
Objectifs
Ce tutoriel vous montre comment installer le composant Jupyter de Managed Service for Apache Spark sur un nouveau cluster, puis vous connecter à l'interface utilisateur du notebook Jupyter s'exécutant sur le cluster à partir du navigateur local en utilisant la passerelle des composants Managed Service for Apache Spark.
Coûts
Dans ce document, vous utilisez les composants facturables suivants de Google Cloud :
Pour obtenir une estimation des coûts en fonction de votre utilisation prévue, utilisez le simulateur de coût.
Avant de commencer
Si ce n'est pas déjà fait, créez un projet Google Cloud et un bucket Cloud Storage.
Configurer le projet
- Connectez-vous à votre compte Google Cloud . Si vous débutez sur Google Cloud, créez un compte pour évaluer les performances de nos produits en conditions réelles. Les nouveaux clients bénéficient également de 300 $de crédits sans frais pour exécuter, tester et déployer des charges de travail.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc, Compute Engine, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
Installez la Google Cloud CLI.
-
Si vous utilisez un fournisseur d'identité (IdP) externe, vous devez d'abord vous connecter à la gcloud CLI avec votre identité fédérée.
-
Pour initialiser la gcloud CLI, exécutez la commande suivante :
gcloud init -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc, Compute Engine, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
Installez la Google Cloud CLI.
-
Si vous utilisez un fournisseur d'identité (IdP) externe, vous devez d'abord vous connecter à la gcloud CLI avec votre identité fédérée.
-
Pour initialiser la gcloud CLI, exécutez la commande suivante :
gcloud init
Créez un bucket Cloud Storage dans votre projet pour stocker les notebooks que vous créez dans ce tutoriel.
- Dans la console Google Cloud , accédez à la page Buckets Cloud Storage.
- Cliquez sur Créer.
- Sur la page Créer un bucket, saisissez les informations concernant votre bucket. Pour passer à l'étape suivante, cliquez sur Continuer.
-
Dans la section Premiers pas, procédez comme suit :
- Saisissez un nom unique qui répond aux exigences relatives aux noms des buckets.
- Pour ajouter une étiquette de bucket, développez la section Étiquettes (), cliquez sur add_box
Ajouter une étiquette, puis spécifiez un élément
keyetvaluepour votre étiquette.
-
Dans la section Choisir l'emplacement de stockage de vos données, procédez comme suit :
- Sélectionnez un type d'emplacement.
- Choisissez un emplacement où les données de votre bucket seront stockées de manière permanente dans le menu déroulant Type d'emplacement.
- Si vous sélectionnez le type d'emplacement birégional, vous pouvez également choisir d'activer la réplication turbo à l'aide de la case à cocher correspondante.
- Pour configurer la réplication entre buckets, sélectionnez Ajouter une réplication entre buckets via le service de transfert de stockage et suivez ces étapes :
Configurer la réplication entre buckets
- Dans le menu Bucket, sélectionnez un bucket.
Dans la section Paramètres de réplication, cliquez sur Configurer pour configurer les paramètres du job de réplication.
Le volet Configurer la réplication entre buckets s'affiche.
- Pour filtrer les objets à répliquer en fonction du préfixe de leur nom, saisissez le préfixe avec lequel vous souhaitez inclure ou exclure des objets, puis cliquez sur Ajouter un préfixe.
- Pour définir une classe de stockage pour les objets répliqués, sélectionnez-en une dans le menu Classe de stockage. Si vous ignorez cette étape, les objets répliqués utiliseront la classe de stockage par défaut du bucket de destination.
- Cliquez sur OK.
-
Dans la section Choisir comment stocker vos données, procédez comme suit :
- Sélectionnez une classe de stockage par défaut pour le bucket ou classe automatique pour gérer automatiquement les classes de stockage des données de votre bucket.
- Pour activer l'espace de noms hiérarchique, dans la section Optimiser l'espace de stockage pour les charges de travail utilisant beaucoup de données, sélectionnez Activer l'espace de noms hiérarchique sur ce bucket.
- Dans la section Choisir comment contrôler l'accès aux objets, indiquez si votre bucket applique ou non la protection contre l'accès public et sélectionnez une méthode de contrôle des accès pour les objets de votre bucket.
-
Dans la section Choisir comment protéger les données d'objet, procédez comme suit :
- Sous Protection des données, sélectionnez les options que vous souhaitez définir pour votre bucket.
- Pour activer la suppression réversible, cochez la case Règle de suppression réversible (pour la récupération de données), puis spécifiez le nombre de jours pendant lesquels vous souhaitez conserver les objets après leur suppression.
- Pour configurer la gestion des versions d'objets, cochez la case Gestion des versions des objets (pour le contrôle des versions), puis spécifiez le nombre maximal de versions par objet et le nombre de jours après lesquels les versions obsolètes expirent.
- Pour activer la règle de conservation sur les objets et les buckets, cochez la case Conservation (pour la conformité), puis procédez comme suit :
- Pour activer le verrou de conservation des objets, cochez la case Activer la conservation des objets.
- Pour activer le verrou de bucket, cochez la case Définir une règle de conservation du bucket, puis choisissez une unité de temps et une durée pour votre période de conservation.
- Pour choisir comment vos données d'objet seront chiffrées, développez la section Chiffrement des données (), puis sélectionnez une méthode de chiffrement des données.
- Sous Protection des données, sélectionnez les options que vous souhaitez définir pour votre bucket.
-
Dans la section Premiers pas, procédez comme suit :
- Cliquez sur Créer. Vos notebooks seront enregistrés dans Cloud Storage sous
gs://bucket-name/notebooks/jupyter.
Créer un cluster et installer le composant Jupyter
Créez un cluster avec le composant Jupyter installé.
Ouvrir les interfaces utilisateur Jupyter et JupyterLab
Cliquez sur les liens de la passerelle des composants de la consoleGoogle Cloud dans la console Google Cloud pour ouvrir les interfaces utilisateur du notebook Jupyter ou JupyterLab exécutées sur le nœud maître de votre cluster.
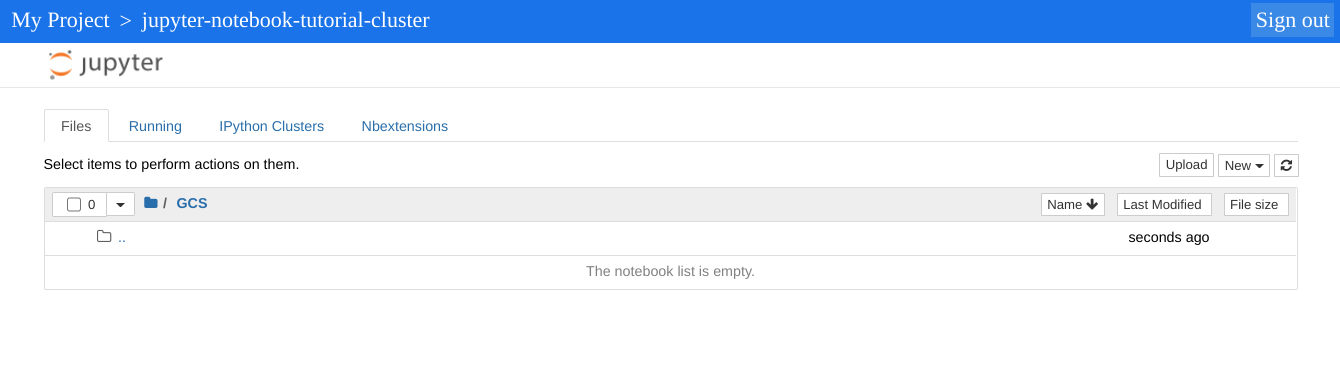
Le répertoire de premier niveau affiché par votre instance Jupyter est un répertoire virtuel qui vous permet de voir le contenu de votre bucket Cloud Storage ou de votre système de fichiers local. Vous pouvez choisir l'un ou l'autre emplacement en cliquant sur le lien GCS pour Cloud Storage ou sur Disque local pour le système de fichiers local du nœud maître de votre cluster.
- Cliquez sur le lien GCS. L'interface utilisateur Web du notebook Jupyter affiche les notebooks stockés dans votre bucket Cloud Storage, y compris ceux que vous créez dans ce tutoriel.
Effectuer un nettoyage
Une fois le tutoriel terminé, vous pouvez procéder au nettoyage des ressources que vous avez créées afin qu'elles ne soient plus comptabilisées dans votre quota et qu'elles ne vous soient plus facturées. Dans les sections suivantes, nous allons voir comment supprimer ou désactiver ces ressources.
Supprimer le projet
Le moyen le plus simple d'empêcher la facturation est de supprimer le projet que vous avez créé pour ce tutoriel.
Pour supprimer le projet :
- Dans la console Google Cloud , accédez à la page Gérer les ressources.
- Dans la liste des projets, sélectionnez le projet que vous souhaitez supprimer, puis cliquez sur Supprimer.
- Dans la boîte de dialogue, saisissez l'ID du projet, puis cliquez sur Arrêter pour supprimer le projet.
Supprimer le cluster
- Pour supprimer le cluster :
gcloud dataproc clusters delete cluster-name \ --region=${REGION}
Supprimer le bucket
- Pour supprimer le bucket Cloud Storage créé à l'étape 2 Avant de commencer, y compris les notebooks stockés dans le bucket :
gcloud storage rm gs://${BUCKET_NAME} --recursive