

In genere, le aziende gestiscono le identità (utenti e gruppi di utenti) utilizzando un provider di identità (IDP). Tuttavia, le applicazioni personalizzate che un'azienda ha creato internamente possono consentire ai clienti di creare nuovi gruppi di utenti definiti localmente all'interno dell'applicazione. Questi gruppi di utenti specifici dell'applicazione o ID utente secondari sono chiamati identità esterne.
Perché configurare la mappatura delle identità?
Per assicurarti che Google possa applicare correttamente il controllo dell'accesso, mappa le identità IDP a tutte le identità esterne delle applicazioni personalizzate che prevedi di utilizzare con Gemini Enterprise.
Per applicare il controllo dell'accesso ai risultati delle app, Google utilizza l'IDP come fonte di riferimento per determinare a quali dati hanno accesso i tuoi utenti. Spesso le aziende collegano il proprio IDP ad altre soluzioni SaaS in modo che un dipendente possa utilizzare un unico set di credenziali aziendali per accedere a tutte le risorse aziendali.
Se hai identità esterne definite tramite applicazioni che prevedi di connettere alla tua app, ad esempio applicazioni personalizzate, l'IDP non è l'unica fonte di riferimento per il controllo dell'accesso.
Ad esempio, supponiamo che "JaneDoe" esista all'interno dell'organizzazione di esempio, con il dominio "example.com". L'ID nell'IDP è definito come "JaneDoe@example.com". Lo stesso utente ha un ID separato all'interno di un'applicazione personalizzata come "JDoe". L'IDP potrebbe non essere a conoscenza di questo ID. Per questo motivo, Gemini Enterprise non riceve informazioni sugli ID delle applicazioni personalizzate tramite l'IDP.
In Gemini Enterprise, le mappature delle identità vengono archiviate in un archivio di mappatura delle identità che crei e in cui importi le mappature. Se prevedi di utilizzare un connettore personalizzato, puoi associare l'archivio di mappatura delle identità al datastore del connettore personalizzato e poi aggiornare i metadati ACL del datastore con informazioni sulle tue identità esterne.
Prima di iniziare
Prima di configurare la mappatura delle identità, collega il provider di identità al tuo Google Cloud progetto.
Prepara le voci di mappatura delle identità
Prepara le voci di mappatura delle identità per l'importazione. Le mappature delle identità devono essere formattate come nell'esempio seguente:
{
"identity_mapping_entries": [
{
"external_identity": "u1",
"user_id": "user1@example.com"
},
{
"external_identity": "u2",
"user_id": "user2@example.com"
},
{
"external_identity": "gABC",
"group_id": "groupABC@example.com"
}
]
}
Ad esempio, il seguente grafico rappresenta un esempio di appartenenza a un gruppo di utenti, dove Ext rappresenta i gruppi esterni. Questo grafico mostra un esempio di relazione tra gruppi esterni e utenti e gruppi IDP.
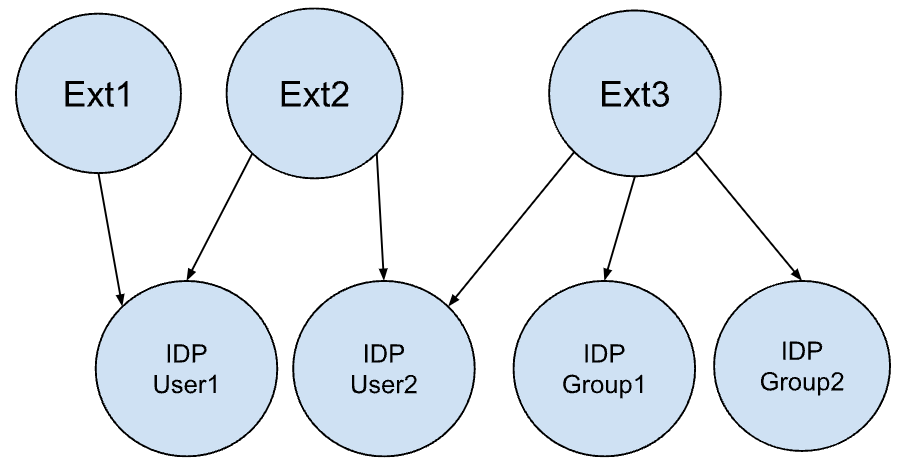
Questo grafico di appartenenza a un gruppo di utenti avrà la seguente mappatura:
{
"identity_mapping_entries": [
{
"external_identity": "Ext1",
"user_id": "IDPUser1@example.com"
},
{
"external_identity": "Ext2",
"user_id": "IDPUser1@example.com"
},
{
"external_identity": "Ext2",
"user_id": "IDPUser2@example.com"
},
{
"external_identity": "Ext3",
"user_id": "IDPUser2@example.com"
},
{
"external_identity": "Ext3",
"group_id": "IDPGroup1@example.com"
},
{
"external_identity": "Ext3",
"group_id": "IDPGroup2@example.com"
}
]
}
Le appartenenze a identità nidificate, in cui le identità esterne hanno identità secondarie, devono essere appiattite.
Google presuppone che il connettore invii un ID principale per un'identità esterna. Ad esempio, importa l'ID del gruppo anziché il nome del gruppo, perché il nome potrebbe essere modificato durante la durata del gruppo all'interno dell'applicazione personalizzata.
Configura la mappatura delle identità
Utilizza le seguenti procedure per configurare la mappatura delle identità in Gemini Enterprise tra l'IDP e le identità esterne. Nei passaggi seguenti, creerai un archivio di mappatura delle identità e importerai le mappature delle identità che hai preparato. Se prevedi di utilizzare un connettore personalizzato, creerai anche un nuovo datastore associato all'archivio di mappatura delle identità.
Crea un archivio di mappatura delle identità
Il primo passaggio consiste nel configurare un archivio di mappatura delle identità. Questa è la risorsa principale in cui vengono archiviate tutte le mappature delle identità.
Quando crei l'archivio di mappatura delle identità, recupera automaticamente la configurazione IDP dall'IDP che hai collegato al tuo progetto Gemini Enterprise.
Per creare un archivio di mappatura delle identità, esegui il seguente comando utilizzando il
identityMappingStores.createmetodo:curl -X POST \ -H "Authorization: Bearer $(gcloud auth application-default print-access-token)" \ -H "Content-Type: application/json" \ -H "X-Goog-User-Project: PROJECT_ID" \ "https://discoveryengine.googleapis.com/v1/projects/PROJECT_ID/locations/global/identityMappingStores?identityMappingStoreId=IDENTITY_MAPPING_STORE_ID" \ -d '{ "name": "projects/PROJECT_ID/locations/global/identityMappingStores/IDENTITY_MAPPING_STORE_ID" }'Sostituisci quanto segue:
PROJECT_ID: l'ID progetto.IDENTITY_MAPPING_STORE_ID: l'ID univoco dell' archivio di mappatura delle identità. Ad esempio,test-id-mapping-store.
Importa le mappature delle identità
Dopo aver creato l'archivio di mappatura delle identità, importa le voci di mappatura delle identità che hai preparato. Puoi importare le mappature delle identità utilizzando un'origine in linea (opzione 1) o da Cloud Storage (opzione 2).
Quando importi da Cloud Storage, si applicano i seguenti formati e vincoli:
- Formati consentiti: i file di input devono essere in formato NDJSON (
.ndjson) o JSON Lines (.jsonl), con ogni riga che rappresenta una singola voce di mappatura delle identità. - Vincoli relativi alle dimensioni dei file: ogni file non deve superare i 2 GB.
- Vincoli relativi al numero di mappature delle identità: puoi importare fino a
500,000mappature delle identità esterne in un'operazione di importazione. - Vincoli relativi al numero di file: puoi specificare fino a
2,000file nell'elencoinputUris. Se utilizzi i caratteri jolly, il limite si applica al numero totale di file dopo l'espansione dei caratteri jolly.
Opzione 1: importa utilizzando l'origine in linea
Per importare le mappature delle identità utilizzando un'origine in linea, esegui il seguente comando utilizzando il
importIdentityMappingsmetodo:curl -X POST \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" -H "x-goog-user-project: PROJECT_ID" \ "https://ENDPOINT_LOCATION-discoveryengine.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/identityMappingStores/IDENTITY_MAPPING_STORE_ID:importIdentityMappings" \ -d '{"inline_source" : IDENTITY_MAPPINGS_JSON}'Sostituisci quanto segue:
PROJECT_ID: l'ID progetto.ENDPOINT_LOCATION: la multi-regione per la richiesta API. Specifica uno dei seguenti valori:usper la multi-regione Stati Unitieuper la multi-regione EUglobalper la località globale
LOCATION: la multi-regione del datastore:global,usoeuIDENTITY_MAPPING_STORE_ID: l'ID univoco dell'archivio di mappatura delle identità.IDENTITY_MAPPINGS_JSON: le mappature delle identità preparate in formato JSON.
Se prevedi di creare un connettore personalizzato e utilizzare identità esterne, vai a Associare datastore personalizzati all'archivio di mappatura delle identità. In caso contrario, vai a Aggiorna i metadati ACL.
Opzione 2: importa da Cloud Storage
Per importare le mappature delle identità da Cloud Storage, esegui il seguente comando utilizzando il
importIdentityMappingsmetodo:curl -X POST \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" -H "x-goog-user-project: PROJECT_ID" \ "https://ENDPOINT_LOCATION-discoveryengine.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/identityMappingStores/IDENTITY_MAPPING_STORE_ID:importIdentityMappings" \ -d '{ "gcsSource": { "inputUris": ["gs://BUCKET_NAME/FILE_PATH"] }, "errorConfig": { "gcsPrefix": "gs://BUCKET_NAME/ERROR_DIR" }, "reconciliationMode": "FULL" }'Sostituisci quanto segue:
PROJECT_ID: l'ID progetto.ENDPOINT_LOCATION: la multi-regione per la richiesta API. Specifica uno dei seguenti valori:usper la multi-regione Stati Unitieuper la multi-regione EUglobalper la località globale
LOCATION: la multi-regione del datastore:global,usoeuIDENTITY_MAPPING_STORE_ID: l'ID univoco dell'archivio di mappatura delle identità.BUCKET_NAME: il nome del bucket Cloud Storage.FILE_PATH: il percorso del file di mappatura delle identità in Cloud Storage.ERROR_DIR: la directory in Cloud Storage in cui verranno archiviati i log degli errori.
Se prevedi di creare un connettore personalizzato e utilizzare identità esterne, vai a Associare datastore personalizzati all'archivio di mappatura delle identità. In caso contrario, vai a Aggiorna i metadati ACL.
Associa datastore personalizzati all'archivio di mappatura delle identità
Questa procedura è necessaria solo se crei un connettore personalizzato. Se non stai creando un connettore personalizzato, salta questo passaggio.
Per i connettori personalizzati, l'archivio di mappatura delle identità deve essere associato al datastore prima che un'identità esterna possa essere associata ai relativi documenti. L'impostazione di questo campo è consentita solo durante la creazione del datastore.
Per associare un datastore all'archivio di mappatura delle identità, specifica
identity_mapping_storedurante la creazione del datastore utilizzando ilDatastores.createmetodo.curl -X POST \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ -H "X-Goog-User-Project: PROJECT_ID" \ "https://discoveryengine.googleapis.com/v1/projects/PROJECT_ID/locations/global/collections/default_collection/dataStores?dataStoreId=DATA_STORE_ID \ -d '{ ... "identity_mapping_store": "IDENTITY_MAPPING_STORE_NAME" }'Sostituisci quanto segue:
PROJECT_ID: l'ID progetto.DATA_STORE_ID: l'ID del datastore che vuoi creare. Questo ID può contenere solo lettere minuscole, cifre, trattini bassi e trattini.IDENTITY_MAPPING_STORE_NAME: il nome completo della risorsa dell'archivio di mappatura delle identità. Ad esempio,projects/exampleproject/locations/global/identityMappingStores/test-id-mapping-store. Dopo aver creato un datastore, questo nome non può essere aggiornato.
Aggiungi metadati ACL
Includi i metadati ACL nell'oggetto AclInfo per i tuoi documenti.
Quando un utente invia una richiesta di ricerca e vengono recuperati i documenti i cui metadati ACL includono identità esterne, queste identità esterne vengono valutate.
Se l'identità dell'utente (groupID o userID) è mappata a un'identità esterna (externalEntityId) associata a un documento, l'utente ottiene l'accesso a quel documento.
Ad esempio, supponiamo che tu abbia creato un connettore personalizzato per Jira. Un determinato problema di Jira è accessibile a determinati utenti IDP, a determinati gruppi IDP e a un ruolo di amministratore. Per consentire a queste persone di accedere al problema nei risultati di ricerca, puoi creare un archivio di mappatura delle identità e mappare gli utenti e i gruppi IDP a identità esterne specifiche di Jira. Associa l'archivio di mappatura delle identità al datastore Jira. Poi, crea documenti nei datastore Jira con aclInfo configurato con gli utenti IDP, i gruppi IDP e le identità esterne che devono avere accesso a questi documenti.
Per aggiornare i metadati ACL con informazioni sulle tue identità esterne, utilizza il seguente formato per specificare le identità esterne e gli ID utente e gruppo associati.
{
"aclInfo": {
"readers": [
{
"principals": [
{
"groupId": "group_1"
},
{
"userId": "user_1"
},
{
"externalEntityId": "external_id1"
}
]
}
]
}
}
Per saperne di più sull'aggiornamento dei metadati ACL, consulta Configurare un'origine dati con il controllo dell'accesso.
Gestisci le mappature delle identità
Puoi elencare le mappature delle identità in un archivio di identità oppure puoi eliminare un archivio di identità definendole tramite un'origine in linea o utilizzando una condizione di filtro.
Le attività di gestione disponibili per la mappatura delle identità sono:
- Elenca le mappature delle identità
- Elimina utilizzando l'origine in linea
- Elimina utilizzando una condizione di filtro
Elenca le mappature delle identità
Per elencare le mappature delle identità, esegui il seguente comando utilizzando il
listIdentityMappingsmetodo:curl -X GET \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ -H "x-goog-user-project: PROJECT_ID" \ "https://discoveryengine.googleapis.com/v1/projects/PROJECT_ID/locations/global/identityMappingStores/IDENTITY_MAPPING_STORE_ID:listIdentityMappings?page_size=PAGE_SIZE&page_token=PAGE_TOKEN"Sostituisci quanto segue:
PROJECT_ID: l'ID progetto.PAGE_SIZE: il numero massimo di archivi di mappatura delle identità da restituire. Se non specificato, il valore predefinito è 100. Il valore massimo consentito è 1000. I valori superiori a 1000 verranno forzati a 1000.PAGE_TOKEN: un token di pagina, ricevuto da una chiamataListIdentityMappingStoresprecedente. Fornisci questo valore per recuperare la pagina successiva.
Elimina utilizzando l'origine in linea
Puoi eliminare definitivamente le voci specificate da un datastore di mappatura delle identità fornendo un file JSON delle identità da eliminare definitivamente.
Per eliminare le mappature delle identità utilizzando l'origine in linea, esegui il seguente comando utilizzando il
purgeIdentityMappingsmetodo:curl -X POST \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ -H "x-goog-user-project: PROJECT_ID" \ "https://discoveryengine.googleapis.com/v1/projects/PROJECT_ID/locations/global/identityMappingStores/IDENTITY_MAPPING_STORE_ID:purgeIdentityMappings" \ -d '{"inline_source" : IDENTITY_MAPPINGS_JSON}'Sostituisci quanto segue:
PROJECT_ID: l'ID progetto.IDENTITY_MAPPING_STORE_ID: l'ID univoco dell'archivio di mappatura delle identità.IDENTITY_MAPPING_STORE_NAME: il nome dell'archivio di mappatura delle identità.IDENTITY_MAPPINGS_JSON: le mappature delle identità da eliminare.
Elimina utilizzando una condizione di filtro
Puoi eliminare le voci specificate da un archivio di mappatura delle identità filtrando le voci in base all'ora di aggiornamento, all'identità esterna o a tutte le voci.
Per eliminare le mappature delle identità utilizzando una condizione di filtro, esegui il seguente comando utilizzando il
purgeIdentityMappingsmetodo:curl -X POST \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ -H "x-goog-user-project: PROJECT_ID" \ "https://discoveryengine.googleapis.com/v1/projects/PROJECT_ID/locations/global/identityMappingStores/IDENTITY_MAPPING_STORE_ID:purgeIdentityMappings" \ -d '{"identity_mapping_store":"IDENTITY_MAPPING_STORE_NAME", "filter": "FILTER_CONDITION"}'Sostituisci quanto segue:
PROJECT_ID: l'ID progetto.IDENTITY_MAPPING_STORE_ID: l'ID univoco dell'archivio di mappatura delle identità.IDENTITY_MAPPING_STORE_NAME: il nome dell'archivio di mappatura delle identità.FILTER_CONDITION: uno dei seguenti tipi di filtro:- Ora di aggiornamento. Ad esempio,
update_time > "2012-04-23T18:25:43.511Z" AND update_time < "2012-04-23T18:30:43.511Z"> - Identità esterna. Ad esempio,
external_id = "id1" - Tutte le mappature delle identità. Ad esempio,
*
Gestisci gli archivi di mappatura delle identità
Puoi recuperare, eliminare, elencare ed eliminare gli archivi di mappatura delle identità.
Recupera l'archivio di mappatura delle identità
Per recuperare un archivio di mappatura delle identità, esegui il seguente comando utilizzando il
identityMappingStores.getmetodo:curl -X GET \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ -H "X-Goog-User-Project: PROJECT_ID" \ "https://discoveryengine.googleapis.com/v1/projects/PROJECT_ID/locations/global/identityMappingStores/IDENTITY_MAPPING_STORE_ID"Sostituisci quanto segue:
PROJECT_ID: l'ID progetto.IDENTITY_MAPPING_STORE_ID: l'ID univoco dell'archivio di mappatura delle identità.IDENTITY_MAPPING_STORE_NAME: il nome dell'archivio di mappatura delle identità.
Elenca gli archivi di mappatura delle identità
Per elencare gli archivi di mappatura delle identità, esegui il seguente comando utilizzando il
identityMappingStores.listmetodo:curl -X GET \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ -H "x-goog-user-project: PROJECT_ID" \ "https://discoveryengine.googleapis.com/v1/projects/PROJECT_ID/locations/global/identityMappingStores?page_size=PAGE_SIZE&page_token=PAGE_TOKEN"Sostituisci quanto segue:
PROJECT_ID: l'ID progetto.PAGE_SIZE: il numero massimo di archivi di mappatura delle identità da restituire. Se non specificato, il valore predefinito è 100. Il valore massimo consentito è 1000. I valori superiori a 1000 verranno forzati a 1000.PAGE_TOKEN: un token di pagina, ricevuto da una chiamataListIdentityMappingStoresprecedente. Fornisci questo valore per recuperare la pagina successiva.
Elimina gli archivi di mappatura delle identità
Per eliminare un archivio di mappatura delle identità, non deve essere associato a un datastore e non devono essere presenti mappature delle identità nell'archivio di mappatura delle identità.
Per eliminare un archivio di mappatura delle identità, esegui il seguente comando utilizzando il
identityMappingStores.deletemetodo:curl -X DELETE \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ -H "X-Goog-User-Project: PROJECT_ID" \ "https://discoveryengine.googleapis.com/v1/projects/PROJECT_ID/locations/global/identityMappingStores/IDENTITY_MAPPING_STORE_ID"Sostituisci quanto segue:
PROJECT_ID: l'ID progetto.IDENTITY_MAPPING_STORE_ID: l'ID univoco dell'archivio di mappatura delle identità.IDENTITY_MAPPING_STORE_NAME: il nome dell'archivio di mappatura delle identità.