lotes, ten en cuenta las siguientes características:
- Latencia: La latencia de inicio de la carga de trabajo suele variar de minutos a días, ya que los trabajos a menudo se programan durante las horas no pico.
- Fuentes de datos: Procesas grandes conjuntos de datos, desde gigabytes hasta petabytes, que suelen almacenarse en tablas de Cloud Storage o BigQuery.
- Patrón de procesamiento: Usas trabajos episódicos y repentinos que se inicializan, procesan los datos y, luego, finalizan.
- Optimización de costos: Este patrón se puede optimizar en gran medida con un modelo de pago por uso. Debido a que los trabajos por lotes tienen ventanas de finalización flexibles, te recomendamos que uses VMs Spot para reducir los costos.
Optimiza la capacidad de procesamiento y la rentabilidad
Las cargas de trabajo de inferencia por lotes son ideales para la infraestructura que ahorra costos y que puede implicar interrupciones.
Usa VMs Spot para reducir los costos de procesamiento
Usa los descuentos de las VMs Spot para los trabajos por lotes. Debido a que las cargas de trabajo de inferencia por lotes suelen tolerar la latencia y las interrupciones, son buenas candidatas para los precios reducidos de la capacidad de Spot.
Asegúrate de que tu código de inferencia por lotes implemente el checkpointing para controlar posibles eventos de interrupción. Si se interrumpe una VM Spot, puedes crear un nodo nuevo y reanudar tu carga de trabajo desde el último lote procesado en lugar de reiniciar desde cero.
Ajusta el tamaño del lote de la carga de trabajo y el tamaño del lote de la solicitud
Para evitar la contención de recursos y los tiempos de espera del trabajo, asegúrate de que la cantidad de elementos enviados a tu motor (lote de carga de trabajo) sea al menos tan grande como las solicitudes simultáneas que el servidor puede procesar (lote de solicitudes) para evitar la subutilización de los aceleradores.
Ajusta el tamaño del lote de tu carga de trabajo
El tamaño del lote de carga de trabajo es la cantidad total de elementos que se envían a tu motor de inferencia en una sola unidad de trabajo. Puedes configurar esto en la lógica de envío del cliente o en la configuración del trabajo de Kubernetes fragmentando tus datos o agrupando varios elementos en una sola solicitud.
Para determinar el tamaño óptimo del lote de la carga de trabajo, usa los siguientes límites:
- Calcula el tamaño mínimo del lote: Asegúrate de que el tamaño del lote de tu carga de trabajo sea al menos tan grande como el tamaño del lote de tu solicitud. Por ejemplo, enviar un elemento a un servidor que puede procesar 256 elementos de forma simultánea genera una subutilización significativa. Para encontrar tu tamaño mínimo, consulta la configuración del servidor de inferencia, como el argumento
max_num_seqsen vLLM. Puedes configurar la lógica del cliente para agrupar varios elementos en una sola solicitud o puedes fragmentar tus datos de modo que cada trabajo reciba una cantidad mínima de datos que cumpla o supere el tamaño del lote de solicitudes. - Calcula el tamaño máximo del lote: Asegúrate de que el tamaño del lote de tu carga de trabajo permita que el Pod finalice antes de que se agote el tiempo de espera de
activeDeadlineSecondsdefinido en tu trabajo de Kubernetes. Estima el tiempo necesario para procesar un lote de solicitudes y establece el tamaño de la carga de trabajo de modo que el Pod se complete mucho antes de la fecha límite. Por ejemplo, si tuactiveDeadlineSecondses de 3,600 segundos y tu sobrecarga de inicio es de 600 segundos, asegúrate de que el tiempo de ejecución máximo permita que el Pod finalice en menos de 3,000 segundos.
Si el tamaño del lote de tu carga de trabajo es demasiado pequeño, tu trabajo perderá tiempo en la sobrecarga de inicio del Pod (descarga de pesos, aprovisionamiento, inicialización del acelerador); si es demasiado grande, corres el riesgo de que GKE finalice el trabajo debido al tiempo de espera de activeDeadlineSeconds, lo que provocará que el trabajo falle y pierda su progreso.
Ajusta el tamaño del lote de solicitudes
El tamaño del lote de solicitudes es la cantidad de solicitudes simultáneas que el servidor de inferencia procesa de forma simultánea en el acelerador. Puedes optimizar este parámetro ajustando las marcas específicas del servidor en la configuración del servidor de inferencia (por ejemplo, la marca --max-num-seqs para vLLM).
Tu objetivo es maximizar el uso de la GPU sin activar errores de memoria insuficiente (OOM). Si el tamaño del lote de solicitudes no está calibrado, tu sistema subutilizará el acelerador o fallará el servidor del modelo. En el caso de vLLM, puedes usar herramientas como el script auto_tune de vLLM para encontrar los mejores valores para la configuración de max_num_seqs y max_num_batched_tokens para tu hardware específico. Para obtener más información, consulta Optimiza la configuración de tu servidor de inferencia en la guía Descripción general de las prácticas recomendadas de inferencia en GKE.
Implementa componentes asíncronos para la inferencia asíncrona
Para la inferencia asíncrona, te recomendamos que uses búferes de mensajería para desacoplar tu capa de transferencia de tu capa de inferencia.
En el siguiente diagrama de arquitectura, se ilustra un ejemplo de una plataforma de inferencia asíncrona. Esta arquitectura protege los servidores de inferencia de los picos de tráfico, administra los registros de trabajo pendientes y garantiza un alto uso del acelerador.
En el diagrama, se muestra el flujo desde Pub/Sub hacia los suscriptores, una puerta de enlace de inferencia y un servidor de inferencia, con los resultados persistidos en AlloyDB y los mensajes fallidos enviados a un tema de mensajes no entregados.
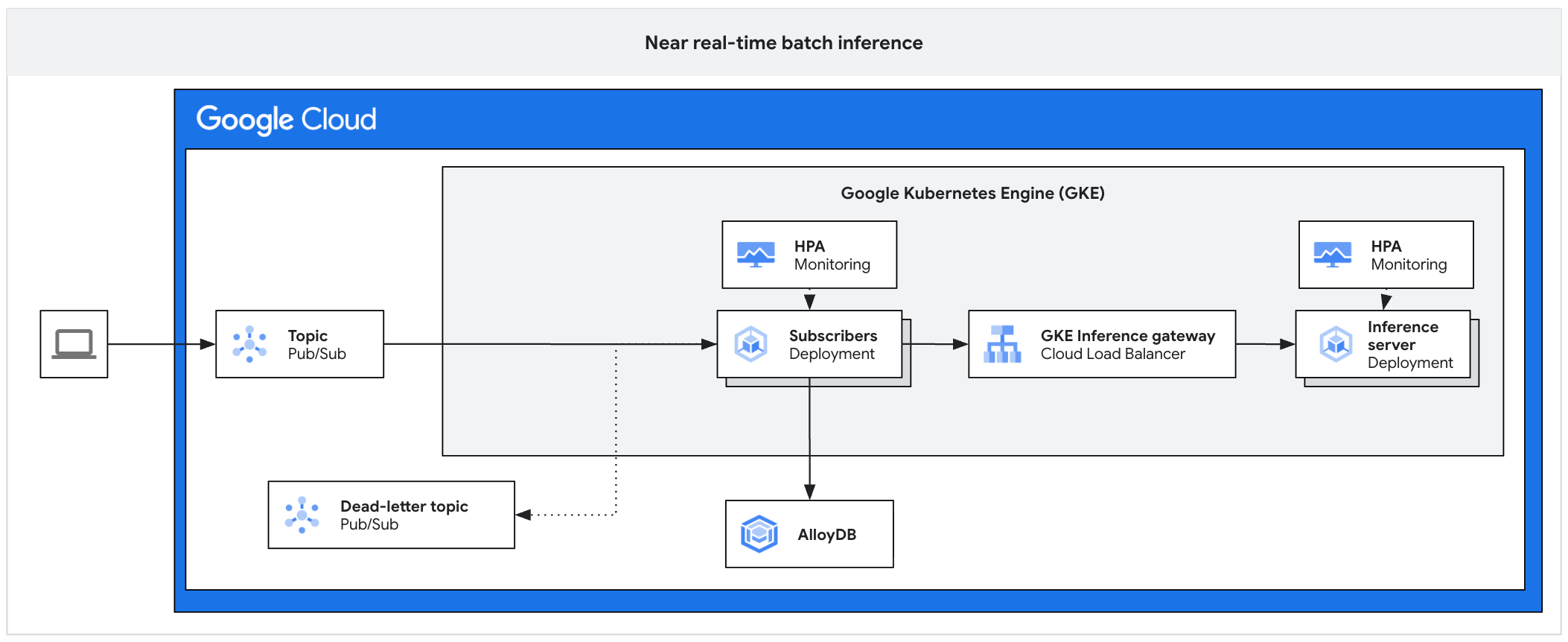
La arquitectura consta de los siguientes componentes:
- El tema de Pub/Sub actúa como un búfer persistente para los mensajes entrantes del cliente, con un período de retención de 7 a 31 días.
- Suscriptor: Es un componente que lee lotes de mensajes, envía solicitudes al servidor de inferencia y confirma el procesamiento.
- HPA del suscriptor: Escala la implementación del suscriptor en función de la métrica
num_undelivered_messages(la cantidad de mensajes no confirmados). - Almacenamiento: Persiste los resultados de la inferencia con una base de datos (como AlloyDB) o un almacenamiento de objetos (como Cloud Storage) .
- Puerta de enlace de inferencia: Expone las cargas de trabajo de inferencia al suscriptor.
- Servidor de inferencia: Procesa las solicitudes de inferencia por lotes (por ejemplo, vLLM).
- HPA del servidor: Ajusta el motor de inferencia según métricas específicas del motor, como
vllm:num_requests_waiting. - Tema de mensajes no entregados: Captura los mensajes que no se procesan después de una cantidad establecida de reintentos de retirada exponencial.
Para obtener más información, consulta la implementación de referencia en GitHub.
Almacena en búfer y agrega solicitudes
Para administrar el flujo de solicitudes, haz lo siguiente:
- Usa Pub/Sub como un búfer duradero: Implementa Pub/Sub para almacenar solicitudes de inferencia de forma duradera. Esta configuración actúa como un búfer FIFO que contiene solicitudes hasta que un consumidor tiene la capacidad de procesarlas, lo que evita la sobrecarga del servidor durante el tráfico repentino.
- Usa suscripciones de extracción con control de flujo del cliente: Configura un modelo de suscripción de extracción. Esto permite que tu aplicación de suscriptor solicite mensajes de forma explícita solo cuando tenga la capacidad de procesarlos, lo que te otorga un control total sobre la tasa de consumo.
- Agrega mensajes para completar el tamaño del lote del servidor: Evita enviar un mensaje de Pub/Sub como una solicitud de inferencia. En cambio, el suscriptor debe agrupar varios mensajes en una sola solicitud por lotes que se alinee con el tamaño de lote óptimo de tu servidor de inferencia (por ejemplo, que coincida con la configuración de
max_num_seqsen vLLM). Este enfoque ayuda a garantizar que los aceleradores estén completamente saturados y maximiza la capacidad de procesamiento. Específicamente, configura el parámetro de extracciónmax_messagesde tu suscriptor en un múltiplo demax_num_seqspara garantizar que cada pase hacia adelante del modelo esté completamente saturado.
Ajusta automáticamente la escala de los suscriptores y los servidores
La inferencia por lotes eficaz requiere escalar los suscriptores (vinculados a la CPU) de manera diferente a los servidores de inferencia (vinculados a la GPU o la TPU).
Escala los suscriptores según el backlog de trabajo: Configura el HorizontalPodAutoscaler (HPA) para la implementación de tu suscriptor según la métrica
num_undelivered_messagesde Pub/Sub. Para obtener más información, consulta Optimiza el ajuste de escala automático de Pods en función de las métricas. Calcula las réplicas que deseas usar con la siguiente ecuación:\[ desiredReplicas = \frac{num\_undelivered\_messages}{target\_latency\_seconds \times throughput\_per\_replica} \]
Respeta las cuotas de infraestructura: Limita de forma explícita las réplicas máximas de tus suscriptores configurando el parámetro
maxReplicasen tu HPA. No aumentes la cantidad de suscriptores más allá de lo que puede admitir la cuota de GPU o TPU de tus servidores de inferencia. El aprovisionamiento excesivo de suscriptores trasladará el cuello de botella al servidor de inferencia, lo que aumentará la contención de recursos sin aumentar el rendimiento.Escala los servidores de inferencia según las métricas del motor: Escala la implementación de tu servidor de inferencia según las métricas que exporta directamente el motor de inferencia (no solo a través de la CPU o la memoria). Por ejemplo, usa el parámetro de configuración
vllm:num_requests_waitingpara vLLM, que mide directamente el trabajo pendiente de procesamiento a nivel del servidor del modelo. Para obtener más información, consulta Cómo ajustar automáticamente la escala de tus Pods.
Cómo controlar errores y tiempos de espera
Para controlar los errores y los tiempos de espera, haz lo siguiente:
- Extiende de forma proactiva los plazos de confirmación: Configura tu suscriptor para que extienda de forma proactiva el plazo de confirmación (ack) de Pub/Sub para los mensajes que se están procesando y, así, evitar bucles de reenvío y procesamiento duplicado. Este enfoque es necesario porque las tareas de inferencia suelen tardar más que los períodos de tiempo de espera predeterminados. Como regla general, establece el período de extensión para que sea más largo que el tiempo de inferencia por lotes en el peor de los casos.
- Aísla las fallas con un tema de mensajes no entregados: Habilita un tema de mensajes no entregados para aislar automáticamente los mensajes con formato incorrecto que no se entregan de forma reiterada. Este enfoque evita que los mensajes de "píldora venenosa" bloqueen la cola y detengan toda la canalización.
- Implementa estrategias de retirada: Si el servidor de inferencia devuelve errores
429(Demasiadas solicitudes) o503(Servicio no disponible), el suscriptor debe detectar estos errores y, luego, implementar una estrategia de retirada exponencial, pausando temporalmente el consumo de Pub/Sub hasta que el servidor se recupere.
Organiza trabajos por lotes a gran escala
Sigue estas prácticas recomendadas para maximizar la capacidad de procesamiento, garantizar la eficiencia de costos, implementar una trazabilidad integral para la auditoría y aplicar la administración avanzada de cuotas y la priorización de trabajos cuando proceses conjuntos de datos masivos.
Usa JobSet para la inferencia distribuida de varios nodos
Te recomendamos que uses el recurso JobSet de Kubernetes para coordinar cargas de trabajo de inferencia distribuidas que requieren que varios nodos cooperen, como los modelos grandes que se ejecutan en Pods de TPU o clústeres de GPU de varios nodos. Los trabajos estándar de Kubernetes no pueden garantizar que todos los Pods requeridos se inicien de forma simultánea, lo que puede provocar bloqueos en las cargas de trabajo distribuidas.
JobSet es una API nativa de Kubernetes que administra grupos de trabajos como una unidad y proporciona los siguientes beneficios para la inferencia por lotes:
- Programación en grupo: Ayuda a garantizar que todos los recursos necesarios, como las porciones de TPU o los nodos de GPU, estén disponibles antes de iniciar la carga de trabajo para evitar bloqueos.
- Colocación exclusiva: Ayuda a garantizar que un solo JobSet tenga acceso exclusivo a la topología de red (por ejemplo, una porción de TPU) para maximizar el rendimiento de la interconexión.
- Recuperación ante fallas: Te permite reiniciar trabajos replicados específicos o el conjunto completo si falla un trabajador, según tu configuración.
Usa trabajos indexados para la fragmentación de datos
Cuando usas JobSet, configura ReplicatedJob para que use el parámetro de configuración completionMode:
Indexed. Este parámetro de configuración inserta automáticamente una variable de entorno JOB_COMPLETION_INDEX en cada Pod. Tu código de inferencia puede usar este índice para seleccionar de forma determinística un fragmento único de datos para procesar.
Por ejemplo, si tienes un bucket de Cloud Storage con 100,000 imágenes y implementas un JobSet con un paralelismo de 10, cada uno de los 10 Pods lee su índice (0 a 9) al inicio. Luego, el Pod 0 puede calcular que debe procesar las imágenes de 0 a 9,999, mientras que el Pod 1 procesa las imágenes de 10,000 a 19,999. Este enfoque reduce la necesidad de un servicio de lista de tareas en cola independiente.
Usa el patrón de sidecar para la saturación del servidor
Para maximizar el uso del acelerador, configura tus Pods de JobSet con dos contenedores que usen el patrón de sidecar:
- Servidor de inferencia: Un servidor optimizado (como vLLM) que se enfoca por completo en la computación de GPU o TPU.
- Controlador del cliente: Es un contenedor lógico que envía de forma asíncrona un gran volumen de solicitudes al servidor en localhost.
Este desacoplamiento ayuda a garantizar que la GPU o TPU permanezcan ocupadas y nunca estén inactivas mientras esperan la E/S de red o el preprocesamiento de datos. Sin este enfoque, los modelos que cargan datos de forma secuencial pueden hacer que el acelerador espere a que se completen las operaciones de E/S, lo que genera una subutilización. Por ejemplo, en lugar de esperar a que se procesen los datos, el controlador del cliente puede realizar una recuperación previa de los datos y enviar solicitudes asíncronas de forma continua al servidor de inferencia, lo que ayuda a garantizar que la cola de solicitudes del acelerador permanezca saturada.
Resumen de la lista de tareas
| Categoría | Práctica recomendada |
|---|---|
| Patrones de arquitectura |
|
| Costo y capacidad de procesamiento |
|
| Mensajería y escalamiento |
|
| Organización |
|