
Dokumen ini memberikan praktik terbaik untuk menjalankan workload inferensi batch di Google Kubernetes Engine (GKE). Inferensi batch adalah proses penggunaan model machine learning untuk menghasilkan prediksi pada set data besar, dengan memprioritaskan throughput tinggi dan efisiensi biaya daripada respons langsung dan latensi rendah.
Panduan ini membedakan inferensi batch dari pengelompokan batch permintaan (atau pengelompokan dinamis)—teknik sisi server di mesin seperti vLLM atau SGLang yang mengelompokkan permintaan real-time serentak untuk mengoptimalkan efisiensi akselerator. Anda dapat menerapkan pengelompokan batch permintaan ke workload inferensi batch.
Praktik terbaik dalam panduan ini mencakup dua jenis pola inferensi batch umum:
- Inferensi asinkron: memproses data dalam potongan segera setelah data dibuat. Dengan latensi umum dalam hitungan detik hingga menit, pendekatan ini menyeimbangkan kebutuhan akan data baru dengan efisiensi pemrosesan beberapa item secara bersamaan. Inferensi asinkron terkadang disebut sebagai inferensi hampir real-time.
- Inferensi batch: memproses data terakumulasi dalam volume besar pada interval terjadwal (misalnya, setiap malam atau mingguan). Latensi biasanya berkisar antara jam hingga hari, karena tugas ini sering dijadwalkan selama jam tidak sibuk untuk memaksimalkan ketersediaan resource.
Rekomendasi ini adalah lapisan pengoptimalan khusus yang dibangun berdasarkan fondasi yang dijelaskan dalam Ringkasan praktik terbaik inferensi di GKE. Sebelum mengoptimalkan workload batch, pastikan Anda telah mengikuti praktik terbaik inti untuk pemilihan model, kuantisasi, dan pilihan akselerator.
Memilih pola arsitektur untuk pemrosesan inferensi batch
Memilih pola arsitektur yang tepat adalah keputusan terpenting untuk men-deploy workload inferensi batch karena memengaruhi pertukaran antara latensi, throughput, dan biaya. Untuk mempertahankan efisiensi, pastikan throughput inferensi Anda melebihi kecepatan kueri masuk selama jam tidak sibuk untuk mencegah antrean tumbuh tanpa batas.
Menggunakan inferensi asinkron untuk pekerjaan yang tidak terduga
Inferensi asinkron berfungsi dengan baik untuk kasus penggunaan yang memerlukan update inkremental yang sering, seperti berikut:
- Memperbarui profil rekomendasi pengguna setiap beberapa menit berdasarkan interaksi terbaru.
- Memproses sebutan media sosial dengan interval satu menit untuk pemantauan real-time.
- Mendeteksi sinyal penggerak pasar dari aliran data keuangan frekuensi tinggi.
- Melakukan analisis sentimen pada masukan pelanggan atau feed berita yang masuk.
Pilih pola ini jika workload Anda dapat mentoleransi latensi yang berkisar antara beberapa detik hingga beberapa menit.
Saat Anda menerapkan inferensi asinkron, pertimbangkan karakteristik berikut:
- Latensi: Anda dapat memperkirakan waktu hingga token pertama berkisar antara puluhan detik hingga menit.
- Sumber data: Anda biasanya memproses set data yang berkisar dari megabyte hingga gigabyte, seperti pesan dari Pub/Sub atau file dari Cloud Storage yang terakumulasi dalam jangka waktu singkat.
- Pola komputasi: infrastruktur Anda harus mendukung layanan berkelanjutan yang menangani pekerjaan yang tidak terduga.
- Pengoptimalan biaya: pola ini menawarkan keseimbangan antara inferensi real-time latensi rendah dan pemrosesan batch throughput tinggi.
Menggunakan inferensi batch untuk set data besar
Inferensi batch ideal untuk tugas skala besar dan episodik yang dapat mentoleransi penundaan selama berjam-jam atau berhari-hari, seperti berikut:
- Membuat laporan penilaian risiko setiap malam berdasarkan transaksi keuangan hari sebelumnya.
- Membuat embedding produk untuk seluruh katalog guna mendukung sistem penelusuran dan rekomendasi downstream.
- Memberi label pada set data gambar yang besar untuk pelatihan model atau kategorisasi arsip.
Pilih pola ini jika Anda memproses data dalam volume besar dan dapat mentoleransi latensi yang berkisar antara jam hingga beberapa hari.
Saat Anda menerapkan inferensi batch, pertimbangkan karakteristik berikut:
- Latensi: latensi awal workload biasanya berkisar antara menit hingga hari karena tugas sering dijadwalkan selama jam tidak sibuk.
- Sumber data: Anda memproses set data besar dari gigabyte hingga petabyte, yang biasanya disimpan dalam tabel Cloud Storage atau BigQuery.
- Pola komputasi: Anda menggunakan tugas episodik dan tidak terduga yang melakukan inisialisasi, memproses data, lalu menghentikan tugas.
- Pengoptimalan biaya: pola ini sangat dapat dioptimalkan dengan model bayar sesuai penggunaan. Karena tugas batch memiliki jendela penyelesaian yang fleksibel, sebaiknya gunakan Spot VM untuk mengurangi biaya.
Mengoptimalkan throughput dan efisiensi biaya
Workload inferensi batch sangat cocok untuk infrastruktur hemat biaya yang mungkin melibatkan gangguan.
Menggunakan Spot VM untuk mengurangi biaya komputasi
Gunakan diskon Spot VM untuk tugas batch. Karena workload inferensi batch biasanya toleran terhadap latensi dan gangguan, workload ini merupakan kandidat yang baik untuk harga kapasitas Spot yang lebih rendah.
Pastikan kode inferensi batch Anda menerapkan checkpointing untuk menangani potensi peristiwa preemption. Jika Spot VM di-preempt, Anda dapat membuat node baru dan melanjutkan workload dari batch terakhir yang diproses, bukan memulai ulang dari nol.
Menyesuaikan ukuran batch workload dan ukuran batch permintaan
Untuk menghindari pertentangan resource dan waktu tunggu tugas, pastikan jumlah item yang dikirim ke mesin Anda (batch workload) setidaknya sama besar dengan permintaan serentak yang dapat diproses server (batch permintaan) untuk menghindari penggunaan akselerator yang kurang optimal.
Menyesuaikan ukuran tumpukan workload
Ukuran batch workload adalah jumlah total item yang dikirim ke mesin inferensi Anda dalam satu unit kerja. Anda mengonfigurasi hal ini dalam logika pengiriman klien atau konfigurasi Tugas Kubernetes dengan melakukan sharding data atau mengelompokkan beberapa item ke dalam satu permintaan.
Untuk menentukan ukuran batch workload yang optimal, gunakan batas berikut:
- Menghitung ukuran batch minimum: pastikan ukuran batch workload Anda setidaknya sama besar dengan ukuran batch permintaan. Misalnya, mengirim satu item ke server yang dapat memproses 256 item secara serentak akan menghasilkan penggunaan yang sangat kurang optimal. Untuk menemukan ukuran minimum, periksa konfigurasi server inferensi Anda, seperti argumen
max_num_seqsdi vLLM. Anda dapat mengonfigurasi logika klien untuk mengelompokkan beberapa item ke dalam satu permintaan, atau Anda dapat melakukan sharding data sehingga setiap Tugas menerima jumlah data minimum yang memenuhi atau melebihi ukuran batch permintaan. - Menghitung ukuran batch maksimum: pastikan ukuran batch workload Anda memungkinkan
Pod selesai sebelum mencapai waktu tunggu
activeDeadlineSecondsyang ditentukan dalam Tugas Kubernetes. Perkirakan waktu yang diperlukan untuk memproses satu batch permintaan dan tetapkan ukuran workload sehingga Pod selesai dalam batas waktu. Misalnya, jikaactiveDeadlineSecondsAnda adalah 3.600 detik, dan overhead startup Anda adalah 600 detik, pastikan waktu eksekusi maksimum memungkinkan Pod selesai dalam waktu 3.000 detik.
Jika ukuran batch workload Anda terlalu kecil, tugas Anda akan membuang waktu untuk overhead startup Pod (mendownload bobot, menyediakan, menginisialisasi akselerator);
jika terlalu besar, Anda berisiko Tugas dihentikan oleh
GKE karena waktu tunggu
activeDeadlineSeconds, yang menyebabkan Tugas gagal dan kehilangan progresnya.
Menyesuaikan ukuran batch permintaan
Ukuran tumpukan permintaan adalah jumlah permintaan serentak yang diproses server inferensi secara bersamaan di akselerator. Anda mengoptimalkan parameter ini dengan menyesuaikan flag khusus server dalam konfigurasi server inferensi (misalnya, flag --max-num-seqs untuk vLLM).
Tujuan Anda adalah memaksimalkan penggunaan GPU tanpa memicu error Kehabisan Memori (OOM). Jika ukuran batch permintaan tidak dikalibrasi, sistem Anda akan menggunakan akselerator secara kurang optimal atau menyebabkan server model mengalami error. Untuk vLLM, Anda dapat menggunakan
alat seperti skrip
vLLM auto_tune untuk
menemukan nilai terbaik untuk max_num_seqs dan max_num_batched_tokens setelan untuk hardware
tertentu. Untuk mengetahui informasi selengkapnya, lihat
Mengoptimalkan konfigurasi server inferensi Anda
dalam panduan Ringkasan praktik terbaik inferensi di GKE.
Mengimplementasikan komponen asinkron untuk inferensi Asinkron
Untuk inferensi Asinkron, sebaiknya gunakan buffer pesan untuk memisahkan lapisan penyerapan dari lapisan inferensi.
Diagram arsitektur berikut mengilustrasikan contoh platform inferensi asinkron. Arsitektur ini melindungi server inferensi dari lonjakan traffic, mengelola backlog pekerjaan, dan memastikan penggunaan akselerator yang tinggi.
Diagram ini menunjukkan alur dari Pub/Sub ke pelanggan, gateway inferensi, dan server inferensi, dengan hasil yang dipertahankan di AlloyDB dan pesan yang gagal dikirim ke topik yang dihentikan pengirimannya.
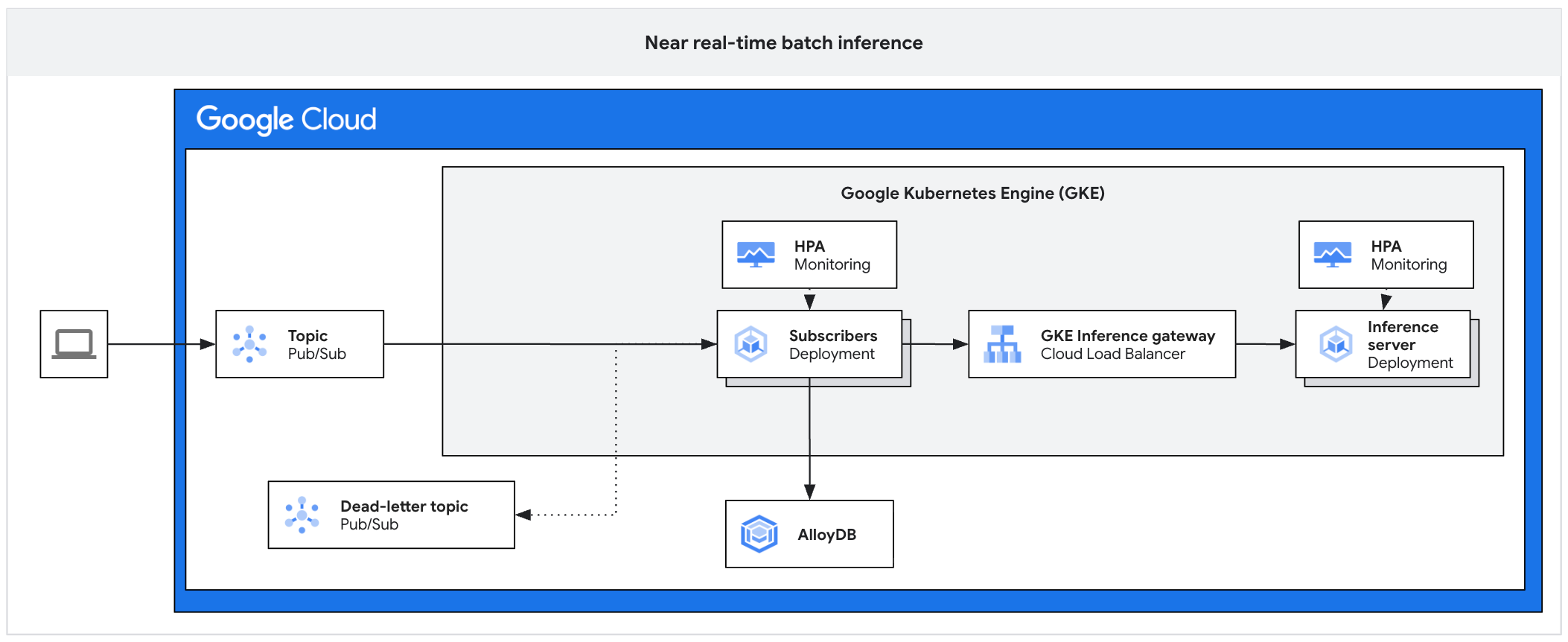
Arsitektur ini terdiri dari komponen berikut:
- Topik Pub/Sub: bertindak sebagai buffer persisten untuk pesan klien yang masuk, dengan periode retensi data 7 hingga 31 hari.
- Pelanggan: komponen yang membaca batch pesan, mengirim permintaan ke server inferensi, dan mengonfirmasi pemrosesan.
- HPA Pelanggan: menskalakan deployment pelanggan berdasarkan metrik
num_undelivered_messages(jumlah pesan yang tidak dikonfirmasi). - Penyimpanan: mempertahankan hasil inferensi menggunakan database (seperti AlloyDB) atau penyimpanan objek (seperti Cloud Storage) .
- Gateway Inferensi: mengekspos workload inferensi ke pelanggan.
- Server Inferensi: memproses permintaan inferensi batch (misalnya, vLLM).
- HPA Server: menskalakan mesin inferensi berdasarkan metrik khusus mesin seperti
vllm:num_requests_waiting. - Topik yang dihentikan pengirimannya: menangkap pesan yang gagal diproses setelah sejumlah percobaan ulang backoff eksponensial.
Untuk mengetahui informasi selengkapnya, lihat implementasi referensi di GitHub.
Mem-buffer dan menggabungkan permintaan
Untuk mengelola alur permintaan, lakukan hal berikut:
- Menggunakan Pub/Sub sebagai buffer yang tahan lama: implementasikan Pub/Sub untuk menyimpan permintaan inferensi secara tahan lama. Penyiapan ini bertindak sebagai buffer FIFO yang menyimpan permintaan hingga konsumen memiliki kapasitas untuk memprosesnya, sehingga mencegah server kelebihan muatan selama traffic yang tidak terduga.
- Menggunakan langganan pull dengan kontrol alur sisi klien: konfigurasikan model langganan Pull. Hal ini memungkinkan aplikasi pelanggan Anda meminta pesan secara eksplisit hanya jika memiliki kapasitas untuk memprosesnya, sehingga Anda memiliki kontrol penuh atas kecepatan konsumsi.
- Menggabungkan pesan untuk mengisi ukuran tumpukan server: hindari mengirim satu pesan Pub/Sub sebagai satu permintaan inferensi. Sebagai gantinya, pelanggan harus menggabungkan beberapa pesan ke dalam satu permintaan batch yang selaras dengan ukuran batch optimal server inferensi Anda (misalnya, yang cocok dengan setelan
max_num_seqsdi vLLM). Pendekatan ini membantu memastikan akselerator sepenuhnya jenuh dan memaksimalkan throughput. Secara khusus, konfigurasikan setelan pullmax_messagespelanggan Anda ke kelipatanmax_num_seqsuntuk memastikan setiap model forward pass sepenuhnya jenuh.
Melakukan penskalaan otomatis pelanggan dan server
Inferensi batch yang efektif memerlukan penskalaan pelanggan (terikat CPU) secara berbeda dari server inferensi (terikat GPU atau TPU).
Menskalakan pelanggan berdasarkan backlog pekerjaan: konfigurasikan HorizontalPodAutoscaler (HPA) untuk deployment pelanggan Anda berdasarkan metrik
num_undelivered_messagesdari Pub/Sub. Untuk mengetahui informasi selengkapnya, lihat contoh HPA Pub/Sub. Hitung replika yang ingin Anda gunakan menggunakan persamaan berikut:\[ desiredReplicas = \frac{num\_undelivered\_messages}{target\_latency\_seconds \times throughput\_per\_replica} \]
Mematuhi kuota infrastruktur: batasi secara eksplisit replika maksimum pelanggan Anda dengan mengonfigurasi setelan
maxReplicasdi HPA. Jangan menskalakan pelanggan melebihi kuota GPU atau TPU server inferensi Anda. Penyediaan pelanggan yang berlebihan akan mengalihkan bottleneck ke server inferensi, sehingga meningkatkan pertentangan resource tanpa meningkatkan throughput.Menskalakan server inferensi berdasarkan metrik mesin: skalakan deployment server inferensi Anda berdasarkan metrik yang diekspor langsung oleh mesin inferensi (tidak hanya melalui CPU/Memori). Misalnya, gunakan setelan
vllm:num_requests_waitinguntuk vLLM, yang secara langsung mengukur backlog pemrosesan di tingkat server model. Untuk mengetahui informasi selengkapnya, lihat Menskalakan Pod Anda secara otomatis.
Menangani error dan waktu tunggu
Untuk menangani error dan waktu tunggu, lakukan hal berikut:
- Memperpanjang batas waktu konfirmasi secara proaktif: konfigurasikan pelanggan Anda untuk memperpanjang batas waktu konfirmasi (ack) Pub/Sub secara proaktif untuk pesan yang sedang diproses guna mencegah loop pengiriman ulang dan pemrosesan duplikat. Pendekatan ini diperlukan karena tugas inferensi sering kali memerlukan waktu lebih lama daripada jendela waktu tunggu default. Sebagai aturan umum, tetapkan periode perpanjangan agar lebih lama dari waktu inferensi batch kasus terburuk Anda.
- Mengisolasi kegagalan dengan topik yang dihentikan pengirimannya: aktifkan topik yang dihentikan pengirimannya untuk mengisolasi pesan yang salah format secara otomatis yang gagal dikirim berulang kali. Pendekatan ini mencegah pesan "poison pill" memblokir antrean dan menghentikan seluruh pipeline Anda.
- Mengimplementasikan strategi backoff: jika server inferensi menampilkan error
429(Terlalu Banyak Permintaan) atau503(Layanan Tidak Tersedia), pelanggan harus menangkap error ini dan mengimplementasikan strategi backoff eksponensial, yang menghentikan sementara konsumsi dari Pub/Sub hingga server pulih.
Mengorkestrasi tugas batch dalam skala besar
Ikuti praktik terbaik ini untuk memaksimalkan throughput, memastikan efisiensi biaya, menerapkan keterlacakan komprehensif untuk audit, dan menerapkan pengelolaan kuota serta prioritas tugas lanjutan, saat memproses set data besar.
Menggunakan JobSet untuk inferensi terdistribusi multi-node
Sebaiknya gunakan resource JobSet Kubernetes untuk mengorkestrasi workload inferensi terdistribusi yang memerlukan beberapa node untuk berkolaborasi, seperti model besar yang berjalan di Pod TPU atau cluster GPU multi-node. Tugas Kubernetes Standar tidak dapat menjamin bahwa semua Pod yang diperlukan dimulai secara bersamaan, yang dapat menyebabkan deadlock dalam workload terdistribusi.
JobSet adalah API native Kubernetes yang mengelola grup Tugas sebagai satu unit dan memberikan manfaat berikut untuk inferensi batch:
- Penjadwalan gang: membantu memastikan semua resource yang diperlukan, seperti slice TPU atau node GPU, tersedia sebelum memulai workload untuk mencegah deadlock.
- Penempatan eksklusif: membantu memastikan bahwa satu JobSet memiliki akses eksklusif ke topologi jaringan (misalnya, slice TPU) untuk memaksimalkan performa interkoneksi.
- Pemulihan kegagalan: memungkinkan Anda memulai ulang tugas yang direplikasi tertentu atau seluruh set jika pekerja gagal, bergantung pada konfigurasi Anda.
Menggunakan Tugas Terindeks untuk sharding data
Saat menggunakan JobSet, konfigurasikan ReplicatedJob untuk menggunakan setelan completionMode:
Indexed. Setelan ini secara otomatis menyisipkan variabel lingkungan JOB_COMPLETION_INDEX ke setiap Pod. Kode inferensi Anda dapat menggunakan indeks ini untuk memilih shard data unik secara deterministik untuk diproses.
Misalnya, jika Anda memiliki bucket Cloud Storage dengan 100.000 gambar dan men-deploy JobSet dengan paralelisme 10, setiap 10 Pod akan membaca indeksnya (0-9) saat startup. Pod 0 kemudian dapat menghitung bahwa Pod tersebut harus memproses gambar 0-9.999, sedangkan Pod 1 memproses 10.000-19.999. Pendekatan ini mengurangi kebutuhan akan layanan antrean tugas terpisah.
Menggunakan pola sidecar untuk saturasi server
Untuk memaksimalkan penggunaan akselerator, konfigurasikan Pod JobSet Anda dengan dua container menggunakan pola sidecar:
- Server inferensi: server yang dioptimalkan (seperti vLLM) yang sepenuhnya berfokus pada komputasi GPU atau TPU.
- Driver klien: container logika yang mengirim permintaan bervolume tinggi secara asinkron ke server di localhost.
Pemisahan ini membantu memastikan bahwa GPU atau TPU tetap sibuk dan tidak pernah menganggur saat menunggu I/O jaringan atau pra-pemrosesan data. Tanpa pendekatan ini, model yang memuat data secara berurutan dapat menyebabkan akselerator menunggu operasi I/O selesai, sehingga menyebabkan penggunaan yang kurang optimal. Misalnya, daripada menunggu data diproses, driver klien dapat melakukan pramuat data dan terus mengirim permintaan asinkron ke server inferensi, yang membantu memastikan antrean permintaan akselerator tetap jenuh.
Ringkasan checklist
| Kategori | Praktik terbaik |
|---|---|
| Pola arsitektur |
|
| Biaya dan throughput |
|
| Pengiriman pesan dan penskalaan |
|
| Orkestrasi |
|