
您可以将用户标签应用于 Managed Service for Apache Spark 集群和作业,从而对这些资源进行分组,以便稍后进行过滤和列出。您可以在创建资源时(在创建集群或提交作业时)将标签与资源进行关联。一旦资源与标签进行关联,标签即会传播到对资源执行的操作(集群创建、更新、修补或删除;作业提交、更新、取消或删除),可让您通过标签过滤和列出集群、作业和操作。
您还可以向与集群资源(例如虚拟机实例和磁盘)关联的 Compute Engine 资源添加标签。
什么是标签?
标签是一种键值对,可分配给 Managed Service for Apache Spark 集群和作业。 它们可以帮助您按照所需的粒度大规模组织这些资源并管理费用。您可以将标签附加到各项资源,然后根据其标签对资源进行过滤。标签的相关信息会转发到结算系统,以便您按标签细分结算费用。使用内置的结算报告,您可以按资源标签对费用进行过滤和分组。您还可以使用标签查询结算数据导出。
标签要求
应用于资源的标签必须符合以下要求:
- 每个集群或作业最多可以有 32 个标签。
- 每个标签都必须采用键值对形式。
- 键至少包含 1 个字符,最多包含 63 个字符,且不能为空。值可以为空,且最多包含 63 个字符。
- 键和值只能包含小写字母、数字字符、下划线和短划线。所有字符必须使用 UTF-8 编码,允许使用国际字符。 键必须以小写字母或国际字符开头。
- 标签的键部分在单个资源内必须是唯一的。不过,您可以将同一个键用于多个资源。
这些限制适用于每个标签的键和值,以及带有标签的各个 Managed Service for Apache Spark 集群或作业。您可以对一个项目的所有资源应用任意数量的标签。
标签的常见用途
以下是标签的一些常见使用场景:
团队或费用中心标签:根据团队或 费用中心添加标签,以区分不同 团队(例如
team:research和team:analytics)所拥有的 Managed Service for Apache Spark 集群和作业。这种 标签可用于费用核算或预算。组件标签:例如
component:redis、component:frontend、component:ingest和component:dashboard。环境或阶段标签:例如
environment:production和environment:test。状态标签:例如
state:active、state:readytodelete、state:archive。所有权标签:用于标识负责运营的团队,例如:
team:shopping-cart。
我们不建议创建大量唯一标签,例如为每个 API 调用的时间戳或个别值创建标签。这种方法的问题在于,当值经常变化或键导致目录杂乱时,很难有效地过滤和报告资源。
标签和标记
标签可用作资源可查询的注释,但不能用于设置政策的条件。通过对政策进行精细控制,标记提供了一种有条件地允许或拒绝政策的方法,具体取决于资源是否具有特定的标记。如需了解详情,请参阅 标记概览。
创建和使用 Managed Service for Apache Spark 标签
gcloud 命令
您可以在创建或提交时使用 Google Cloud CLI 指定要应用于 Managed Service for Apache Spark 集群或作业的一个或多个标签。
gcloud dataproc clusters create args --labels environment=production,customer=acmegcloud dataproc jobs submit args --labels environment=production,customer=acme
创建 Managed Service for Apache Spark 集群或作业后,您可以使用 Google Cloud CLI 更新与相应资源关联的标签。
gcloud dataproc clusters update args --update-labels environment=production,customer=acmegcloud dataproc jobs update args --update-labels environment=production,customer=acme
同样,您可以借助 Google Cloud CLI,使用
以下格式的过滤表达式按标签过滤 Managed Service for Apache Spark 资源:labels.<key=value>。
gcloud dataproc clusters list \ --region=region \ --filter="status.state=ACTIVE AND labels.environment=production"gcloud dataproc jobs list \ --region=region \ --filter="status.state=ACTIVE AND labels.customer=acme"
如需详细了解如何编写过滤表达式,请参阅 clusters.list 和 jobs.list Dataproc API 文档。
REST API
您可以通过
Managed Service for Apache Spark REST API将标签附加到 Managed Service for Apache Spark 集群或作业。您还可以使用 clusters.create、
jobs.submit
API,在创建或提交集群或作业时将标签附加到集群或作业。
创建集群后,可以使用 clusters.patch、
jobs.patch API
修改标签。以下是 cluster.create 请求的 JSON 正文,该请求可将 key1:value 标签附加到集群上。
{
"clusterName":"cluster-1",
"projectId":"my-project",
"config":{
"configBucket":"",
"gceClusterConfig":{
"networkUri":".../networks/default",
"zoneUri":".../zones/us-central1-f"
},
"masterConfig":{
"numInstances":1,
"machineTypeUri":"..../machineTypes/n1-standard-4",
"diskConfig":{
"bootDiskSizeGb":500,
"numLocalSsds":0
}
},
"workerConfig":{
"numInstances":2,
"machineTypeUri":"...machineTypes/n1-standard-4",
"diskConfig":{
"bootDiskSizeGb":500,
"numLocalSsds":0
}
}
},
"labels":{
"key1":"value1"
}
}
您可以使用 clusters.list
和 jobs.list
API 按照以下格式列出符合指定过滤条件的集群或作业:labels.<key=value>。
下面是一个示例 Dataproc API clusters.list HTTPS GET 请求,该请求指定了 key=value 标签过滤条件。调用者插入 project、region、过滤条件 label-key 和 label-value 以及 api-key。
请注意,此示例请求被划分为两行以提高可读性。
GET https://dataproc.googleapis.com/v1/projects/project/regions/region/clusters? filter=labels.label-key=label-value&key=api-key
如需详细了解如何编写过滤表达式,请参阅 clusters.list 和 jobs.list Dataproc API 文档。
控制台
您可以使用 Google Cloud 控制台在创建或提交时指定要添加到 Managed Service for Apache Spark 集群或作业的一组标签。
- 从 Managed Service for Apache Spark 创建集群页面的“自定义集群”面板的“标签”部分中向集群添加标签。
- 从 Managed Service for Apache Spark 提交作业页面向作业添加标签。
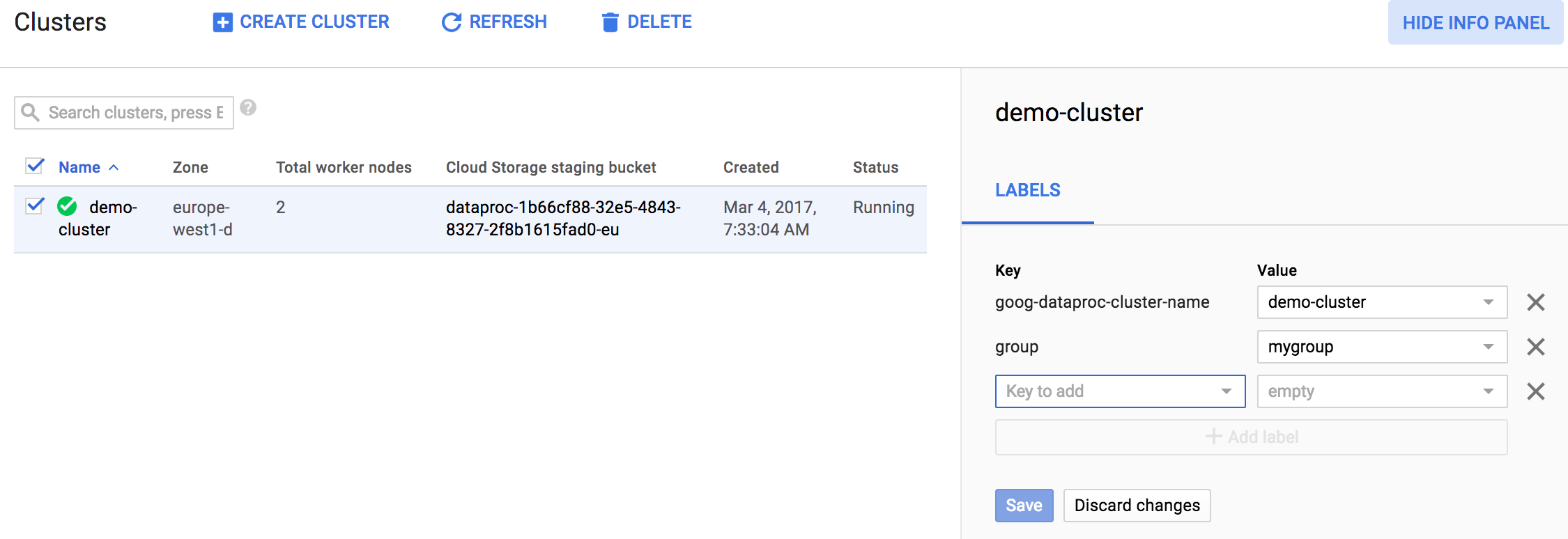
创建或提交 Managed Service for Apache Spark 集群或作业后,您可以更新与集群或作业关联的标签。如需更新标签,请点击列出的集群或作业的选择框,然后点击 SHOW INFO PANEL。下面是 Managed Service for Apache Spark→列出集群 页面的一个示例。

显示信息面板后,您可以更新 Managed Service for Apache Spark 集群或作业的标签。以下是更新 Managed Service for Apache Spark 集群标签的示例。
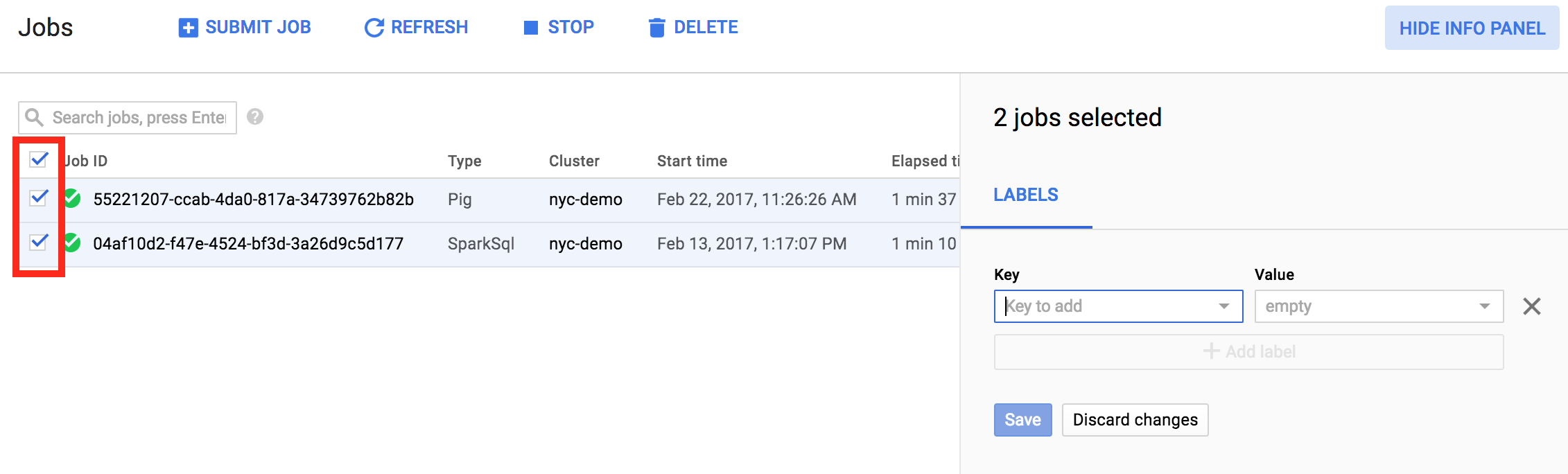
您也可以在一次操作中更新多个项目的标签。在此示例中,同时更新了多个 Managed Service for Apache Spark 作业的标签。
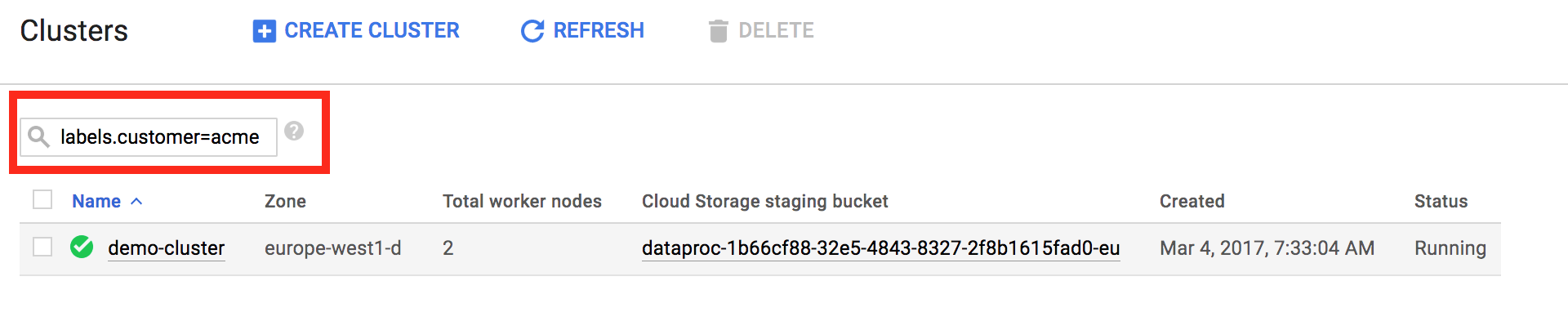
通过使用标签,您可以过滤 [Managed Service for Apache Spark→列出集群](https://console.cloud.google.com/managed-spark/clusters) 和 [Managed Service for Apache Spark→列出作业](https://console.cloud.google.com/managed-spark/jobs) 页面中显示的 Managed Service for Apache Spark 资源。在页面顶部,您可以使用搜索模式“labels.
自动应用的标签
在创建或更新集群时,Managed Service for Apache Spark 会自动将多个标签应用于集群和集群资源。例如,在创建集群时,Managed Service for Apache Spark 会将标签应用于虚拟机、永久性磁盘和加速器。自动应用的标签具有
特殊的 goog-dataproc 前缀。
以下 goog-dataproc 标签会自动应用于 Managed Service for Apache Spark 资源。您在创建集群时为预留的 goog-dataproc 标签提供的任何值都会替换自动提供的值。因此,不建议为这些标签提供您自己的值。
| 标签 | 说明 |
|---|---|
goog-dataproc-cluster-name |
用户指定的集群名称 |
goog-dataproc-cluster-uuid |
唯一集群 ID |
goog-dataproc-location |
Managed Service for Apache Spark 区域集群端点 |
您可以通过多种方式使用这些自动应用的标签,方式包括:
后续步骤
了解如何使用标签整理资源。