
Après avoir collecté des métriques à partir de vos charges de travail déployées dans Google Distributed Cloud (GDC) air-gapped, vous pouvez commencer à les analyser. Pour analyser les métriques, vous pouvez les visualiser et les filtrer dans des tableaux de bord Grafana informatifs, ou y accéder directement depuis Cortex à l'aide de l'outil curl pour un script et une automatisation flexibles.
Cette page fournit des instructions détaillées sur la façon d'interroger et de visualiser vos métriques à l'aide de l'interface utilisateur Grafana et de l'outil curl pour le point de terminaison Cortex. Vous pourrez ainsi obtenir des insights sur les performances de votre charge de travail.
Vous pouvez accéder à vos métriques de deux manières :
- Tableaux de bord Grafana : explorez les tendances et identifiez les anomalies grâce à des visualisations intuitives des métriques clés, comme l'utilisation du processeur, la consommation de stockage et l'activité réseau. Grafana fournit une interface conviviale pour filtrer et analyser les données de charge de travail dans les tableaux de bord.
- Point de terminaison Cortex : pour les cas d'utilisation plus avancés, interrogez directement l'instance Cortex de votre projet à l'aide de l'outil
curlsur une ligne de commande. Cortex stocke les métriques Prometheus de votre projet et fournit un point de terminaison HTTP pour l'accès programmatique. Cet accès vous permet d'exporter des données, d'automatiser des tâches et de créer des intégrations personnalisées.
Avant de commencer
Pour obtenir les autorisations nécessaires pour interroger et visualiser les métriques dans les tableaux de bord Grafana, demandez à votre administrateur IAM de l'organisation ou du projet de vous accorder l'un des rôles prédéfinis "Lecteur Grafana de l'organisation" ou "Lecteur Grafana du projet". Selon le niveau d'accès et les autorisations dont vous avez besoin, vous pouvez obtenir des rôles Grafana dans une organisation ou un projet.
Vous pouvez également demander à l'administrateur IAM de votre projet de vous accorder le rôle Lecteur Prometheus Project Cortex dans l'espace de noms de votre projet pour obtenir les autorisations nécessaires pour interroger les métriques à partir du point de terminaison Cortex.
Le tableau suivant récapitule les exigences Role pour PA persona.
| Persona | Objet | Cluster | Rôle | Espace de noms | Groupe/Utilisateur | Config |
|---|---|---|---|---|---|---|
| PA | grafana | org-admin | project-grafana-viewer |
platform-obs | Groupe | 1 |
| PA | cortex | org-admin | project-cortex-prometheus-viewer |
platform-obs | Groupe | 2 |
| PA | grafana | org-admin | project-grafana-viewer |
platform-obs | Utilisateur | 3 |
| PA | cortex | org-admin | project-cortex-prometheus-viewer |
platform-obs | Utilisateur | 4 |
Remplacez les variables suivantes de manière appropriée :
| Variable | Description |
|---|---|
KUBECONFIG |
Vous aurez besoin du fichier kubeconfig du cluster spécifique contenant le NAMESPACE auquel ce RoleBinding sera appliqué. |
RULE_NAME |
Nom unique de cette ressource RoleBinding dans l'espace de noms. Exemple :io-root-cortex-prometheus-viewer |
NAMESPACE |
Espace de noms Kubernetes dans lequel ce RoleBinding sera créé et appliqué. Recherchez la colonne Namespace dans le tableau précédent. |
EMAIL_ADDRESS |
Identifiant de l'utilisateur auquel le rôle est attribué. Il s'agit souvent d'une adresse e-mail. Par exemple, infrastructure-operator@example.com. |
ROLE |
Nom du Role contenant les autorisations que vous souhaitez accorder à l'utilisateur. Recherchez les rôles disponibles dans le tableau précédent. |
GROUP_NAME |
Nom du Role contenant les autorisations que vous souhaitez accorder à l'utilisateur. Exemple :io-group |
ZONE |
Nom de la zone |
Configuration 1
Cette configuration est destinée à la persona PA, ciblant l'objet grafana dans le cluster org-admin.
Il attribue le rôle project-grafana-viewer dans l'espace de noms platform-obs à un Group.
Commande Kubectl
Voici le format générique des commandes :
kubectl --kubeconfig `KUBECONFIG` create rolebinding `RULE_NAME` -n platform-obs --group=`GROUP_NAME` --role=project-grafana-viewerExemple :
kubectl --kubeconfig <path-to-kubeconfig> create rolebinding project-grafana-viewers-binding --role=project-grafana-viewer --group=my-team --namespace=platform-obsChemin d'accès au fichier IAC
/infrastructure/zonal/zones/`ZONE`/org-admin/rolebindings/`GROUP_NAME`/<YAML_FILE>Fichier YAML
apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: RULE_NAME namespace: platform-obs subjects: - kind: Group name: GROUP_NAME apiGroup: rbac.authorization.k8s.io roleRef: kind: Role name: project-grafana-viewer apiGroup: rbac.authorization.k8s.io
Configuration 2
Cette configuration est destinée à la persona PA, ciblant l'objet cortex dans le cluster org-admin.
Il attribue le rôle project-cortex-prometheus-viewer dans l'espace de noms platform-obs à un Group.
Commande Kubectl
Voici le format générique des commandes :
kubectl --kubeconfig `KUBECONFIG` create rolebinding `RULE_NAME` -n platform-obs --group=`GROUP_NAME` --role=project-cortex-prometheus-viewerExemple :
kubectl --kubeconfig <path-to-kubeconfig> create rolebinding project-cortex-prometheus-viewer-binding --role=project-cortex-prometheus-viewer --group=my-team --namespace=platform-obsChemin d'accès au fichier IAC
/infrastructure/zonal/zones/`ZONE`/org-admin/rolebindings/`GROUP_NAME`/<YAML_FILE>Fichier YAML
apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: RULE_NAME namespace: platform-obs subjects: - kind: Group name: GROUP_NAME apiGroup: rbac.authorization.k8s.io roleRef: kind: Role name: project-cortex-prometheus-viewer apiGroup: rbac.authorization.k8s.io
Configuration 3
Cette configuration est destinée à la persona PA, ciblant l'objet grafana dans le cluster org-admin.
Il attribue le rôle project-grafana-viewer dans l'espace de noms platform-obs à un User.
Commande Kubectl
Voici le format générique des commandes :
kubectl --kubeconfig `KUBECONFIG` create rolebinding `RULE_NAME` -n platform-obs --user=`EMAIL_ADDRESS` --role=project-grafana-viewerExemple :
kubectl --kubeconfig <path-to-kubeconfig> create rolebinding project-grafana-viewers-binding --role=project-grafana-viewer --user=my-email@example.com --namespace=platform-obsChemin d'accès au fichier IAC
/infrastructure/zonal/zones/`ZONE`/org-admin/rolebindings/`EMAIL_ADDRESS`/<YAML_FILE>Fichier YAML
apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: RULE_NAME namespace: platform-obs subjects: - kind: User name: EMAIL_ADDRESS apiGroup: rbac.authorization.k8s.io roleRef: kind: Role name: project-grafana-viewer apiGroup: rbac.authorization.k8s.io
Configuration 4
Cette configuration est destinée à la persona PA, ciblant l'objet cortex dans le cluster org-admin.
Il attribue le rôle project-cortex-prometheus-viewer dans l'espace de noms platform-obs à un User.
Commande Kubectl
Voici le format générique des commandes :
kubectl --kubeconfig `KUBECONFIG` create rolebinding `RULE_NAME` -n platform-obs --user=`EMAIL_ADDRESS` --role=project-cortex-prometheus-viewerExemple :
kubectl --kubeconfig <path-to-kubeconfig> create rolebinding project-cortex-prometheus-viewer-binding --role=project-cortex-prometheus-viewer --user=my-email@example.com --namespace=platform-obsChemin d'accès au fichier IAC
/infrastructure/zonal/zones/`ZONE`/org-admin/rolebindings/`EMAIL_ADDRESS`/<YAML_FILE>Fichier YAML
apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: RULE_NAME namespace: platform-obs subjects: - kind: User name: EMAIL_ADDRESS apiGroup: rbac.authorization.k8s.io roleRef: kind: Role name: project-cortex-prometheus-viewer apiGroup: rbac.authorization.k8s.io
Pour en savoir plus sur ces rôles, consultez Préparer les autorisations IAM.
Obtenir et filtrer vos métriques
Sélectionnez l'une des méthodes suivantes pour créer des requêtes, visualiser des tendances et filtrer des métriques à partir des charges de travail de votre projet :
Tableaux de bord Grafana
Cette section explique comment accéder à vos métriques à l'aide des tableaux de bord Grafana.
Identifier votre point de terminaison Grafana
L'URL suivante est le point de terminaison de l'instance Grafana de votre projet :
https://GDC_URL/PROJECT_NAMESPACE/grafana
Remplacez les éléments suivants :
GDC_URL: URL de votre organisation dans GDC.PROJECT_NAMESPACE: espace de noms de votre projet.Par exemple, le point de terminaison Grafana pour le projet
platform-obsdans l'organisationorg-1esthttps://org-1/platform-obs/grafana.
Afficher les métriques dans l'interface utilisateur Grafana
Récupérez les métriques dans l'interface utilisateur Grafana :
- Dans la console GDC, sélectionnez votre projet.
- Dans le menu de navigation, sélectionnez Opérations > Monitoring.
Cliquez sur Tout afficher dans Grafana.
Une nouvelle page s'ouvre sur votre point de terminaison Grafana et affiche l'interface utilisateur.
Dans l'interface utilisateur, cliquez sur Explorer Explorer dans le menu de navigation pour ouvrir la page Explorer.
Dans le menu de la barre Explorer, sélectionnez une source de données pour récupérer les métriques, en fonction de votre type d'univers :
Univers à zone unique : sélectionnez prometheus pour afficher les métriques de la zone unique de votre univers.
Univers multizones : Grafana peut se connecter à différentes zones et afficher des données interzones. Sélectionnez Métriques ZONE_NAME pour afficher les métriques de n'importe quelle zone de votre univers, quelle que soit la zone à laquelle vous êtes connecté.
De plus, pour obtenir des visualisations de données multizones dans un seul tableau de bord et ajouter plusieurs zones à votre requête, sélectionnez Mixte comme source de données.
Saisissez une requête pour rechercher des métriques à l'aide d'expressions PromQL (Prometheus Query Language). Vous pouvez effectuer cette étape de l'une des deux manières suivantes :
- Sélectionnez une métrique et un libellé pour votre requête dans les menus Métrique et Filtres de libellés. Cliquez sur ajouter Ajouter pour ajouter d'autres libellés à votre requête. Cliquez ensuite sur Exécuter la requête.
- Saisissez votre requête directement dans le champ de texte Métriques, puis appuyez sur Maj+Entrée pour l'exécuter.
La page affiche les métriques correspondant à votre requête.
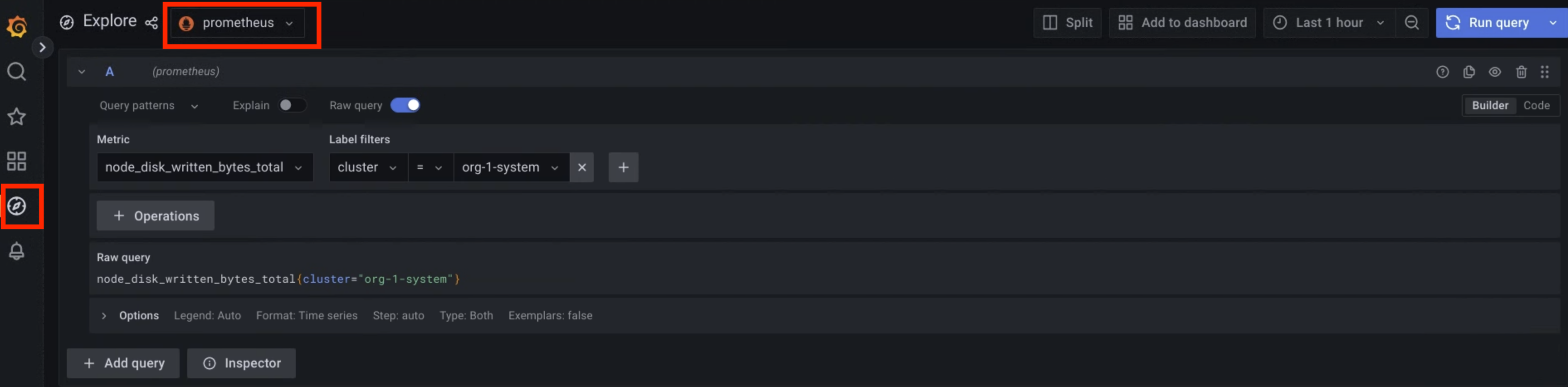
Figure 1 : Option de menu permettant d'interroger les métriques à partir de l'interface utilisateur Grafana.
Dans la figure 1, l'option prometheus affiche l'interface qui vous permet de créer des requêtes à partir de Grafana pour récupérer des métriques.
Pour obtenir des exemples de valeurs de libellés que vous pouvez utiliser pour interroger des métriques, consultez Exemples de requêtes et de libellés.
Point de terminaison Cortex (zone unique)
Cette section explique comment accéder à vos métriques à l'aide de Cortex.
Identifier votre point de terminaison Cortex
L'URL suivante est le point de terminaison de l'instance Cortex de votre projet :
https://GDC_URL/PROJECT_NAMESPACE/cortex/prometheus/
Remplacez les éléments suivants :
GDC_URL: URL de votre organisation dans GDC.PROJECT_NAMESPACE: espace de noms de votre projet.Par exemple, le point de terminaison Cortex pour le projet
platform-obsdans l'organisationorg-1esthttps://org-1/platform-obs/cortex/prometheus/.
Authentifier la requête curl
- Téléchargez et installez la gdcloud CLI.
Définissez la propriété gdcloud
core/organization_console_url:gdcloud config set core/organization_console_url https://GDC_URLSe connecter avec le fournisseur d'identité configuré :
gdcloud auth loginUtilisez votre nom d'utilisateur et votre mot de passe pour vous authentifier et vous connecter.
Une fois la connexion établie, vous pouvez utiliser l'en-tête d'autorisation dans votre requête curl à l'aide de la commande
gdcloud auth print-identity-token. Pour en savoir plus, consultez gdcloud auth.
Appeler le point de terminaison Cortex
Pour accéder au point de terminaison Cortex à l'aide de l'outil curl, procédez comme suit :
- Authentifiez la requête
curl. Utilisez
curlpour appeler le point de terminaison Cortex et étendre l'URL à l'aide du format d'API HTTP pour les requêtes afin d'interroger les métriques.Voici un exemple de requête
curl:curl https://GDC_URL/PROJECT_NAME/cortex/prometheus/api/v1/query?query=my_metric{cluster="my-cluster"}&time=2015-07-01T20:10:51.781Z \ -H "Authorization: Bearer $(gdcloud auth print-identity-token \ --audiences=https://GDC_URL)"Vous obtenez le résultat suivant après l'exécution de la commande. La réponse de l'API est au format JSON.
Point de terminaison Cortex : multizone
Cette section explique comment accéder à vos métriques à l'aide de Cortex.
Identifier votre point de terminaison Cortex
L'URL suivante est le point de terminaison de l'instance Cortex de votre projet pour les requêtes multizones :
https://GDC_URL/PROJECT_NAMESPACE/cortex/metrics
Remplacez les éléments suivants :
GDC_URL: URL de votre organisation dans GDC.- Exemple pour org-1, zone1 :
console.org-1.zone1.google.gdch.test - Remplacez l'organisation et la zone de votre application.
- Exemple pour org-1, zone1 :
PROJECT_NAMESPACE: espace de noms de votre projet.Par exemple, le point de terminaison Cortex pour le projet
project-1dans l'organisationorg-1esthttps://console.org-1.zone1.google.gdch.test/project-1/cortex/metrics..
Authentifier la requête curl
- Téléchargez et installez la gdcloud CLI.
Définissez la propriété gdcloud
core/organization_console_url:gdcloud config set core/organization_console_url https://GDC_URLSe connecter avec le fournisseur d'identité configuré :
gdcloud auth loginUtilisez votre nom d'utilisateur et votre mot de passe pour vous authentifier et vous connecter.
Une fois la connexion établie, vous pouvez utiliser l'en-tête d'autorisation dans votre requête curl à l'aide de la commande
gdcloud auth print-identity-token. Pour en savoir plus, consultez gdcloud auth.
Appeler le point de terminaison Cortex
Pour accéder au point de terminaison Cortex à l'aide de l'outil curl, procédez comme suit :
- Authentifiez la requête
curl. - Utilisez
curlpour appeler le point de terminaison Cortex et étendre l'URL à l'aide du format d'API HTTP pour les requêtes afin d'interroger les métriques. En plus des paramètres de requête d'URL Prometheus, incluez le paramètre de localisation pour fournir la liste des zones à interroger. - location={string} : liste des zones séparées par
|- Si aucune zone n'est spécifiée, la requête sera exécutée sur toutes les zones disponibles.Voici un exemple de requête
curl POST:curl POST \ https://GDC_URL/PROJECT_NAME/cortex/metrics/api/v1/query_range" \ -H 'Content-Type: application/x-www-form-urlencoded' \ --data-urlencode 'query=pod_cpu_usage_total' \ --data-urlencode 'start=2025-07-21T16:00:00Z' \ --data-urlencode 'end=2025-07-21T16:15:00Z' \ --data-urlencode 'step=60s' \ --data-urlencode 'location=zone1|zone2' \ -H "Authorization: Bearer $(gdcloud auth print-identity-token \ --audiences=https://GDC_URL)"Voici un exemple de requête
curl GET:curl -X GET \ https://GDC_URL/PROJECT_NAME/cortex/metrics/api/v1/query_range?query=pod_cpu_usage_total&start=2025-07-21T16:00:00Z&end=2025-07-21T16:15:00Z&step=1s&location=zone1|zone2" \ -H "Authorization: Bearer $(gdcloud auth print-identity-token \ --audiences=https://GDC_URL)"Vous obtenez le résultat après l'exécution de la commande. La réponse de l'API est au format JSON.
Exemples de requêtes et de libellés
Vous pouvez interroger des métriques à l'aide du nom de la métrique et des paires clé-valeur pour les libellés. Une requête PromQL utilise la syntaxe suivante :
metric_name{label_one="value", label_two="value"}
Les libellés vous permettent de différencier les caractéristiques d'une métrique. De cette manière, les auteurs de conteneurs font en sorte que leurs charges de travail génèrent des métriques et ajoutent des tags pour filtrer ces métriques.
Par exemple, vous pouvez utiliser une métrique api_http_requests_total pour comptabiliser le nombre de requêtes HTTP reçues. Vous pouvez ensuite ajouter un libellé request_method à cette métrique, qui prend une valeur POST, GET ou PUT. Par conséquent, vous créez trois flux de métriques pour chaque type de demande que vous pourriez recevoir. Dans ce cas, pour trouver le nombre de requêtes HTTP GET, exécutez la requête suivante :
api_http_requests_total{request_method="GET"}
Pour en savoir plus sur les métriques et les libellés, consultez Noms des métriques et des libellés.
Voici quelques-uns des libellés par défaut ajoutés par la ressource personnalisée MonitoringTarget. Vous pouvez utiliser ces libellés par défaut pour interroger les métriques :
_gdch_service: nom abrégé du service.cluster: nom du cluster.container_name: nom du conteneur dans un pod.namespace_name: espace de noms de votre projet.pod_name: préfixe du nom du pod.
Le tableau suivant décrit les libellés que Prometheus ajoute automatiquement :
| Libellé de la métrique | Description |
|---|---|
job |
Nom interne du job de récupération utilisé pour collecter la métrique. Les jobs créés par la ressource personnalisée MonitoringTarget ont un nom qui suit le modèle suivant :obs-system/OBS_SHADOW_PROJECT_NAME/MONITORINGTARGET_NAME.MONITORINGTARGET_NAMESPACE/I/JI et J sont des nombres uniques déterminés en interne pour éviter les conflits de noms. |
instance |
$IP:$PORT du service abandonné. Si une ressource de charge de travail comporte plusieurs réplicas, utilisez ce champ pour les différencier. |
L'exemple de code suivant montre comment utiliser des paires clé-valeur pour les libellés afin d'interroger différentes métriques pour afficher l'utilisation du processeur collectée dans un cluster Kubernetes :
pod_cpu_usage_total{cluster="CLUSTER_NAME"}
Utilisez l'outil de modification des libellés de métriques pour ajouter des libellés qui n'étaient pas exposés initialement par les conteneurs récupérés et renommer les métriques produites. Vous devez configurer la ressource personnalisée MonitoringTarget pour ajouter des libellés aux métriques qu'elle collecte.
Spécifiez ces libellés dans le champ metricsRelabelings de la ressource personnalisée.
Pour en savoir plus, consultez Métriques des libellés.
Voici un exemple de réponse reçue d'un point de terminaison de métriques Cortex :
{
"zone1": {
"status": "success",
"data": {
"resultType": "matrix",
"result": [
{
"metric": {
"__name__": "pod_cpu_usage_total",
"_gdch_project": "project-1",
"cluster": "root-admin",
"container_name": "otel-collector",
"exported_instance": "localhost:2112",
"exported_job": "workload-0",
"ha_cluster": "root-admin-shard1",
"instance": "172.192.1.74:3113",
"job": "metrics-server-exporter.mon-system",
"namespace": "mon-system",
"namespace_name": "mon-system",
"pod": "cortex-0",
"pod_name": "metrics-server-exporter-695c9f848b-swzgq",
"zone_id": "zone1"
},
"values": [
[
1753261200,
"2.258621991"
],
[
1753261800,
"1.029301454"
]
]
}
]
}
},
"zone2": {
"status": "success",
"data": {
"resultType": "matrix",
"result": [
{
"metric": {
"__name__": "pod_cpu_usage_total",
"_gdch_project": "project-1",
"cluster": "root-admin",
"container_name": "otel-collector",
"exported_instance": "localhost:2112",
"exported_job": "workload-0",
"ha_cluster": "root-admin-shard1",
"instance": "172.196.3.208:3113",
"job": "metrics-server-exporter.mon-system",
"namespace": "mon-system",
"namespace_name": "mon-system",
"pod": "cortex-0",
"pod_name": "metrics-server-exporter-695c9f848b-kchfv",
"zone_id": "zone2"
},
"values": [
[
1753261200,
"1.814027424"
],
[
1753261800,
"2.7767060260000003"
]
]
}
]
}
}
}
Interroger l'API HTTP
Présentation du format
Les réponses de l'API sont systématiquement au format JSON. Les requêtes réussies reçoivent toujours un code d'état 2xx.
Pour les requêtes non valides, les gestionnaires d'API renvoient un objet d'erreur JSON ainsi que l'un des codes d'état HTTP suivants :
- 400 Bad Request : si des paramètres essentiels sont manquants ou incorrects.
- 503 Service indisponible : si les requêtes dépassent leur limite de temps ou sont abandonnées.
Toutes les données collectées seront incluses dans le champ "data" de la réponse.
Le format de l'enveloppe de réponse JSON est le suivant :
{
"status": "success" | "error",
"data": <data>,
// Only set if status is "error". The data field may still hold
// additional data.
"errorType": "<string>",
"error": "<string>",
// Only set if there were warnings while executing the request.
// There will still be data in the data field.
"warnings": ["<string>"],
// Only set if there were info-level annotations while executing the request.
"infos": ["<string>"]
}
Requêtes instantanées
Le point de terminaison suivant évalue une requête instantanée à un moment précis :
GET /api/v1/query
POST /api/v1/query
Les paramètres de requête d'URL suivants sont disponibles pour les requêtes d'expression Prometheus :
query=<string>: chaîne de requête d'expression Prometheus.time=<rfc3339 | unix_timestamp>: code temporel d'évaluation facultatif, spécifié sous la forme d'une chaîne RFC 3339 ou d'un code temporel UNIX. Si elle est omise, l'heure actuelle du serveur est utilisée.timeout=<duration>: délai d'évaluation facultatif. La valeur par défaut est celle de l'indicateur query.timeout, qui est également la valeur maximale.limit=<number>: nombre maximal facultatif de séries à renvoyer. Cela tronque les séries pour les matrices et les vecteurs, mais n'affecte pas les scalaires ni les chaînes. La valeur 0 désactive cette limite.lookback_delta=<number>: paramètre facultatif permettant de remplacer la période d'analyse spécifiquement pour cette requête.
L'heure actuelle du serveur est utilisée si le paramètre "time" est omis.
Pour les requêtes plus volumineuses qui peuvent dépasser les limites de caractères des URL, vous pouvez envoyer ces paramètres à l'aide de la méthode POST. Assurez-vous que le corps de la requête est encodé en URL et que l'en-tête Content-Type est défini sur application/x-www-form-urlencoded.
La section de données du résultat de la requête se présente au format suivant :
{
"resultType": "matrix" | "vector" | "scalar" | "string",
"result": <value>
}
<value> fait référence aux données des résultats de la requête, dont le format varie en fonction de resultType.
L'exemple suivant évalue l'expression jusqu'à la date et l'heure 2015-07-01T20:10:51.781Z :
curl 'http://localhost:9090/api/v1/query?query=up&time=2015-07-01T20:10:51.781Z'
{
"status" : "success",
"data" : {
"resultType" : "vector",
"result" : [
{
"metric" : {
"__name__" : "up",
"job" : "prometheus",
"instance" : "localhost:9090"
},
"value": [ 1435781451.781, "1" ]
},
{
"metric" : {
"__name__" : "up",
"job" : "node",
"instance" : "localhost:9100"
},
"value" : [ 1435781451.781, "0" ]
}
]
}
}
Requêtes de plage
Le point de terminaison suivant évalue une requête d'expression sur une période donnée :
GET /api/v1/query_range
POST /api/v1/query_range
Les paramètres de requête d'URL suivants sont disponibles pour les requêtes d'expression Prometheus :
query=<string>: chaîne de requête d'expression Prometheus.start=<rfc3339 | unix_timestamp>: code temporel de début (inclus).end=<rfc3339 | unix_timestamp>: code temporel de fin (inclus).step=<duration | float>: largeur du pas de résolution de la requête au format de durée ou nombre flottant de secondes.timeout=<duration>: délai d'évaluation facultatif. La valeur par défaut est celle de l'indicateur query.timeout, qui est également la valeur maximale.limit=<number>: nombre maximal facultatif de séries à renvoyer. Cela tronque les séries pour les matrices et les vecteurs, mais n'affecte pas les scalaires ni les chaînes. La valeur 0 désactive cette limite.lookback_delta=<number>: paramètre facultatif permettant de remplacer la période d'analyse spécifiquement pour cette requête.
Pour les requêtes plus volumineuses qui peuvent dépasser les limites de caractères des URL, vous pouvez envoyer ces paramètres à l'aide de la méthode POST. Assurez-vous que le corps de la requête est encodé en URL et que l'en-tête Content-Type est défini sur application/x-www-form-urlencoded.
La section de données du résultat de la requête se présente au format suivant :
{
"resultType": "matrix",
"result": <value>
}
L'exemple suivant évalue l'expression "up" sur une plage de 30 secondes avec une résolution de requête de 15 secondes.
curl 'http://localhost:9090/api/v1/query_range?query=up&start=2015-07-01T20:10:30.781Z&end=2015-07-01T20:11:00.781Z&step=15s'
{
"status" : "success",
"data" : {
"resultType" : "matrix",
"result" : [
{
"metric" : {
"__name__" : "up",
"job" : "prometheus",
"instance" : "localhost:9090"
},
"values" : [
[ 1435781430.781, "1" ],
[ 1435781445.781, "1" ],
[ 1435781460.781, "1" ]
]
},
{
"metric" : {
"__name__" : "up",
"job" : "node",
"instance" : "localhost:9091"
},
"values" : [
[ 1435781430.781, "0" ],
[ 1435781445.781, "0" ],
[ 1435781460.781, "1" ]
]
}
]
}
}
Nommer les métriques et les libellés
Consignes concernant l'attribution de noms aux métriques
Lorsque vous définissez des noms de métriques, tenez compte des principes suivants :
Un nom de métrique DOIT inclure un préfixe d'application d'un seul mot, que les bibliothèques clientes appellent parfois "espace de noms". Ce préfixe identifie le domaine auquel appartient la métrique. Pour les métriques spécifiques à une application, le nom de l'application est généralement utilisé comme préfixe.
Exemples :
- prometheus_notifications_total (spécifique au serveur Prometheus)
- process_cpu_seconds_total (exporté par de nombreuses bibliothèques clientes)
- http_request_duration_seconds (pour toutes les requêtes HTTP)
Un nom de métrique DOIT représenter une seule unité (par exemple, évitez de mélanger les secondes et les millisecondes, ou les secondes et les octets).
Le nom d'une métrique DOIT utiliser des unités de base (par exemple, secondes, octets, mètres) plutôt que des unités dérivées (par exemple, millisecondes, mégaoctets, kilomètres).
Le nom d'une métrique DOIT inclure un suffixe d'unité au pluriel. Pour les nombres cumulés, le suffixe "total" doit être utilisé en plus du suffixe d'unité, le cas échéant.
Exemples :
- http_request_duration_seconds
- node_memory_usage_bytes
- http_requests_total (pour un nombre cumulé sans unité)
- process_cpu_seconds_total (pour un nombre cumulé avec une unité)
- foobar_build_info (pour une pseudo-métrique fournissant des métadonnées sur le binaire en cours d'exécution)
Un nom de métrique PEUT ordonner ses composants pour faciliter le regroupement lors du tri lexicographique, à condition que toutes les autres règles soient respectées. Les métriques associées ont souvent des composants de nom communs placés en premier pour s'assurer qu'elles sont triées ensemble.
Exemples :
- prometheus_tsdb_head_truncations_closed_total
- prometheus_tsdb_head_truncations_established_total
- prometheus_tsdb_head_truncations_failed_total
- prometheus_tsdb_head_truncations_total
Le nom d'une métrique DOIT représenter de manière cohérente la même "chose mesurée" logique pour toutes les dimensions de libellé.
Exemples :
- Durée d'une requête
- octets de données transférées
- Utilisation instantanée des ressources en pourcentage
Consignes pour nommer les libellés
Lorsque vous mesurez quelque chose, utilisez des libellés pour distinguer ses caractéristiques. Exemple :
- Pour le nombre total de requêtes HTTP d'API (
api_http_requests_total), différenciez-les par type d'opération, par exemplecreate,update,delete(types de requêtes :operation="create|update|delete"). - Pour la durée des requêtes d'API en secondes (
api_request_duration_seconds), différenciez-les par étape de requête, par exempleextract,transform,load(étapes de requête :stage="extract|transform|load").
Évitez d'inclure des noms de libellés dans le nom de la métrique elle-même, car cela crée une redondance et peut entraîner une confusion si ces libellés sont agrégés ultérieurement.