
Vous pouvez créer un cluster Managed Service pour Apache Spark avec une image personnalisée incluant vos packages préinstallés. Cette page vous explique comment créer une image personnalisée et l'installer sur un cluster Managed Service pour Apache Spark.
Remarques et limites concernant l'utilisation
Durée de vie des images personnalisées : pour que les clusters reçoivent les dernières mises à jour de service et corrections de bugs, la création de clusters avec une image personnalisée est limitée à 365 jours à compter de la date de création de l'image personnalisée. Notez que les clusters existants créés avec une image personnalisée peuvent s'exécuter indéfiniment.
Vous devrez peut-être utiliser l'automatisation si vous souhaitez créer des clusters avec une image personnalisée spécifique pendant plus de 365 jours. Pour en savoir plus, consultez Créer un cluster avec une image personnalisée expirée.
Linux uniquement : les instructions de ce document ne s'appliquent qu'aux systèmes d'exploitation Linux. D'autres systèmes d'exploitation pourraient être compatibles dans les prochaines versions de Managed Service pour Apache Spark.
Images de base compatibles : les compilations d'images personnalisées nécessitent de partir d'une image de base Managed Service pour Apache Spark. Les images de base suivantes sont compatibles : Debian, Rocky Linux et Ubuntu.
- Disponibilité des images de base : les nouvelles images annoncées dans les notes de version de Managed Service pour Apache Spark ne sont disponibles en tant que base pour les images personnalisées qu'une semaine après leur date d'annonce.
Utiliser des composants facultatifs :
Images de base
2.2et antérieures : par défaut, tous les composants facultatifs de Managed Service pour Apache Spark (packages et configurations OS) sont installés sur l'image personnalisée. Vous pouvez personnaliser les versions et les configurations des packages OS.Images de base
2.3et ultérieures : seuls les composants facultatifs sélectionnés sont installés sur l'image personnalisée (voir l'indicateurgenerate_custom_image.py--optional-components).
Quelle que soit l'image de base utilisée pour votre image personnalisée, lorsque vous créez votre cluster, vous devez lister ou sélectionner les composants facultatifs.
Exemple : commande Google Cloud CLI pour la création d'un cluster :
gcloud dataproc clusters create CLUSTER_NAME --image=CUSTOM_IMAGE_URI \ --optional-components=COMPONENT_NAME \ ... other flags
Si le nom du composant n'est pas spécifié lors de la création du cluster, le composant facultatif, y compris les packages et configurations d'OS personnalisés, est supprimé.
Utiliser des images personnalisées hébergées : si vous utilisez une image personnalisée hébergée dans un autre projet, le compte de service de l'agent de service Managed Service pour Apache Spark dans votre projet doit disposer de l'autorisation
compute.images.getsur l'image du projet hôte. Pour ce faire, attribuez le rôleroles/compute.imageUsersur l'image hébergée au compte de service de l'agent de service Managed Service pour Apache Spark de votre projet (consultez la section Partager des images personnalisées au sein d'une organisation).Utiliser les secrets MOK (Machine Owner Key) du démarrage sécurisé : pour activer le démarrage sécurisé avec votre image personnalisée Managed Service pour Apache Spark, procédez comme suit :
Activez l'API Secret Manager (
secretmanager.googleapis.com). Managed Service pour Apache Spark génère et gère une paire de clés à l'aide du service Secret Manager.Ajoutez le flag
--service-account="SERVICE_ACCOUNT"à la commandegenerate_custom_image.pylorsque vous générez une image personnalisée. Remarque : Vous devez attribuer au compte de service le rôle Lecteur Secret Manager (roles/secretmanager.viewer) sur le projet et le rôle Accesseur Secret Manager (roles/secretmanager.secretAccessor) sur les secrets publics et privés.Pour en savoir plus et obtenir des exemples, consultez
README.mdet les autres fichiers du répertoire examples/secure-boot du dépôtGoogleCloudDataproc/custom-imagessur GitHub.Pour désactiver le démarrage sécurisé : par défaut, les scripts d'image personnalisée Managed Service pour Apache Spark génèrent et gèrent une paire de clés à l'aide de Secret Manager lorsqu'ils sont exécutés à partir d'un cluster Managed Service pour Apache Spark. Si vous ne souhaitez pas utiliser le démarrage sécurisé avec votre image personnalisée, incluez
--trusted-cert=""(valeur d'indicateur vide) dans la commandegenerate_custom_image.pylorsque vous générez votre image personnalisée.
Avant de commencer
Assurez-vous de configurer votre projet avant de générer votre image personnalisée.
Configurer votre projet
- Connectez-vous à votre compte Google Cloud . Si vous débutez sur Google Cloud, créez un compte pour évaluer les performances de nos produits en conditions réelles. Les nouveaux clients bénéficient également de 300 $ de crédits sans frais pour exécuter, tester et déployer des charges de travail.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc API, Compute Engine API, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
Installez la Google Cloud CLI.
-
Si vous utilisez un fournisseur d'identité (IdP) externe, vous devez d'abord vous connecter à la gcloud CLI avec votre identité fédérée.
-
Pour initialiser la gcloud CLI, exécutez la commande suivante :
gcloud init -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc API, Compute Engine API, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
Installez la Google Cloud CLI.
-
Si vous utilisez un fournisseur d'identité (IdP) externe, vous devez d'abord vous connecter à la gcloud CLI avec votre identité fédérée.
-
Pour initialiser la gcloud CLI, exécutez la commande suivante :
gcloud init - Installez Python 3.11 ou version ultérieure.
- Préparez un script de personnalisation qui installe des packages personnalisés et/ou met à jour les configurations, par exemple :
#! /usr/bin/bash apt-get -y update apt-get install python-dev apt-get install python-pip pip install numpy
Créer un bucket Cloud Storage dans votre projet
- Dans la console Google Cloud , accédez à la page Buckets de Cloud Storage.
- Cliquez sur Créer.
- Sur la page Créer un bucket, saisissez les informations concernant votre bucket. Pour passer à l'étape suivante, cliquez sur Continuer.
-
Dans la section Premiers pas, procédez comme suit :
- Saisissez un nom unique qui répond aux exigences relatives aux noms des buckets.
- Pour ajouter une étiquette de bucket, développez la section Étiquettes (), cliquez sur add_box
Ajouter une étiquette, puis spécifiez un élément
keyetvaluepour votre étiquette.
-
Dans la section Choisir l'emplacement de stockage de vos données, procédez comme suit :
- Sélectionnez un type d'emplacement.
- Choisissez un emplacement où les données de votre bucket seront stockées de manière permanente dans le menu déroulant Type d'emplacement.
- Si vous sélectionnez le type d'emplacement birégional, vous pouvez également choisir d'activer la réplication turbo à l'aide de la case à cocher correspondante.
- Pour configurer la réplication entre buckets, sélectionnez Ajouter une réplication entre buckets via le service de transfert de stockage et suivez ces étapes :
Configurer la réplication entre buckets
- Dans le menu Bucket, sélectionnez un bucket.
Dans la section Paramètres de réplication, cliquez sur Configurer pour configurer les paramètres du job de réplication.
Le volet Configurer la réplication entre buckets s'affiche.
- Pour filtrer les objets à répliquer en fonction du préfixe de leur nom, saisissez le préfixe avec lequel vous souhaitez inclure ou exclure des objets, puis cliquez sur Ajouter un préfixe.
- Pour définir une classe de stockage pour les objets répliqués, sélectionnez-en une dans le menu Classe de stockage. Si vous ignorez cette étape, les objets répliqués utiliseront la classe de stockage par défaut du bucket de destination.
- Cliquez sur OK.
-
Dans la section Choisir comment stocker vos données, procédez comme suit :
- Sélectionnez une classe de stockage par défaut pour le bucket ou classe automatique pour gérer automatiquement les classes de stockage des données de votre bucket.
- Pour activer l'espace de noms hiérarchique, dans la section Optimiser l'espace de stockage pour les charges de travail utilisant beaucoup de données, sélectionnez Activer l'espace de noms hiérarchique sur ce bucket.
- Dans la section Choisir comment contrôler l'accès aux objets, indiquez si votre bucket applique ou non la protection contre l'accès public et sélectionnez une méthode de contrôle des accès pour les objets de votre bucket.
-
Dans la section Choisir comment protéger les données d'objet, procédez comme suit :
- Sous Protection des données, sélectionnez les options que vous souhaitez définir pour votre bucket.
- Pour activer la suppression réversible, cochez la case Règle de suppression réversible (pour la récupération de données), puis spécifiez le nombre de jours pendant lesquels vous souhaitez conserver les objets après leur suppression.
- Pour configurer la gestion des versions d'objets, cochez la case Gestion des versions des objets (pour le contrôle des versions), puis spécifiez le nombre maximal de versions par objet et le nombre de jours après lesquels les versions obsolètes expirent.
- Pour activer la règle de conservation sur les objets et les buckets, cochez la case Conservation (pour la conformité), puis procédez comme suit :
- Pour activer le verrou de conservation des objets, cochez la case Activer la conservation des objets.
- Pour activer le verrou de bucket, cochez la case Définir une règle de conservation du bucket, puis choisissez une unité de temps et une durée pour votre période de conservation.
- Pour choisir comment vos données d'objet seront chiffrées, développez la section Chiffrement des données , puis sélectionnez une méthode de chiffrement des données.
- Sous Protection des données, sélectionnez les options que vous souhaitez définir pour votre bucket.
-
Dans la section Premiers pas, procédez comme suit :
- Cliquez sur Créer.
Générer une image personnalisée
Pour créer une image personnalisée Managed Service pour Apache Spark, vous allez utiliser generate_custom_image.py, un programme Python.
Fonctionnement
Le programme generate_custom_image.py lance une instance de VM Compute Engine temporaire avec l'image de base Managed Service for Apache Spark spécifiée, puis exécute le script de personnalisation dans l'instance de VM pour installer des packages personnalisés et/ou mettre à jour les configurations. Une fois le script de personnalisation terminé, il arrête l'instance de VM et crée une image personnalisée Managed Service for Apache Spark à partir du disque de l'instance de VM. La VM temporaire est supprimée après la création de l'image personnalisée. L'image personnalisée est enregistrée et peut être utilisée pour créer des clusters Managed Service pour Apache Spark.
Le programme generate_custom_image.py utilise gcloud CLI pour exécuter des workflows en plusieurs étapes sur Compute Engine.
Exécuter le code
Divisez ou clonez les fichiers sur GitHub dans Images personnalisées Managed Service pour Apache Spark.
Exécutez ensuite le script generate_custom_image.py pour que Managed Service pour Apache Spark génère et enregistre votre image personnalisée.
python3 generate_custom_image.py \ --image-name=CUSTOM_IMAGE_NAME \ [--family=CUSTOM_IMAGE_FAMILY_NAME] \ --dataproc-version=IMAGE_VERSION \ --customization-script=LOCAL_PATH \ --zone=ZONE \ --gcs-bucket=gs://BUCKET_NAME \ [--no-smoke-test]
Indicateurs requis
--image-name: nom de sortie de votre image personnalisée.--dataproc-version: version de l'image Managed Service pour Apache Spark à utiliser dans votre image personnalisée. Spécifiez la version au formatx.y.z-osoux.y.z-rc-os, par exemple "2.0.69-debian10".--customization-script: chemin d'accès local au script que l'outil exécutera pour installer vos packages personnalisés ou effectuer d'autres personnalisations. Ce script est exécuté en tant que script de démarrage Linux uniquement sur la VM temporaire permettant de créer l'image personnalisée. Vous pouvez spécifier un script d'initialisation différent pour les autres actions d'initialisation que vous souhaitez effectuer lorsque vous créez un cluster avec votre image personnalisée.Images inter-projets : si votre image personnalisée est utilisée pour créer des clusters dans différents projets, une erreur peut se produire en raison du cache de commandes
gcloudougsutilstocké dans l'image. Pour éviter ce problème, incluez la commande suivante dans votre script de personnalisation afin d'effacer les identifiants mis en cache.rm -r /root/.gsutil /root/.config/gcloud
--zone: zone Compute Engine oùgenerate_custom_image.pyva créer une VM temporaire à utiliser pour créer votre image personnalisée.--gcs-bucket: URI, au formatgs://BUCKET_NAME, qui pointe vers votre bucket Cloud Storage.generate_custom_image.pyécrit des fichiers journaux dans ce bucket.
--family: famille de l'image personnalisée. Les familles d'images permettent de regrouper des images similaires et peuvent être utilisées lors de la création d'un cluster en tant que pointeur vers l'image la plus récente de la famille. Exemple :custom-2-2-debian12--no-smoke-test: option facultative qui désactive le test de confiance de l'image personnalisée nouvellement créée. Le test de confiance crée un cluster de test Managed Service pour Apache Spark avec l'image nouvellement créée, exécute un petit job, puis supprime le cluster à la fin du test. Le test de confiance s'exécute par défaut pour vérifier que l'image personnalisée nouvellement créée est en mesure de créer un cluster Managed Service pour Apache Spark fonctionnel. La désactivation de cette étape à l'aide de l'option--no-smoke-testaccélère le processus de compilation d'image personnalisée, mais son utilisation n'est pas recommandée.--subnet: sous-réseau à utiliser pour créer la VM qui crée l'image Managed Service pour Apache Spark personnalisée. Si votre projet fait partie d'un VPC partagé, vous devez spécifier l'URL complète du sous-réseau au format suivant :projects/HOST_PROJECT_ID/regions/REGION/subnetworks/SUBNET.--optional-components: ce flag n'est disponible que lorsque vous utilisez les versions2.3et ultérieures de l'image de base. Liste des composants facultatifs à installer dans l'image, tels que SOLR, RANGER, TRINO, DOCKER, FLINK, HIVE_WEBHCAT, ZEPPELIN, HUDI, ICEBERG et PIG (PIG est disponible en tant que composant facultatif dans les versions d'image2.3et ultérieures).Exemple : commande Google Cloud CLI pour créer un cluster :
gcloud dataproc clusters create CLUSTER_NAME --image=CUSTOM_IMAGE_URI \ --optional-components=COMPONENT_NAME \ ... other flags
Pour obtenir la liste des options facultatives disponibles, consultez la section Arguments facultatifs sur GitHub.
Si generate_custom_image.py réussit, le imageURI de l'image personnalisée s'affiche dans le résultat de la fenêtre du terminal (le imageUri complet est affiché en gras ci-dessous) :
...
managedCluster:
clusterName: verify-image-20180614213641-8308a4cd
config:
gceClusterConfig:
zoneUri: ZONE
masterConfig:
imageUri: **https://www.googleapis.com/compute/beta/projects/PROJECT_ID/global/images/CUSTOM_IMAGE_NAME**
...
INFO:__main__:Successfully built Dataproc custom image: CUSTOM_IMAGE_NAME
INFO:__main__:
#####################################################################
WARNING: DATAPROC CUSTOM IMAGE 'CUSTOM_IMAGE_NAME'
WILL EXPIRE ON 2018-07-14 21:35:44.133000.
#####################################################################
Libellés des versions d'images personnalisées (utilisation avancée)
Lorsque vous utilisez l'outil standard de création d'image personnalisée de Managed Service pour Apache Spark, un libellé goog-dataproc-version est défini sur l'image personnalisée créée. Le libellé reflète les fonctionnalités et les protocoles de la caractéristique utilisés par Managed Service pour Apache Spark pour gérer le logiciel sur l'image.
Utilisation avancée : si vous utilisez votre propre processus pour créer une image Managed Service pour Apache Spark personnalisée, vous devez ajouter manuellement le libellé goog-dataproc-version à votre image personnalisée, comme suit :
Extrayez le libellé
goog-dataproc-versionde l'image Managed Service pour Apache Spark de base utilisée pour créer l'image personnalisée.gcloud compute images describe ${BASE_DATAPROC_IMAGE} \ --project cloud-dataproc \ --format="value(labels.goog-dataproc-version)"Définissez le libellé sur l'image personnalisée.
gcloud compute images add-labels IMAGE_NAME --labels=[KEY=VALUE,...]
Utiliser une image personnalisée
Vous spécifiez l'image personnalisée lorsque vous créez un cluster Managed Service pour Apache Spark. Une image personnalisée est enregistrée dans les Images Cloud Compute. Elle permet de créer un cluster Managed Service pour Apache Spark pendant 365 jours à compter de sa date de création (consultez la section Créer un cluster avec une image personnalisée arrivée à expiration si vous souhaitez utiliser une image personnalisée au-delà de cette période de 365 jours).
URI de l'image personnalisée
Vous transmettez l'URI de l'image personnalisée imageUri à l'opération de création de cluster.
Cet URI peut être spécifié de l'une des trois manières suivantes :
- URI complet :
https://www.googleapis.com/compute/beta/projects/PROJECT_ID/global/images/`gs://`BUCKET_NAME` - URI partiel :
projects/PROJECT_ID/global/images/CUSTOM_IMAGE_NAME - Nom abrégé : CUSTOM_IMAGE_NAME
Les images personnalisées peuvent également être spécifiées par leur URI de famille, qui choisit toujours l'image la plus récente de la famille d'images.
- URI complet :
https://www.googleapis.com/compute/beta/projects/PROJECT_ID/global/images/family/CUSTOM_IMAGE_FAMILY_NAME/var> - URI partiel :
projects/PROJECT_ID/global/images/family/CUSTOM_IMAGE_FAMILY_NAME
Trouver l'URI de l'image personnalisée
Google Cloud CLI
Exécutez la commande suivante pour lister les noms de vos images personnalisées.
gcloud compute images list
Transmettez le nom de votre image personnalisée à la commande suivante pour répertorier l'URI (selfLink) de votre image personnalisée.
gcloud compute images describe custom-image-name
Extrait de sortie :
... name: CUSTOM_IMAGE_NAME selfLink: https://www.googleapis.com/compute/v1/projects/PROJECT_ID/global/images/CUSTOM_IMAGE_NAME ...
ConsoleGoogle Cloud
- Ouvrez la page Compute Engine → Images dans la console Google Cloud , puis cliquez sur le nom de l'image.
Vous pouvez insérer une requête dans le champ
filter imagespour limiter le nombre d'images affichées.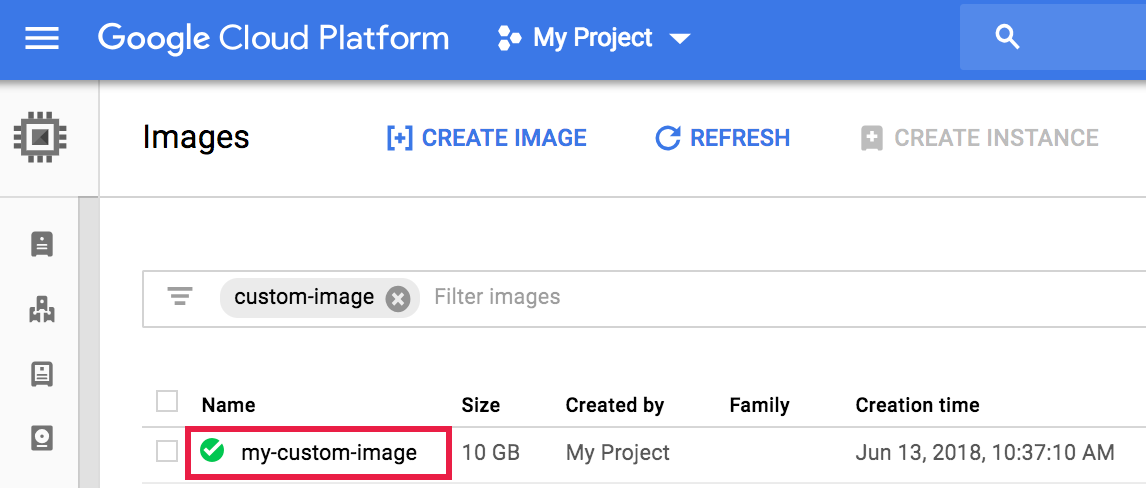
- La page Détails des images s'ouvre. Cliquez sur Équivalent REST.
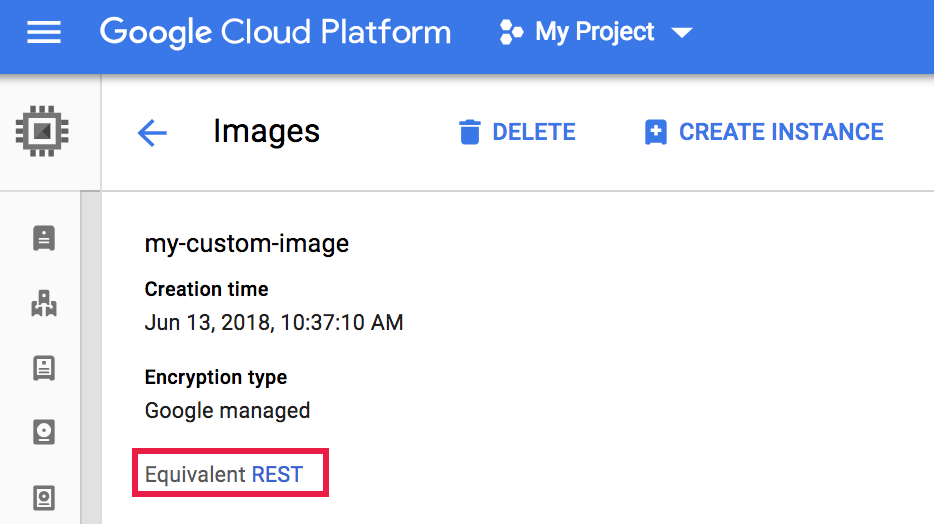
- La réponse REST répertorie des informations supplémentaires sur l'image, y compris
selfLink, qui est l'URI de l'image.{ ... "name": "my-custom-image", "selfLink": "projects/PROJECT_ID/global/images/CUSTOM_IMAGE_NAME", "sourceDisk": ..., ... }
Créer un cluster avec une image personnalisée
Créez un cluster à l'aide de la gcloud CLI, de l'API Dataproc ou de la consoleGoogle Cloud .
ConsoleGoogle Cloud
- Ouvrez la page Créer un cluster.
- Dans la section Définir votre cluster, cliquez sur Type et version de l'image, sélectionnez Image personnalisée, puis confirmez ou modifiez le projet et sélectionnez une image personnalisée disponible.
gcloud CLI
Créez un cluster Managed Service pour Apache Spark avec une image personnalisée à l'aide de la commande dataproc clusters create et de l'option --image.
gcloud dataproc clusters create CLUSTER-NAME \ --image=CUSTOM_IMAGE_URI \ --region=REGION \ ... other flags
API REST
Créez un cluster avec une image personnalisée en spécifiant un URI d'image personnalisé dans le champ InstanceGroupConfig.imageUri des objets masterConfig, workerConfig et, le cas échéant, secondaryWorkerConfig inclus dans une requête d'API cluster.create.
Exemple : Requête REST permettant de créer un cluster Managed Service pour Apache Spark standard (un nœud maître, deux nœuds de calcul) avec une image personnalisée.
POST /v1/projects/PROJECT_ID/regions/REGION/clusters/
{
"clusterName": "CLUSTER_NAME",
"config": {
"masterConfig": {
"imageUri": "projects/PROJECT_ID/global/images/CUSTOM_IMAGE_NAME"
},
"workerConfig": {
"imageUri": "projects/PROJECT_ID/global/images/CUSTOM_IMAGE_NAME"
}
}
}
Remplacer les propriétés du cluster Managed Service pour Apache Spark par une image personnalisée
Vous pouvez utiliser des images personnalisées pour écraser les propriétés de cluster définies lors de la création du cluster. Si vous créez un cluster avec une image personnalisée et que l'opération de création de cluster définit des propriétés avec des valeurs différentes de celles définies par votre image personnalisée, les valeurs de propriété définies par votre image personnalisée seront prioritaires.
Pour définir les propriétés de cluster avec votre image personnalisée :
Dans votre script de personnalisation d'image personnalisée, créez un fichier
dataproc.custom.propertiesdans/etc/google-dataproc, puis définissez les valeurs de propriété du cluster dans le fichier.- Exemple de fichier
dataproc.custom.properties:
dataproc.conscrypt.provider.enable=VALUE dataproc.logging.stackdriver.enable=VALUE
- Exemple d'extrait de fichier de création de script de personnalisation pour remplacer deux propriétés de cluster :
cat <<EOF >/etc/google-managed-spark/dataproc.custom.properties dataproc.conscrypt.provider.enable=true dataproc.logging.stackdriver.enable=false EOF
- Exemple de fichier
Créer un cluster avec une image personnalisée arrivée à expiration
Par défaut, les images personnalisées expirent 365 jours après leur date de création. Pour créer un cluster utilisant une image personnalisée arrivée à expiration, procédez comme suit :
Essayez de créer un cluster Managed Service pour Apache Spark avec une image personnalisée arrivée à expiration, ou qui expirera dans 10 jours.
gcloud dataproc clusters create CLUSTER-NAME \ --image=CUSTOM-IMAGE-NAME \ --region=REGION \ ... other flags
La gcloud CLI émet un message d'erreur incluant le nom de la propriété
dataproc:dataproc.custom.image.expiration.tokendu cluster et la valeur du jeton.
dataproc:dataproc.custom.image.expiration.token=TOKEN_VALUE
Copiez la chaîne TOKEN_VALUE dans le presse-papiers.
Utilisez gcloud CLI pour créer de nouveau le cluster Managed Service pour Apache Spark, en ajoutant le TOKEN_VALUE copié en tant que propriété de cluster.
gcloud dataproc clusters create CLUSTER-NAME \ --image=CUSTOM-IMAGE-NAME \ --properties=dataproc:dataproc.custom.image.expiration.token=TOKEN_VALUE \ --region=REGION \ ... other flags
La création du cluster avec l'image personnalisée devrait réussir.