
Dopo aver raccolto le metriche dai workload di cui è stato eseguito il deployment in Google Distributed Cloud (GDC) con air gap, puoi iniziare ad analizzarle. Per analizzare le metriche, puoi visualizzarle e filtrarle in
dashboard Grafana informative oppure accedervi direttamente da Cortex utilizzando lo strumento
curl per script e automazione flessibili.
Questa pagina fornisce istruzioni dettagliate su come eseguire query e visualizzare le metriche utilizzando sia l'interfaccia utente di Grafana sia lo strumento curl per l'endpoint Cortex per ottenere informazioni sul rendimento del tuo workload.
Puoi accedere alle metriche in uno dei due modi seguenti:
- Dashboard Grafana: esplora le tendenze e identifica le anomalie con visualizzazioni intuitive di metriche chiave come l'utilizzo della CPU, il consumo di spazio di archiviazione e l'attività di rete. Grafana fornisce un'interfaccia facile da usare per filtrare e analizzare i dati dei workload nelle dashboard.
- Endpoint Cortex: per casi d'uso più avanzati, esegui query direttamente sull'istanza Cortex del tuo progetto utilizzando lo strumento
curlsu una riga di comando. Cortex archivia le metriche Prometheus del tuo progetto e fornisce un endpoint HTTP per l'accesso programmatico. Questo accesso ti consente di esportare dati, automatizzare attività e creare integrazioni personalizzate.
Prima di iniziare
Per ottenere le autorizzazioni necessarie per eseguire query e visualizzare le metriche nelle dashboard Grafana, chiedi all'amministratore IAM dell'organizzazione o all'amministratore IAM del progetto di concederti uno dei ruoli predefiniti Grafana Viewer o Project Grafana Viewer. A seconda del livello di accesso e delle autorizzazioni di cui hai bisogno, potresti ottenere ruoli Grafana in un'organizzazione o un progetto.
In alternativa, per ottenere le autorizzazioni necessarie per eseguire query sulle metriche dall'endpoint Cortex, chiedi all'amministratore IAM del progetto di concederti il ruolo Project Cortex Prometheus Viewer nello spazio dei nomi del progetto.
La seguente tabella riepiloga i requisiti di Role per PA persona.
| Utente tipo | Oggetto | Cluster | Ruolo | Spazio dei nomi | Gruppo/utente | Configurazione |
|---|---|---|---|---|---|---|
| PA | grafana | org-admin | project-grafana-viewer |
platform-obs | Gruppo | 1 |
| PA | cortex | org-admin | project-cortex-prometheus-viewer |
platform-obs | Gruppo | 2 |
| PA | grafana | org-admin | project-grafana-viewer |
platform-obs | Utente | 3 |
| PA | cortex | org-admin | project-cortex-prometheus-viewer |
platform-obs | Utente | 4 |
Sostituisci le seguenti variabili in modo appropriato:
| Variabile | Descrizione |
|---|---|
KUBECONFIG |
Avrai bisogno del kubeconfig per il cluster specifico che contiene NAMESPACE in cui verrà applicato questo RoleBinding. |
RULE_NAME |
Il nome univoco di questa risorsa RoleBinding all'interno dello spazio dei nomi. Ad esempio, io-root-cortex-prometheus-viewer. |
NAMESPACE |
Lo spazio dei nomi Kubernetes in cui verrà creato e applicato questo RoleBinding. Cerca la colonna Namespace nella tabella precedente. |
EMAIL_ADDRESS |
L'identificatore dell'utente a cui viene concesso il ruolo. Spesso si tratta di un indirizzo email. Ad esempio, infrastructure-operator@example.com. |
ROLE |
Il nome del Role che contiene le autorizzazioni che vuoi concedere all'utente. Cerca i ruoli disponibili nella tabella precedente |
GROUP_NAME |
Il nome del Role che contiene le autorizzazioni che vuoi concedere all'utente. Ad esempio, io-group. |
ZONE |
Nome della zona |
Configurazione 1
Questa configurazione è per l'utente tipo PA, che ha come target l'oggetto grafana nel cluster org-admin.
Concede il ruolo project-grafana-viewer all'interno dello spazio dei nomi platform-obs a un Group.
Comando kubectl
Questo è il formato generico del comando:
kubectl --kubeconfig `KUBECONFIG` create rolebinding `RULE_NAME` -n platform-obs --group=`GROUP_NAME` --role=project-grafana-viewerEsempio:
kubectl --kubeconfig <path-to-kubeconfig> create rolebinding project-grafana-viewers-binding --role=project-grafana-viewer --group=my-team --namespace=platform-obsPercorso file IAC
/infrastructure/zonal/zones/`ZONE`/org-admin/rolebindings/`GROUP_NAME`/<YAML_FILE>File YAML
apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: RULE_NAME namespace: platform-obs subjects: - kind: Group name: GROUP_NAME apiGroup: rbac.authorization.k8s.io roleRef: kind: Role name: project-grafana-viewer apiGroup: rbac.authorization.k8s.io
Configurazione 2
Questa configurazione è per l'utente tipo PA, che ha come target l'oggetto cortex nel cluster org-admin.
Concede il ruolo project-cortex-prometheus-viewer all'interno dello spazio dei nomi platform-obs a un Group.
Comando kubectl
Questo è il formato generico del comando:
kubectl --kubeconfig `KUBECONFIG` create rolebinding `RULE_NAME` -n platform-obs --group=`GROUP_NAME` --role=project-cortex-prometheus-viewerEsempio:
kubectl --kubeconfig <path-to-kubeconfig> create rolebinding project-cortex-prometheus-viewer-binding --role=project-cortex-prometheus-viewer --group=my-team --namespace=platform-obsPercorso file IAC
/infrastructure/zonal/zones/`ZONE`/org-admin/rolebindings/`GROUP_NAME`/<YAML_FILE>File YAML
apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: RULE_NAME namespace: platform-obs subjects: - kind: Group name: GROUP_NAME apiGroup: rbac.authorization.k8s.io roleRef: kind: Role name: project-cortex-prometheus-viewer apiGroup: rbac.authorization.k8s.io
Configurazione 3
Questa configurazione è per l'utente tipo PA, che ha come target l'oggetto grafana nel cluster org-admin.
Concede il ruolo project-grafana-viewer all'interno dello spazio dei nomi platform-obs a un User.
Comando kubectl
Questo è il formato generico del comando:
kubectl --kubeconfig `KUBECONFIG` create rolebinding `RULE_NAME` -n platform-obs --user=`EMAIL_ADDRESS` --role=project-grafana-viewerEsempio:
kubectl --kubeconfig <path-to-kubeconfig> create rolebinding project-grafana-viewers-binding --role=project-grafana-viewer --user=my-email@example.com --namespace=platform-obsPercorso file IAC
/infrastructure/zonal/zones/`ZONE`/org-admin/rolebindings/`EMAIL_ADDRESS`/<YAML_FILE>File YAML
apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: RULE_NAME namespace: platform-obs subjects: - kind: User name: EMAIL_ADDRESS apiGroup: rbac.authorization.k8s.io roleRef: kind: Role name: project-grafana-viewer apiGroup: rbac.authorization.k8s.io
Configurazione 4
Questa configurazione è per l'utente tipo PA, che ha come target l'oggetto cortex nel cluster org-admin.
Concede il ruolo project-cortex-prometheus-viewer all'interno dello spazio dei nomi platform-obs a un User.
Comando kubectl
Questo è il formato generico del comando:
kubectl --kubeconfig `KUBECONFIG` create rolebinding `RULE_NAME` -n platform-obs --user=`EMAIL_ADDRESS` --role=project-cortex-prometheus-viewerEsempio:
kubectl --kubeconfig <path-to-kubeconfig> create rolebinding project-cortex-prometheus-viewer-binding --role=project-cortex-prometheus-viewer --user=my-email@example.com --namespace=platform-obsPercorso file IAC
/infrastructure/zonal/zones/`ZONE`/org-admin/rolebindings/`EMAIL_ADDRESS`/<YAML_FILE>File YAML
apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: RULE_NAME namespace: platform-obs subjects: - kind: User name: EMAIL_ADDRESS apiGroup: rbac.authorization.k8s.io roleRef: kind: Role name: project-cortex-prometheus-viewer apiGroup: rbac.authorization.k8s.io
Per saperne di più su questi ruoli, consulta Prepara le autorizzazioni IAM.
Ottieni e filtra le metriche
Seleziona uno dei seguenti metodi per creare query, visualizzare le tendenze e filtrare le metriche dai workload del progetto:
Dashboard Grafana
Questa sezione descrive come accedere alle metriche utilizzando le dashboard Grafana.
Identifica l'endpoint Grafana
Il seguente URL è l'endpoint dell'istanza Grafana del tuo progetto:
https://GDC_URL/PROJECT_NAMESPACE/grafana
Sostituisci quanto segue:
GDC_URL: l'URL della tua organizzazione in GDC.PROJECT_NAMESPACE: lo spazio dei nomi del progetto.Ad esempio, l'endpoint Grafana per il progetto
platform-obsnell'organizzazioneorg-1èhttps://org-1/platform-obs/grafana.
Visualizza le metriche nell'interfaccia utente di Grafana
Recupera le metriche nell'interfaccia utente di Grafana:
- Nella console GDC, seleziona il progetto.
- Nel menu di navigazione, seleziona Operazioni > Monitoring.
Fai clic su Visualizza tutto in Grafana.
Si apre una nuova pagina con l'endpoint Grafana e viene visualizzata l'interfaccia utente.
Nell'interfaccia utente, fai clic su Esplora Esplora dal menu di navigazione per aprire la pagina Esplora.
Dal menu della barra Esplora, seleziona un'origine dati per recuperare le metriche in base al tipo di universo:
Universi a zona singola: seleziona prometheus per visualizzare le metriche della singola zona del tuo universo.
Universi multizona: Grafana può connettersi a zone diverse e mostrare i dati tra le zone. Seleziona Metriche ZONE_NAME per visualizzare le metriche di qualsiasi zona del tuo universo, indipendentemente dalla zona in cui hai eseguito l'accesso.
Inoltre, per visualizzare i dati tra zone diverse in un'unica dashboard e aggiungere più zone alla query, seleziona Mista come origine dati.
Inserisci una query per cercare le metriche utilizzando le espressioni PromQL (Prometheus Query Language). Puoi completare questo passaggio in uno dei seguenti modi:
- Seleziona una metrica e un'etichetta per la query dai menu Metrica e Filtri etichette. Fai clic su Aggiungi Aggiungi per aggiungere altre etichette alla query. Quindi, fai clic su Esegui query.
- Inserisci la query direttamente nel campo di testo Metriche e premi Maiusc+Invio per eseguire la query.
La pagina mostra le metriche corrispondenti alla tua query.
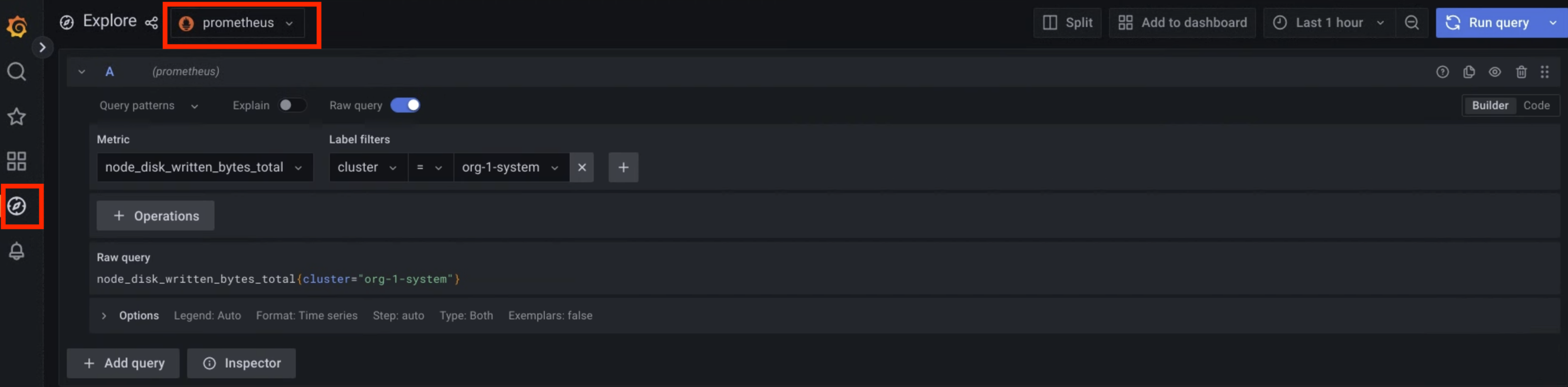
Figura 1. Opzione di menu per eseguire query sulle metriche dall'interfaccia utente di Grafana.
Nella figura 1, l'opzione prometheus mostra l'interfaccia che consente di creare query da Grafana per recuperare le metriche.
Per esempi di valori delle etichette che puoi utilizzare per eseguire query sulle metriche, vedi Query ed etichette di esempio.
Endpoint Cortex - Singola zona
Questa sezione descrive come accedere alle metriche utilizzando Cortex.
Identifica l'endpoint Cortex
Il seguente URL è l'endpoint dell'istanza Cortex del tuo progetto:
https://GDC_URL/PROJECT_NAMESPACE/cortex/prometheus/
Sostituisci quanto segue:
GDC_URL: l'URL della tua organizzazione in GDC.PROJECT_NAMESPACE: lo spazio dei nomi del progetto.Ad esempio, l'endpoint Cortex per il progetto
platform-obsnell'organizzazioneorg-1èhttps://org-1/platform-obs/cortex/prometheus/.
Autentica la richiesta curl
- Scarica e installa l'interfaccia a riga di comando gcloud.
Imposta la proprietà gdcloud
core/organization_console_url:gdcloud config set core/organization_console_url https://GDC_URLAccedi con il provider di identità configurato:
gdcloud auth loginUtilizza il tuo nome utente e la tua password per autenticarti e accedere.
Una volta eseguito l'accesso, puoi utilizzare l'intestazione di autorizzazione nella richiesta curl tramite il comando
gdcloud auth print-identity-token. Per maggiori informazioni, consulta gdcloud auth.
Chiama l'endpoint Cortex
Completa i seguenti passaggi per raggiungere l'endpoint Cortex utilizzando lo strumento curl:
- Autentica la richiesta
curl. Utilizza
curlper chiamare l'endpoint Cortex ed estendi l'URL utilizzando il formato dell'API HTTP di query per eseguire query sulle metriche.Di seguito è riportato un esempio di richiesta
curl:curl https://GDC_URL/PROJECT_NAME/cortex/prometheus/api/v1/query?query=my_metric{cluster="my-cluster"}&time=2015-07-01T20:10:51.781Z \ -H "Authorization: Bearer $(gdcloud auth print-identity-token \ --audiences=https://GDC_URL)"Ottieni l'output seguente al comando. La risposta dell'API è in formato JSON.
Endpoint Cortex - Multizona
Questa sezione descrive come accedere alle metriche utilizzando Cortex.
Identifica l'endpoint Cortex
Il seguente URL è l'endpoint dell'istanza Cortex del tuo progetto per la query multizona:
https://GDC_URL/PROJECT_NAMESPACE/cortex/metrics
Sostituisci quanto segue:
GDC_URL: l'URL della tua organizzazione in GDC.- Esempio per org-1, zone1:
console.org-1.zone1.google.gdch.test - Sostituisci l'organizzazione e la zona per la tua applicazione.
- Esempio per org-1, zone1:
PROJECT_NAMESPACE: lo spazio dei nomi del progetto.Ad esempio, l'endpoint Cortex per il progetto
project-1nell'organizzazioneorg-1èhttps://console.org-1.zone1.google.gdch.test/project-1/cortex/metrics..
Autentica la richiesta curl
- Scarica e installa l'interfaccia a riga di comando gcloud.
Imposta la proprietà gdcloud
core/organization_console_url:gdcloud config set core/organization_console_url https://GDC_URLAccedi con il provider di identità configurato:
gdcloud auth loginUtilizza il tuo nome utente e la tua password per autenticarti e accedere.
Una volta eseguito l'accesso, puoi utilizzare l'intestazione di autorizzazione nella richiesta curl tramite il comando
gdcloud auth print-identity-token. Per maggiori informazioni, consulta gdcloud auth.
Chiama l'endpoint Cortex
Completa i seguenti passaggi per raggiungere l'endpoint Cortex utilizzando lo strumento curl:
- Autentica la richiesta
curl. - Utilizza
curlper chiamare l'endpoint Cortex ed estendi l'URL utilizzando il formato dell'API HTTP di query per eseguire query sulle metriche. Oltre ai parametri di ricerca dell'URL Prometheus, includi il parametro di località per fornire l'elenco delle zone da interrogare. - location={string}: elenco di zone separate da
|- Se non viene fornito, la query verrà eseguita su tutte le zone disponibili.Di seguito è riportato un esempio di richiesta
curl POST:curl POST \ https://GDC_URL/PROJECT_NAME/cortex/metrics/api/v1/query_range" \ -H 'Content-Type: application/x-www-form-urlencoded' \ --data-urlencode 'query=pod_cpu_usage_total' \ --data-urlencode 'start=2025-07-21T16:00:00Z' \ --data-urlencode 'end=2025-07-21T16:15:00Z' \ --data-urlencode 'step=60s' \ --data-urlencode 'location=zone1|zone2' \ -H "Authorization: Bearer $(gdcloud auth print-identity-token \ --audiences=https://GDC_URL)"Di seguito è riportato un esempio di richiesta
curl GET:curl -X GET \ https://GDC_URL/PROJECT_NAME/cortex/metrics/api/v1/query_range?query=pod_cpu_usage_total&start=2025-07-21T16:00:00Z&end=2025-07-21T16:15:00Z&step=1s&location=zone1|zone2" \ -H "Authorization: Bearer $(gdcloud auth print-identity-token \ --audiences=https://GDC_URL)"Dopo il comando, ottieni l'output. La risposta dell'API è in formato JSON.
Query ed etichette di esempio
Puoi eseguire query sulle metriche utilizzando il nome della metrica e le coppie chiave-valore per le etichette. Una query PromQL ha la seguente sintassi:
metric_name{label_one="value", label_two="value"}
Le etichette ti consentono di distinguere le caratteristiche di una metrica. In questo modo, gli autori dei container fanno in modo che i loro workload generino metriche e aggiungano tag per filtrare queste metriche.
Ad esempio, puoi avere una metrica api_http_requests_total per conteggiare il numero di richieste HTTP ricevute. Poi puoi aggiungere un'etichetta request_method a questa metrica, che accetta un valore POST, GET o PUT. Di conseguenza, devi creare tre flussi di metriche per ogni tipo di richiesta che potresti ricevere. In questo
caso, per trovare il numero di richieste HTTP GET, esegui la seguente query:
api_http_requests_total{request_method="GET"}
Per saperne di più su metriche ed etichette, consulta Metriche e denominazione delle etichette.
Di seguito sono riportate alcune delle etichette predefinite aggiunte dalla risorsa personalizzata MonitoringTarget. Puoi utilizzare queste etichette predefinite per eseguire query sulle metriche:
_gdch_service: il nome breve del servizio.cluster: il nome del cluster.container_name: il nome del container all'interno di un pod.namespace_name: lo spazio dei nomi del progetto.pod_name: il prefisso del nome del pod.
La seguente tabella descrive le etichette che Prometheus aggiunge automaticamente:
| Etichetta metrica | Descrizione |
|---|---|
job |
Il nome interno del job di scraping utilizzato per raccogliere la metrica. I job
creati dalla risorsa personalizzata MonitoringTarget hanno un nome
con il seguente pattern:obs-system/OBS_SHADOW_PROJECT_NAME/MONITORINGTARGET_NAME.MONITORINGTARGET_NAMESPACE/I/JI e J sono numeri univoci determinati internamente
per evitare conflitti di nomi. |
instance |
Il $IP:$PORT del servizio sottoposto a scraping. Se una risorsa del workload ha più repliche, utilizza questo campo per distinguerle. |
Il seguente esempio di codice mostra l'utilizzo di coppie chiave-valore per le etichette per eseguire query su diverse metriche per visualizzare l'utilizzo della CPU raccolto in un cluster Kubernetes:
pod_cpu_usage_total{cluster="CLUSTER_NAME"}
Utilizza lo strumento di rietichettatura delle metriche per aggiungere etichette non esposte inizialmente dai
container sottoposti a scraping e rinominare le metriche prodotte. Devi configurare la risorsa personalizzata
MonitoringTarget per aggiungere etichette alle metriche che raccoglie.
Specifica queste etichette nel campo metricsRelabelings della risorsa personalizzata.
Per saperne di più, consulta Metriche delle etichette.
Di seguito è riportato un esempio di risposta ricevuta da un endpoint delle metriche di Cortex:
{
"zone1": {
"status": "success",
"data": {
"resultType": "matrix",
"result": [
{
"metric": {
"__name__": "pod_cpu_usage_total",
"_gdch_project": "project-1",
"cluster": "root-admin",
"container_name": "otel-collector",
"exported_instance": "localhost:2112",
"exported_job": "workload-0",
"ha_cluster": "root-admin-shard1",
"instance": "172.192.1.74:3113",
"job": "metrics-server-exporter.mon-system",
"namespace": "mon-system",
"namespace_name": "mon-system",
"pod": "cortex-0",
"pod_name": "metrics-server-exporter-695c9f848b-swzgq",
"zone_id": "zone1"
},
"values": [
[
1753261200,
"2.258621991"
],
[
1753261800,
"1.029301454"
]
]
}
]
}
},
"zone2": {
"status": "success",
"data": {
"resultType": "matrix",
"result": [
{
"metric": {
"__name__": "pod_cpu_usage_total",
"_gdch_project": "project-1",
"cluster": "root-admin",
"container_name": "otel-collector",
"exported_instance": "localhost:2112",
"exported_job": "workload-0",
"ha_cluster": "root-admin-shard1",
"instance": "172.196.3.208:3113",
"job": "metrics-server-exporter.mon-system",
"namespace": "mon-system",
"namespace_name": "mon-system",
"pod": "cortex-0",
"pod_name": "metrics-server-exporter-695c9f848b-kchfv",
"zone_id": "zone2"
},
"values": [
[
1753261200,
"1.814027424"
],
[
1753261800,
"2.7767060260000003"
]
]
}
]
}
}
}
Esecuzione di query sull'API HTTP
Panoramica del formato
Le risposte dell'API sono formattate in modo coerente in JSON. Le richieste andate a buon fine riceveranno sempre un codice di stato 2xx.
Per le richieste non valide, i gestori API restituiranno un oggetto di errore JSON insieme a uno dei seguenti codici di stato HTTP:
- 400 Bad Request: se i parametri essenziali sono mancanti o forniti in modo errato.
- 503 - Servizio non disponibile: se le query superano il limite di tempo o vengono interrotte.
Tutti i dati raccolti correttamente verranno inclusi nel campo "data" della risposta.
Il formato del contenitore della risposta JSON è il seguente:
{
"status": "success" | "error",
"data": <data>,
// Only set if status is "error". The data field may still hold
// additional data.
"errorType": "<string>",
"error": "<string>",
// Only set if there were warnings while executing the request.
// There will still be data in the data field.
"warnings": ["<string>"],
// Only set if there were info-level annotations while executing the request.
"infos": ["<string>"]
}
Query istantanee
Il seguente endpoint valuta una query istantanea in un singolo momento:
GET /api/v1/query
POST /api/v1/query
Per le query di espressioni Prometheus sono disponibili i seguenti parametri di ricerca URL:
query=<string>: la stringa di query dell'espressione Prometheus.time=<rfc3339 | unix_timestamp>: un timestamp di valutazione facoltativo, specificato come stringa RFC 3339 o timestamp Unix. Se omesso, viene utilizzato l'orario corrente del server.timeout=<duration>: un timeout di valutazione facoltativo. Il valore predefinito è limitato dal valore del flag query.timeout.limit=<number>: Un numero massimo facoltativo di serie da restituire. Tronca le serie per matrici e vettori, ma non influisce su scalari o stringhe. Un valore pari a 0 disabilita questo limite.lookback_delta=<number>: un parametro facoltativo per sostituire il periodo di analisi specificamente per questa query.
Se il parametro time viene omesso, viene utilizzato l'orario attuale del server.
Per le query più grandi che potrebbero superare i limiti di caratteri dell'URL, puoi inviare questi parametri utilizzando il metodo POST. Assicurati che il corpo della richiesta sia codificato come URL e che l'intestazione Content-Type sia impostata su application/x-www-form-urlencoded.
La sezione dei dati del risultato della query ha il seguente formato:
{
"resultType": "matrix" | "vector" | "scalar" | "string",
"result": <value>
}
<value> si riferisce ai dati dei risultati della query, che hanno formati diversi a seconda di resultType.
L'esempio seguente valuta l'espressione fino al momento 2015-07-01T20:10:51.781Z:
curl 'http://localhost:9090/api/v1/query?query=up&time=2015-07-01T20:10:51.781Z'
{
"status" : "success",
"data" : {
"resultType" : "vector",
"result" : [
{
"metric" : {
"__name__" : "up",
"job" : "prometheus",
"instance" : "localhost:9090"
},
"value": [ 1435781451.781, "1" ]
},
{
"metric" : {
"__name__" : "up",
"job" : "node",
"instance" : "localhost:9100"
},
"value" : [ 1435781451.781, "0" ]
}
]
}
}
Query sugli intervalli
Il seguente endpoint valuta una query di espressione in un intervallo di tempo:
GET /api/v1/query_range
POST /api/v1/query_range
Per le query di espressioni Prometheus sono disponibili i seguenti parametri di ricerca URL:
query=<string>: la stringa di query dell'espressione Prometheus.start=<rfc3339 | unix_timestamp>: timestamp di inizio, inclusivo.end=<rfc3339 | unix_timestamp>: timestamp di fine, inclusivo.step=<duration | float>: Larghezza del passaggio di risoluzione della query nel formato della durata o numero in virgola mobile di secondi.timeout=<duration>: un timeout di valutazione facoltativo. Il valore predefinito è limitato dal valore del flag query.timeout.limit=<number>: Un numero massimo facoltativo di serie da restituire. Tronca le serie per matrici e vettori, ma non influisce su scalari o stringhe. Un valore pari a 0 disabilita questo limite.lookback_delta=<number>: un parametro facoltativo per sostituire il periodo di analisi specificamente per questa query.
Per le query più grandi che potrebbero superare i limiti di caratteri dell'URL, puoi inviare questi parametri utilizzando il metodo POST. Assicurati che il corpo della richiesta sia codificato come URL e che l'intestazione Content-Type sia impostata su application/x-www-form-urlencoded.
La sezione dei dati del risultato della query ha il seguente formato:
{
"resultType": "matrix",
"result": <value>
}
L'esempio seguente valuta l'espressione up in un intervallo di 30 secondi con una risoluzione della query di 15 secondi.
curl 'http://localhost:9090/api/v1/query_range?query=up&start=2015-07-01T20:10:30.781Z&end=2015-07-01T20:11:00.781Z&step=15s'
{
"status" : "success",
"data" : {
"resultType" : "matrix",
"result" : [
{
"metric" : {
"__name__" : "up",
"job" : "prometheus",
"instance" : "localhost:9090"
},
"values" : [
[ 1435781430.781, "1" ],
[ 1435781445.781, "1" ],
[ 1435781460.781, "1" ]
]
},
{
"metric" : {
"__name__" : "up",
"job" : "node",
"instance" : "localhost:9091"
},
"values" : [
[ 1435781430.781, "0" ],
[ 1435781445.781, "0" ],
[ 1435781460.781, "1" ]
]
}
]
}
}
Nomenclatura delle metriche e delle etichette
Linee guida per la denominazione delle metriche
Quando definisci i nomi delle metriche, tieni presente i seguenti principi:
Il nome di una metrica DOVREBBE includere un prefisso dell'applicazione di una sola parola, a cui le librerie client a volte fanno riferimento come "spazio dei nomi". Questo prefisso identifica il dominio a cui appartiene la metrica. Per le metriche specifiche per le applicazioni, in genere viene utilizzato il nome dell'applicazione come prefisso.
Esempi:
- prometheus_notifications_total (specifica per il server Prometheus)
- process_cpu_seconds_total (esportato da molte librerie client)
- http_request_duration_seconds (per tutte le richieste HTTP)
Il nome di una metrica DEVE rappresentare una singola unità (ad esempio, evita di combinare secondi con millisecondi o secondi con byte).
Il nome di una metrica DEVE utilizzare unità di base (ad es. secondi, byte, metri) anziché unità derivate (ad es. millisecondi, megabyte, chilometri).
Il nome di una metrica DEVE includere un suffisso di unità plurale. Per i conteggi cumulativi, il suffisso "totale" deve essere utilizzato in aggiunta al suffisso dell'unità, se applicabile.
Esempi:
- http_request_duration_seconds
- node_memory_usage_bytes
- http_requests_total (per un conteggio cumulativo senza unità)
- process_cpu_seconds_total (per un conteggio cumulativo con unità)
- foobar_build_info (per una pseudo-metrica che fornisce metadati sul binario in esecuzione)
Un nome di metrica PUÒ ordinare i suoi componenti per facilitare il raggruppamento quando vengono ordinati in ordine lessicografico, a condizione che vengano seguite tutte le altre regole. Le metriche correlate spesso hanno componenti di nome comuni posizionati per primi per garantire che vengano ordinate insieme.
Esempi:
- prometheus_tsdb_head_truncations_closed_total
- prometheus_tsdb_head_truncations_established_total
- prometheus_tsdb_head_truncations_failed_total
- prometheus_tsdb_head_truncations_total
Il nome di una metrica DEVE rappresentare in modo coerente la stessa "cosa da misurare" logica in tutte le dimensioni delle etichette.
Esempi:
- durata della richiesta
- byte di trasferimento dei dati
- utilizzo istantaneo delle risorse in percentuale
Linee guida per la denominazione delle etichette
Quando misuri qualcosa, utilizza le etichette per distinguere le sue caratteristiche. Ad esempio:
- Per le richieste HTTP API totali (
api_http_requests_total), differenzia per tipo di operazione, ad esempiocreate,update,delete(tipi di richieste:operation="create|update|delete"). - Per la durata della richiesta API in secondi (
api_request_duration_seconds), differenzia per fase della richiesta, ad esempioextract,transform,load(fasi della richiesta:stage="extract|transform|load").
Evita di includere i nomi delle etichette nel nome della metrica, in quanto ciò crea ridondanza e può generare confusione se queste etichette vengono aggregate in un secondo momento.