
In diesem Dokument werden Best Practices für die Ausführung von Batch-Inferenzarbeitslasten in Google Kubernetes Engine (GKE) vorgestellt. Batch Inferenz ist der Prozess, bei dem ein Machine-Learning-Modell verwendet wird, um Vorhersagen für große Datasets zu generieren. Dabei werden ein hoher Durchsatz und Kosteneffizienz gegenüber sofortigen Antworten mit niedriger Latenz priorisiert.
In dieser Anleitung wird zwischen Batch-Inferenz und Batching von Anfragen (oder dynamischem Batching) unterschieden. Dabei handelt es sich um eine serverseitige Technik in Engines wie vLLM oder SGLang, bei der gleichzeitige Echtzeitanfragen gruppiert werden, um die Effizienz des Beschleunigers zu optimieren. Sie können das Batching von Anfragen auf Batch-Inferenzarbeitslasten anwenden.
Die Best Practices in dieser Anleitung decken zwei gängige Arten von Batch-Inferenzmustern ab:
- Asynchrone Inferenz: Verarbeitet Daten in Blöcken kurz nach ihrer Generierung. Mit einer typischen Latenz von Sekunden bis Minuten wird bei diesem Ansatz die Notwendigkeit aktueller Daten mit der Effizienz der gleichzeitigen Verarbeitung mehrerer Elemente in Einklang gebracht. Die asynchrone Inferenz wird manchmal auch als Near-Real-Time-Inferenz bezeichnet.
- Batch-Inferenz: Verarbeitet große Mengen angesammelter Daten in geplanten Intervallen (z. B. täglich oder wöchentlich). Die Latenz liegt in der Regel zwischen Stunden und Tagen, da diese Jobs oft außerhalb der Spitzenzeiten geplant werden, um die Ressourcenverfügbarkeit zu maximieren.
Diese Empfehlungen sind eine spezielle Optimierungsebene, die auf den Grundlagen basiert, die in der Übersicht über Best Practices für die Inferenz in GKE beschrieben sind. Bevor Sie Batcharbeitslasten optimieren, sollten Sie die wichtigsten Best Practices für die Modellauswahl, die Quantisierung und die Auswahl des Beschleunigers befolgt haben.
Architekturmuster für die Batch-Inferenzverarbeitung auswählen
Die Auswahl des richtigen Architekturmusters ist die wichtigste Entscheidung für die Bereitstellung Ihrer Batch-Inferenzarbeitslasten, da sie sich auf die Kompromisse zwischen Latenz, Durchsatz und Kosten auswirkt. Um die Effizienz aufrechtzuerhalten, muss der Inferenzdurchsatz außerhalb der Spitzenzeiten höher sein als die Rate eingehender Anfragen, damit die Warteschlangen nicht unendlich lang werden.
Asynchrone Inferenz für burstartige Arbeitslasten verwenden
Die asynchrone Inferenz eignet sich gut für Anwendungsfälle, die häufige, inkrementelle Updates erfordern, z. B.:
- Empfehlungsprofile für Nutzer alle paar Minuten basierend auf den letzten Interaktionen aktualisieren.
- Erwähnungen in sozialen Medien in Intervallen von einer Minute für die Echtzeitüberwachung verarbeiten.
- Marktbewegende Signale aus Finanzdatenstreams mit hoher Frequenz erkennen.
- Sentimentanalyse für eingehendes Kundenfeedback oder Newsfeeds durchführen.
Wählen Sie dieses Muster aus, wenn Ihre Arbeitslast eine Latenz von mehreren Sekunden bis zu einigen Minuten tolerieren kann.
Berücksichtigen Sie bei der Implementierung der asynchronen Inferenz die folgenden Merkmale:
- Latenz: Die Zeit bis zum ersten Token liegt zwischen einigen Sekunden und Minuten.
- Datenquellen: In der Regel verarbeiten Sie Datasets mit einer Größe von Megabyte bis Gigabyte, z. B. Nachrichten aus Pub/Sub oder Dateien aus Cloud Storage, die über einen kurzen Zeitraum angesammelt wurden.
- Computing-Muster: Ihre Infrastruktur sollte einen kontinuierlichen Dienst unterstützen, der häufige Arbeitsspitzen verarbeitet.
- Kostenoptimierung: Dieses Muster bietet ein Gleichgewicht zwischen Echtzeit-Inferenz mit niedriger Latenz und Batchverarbeitung mit hohem Durchsatz.
Batch-Inferenz für große Datasets verwenden
Die Batch-Inferenz eignet sich ideal für umfangreiche, episodische Jobs, die Verzögerungen von Stunden oder Tagen tolerieren können, z. B.:
- Tägliche Risikobewertungsberichte basierend auf den Finanztransaktionen des Vortags erstellen.
- Produkteinbettungen für einen gesamten Katalog erstellen, um nachgelagerte Such- und Empfehlungssysteme zu unterstützen.
- Große Datasets mit Bildern für das Modelltraining oder die Archivierungskategorisierung labeln.
Wählen Sie dieses Muster aus, wenn Sie große Datenmengen verarbeiten und Latenzen von Stunden bis zu mehreren Tagen tolerieren können.
Berücksichtigen Sie bei der Implementierung der Batch-Inferenz die folgenden Merkmale:
- Latenz: Die Latenz beim Start der Arbeitslast liegt in der Regel zwischen Minuten und Tagen da Jobs oft außerhalb der Spitzenzeiten geplant werden.
- Datenquellen: Sie verarbeiten große Datasets mit einer Größe von Gigabyte bis Petabyte, die in der Regel in Cloud Storage- oder BigQuery-Tabellen gespeichert sind.
- Computing-Muster: Sie verwenden episodische, burstartige Jobs, die initialisiert werden, die Daten verarbeiten und dann beendet werden.
- Kostenoptimierung: Dieses Muster lässt sich mit einem Pay-per-Use Modell sehr gut optimieren. Da Batchjobs flexible Abschlusszeiträume haben, empfehlen wir, Spot-VMs zu verwenden, um Kosten zu senken.
Auf Durchsatz und Kosteneffizienz optimieren
Batch-Inferenzarbeitslasten eignen sich besonders gut für kostensparende Infrastrukturen, bei denen es zu Unterbrechungen kommen kann.
Spot-VMs verwenden, um Computing-Kosten zu senken
Nutzen Sie die Rabatte von Spot-VMs für Batchjobs. Da Batch-Inferenzarbeitslasten in der Regel Latenz und Unterbrechungen tolerieren, eignen sie sich gut für die Nutzung von Spot-Kapazität zu einem reduzierten Preis.
Achten Sie darauf, dass Ihr Batch-Inferenzcode Checkpointing implementiert, um potenzielle Vorabereignisse zu verarbeiten. Wenn eine Spot-VM vorzeitig beendet wird, können Sie einen neuen Knoten erstellen und Ihre Arbeitslast ab dem letzten verarbeiteten Batch fortsetzen, anstatt von Grund auf neu zu beginnen.
Batchgröße der Arbeitslast und Batchgröße der Anfrage optimieren
Um Ressourcenkonflikte und Job-Time-outs zu vermeiden, muss die Anzahl der Elemente, die an Ihre Engine gesendet werden (Batch der Arbeitslast), mindestens so groß sein wie die Anzahl der gleichzeitigen Anfragen, die der Server verarbeiten kann (Batch der Anfrage), um eine Unterauslastung der Beschleuniger zu vermeiden.
Batchgröße der Arbeitslast optimieren
Die Batchgröße der Arbeitslast ist die Gesamtzahl der Elemente, die in einer einzelnen Arbeitseinheit an Ihre Inferenz-Engine gesendet werden. Sie konfigurieren dies in der Logik für die Clientübermittlung oder in der Kubernetes-Jobkonfiguration, indem Sie Ihre Daten fragmentieren oder mehrere Elemente in einer einzelnen Anfrage gruppieren.
Verwenden Sie die folgenden Grenzwerte, um die optimale Batchgröße der Arbeitslast zu ermitteln:
- Mindestbatchgröße berechnen: Die Batchgröße der Arbeitslast muss mindestens so groß sein wie die Batchgröße der Anfrage. Wenn Sie beispielsweise ein Element an einen Server senden, der 256 Elemente gleichzeitig verarbeiten kann, führt dies zu einer erheblichen Unterauslastung. Die Mindestgröße finden Sie in der Konfiguration Ihres Inferenzservers, z. B. im Argument
max_num_seqsin vLLM. Sie können Ihre Clientlogik so konfigurieren, dass mehrere Elemente in einer einzelnen Anfrage gruppiert werden, oder Sie können Ihre Daten so fragmentieren, dass jeder Job eine Mindestmenge an Daten erhält, die der Batchgröße der Anfrage entspricht oder diese übersteigt. - Maximale Batchgröße berechnen: Die Batchgröße der Arbeitslast muss so sein, dass
der Pod die Verarbeitung beendet, bevor das
activeDeadlineSecondsZeitlimit erreicht wird, das in Ihrem Kubernetes -Job definiert ist. Schätzen Sie die Zeit, die für die Verarbeitung eines Anfragebatches erforderlich ist, und legen Sie die Größe der Arbeitslast so fest, dass der Pod die Verarbeitung deutlich vor Ablauf der Frist beendet. WennactiveDeadlineSecondsbeispielsweise 3.600 Sekunden und der Start-Overhead 600 Sekunden beträgt, muss die maximale Ausführungszeit so sein, dass der Pod die Verarbeitung in weniger als 3.000 Sekunden beendet.
Wenn die Batchgröße der Arbeitslast zu klein ist, verschwendet Ihr Job Zeit mit dem Pod
Start-Overhead (Gewichte herunterladen, Ressourcen bereitstellen, Beschleuniger initialisieren);
wenn sie zu groß ist, wird der Job möglicherweise von
GKE aufgrund des
activeDeadlineSeconds
-Zeitlimits beendet, was dazu führt, dass der Job fehlschlägt und der Fortschritt verloren geht.
Batchgröße der Anfrage optimieren
Die Batchgröße der Anfrage ist die Anzahl der gleichzeitigen Anfragen, die der Inferenzserver gleichzeitig auf dem Beschleuniger verarbeitet. Sie optimieren diesen Parameter, indem Sie serverspezifische Flags in der Konfiguration Ihres Inferenzservers anpassen (z. B. das Flag --max-num-seqs für vLLM).
Ziel ist es, die GPU-Auslastung zu maximieren, ohne Fehler aufgrund von zu wenig Arbeitsspeicher auszulösen. Wenn die Batchgröße der Anfrage nicht kalibriert ist, wird der Beschleuniger entweder unterausgelastet oder der Modellserver stürzt ab. Für vLLM können Sie
Tools wie das vLLM-Skript `auto_tune` verwenden, um
die besten Werte für die Einstellungen max_num_seqs und max_num_batched_tokens für Ihre
spezifische Hardware zu finden. Weitere Informationen finden Sie unter
Konfiguration des Inferenzservers optimieren
in der Anleitung Übersicht über Best Practices für die Inferenz in GKE.
Asynchrone Komponenten für die asynchrone Inferenz implementieren
Für die asynchrone Inferenz empfehlen wir, Nachrichtenpuffer zu verwenden, um die Aufnahmeschicht von der Inferenzschicht zu entkoppeln.
Das folgende Architekturdiagramm zeigt ein Beispiel für eine asynchrone Inferenzplattform. Diese Architektur schützt Inferenzserver vor Traffic-Spitzen, verwaltet Arbeitsrückstände und sorgt für eine hohe Auslastung des Beschleunigers.
Das Diagramm zeigt den Fluss von Pub/Sub zu Abonnenten, einem Inferenzgateway und einem Inferenzserver. Die Ergebnisse werden in AlloyDB gespeichert und fehlgeschlagene Nachrichten werden an ein Thema für unzustellbare Nachrichten gesendet.
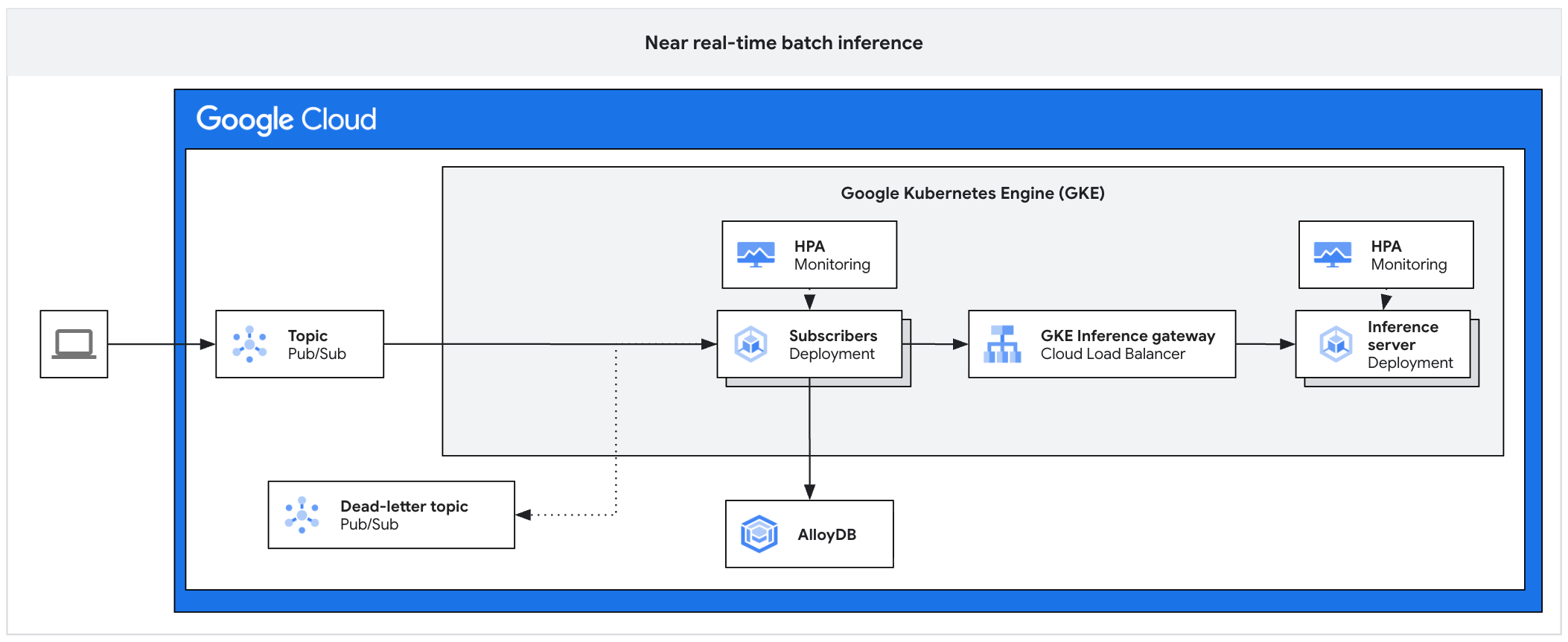
Die Architektur besteht aus den folgenden Komponenten:
- Pub/Sub-Thema:Fungiert als dauerhafter Puffer für eingehende Clientnachrichten mit einer Aufbewahrungsdauer von 7 bis 31 Tagen.
- Abonnent:Eine Komponente, die Nachrichtenbatches liest, Anfragen an den Inferenzserver sendet und die Verarbeitung bestätigt.
- HPA für Abonnenten:Skaliert die Bereitstellung des Abonnenten basierend auf dem Messwert
num_undelivered_messages(Anzahl der nicht bestätigten Nachrichten). - Speicher:Inferenz-Ergebnisse mit einer Datenbank (z. B. AlloyDB) oder einem Objektspeicher (z. B. Cloud Storage) speichern.
- Inferenzgateway:Macht die Inferenzarbeitslasten für den Abonnenten verfügbar.
- Inferenzserver:Verarbeitet die Batch-Inferenzanfragen (z. B. vLLM).
- HPA für Server:Skaliert die Inferenz-Engine basierend auf enginespezifischen Messwerten wie
vllm:num_requests_waiting. - Thema für unzustellbare Nachrichten:Erfasst Nachrichten, deren Verarbeitung nach einer bestimmten Anzahl von Wiederholungen mit exponentiellem Backoff fehlschlägt.
Weitere Informationen finden Sie in der Referenzimplementierung auf GitHub.
Anfragen puffern und aggregieren
So verwalten Sie den Fluss von Anfragen:
- Pub/Sub als dauerhaften Puffer verwenden:Implementieren Sie Pub/Sub, um Inferenzanfragen dauerhaft zu speichern. Diese Einrichtung fungiert als FIFO-Puffer, der Anfragen so lange speichert, bis ein Consumer sie verarbeiten kann. So wird eine Serverüberlastung bei burstartigem Traffic verhindert.
- Pull-Abos mit clientseitiger Ablaufsteuerung verwenden:Konfigurieren Sie ein Pull Abomodell. So kann Ihre Abonnentenanwendung Nachrichten nur dann explizit anfordern, wenn sie sie verarbeiten kann. Sie haben die volle Kontrolle über die Verbrauchsrate.
- Nachrichten aggregieren, um die Batchgröße des Servers zu füllen:Senden Sie nicht eine Pub/Sub-Nachricht als eine Inferenzanfrage. Stattdessen sollte der Abonnent mehrere Nachrichten in einer einzelnen Batchanfrage bündeln, die der optimalen Batchgröße Ihres Inferenzservers entspricht (z. B. passend zu den
max_num_seqs-Einstellungen in vLLM). Dieser Ansatz trägt dazu bei, dass die Beschleuniger voll ausgelastet sind und der Durchsatz maximiert wird. Konfigurieren Sie insbesondere die Pull-Einstellungmax_messagesIhres Abonnenten auf ein Vielfaches vonmax_num_seqs, um sicherzustellen, dass jeder Vorwärtsdurchlauf des Modells voll ausgelastet ist.
Abonnenten und Server automatisch skalieren
Für eine effektive Batch-Inferenz müssen die Abonnenten (CPU-gebunden) anders skaliert werden als die Inferenzserver (GPU- oder TPU-gebunden).
Abonnenten basierend auf Arbeitsrückständen skalieren:Konfigurieren Sie das horizontale Pod-Autoscaling (HPA) für die Bereitstellung Ihrer Abonnenten basierend auf dem Messwert
num_undelivered_messagesaus Pub/Sub. Weitere Informationen finden Sie unter Pod-Autoscaling anhand von Messwerten optimieren. Berechnen Sie die Anzahl der Replikate, die Sie verwenden möchten, mit der folgenden Gleichung:\[ desiredReplicas = \frac{num\_undelivered\_messages}{target\_latency\_seconds \times throughput\_per\_replica} \]
Infrastrukturkontingente berücksichtigen:Begrenzen Sie die maximale Anzahl der Replikate Ihrer Abonnenten explizit, indem Sie die Einstellung
maxReplicasin Ihrem HPA konfigurieren. Skalieren Sie Abonnenten nicht über das hinaus, was das GPU- oder TPU-Kontingent Ihrer Inferenzserver unterstützt. Wenn Sie zu viele Abonnenten bereitstellen, wird der Engpass zum Inferenzserver verschoben und die Ressourcenkonflikte nehmen zu, ohne dass der Durchsatz steigt.Inferenzserver basierend auf Engine-Messwerten skalieren:Skalieren Sie die Bereitstellung Ihres Inferenzservers basierend auf Messwerten, die direkt von der Inferenz-Engine exportiert werden (nicht nur über CPU/Arbeitsspeicher). Verwenden Sie beispielsweise die Einstellung
vllm:num_requests_waitingfür vLLM, die den Verarbeitungsrückstand direkt auf Modellserverebene misst. Weitere Informationen finden Sie unter Pods automatisch skalieren.
Fehler und Time-outs verarbeiten
So verarbeiten Sie Fehler und Time-outs:
- Bestätigungsfristen proaktiv verlängern:Konfigurieren Sie Ihren Abonnenten so, dass er die Pub/Sub-Bestätigungsfrist (Ack) für Nachrichten, die verarbeitet werden, proaktiv verlängert, um Wiederholungsschleifen und doppelte Verarbeitung zu vermeiden. Dieser Ansatz ist erforderlich, da Inferenzaufgaben oft länger dauern als die Standard-Time-out-Zeiträume. In der Regel sollte der Verlängerungszeitraum länger sein als die Batch-Inferenzzeit im Worst-Case-Szenario.
- Fehler mit einem Thema für unzustellbare Nachrichten isolieren:Aktivieren Sie ein Thema für unzustellbare Nachrichten, um fehlerhafte Nachrichten, deren Zustellung wiederholt fehlschlägt, automatisch zu isolieren. So wird verhindert, dass „Poison Pill“-Nachrichten die Warteschlange blockieren und die gesamte Pipeline anhalten.
- Backoff-Strategien implementieren:Wenn der Inferenzserver die Fehler
429(Zu viele Anfragen) oder503(Dienst nicht verfügbar) zurückgibt, muss der Abonnent diese abfangen und eine exponentielle Backoff-Strategie implementieren, um den Verbrauch von Pub/Sub vorübergehend zu pausieren, bis der Server wieder verfügbar ist.
Batchjobs im großen Maßstab orchestrieren
Beachten Sie diese Best Practices, um den Durchsatz zu maximieren, Kosteneffizienz zu gewährleisten, eine umfassende Rückverfolgbarkeit für Audits zu implementieren und eine erweiterte Kontingentverwaltung und Jobpriorisierung anzuwenden, wenn Sie große Datasets verarbeiten.
JobSet für verteilte Inferenz mit mehreren Knoten verwenden
Wir empfehlen, die Kubernetes JobSet Ressource zu verwenden, um verteilte Inferenzarbeitslasten zu orchestrieren, bei denen mehrere Knoten zusammenarbeiten müssen, z. B. große Modelle, die auf TPU-Pods oder GPU Clustern mit mehreren Knoten ausgeführt werden. Standard-Kubernetes-Jobs können nicht garantieren, dass alle erforderlichen Pods gleichzeitig gestartet werden, was zu Deadlocks bei verteilten Arbeitslasten führen kann.
JobSet ist eine Kubernetes-native API, die Gruppen von Jobs als Einheit verwaltet und die folgenden Vorteile für die Batch-Inferenz bietet:
- Gang-Scheduling:Sorgt dafür, dass alle erforderlichen Ressourcen wie TPU-Slices oder GPU-Knoten verfügbar sind, bevor die Arbeitslast gestartet wird, um Deadlocks zu vermeiden.
- Exklusive Platzierung:Sorgt dafür, dass ein einzelnes JobSet exklusiven Zugriff auf die Netzwerktopologie hat (z. B. ein TPU-Slice), um die Interconnect-Leistung zu maximieren.
- Fehlerbehebung:Je nach Konfiguration können Sie bestimmte replizierte Jobs oder das gesamte Set neu starten, wenn ein Worker ausfällt.
Indizierte Jobs für die Datenfragmentierung verwenden
Wenn Sie JobSet verwenden, konfigurieren Sie die ReplicatedJob so, dass die Einstellung completionMode:
Indexed verwendet wird. Mit dieser Einstellung wird automatisch eine Umgebungsvariable JOB_COMPLETION_INDEX in jeden Pod eingefügt. Ihr Inferenzcode kann diesen Index verwenden, um deterministisch einen eindeutigen Shard von Daten zur Verarbeitung auszuwählen.
Wenn Sie beispielsweise einen Cloud Storage-Bucket mit 100.000 Bildern haben und ein JobSet mit einem Parallelismus von 10 bereitstellen, liest jeder der 10 Pods beim Start seinen Index (0–9). Pod 0 kann dann berechnen, dass er die Bilder 0–9.999 verarbeiten soll, während Pod 1 die Bilder 10.000–19.999 verarbeitet. Dieser Ansatz macht einen separaten Dienst für die Aufgabenwarteschlange überflüssig.
Sidecar-Muster für die Serversättigung verwenden
Um die Auslastung des Beschleunigers zu maximieren, konfigurieren Sie Ihre JobSet-Pods mit zwei Containern mithilfe des Sidecar-Musters:
- Inferenzserver:Ein optimierter Server (z. B. vLLM), der sich ausschließlich auf GPU- oder TPU-Berechnungen konzentriert.
- Clienttreiber:Ein Logikcontainer, der asynchron eine große Anzahl von Anfragen an den Server auf localhost sendet.
Diese Entkopplung trägt dazu bei, dass die GPU oder TPU ausgelastet bleibt und nie inaktiv ist, während auf Netzwerk-E/A oder die Datenvorverarbeitung gewartet wird. Ohne diesen Ansatz kann es vorkommen, dass Modelle, die Daten sequenziell laden, dazu führen, dass der Beschleuniger auf den Abschluss von E/A-Vorgängen wartet, was zu einer Unterauslastung führt. Anstatt beispielsweise auf die Verarbeitung der Daten zu warten, kann der Clienttreiber Daten vorab abrufen und kontinuierlich asynchrone Anfragen an den Inferenzserver senden. So wird sichergestellt, dass die Anfragewarteschlange des Beschleunigers ausgelastet bleibt.
Zusammenfassung der Checkliste
| Kategorie | Best Practice |
|---|---|
| Architekturmuster |
|
| Kosten und Durchsatz |
|
| Messaging und Skalierung |
|
| Orchestrierung |
|