
本文提供最佳做法,協助您在 Google Kubernetes Engine (GKE) 上執行批次推論工作負載。批次推論是指使用機器學習模型,對大型資料集生成預測結果的程序,優先考量高處理量和成本效益,而非即時的低延遲回應。
本指南會區分批次推論與要求批次處理 (或動態批次處理)。要求批次處理是 vLLM 或 SGLang 等引擎的伺服器端技術,可將並行的即時要求分組,盡量提升加速器效率。您可以將要求批次處理套用至批次推論工作負載。
本指南的最佳做法涵蓋兩種常見的批次推論模式:
- 非同步推論:在資料產生後不久,就會分批處理資料。這種做法的延遲時間通常為幾秒到幾分鐘,可兼顧對新資料的需求,以及同時處理多個項目的效率。非同步推論有時也稱為近乎即時推論。
- 批次推論:按排定的間隔 (例如每晚或每週) 處理大量累積資料。由於這類工作通常會在離峰時段排定,以盡可能提升資源可用性,因此延遲時間通常介於數小時到數天之間。
這些建議是專門的最佳化層,以在 GKE 上進行推論的最佳做法總覽為基礎建構而成。在針對批次工作負載進行最佳化之前,請務必遵循模型選取、量化和加速器選擇的核心最佳做法。
選擇批次推論處理的架構模式
選取正確的架構模式,是部署批次推論工作負載時最重要的決定,因為這會影響延遲時間、輸送量和成本之間的取捨。為維持效率,請確保在離峰時段,推論輸送量超過傳入查詢的速率,以免佇列無限增長。
針對突發工作使用非同步推論
非同步推論非常適合需要頻繁更新的用途,例如:
- 根據近期互動,每隔幾分鐘更新使用者推薦設定檔。
- 每隔一分鐘處理社群媒體提及內容,進行即時監控。
- 從高頻率金融資料串流中偵測市場變動信號。
- 對收到的顧客意見回饋或新聞動態執行情緒分析。
如果工作負載可容許幾秒到幾分鐘的延遲,請選擇這個模式。
實作非同步推論時,請考量下列特性:
- 延遲:從幾十秒到幾分鐘不等,視第一個權杖的產生時間而定。
- 資料來源:您通常會處理從 MB 到 GB 的資料集,例如 Pub/Sub 中的訊息,或在短時間內從 Cloud Storage 累積的檔案。
- 運算模式:基礎架構應支援持續性服務,處理頻繁的工作量爆增情況。
- 成本最佳化:這種模式可在低延遲的即時推論和高處理量的批次處理之間取得平衡。
對大型資料集執行批次推論
批次推論適合大規模的週期性工作,可容許數小時或數天的延遲,例如:
- 根據前一天的金融交易,每晚生成風險評估報告。
- 為整個目錄建立產品嵌入,以支援下游搜尋和推薦系統。
- 為大量圖片資料集加上標籤,用於模型訓練或封存分類。
如果您要處理大量資料,且可容忍數小時到數天的延遲時間,請選擇這個模式。
實作批次推論時,請考量下列特性:
- 延遲:工作負載啟動延遲通常介於幾分鐘到幾天,因為工作通常會在離峰時段排定。
- 資料來源:處理從 GB 到 PB 的大型資料集,通常儲存在 Cloud Storage 或 BigQuery 資料表中。
- 運算模式:您使用週期性、突發性工作,這些工作會初始化、處理資料,然後終止。
- 成本最佳化:這個模式非常適合採用按用量計費模式。由於批次工作完成時間彈性,建議使用 Spot VM 來降低成本。
提升輸送量和成本效益
批次推論工作負載非常適合用於可節省成本的基礎架構,即使作業中斷也沒關係。
使用 Spot VM 降低運算費用
使用 Spot VM 的折扣處理批次工作。由於批次推論工作負載通常可容許延遲和中斷,因此很適合使用 Spot 容量的優惠價格。
請確保批次推論程式碼會實作檢查點,以處理可能的搶占事件。如果系統先占 Spot VM,您可以建立新節點,並從上次處理的批次繼續執行工作負載,不必從頭開始。
調整工作負載批量和要求批量
為避免資源爭用和工作逾時,請確保傳送至引擎的項目數量 (工作負載批次) 至少與伺服器可處理的並行要求數量 (要求批次) 一樣多,以免加速器使用率不足。
調整工作負載批量
工作負載批量大小是指在單一工作單元中,傳送至推論引擎的項目總數。您可以在用戶端提交邏輯或 Kubernetes Job 設定中設定此項目,方法是將資料分片,或將多個項目分組到單一要求中。
如要判斷最佳工作負載批量大小,請使用下列界線:
- 計算最小批量:確保工作負載批量至少與要求批量相同。舉例來說,如果伺服器可同時處理 256 個項目,但您只傳送一個項目,就會造成資源嚴重閒置。如要找出最小大小,請檢查推論伺服器設定,例如 vLLM 中的
max_num_seqs引數。您可以設定用戶端邏輯,將多個項目分組為單一要求,也可以將資料分片,讓每個工作接收的資料量至少達到要求批量。 - 計算最大批量大小:確保工作負載批量大小允許 Pod 在達到 Kubernetes 工作中定義的
activeDeadlineSeconds逾時前完成。預估處理一個要求批次所需的時間,並設定工作負載大小,確保 Pod 能在期限內完成作業。舉例來說,如果您的activeDeadlineSeconds為 3,600 秒,啟動額外負荷為 600 秒,請確保最長執行時間允許 Pod 在 3,000 秒內完成。
如果工作負載批量過小,工作會浪費時間在 Pod 啟動負擔 (下載權重、佈建、初始化加速器);如果過大,工作可能會因 activeDeadlineSeconds 逾時而遭 GKE 終止,導致工作失敗並失去進度。
調整要求批量大小
要求批量大小是指推論伺服器在加速器上同時處理的要求數量。如要最佳化這個參數,請在推論伺服器設定中調整伺服器專屬的旗標 (例如 vLLM 的 --max-num-seqs 旗標)。
目標是盡量提高 GPU 使用率,同時避免觸發記憶體不足 (OOM) 錯誤。如果要求批量大小未經過校正,系統會無法充分運用加速器,或導致模型伺服器當機。如果是 vLLM,您可以使用 vLLM auto_tune 指令碼等工具,找出特定硬體的 max_num_seqs 和 max_num_batched_tokens 設定最佳值。詳情請參閱「GKE 推論最佳做法總覽」指南中的「最佳化推論伺服器的設定」。
為非同步推論實作非同步元件
如果是非同步推論,建議使用訊息緩衝區,將擷取層與推論層分離。
下圖為非同步推論平台範例架構圖。這個架構可保護推論伺服器免於流量尖峰影響、管理工作積壓,並確保加速器的高使用率。
這張圖表顯示從 Pub/Sub 到訂閱者、推論閘道和推論伺服器的流程,結果會保留在 AlloyDB 中,失敗的訊息則會傳送至死信主題。
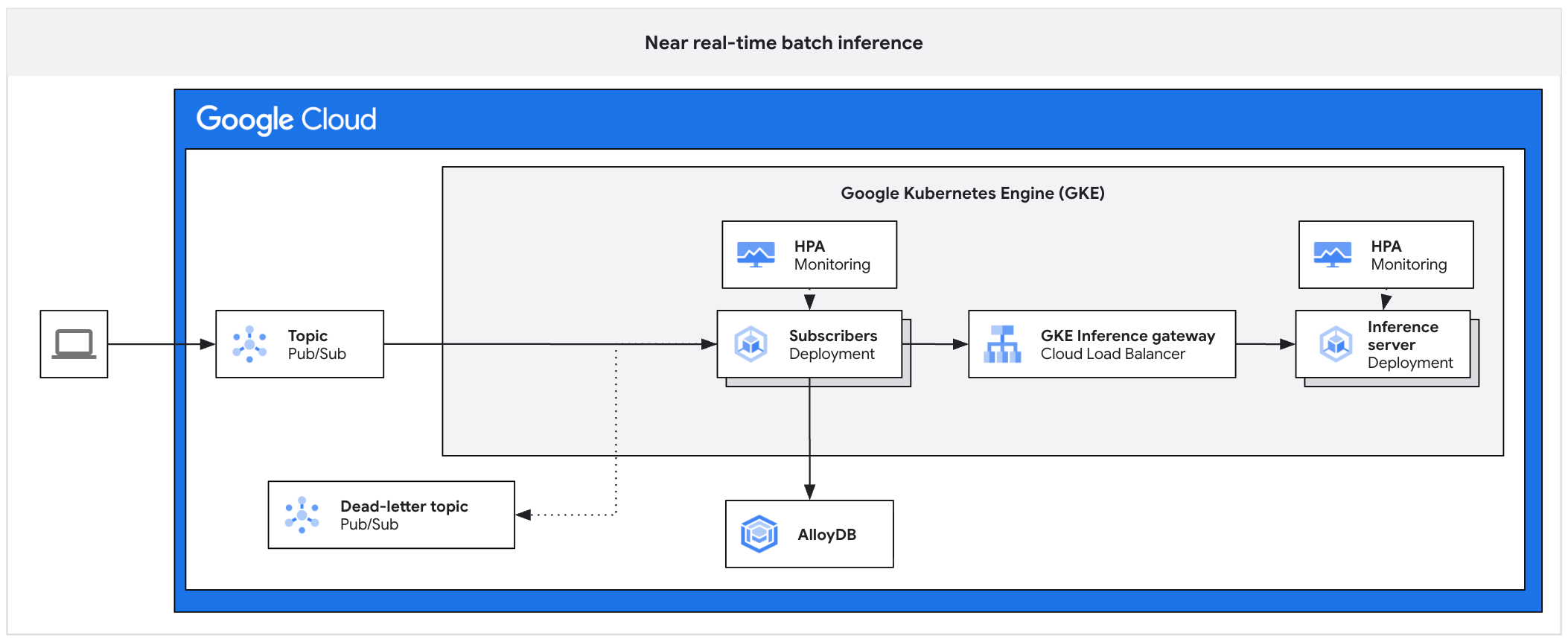
此架構包含下列元件:
- Pub/Sub 主題:做為傳入用戶端訊息的持續緩衝區,保留期限為 7 到 31 天。
- 訂閱者:讀取訊息批次、向推論伺服器傳送要求,並確認處理作業的元件。
- 訂閱者 HPA:根據
num_undelivered_messages指標 (未確認的訊息數量) 調整訂閱者部署的資源配置。 - 儲存空間:使用資料庫 (例如 AlloyDB) 或物件儲存空間 (例如 Cloud Storage) 持續保存推論結果。
- Inference Gateway:向訂閱者公開推論工作負載。
- 推論伺服器:處理批次推論要求 (例如 vLLM)。
- 伺服器 HPA:根據引擎專屬指標 (例如
vllm:num_requests_waiting) 調度推論引擎。 - dead-letter 主題:擷取在經過設定次數的指數輪詢重試後,處理失敗的訊息。
詳情請參閱 GitHub 上的參考實作。
緩衝處理及匯總要求
如要管理要求流程,請按照下列步驟操作:
- 使用 Pub/Sub 做為持久緩衝區:實作 Pub/Sub,以持久儲存推論要求。這項設定會做為 FIFO 緩衝區,保留要求,直到消費者有處理要求的能力為止,避免在流量暴增期間發生伺服器過載的情況。
- 搭配用戶端流量控制使用提取訂閱:設定 Pull 訂閱模型。這樣一來,訂閱端應用程式就能在有能力處理訊息時,明確要求訊息,讓您完全掌控取用率。
- 匯總訊息,填滿伺服器批量:避免將一則 Pub/Sub 訊息做為一個推論要求傳送。訂閱者應將多個訊息綁定至單一的批次要求,並配合推論伺服器的最佳批量 (例如,比照 vLLM 中的
max_num_seqs設定)。這個做法可確保加速器完全飽和,並盡量提高輸送量。具體來說,請將訂閱者的max_messages提取設定設為max_num_seqs的倍數,確保每個模型轉送傳遞都完全飽和。
自動調度訂閱者和伺服器資源
如要有效進行批次推論,必須以不同方式擴充訂閱者 (受 CPU 限制),以及推論伺服器 (受 GPU 或 TPU 限制)。
根據工作待處理事項調整訂閱者數量:根據 Pub/Sub 的
num_undelivered_messages指標,為訂閱者部署設定 HorizontalPodAutoscaler (HPA)。詳情請參閱「根據指標最佳化 Pod 自動調度資源功能」。使用下列方程式計算要使用的副本數:\[ desiredReplicas = \frac{num\_undelivered\_messages}{target\_latency\_seconds \times throughput\_per\_replica} \]
遵守基礎架構配額:在 HPA 中設定
maxReplicas設定,明確限制訂閱者的副本數量上限。請勿將訂閱者人數擴展至超出推論伺服器 GPU 或 TPU 配額可支援的範圍。過度佈建訂閱端會將瓶頸轉移至推論伺服器,增加資源爭用,但不會提高處理量。根據引擎指標調整推論伺服器:根據推論引擎直接匯出的指標 (不只是 CPU/記憶體),調整推論伺服器部署作業的資源配置。舉例來說,您可以為 vLLM 使用
vllm:num_requests_waiting設定,直接測量模型伺服器層級的處理積壓工作。詳情請參閱「自動調度 Pod 資源」。
處理錯誤和逾時
如要處理錯誤和逾時,請執行下列操作:
- 主動延長確認期限:設定訂閱者主動延長處理中訊息的 Pub/Sub 確認期限,避免重新傳送迴圈和重複處理。這是必要做法,因為推論工作通常會超過預設逾時時間範圍。一般來說,延長時間應長於最差情況下的批次推論時間。
- 使用 dead-letter 主題隔離失敗訊息:啟用 dead-letter 主題,自動隔離重複傳送失敗的格式錯誤訊息。這種做法可防止「毒丸」訊息阻塞佇列,導致整個管道停止運作。
- 實作輪詢策略:如果推論伺服器傳回
429(要求過多) 或503(服務無法使用) 錯誤,訂閱者必須擷取這些錯誤,並實作指數輪詢策略,暫時停止從 Pub/Sub 服務取用資料,直到伺服器恢復運作。
大規模自動調度管理批次工作
處理大量資料集時,請遵循下列最佳做法,盡可能提高處理量、確保成本效益、全面實作稽核追蹤功能,以及套用進階配額管理和工作優先順序設定。
使用 JobSet 進行多節點分散式推論
建議您使用 Kubernetes JobSet 資源,協調需要多個節點合作的分散式推論工作負載,例如在 TPU Pod 或多節點 GPU 叢集上執行的大型模型。標準 Kubernetes Job 無法保證所有必要 Pod 同時啟動,這可能會導致分散式工作負載發生死結。
JobSet 是 Kubernetes 原生 API,可將工作群組視為單一單元進行管理,並為批次推論提供下列優點:
- 叢集調度:確保在啟動工作負載前,所有必要資源 (例如 TPU 節點或 GPU 節點) 皆可使用,避免發生死結。
- 專屬放置位置:確保單一 JobSet 專屬存取網路拓撲 (例如 TPU 配量),盡可能提升互連效能。
- 失敗復原:如果 worker 失敗,您可以根據設定重新啟動特定複製工作或整組工作。
使用已建立索引的工作進行資料分片
使用 JobSet 時,請將 ReplicatedJob 設為使用 completionMode:
Indexed 設定。這項設定會自動將 JOB_COMPLETION_INDEX 環境變數注入每個 Pod。推論程式碼可以使用這個索引,確定要選取哪個資料分片進行處理。
舉例來說,如果您有一個包含 100,000 張圖片的 Cloud Storage 儲存空間,並部署平行度為 10 的 JobSet,則每個 Pod 在啟動時都會讀取其索引 (0-9)。Pod 0 接著會計算出應處理的圖片為 0 到 9,999,而 Pod 1 則處理 10,000 到 19,999。這種方法可減少對獨立工作佇列服務的需求。
使用補充資訊模式避免伺服器飽和
如要盡量提高加速器使用率,請使用 Sidecar 模式,透過兩個容器設定 JobSet Pod:
- 推論伺服器:經過最佳化的伺服器 (例如 vLLM),完全專注於 GPU 或 TPU 運算。
- 用戶端驅動程式:邏輯容器,會非同步將大量要求傳送至本機主機上的伺服器。
這種解耦方式可確保 GPU 或 TPU 保持忙碌,不會在等待網路 I/O 或資料預先處理時閒置。如果沒有這種做法,模型依序載入資料可能會導致加速器等待 I/O 作業完成,進而導致資源使用率不足。舉例來說,用戶端驅動程式可以預先擷取資料,並持續將非同步要求傳送至推論伺服器,而不必等待資料處理完畢,這有助於確保加速器的要求佇列保持飽和。
檢查清單摘要
| 類別 | 最佳做法 |
|---|---|
| 架構模式 | |
| 費用和處理量 |
|
| 訊息傳輸與擴充 |
|
| 自動化調度管理 |
|