
瞭解 Firestore 中的效能監控
Cloud Monitoring 會收集 Google Cloud 產品的指標、事件和中繼資料。您也可以透過 Cloud Monitoring 存取用量資訊主頁和安全規則用量中回報的資料,進行更詳細的分析。您也可以使用 Cloud Monitoring 設定自訂資訊主頁和用量快訊。
本文將引導您使用指標、瞭解自訂指標資訊主頁,以及設定快訊。
受監控資源
Cloud Monitoring 中的受監控資源代表邏輯或實體實體,例如虛擬機器、資料庫或應用程式。受監控的資源包含一組獨特的指標,可用於探索、透過資訊主頁回報,或用來建立快訊。每項資源也有一組資源標籤,這些鍵/值組合會保存資源的其他資訊。資源標籤適用於與資源相關聯的所有指標。
使用 Cloud Monitoring API,透過下列資源監控 Firestore 效能:
| 資源 | 說明 | 支援的資料庫模式 |
firestore.googleapis.com/Database (建議) | 受控資源類型,可提供 project、location* 和 database_id 的明細。如果建立資料庫時未指定名稱,系統會使用「資料庫」標籤。(default)database_id |
這兩種模式都適用。 |
firestore_instance | Firestore 專案的受監控資源類型,不提供資料庫的細目。 | 適用於原生模式的 Firestore |
datastore_request | Datastore 專案的監控資源類型,不會提供資料庫的細目。 | 這兩種模式都適用。 |
指標
Firestore 提供兩種不同模式:原生模式的 Firestore 和 Datastore 模式的 Firestore。如要比較這兩種模式的功能,請參閱選擇資料庫模式。
如需兩種模式的完整指標清單,請參閱下列連結:
服務執行階段指標
serviceruntime 指標會顯示專案流量的概略總覽。大多數 Google Cloud API 都提供這些指標。consumed_api 受監控的資源類型包含這些常見指標。這些指標每 30 分鐘取樣一次,因此資料會經過平滑處理。
serviceruntime 指標的重要資源標籤是 method。這個標籤代表呼叫的基礎 RPC 方法。您呼叫的 SDK 方法名稱不一定與基礎 RPC 方法相同。這是因為 SDK 提供高階 API 抽象層級。不過,如要瞭解應用程式與 Firestore 的互動方式,請務必根據 RPC 方法名稱瞭解指標。
如要瞭解特定 SDK 方法的基礎 RPC 方法,請參閱 API 說明文件。
請使用下列服務執行階段指標監控資料庫。
api/request_count
這項指標會提供已完成的要求數量,並依通訊協定(要求通訊協定,例如 http、gRPC 等)、回應代碼 (HTTP 回應代碼)、response_code_class (回應代碼類別,例如 2xx、4xx 等) 和 grpc_status_code (數值 gRPC 回應代碼) 分組。使用這項指標觀察整體 API 要求,並計算錯誤率。
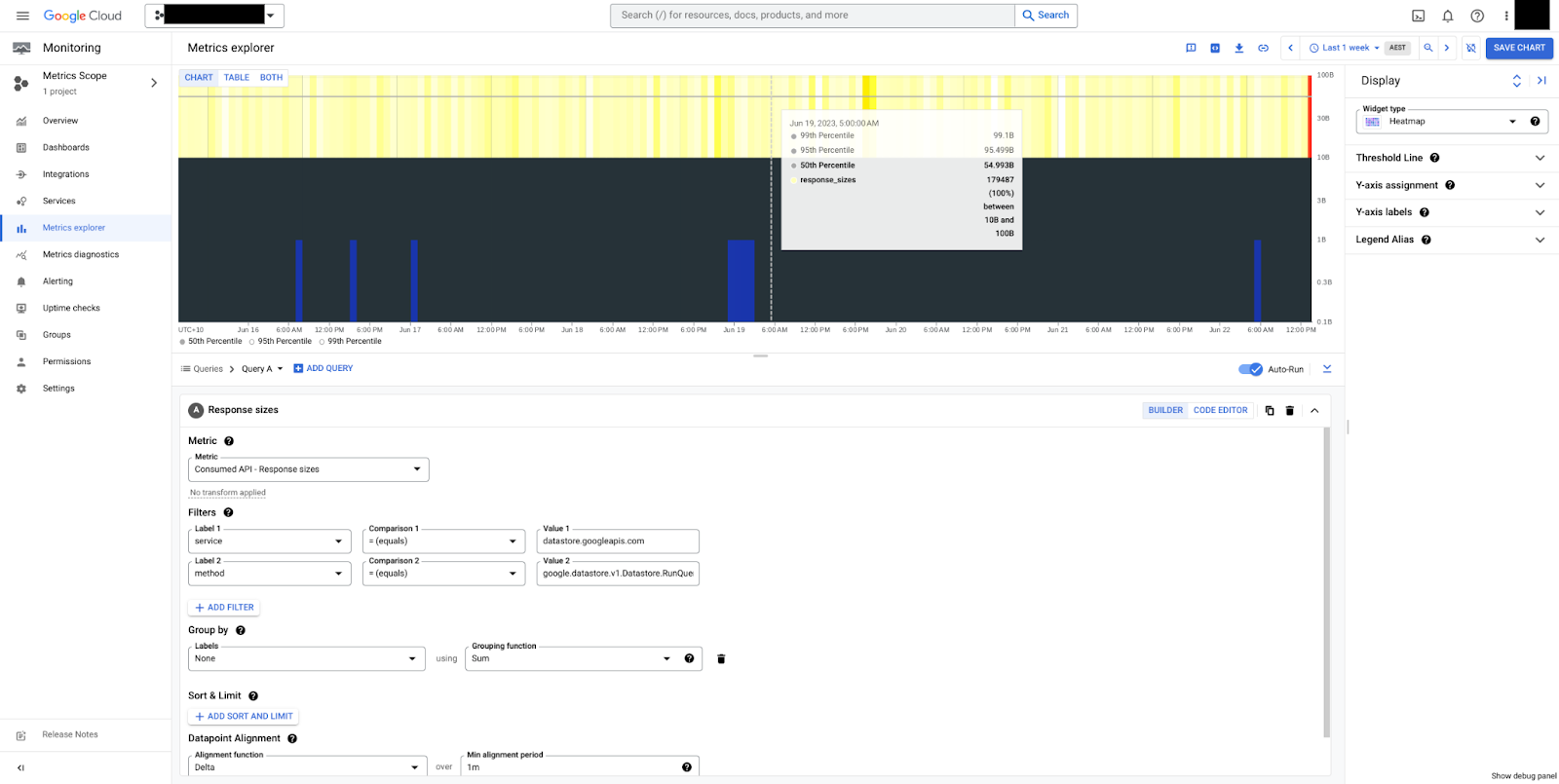
如圖 1 所示,傳回 2xx 代碼的要求會依服務和方法分組。2xx 代碼是 HTTP 狀態碼,表示要求成功。

圖 2 顯示依 response_code 分組的提交。在本範例中,我們只會看到 HTTP 200 回應,這表示資料庫運作正常。
api/request_latencies
api/request_latencies 指標會提供所有已完成要求的延遲分布情形。
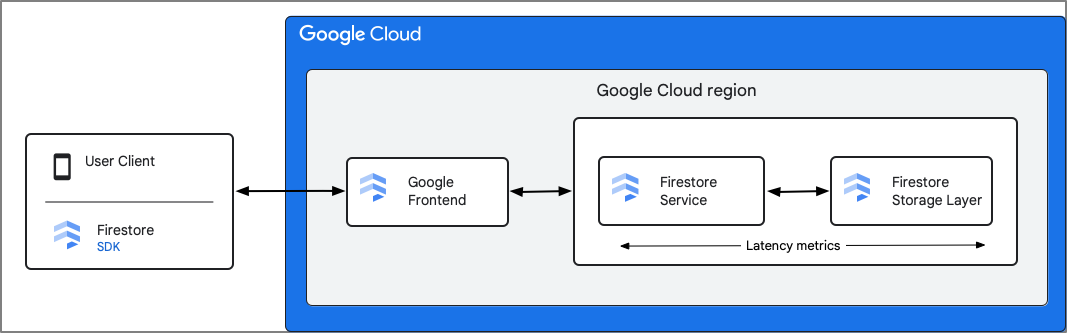
Firestore 會記錄 Firestore 服務元件的指標。延遲時間指標包括 Firestore 收到要求到完成傳送回應的時間,包括與儲存層的互動。因此,這些指標不包含用戶端與 Firestore 服務之間的封包往返延遲時間 (rtt)。
api/request_sizes 和 api/response_sizes
api/request_sizes 和 api/response_sizes 指標分別提供酬載大小 (以位元組為單位) 的深入分析資訊。這類資訊有助於瞭解傳送大量資料的寫入工作負載,或範圍過於廣泛而傳回大量酬載的查詢。
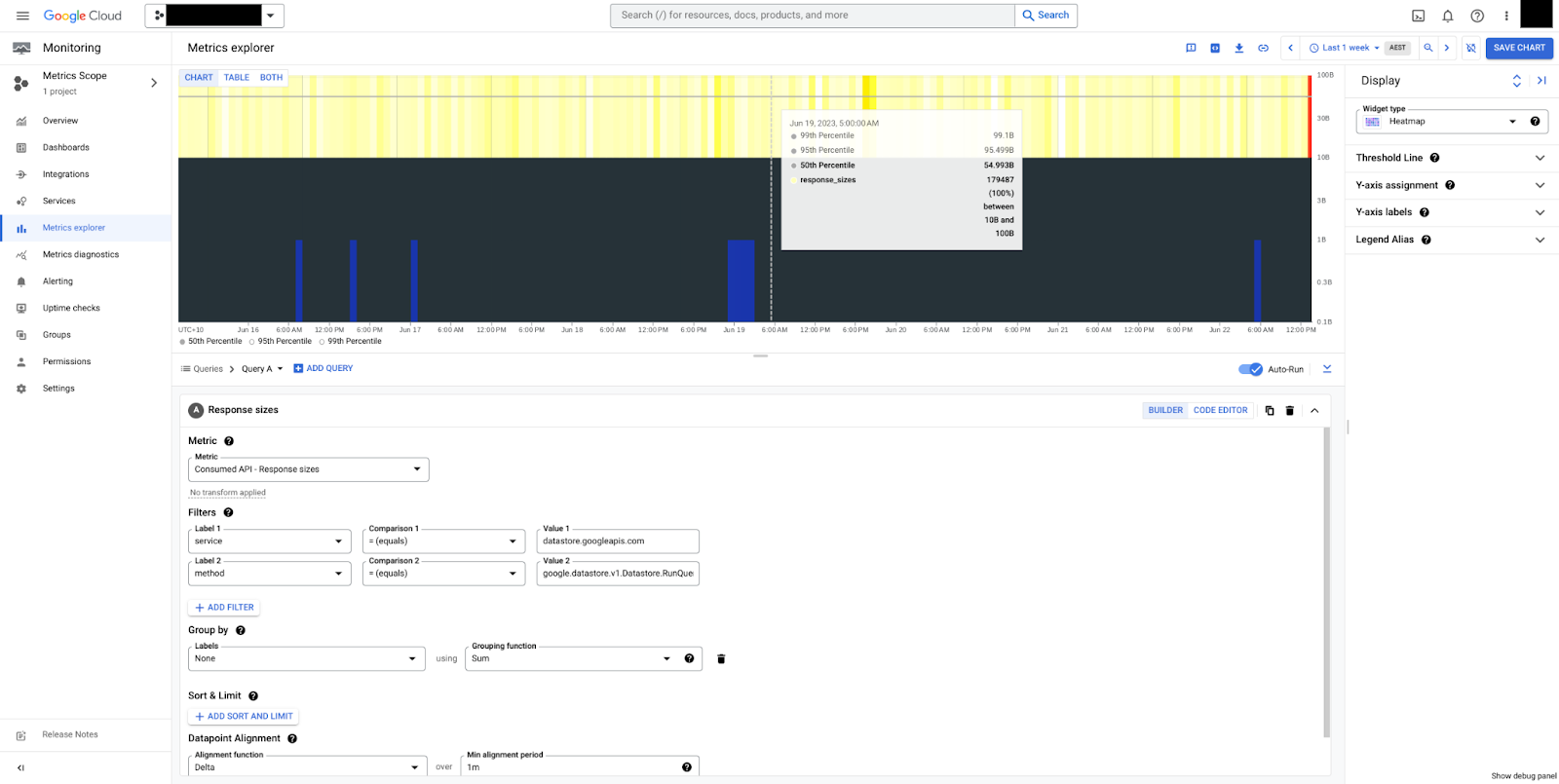
圖 5 顯示 RunQuery 方法的回應大小熱視圖。我們可以發現大小穩定,中位數為 50 個位元組,整體介於 10 個位元組和 100 個位元組之間。請注意,酬載大小一律以未壓縮的位元組為單位計算,不含傳輸控制項的額外負荷。
文件作業指標
Firestore 會提供讀取、寫入和刪除次數。寫入指標會細分「CREATE」和「UPDATE」作業。這些指標與 CRUD 作業一致。
您可以使用下列指標,瞭解資料庫是讀取密集還是寫入密集,以及新文件與已刪除文件的比率。
document/delete_ops_count:成功刪除的文件數量。document/read_ops_count:從查詢或查閱成功讀取文件的次數。document/write_ops_count:成功寫入文件的次數。
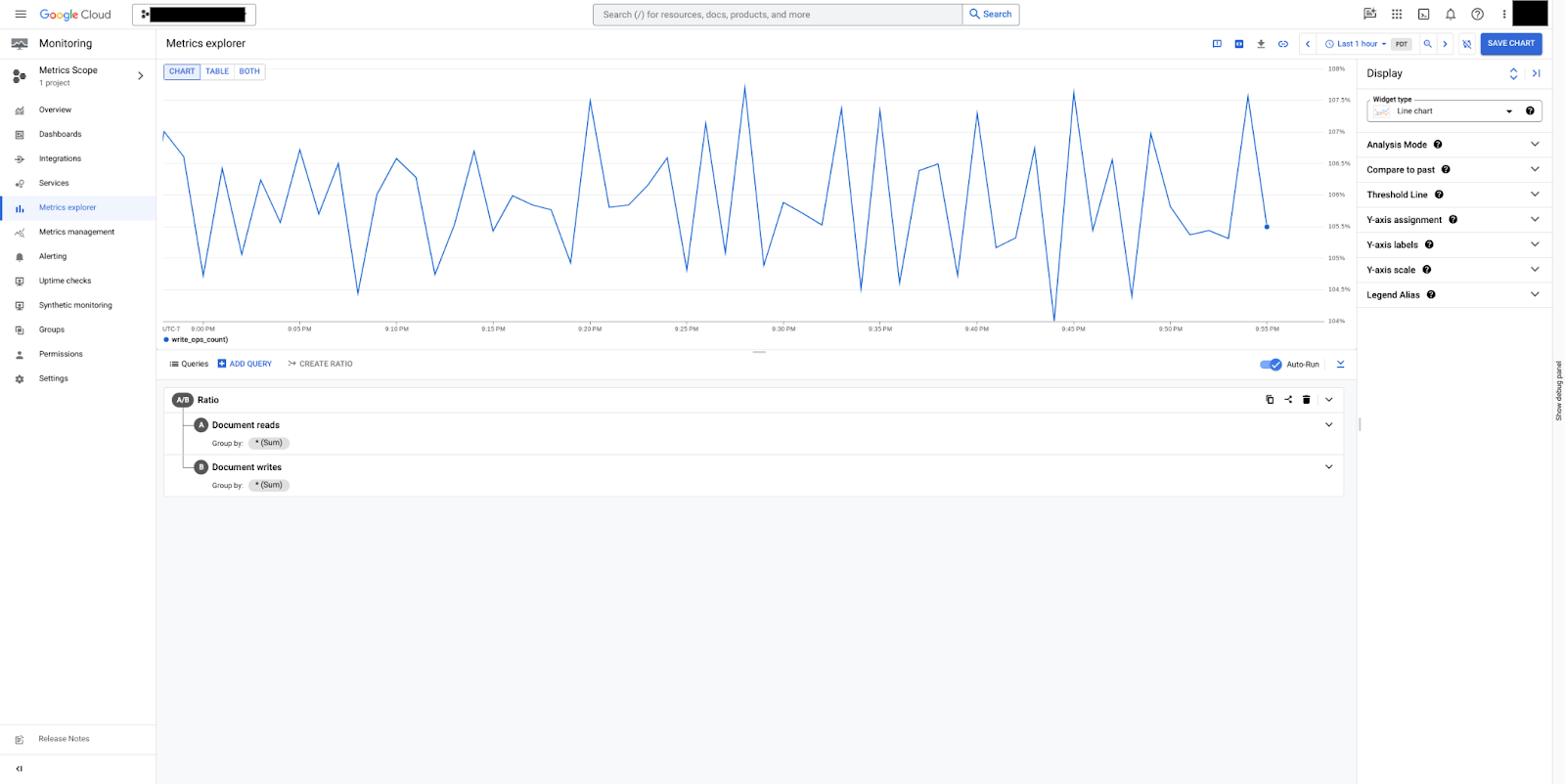
圖 6 顯示如何建立比率,指出讀取的文件與撰寫的文件比率。在本例中,讀取的文件數量比寫入的文件數量多出約 6%。
酬載大小指標
這些指標會提供讀取 (查閱和查詢) 和寫入 Firestore 資料庫的酬載大小 (以位元組為單位) 分布情形。這些值代表酬載總大小。例如查詢傳回的任何結果。
這些指標與 api/request_sizes 和 api/response_sizes 指標類似,主要差異在於文件作業指標提供更精細的取樣,但細目較不精細。
舉例來說,文件作業指標會使用 datastore_request 監控資源,因此不會有服務或方法細目。
entity/read_sizes:讀取文件的大小分布。entity/write_sizes:書面文件大小的分佈情形。
帳單指標 (Enterprise 版)
下列帳單指標僅適用於 Firestore Enterprise 版。
您可以透過這些指標瞭解帳單用量。這些指標不含管理員作業 (建立索引、匯入、匯出及大量刪除) 的帳單。
api/billable_read_units:可計費的讀取單位數量。用量可依服務名稱和 API 方法細分。api/billable_realtime_read_units:來自即時更新的可計費即時更新單位數量。api/billable_write_units:可計費寫入單位的數量。 用量可依服務名稱和 API 方法細分。document/billable_managed_delete_write_units:來自代管刪除服務 (例如 TTL) 的可計費寫入單位數量。
索引指標
您可以將索引寫入率與 document/write_ops_count 指標進行比較,瞭解 索引扇出比。
index/write_count:索引寫入次數。
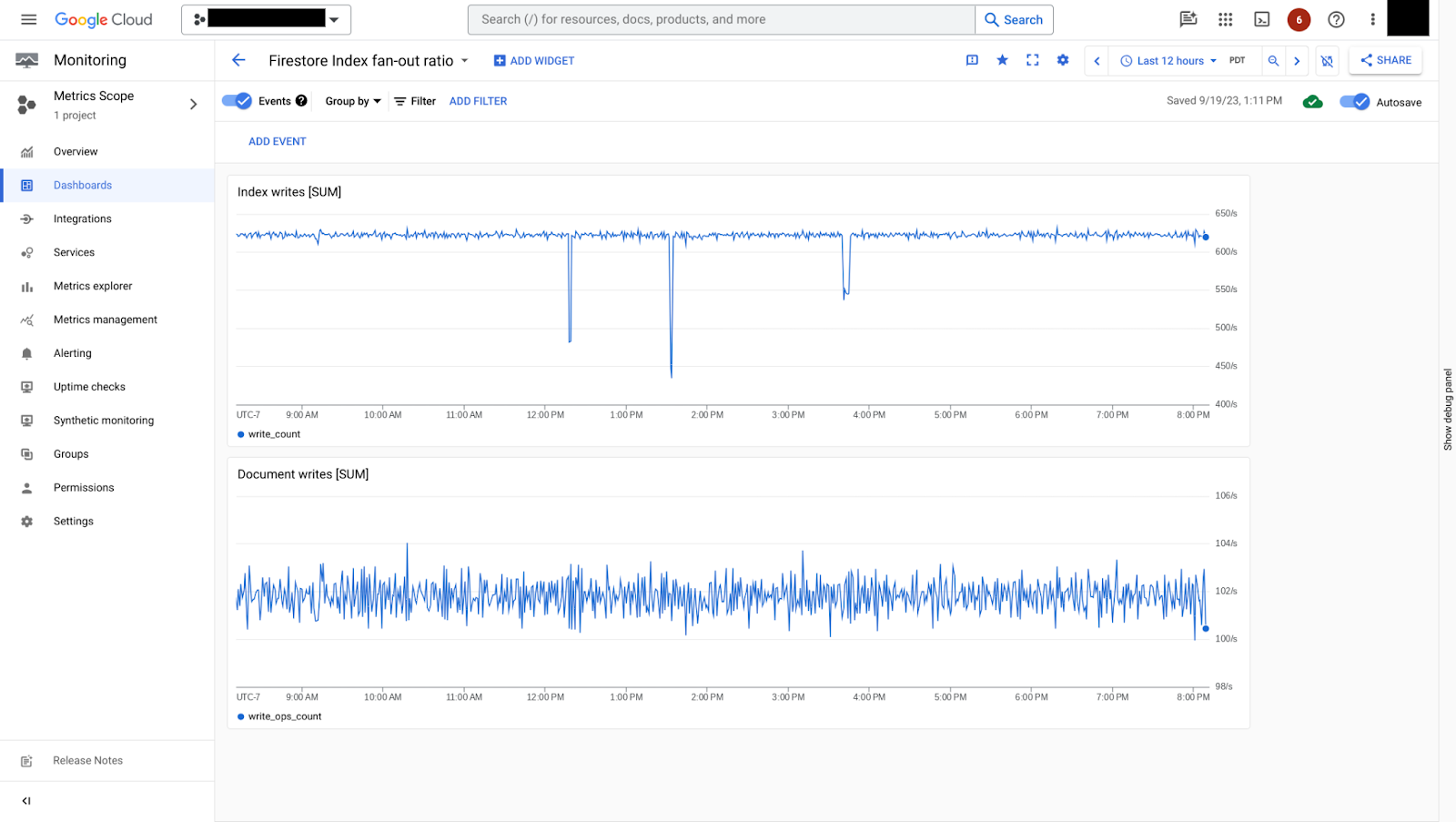
圖 7 顯示索引寫入速率與文件寫入速率的比較。在本例中,每寫入一個文件,大約會寫入 6 個索引,索引扇出率相對較小。
使用 Firebase SDK 直接連線至資料庫的用戶端
您可以透過兩項指標,追蹤直接連線至 Firestore 資料庫的用戶端活動,包括透過 Mobile SDK、Web SDK 或兩者連線的用戶端。這些指標包括與即時快照監聽器相關的功能,可將資料庫中的相關變更立即串流回用戶端。
network/active_connections:該時間點的有效連線數量。每個網頁或行動用戶端都會有一個連線。network/snapshot_listeners:目前在所有已連線的用戶端中註冊的快照監聽器數量。每個用戶端可能有多個連線。
您可以在 Firebase 控制台的 Firestore 資料庫中,查看「Usage」分頁標籤中的指標。

存留時間指標
存留時間指標適用於原生模式的 Firestore 和 Datastore 模式的 Firestore 資料庫。使用這些指標監控強制執行的 TTL 政策效果。
document/ttl_deletion_count:存留時間服務刪除的文件總數。
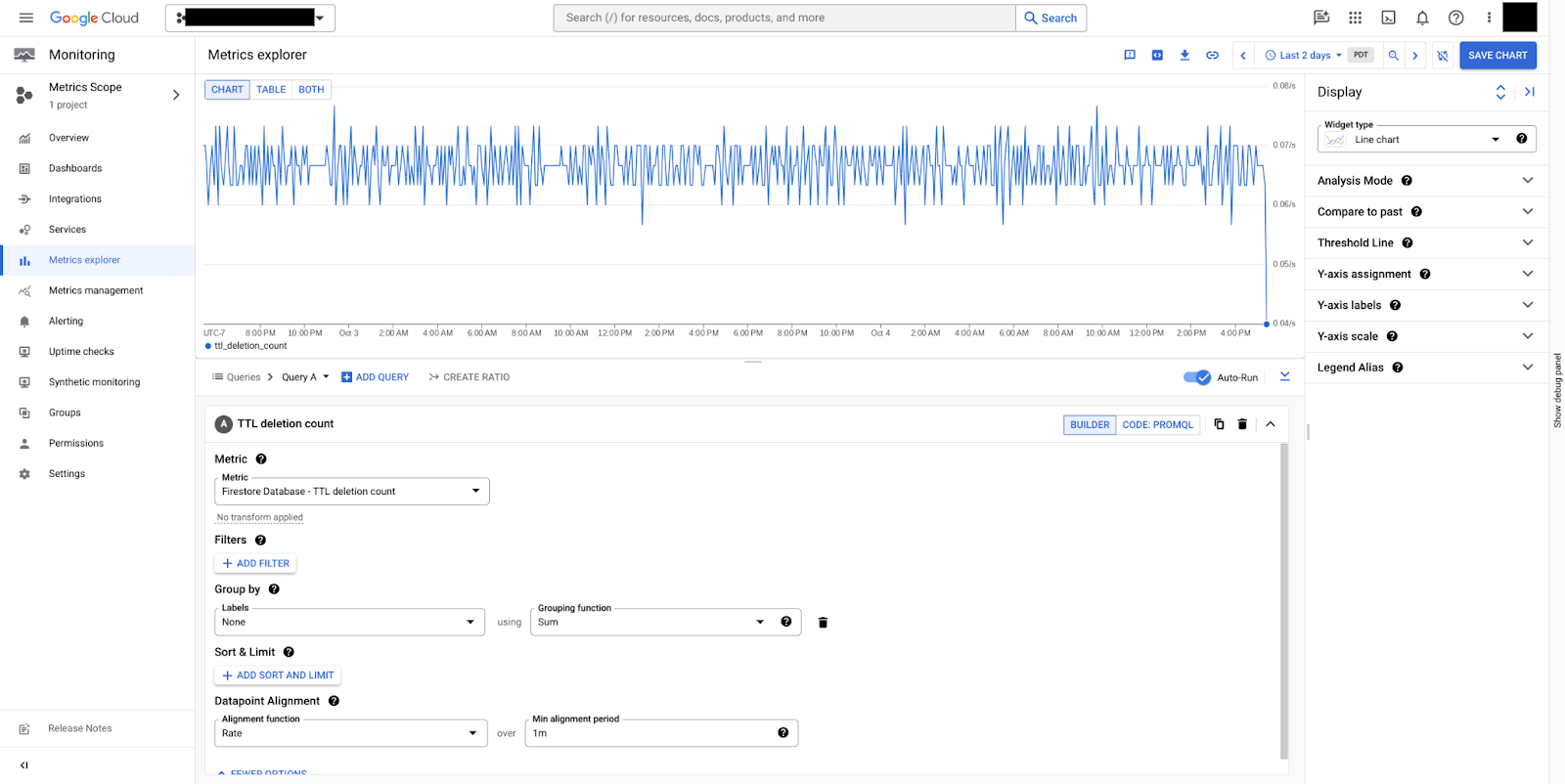
圖 9 顯示一段時間內每分鐘刪除的文件數量。
document/ttl_expiration_to_deletion_delays:文件存留時間到期後,實際刪除文件所經過的時間。
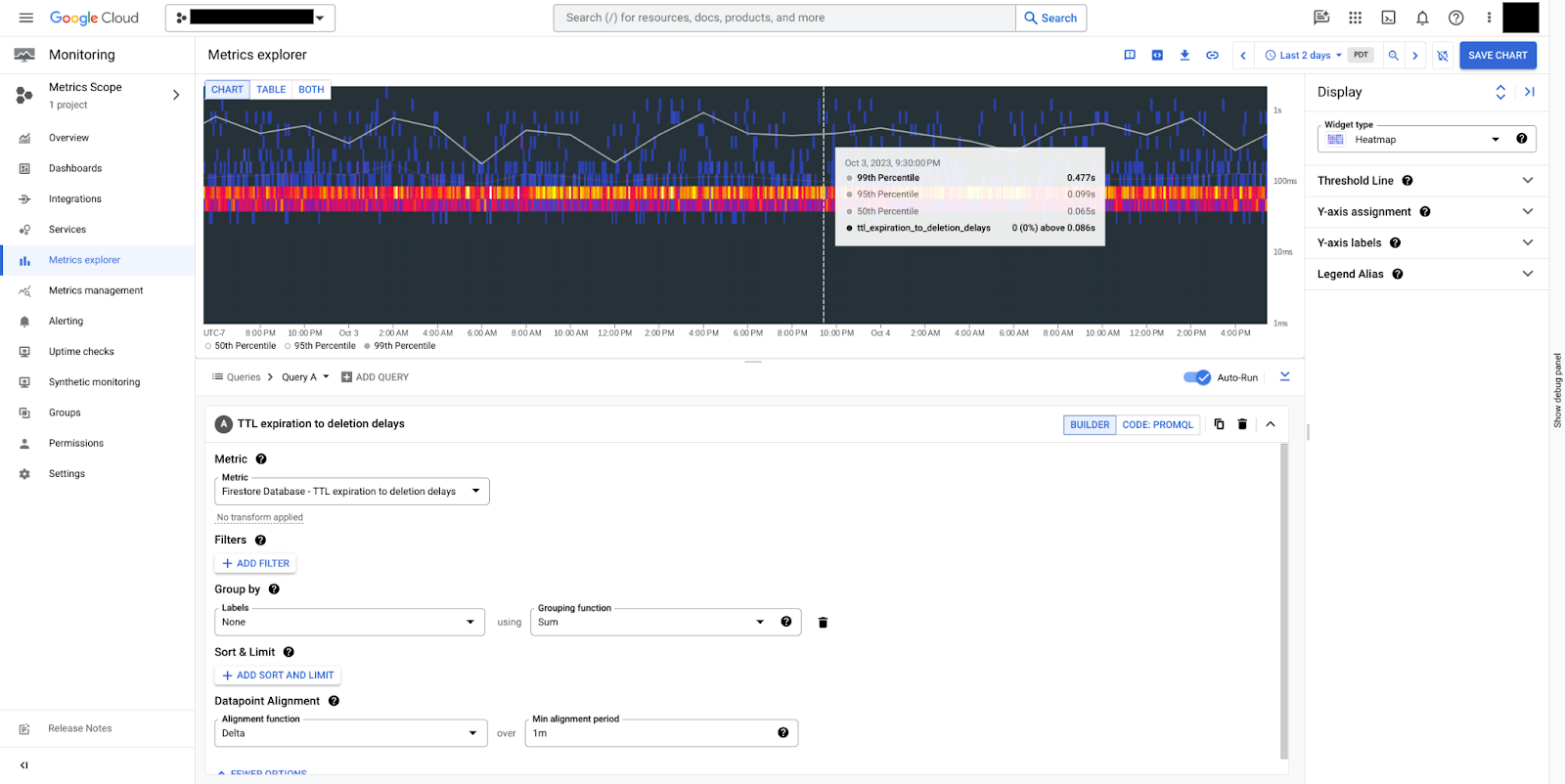
圖 10 顯示這項指標提供的時間分布圖,代表 Firestore 刪除設有存留時間政策的文件所花費的時間 (以秒為單位)。在第 99 個百分位數,刪除 TTL 過期文件的時間不到 0.5 秒。這表示系統運作正常。Firestore 通常會在 24 小時內刪除過期文件,但無法保證一定會這麼做。如果超過 24 小時仍未完成,請與支援團隊聯絡。
後續步驟
- 瞭解如何使用 Cloud Monitoring 資訊主頁查看指標。
- 監控用量,找出特定期間內的文件讀取、寫入和刪除次數。