
Créer un lakehouse avec Spark et le catalogue d'environnements d'exécution Lakehouse
Une architecture de lakehouse combine la flexibilité d'un lac de données avec les fonctionnalités de gestion des données d'un entrepôt de données. Ce document explique comment configurer un lakehouse sur Google Cloud. Vous utilisez Apache Iceberg comme format de table, Managed Service pour Apache Spark pour le traitement et le catalogue REST Iceberg du catalogue d'environnements d'exécution Lakehouse pour la gestion unifiée des métadonnées.
Cette architecture utilise des formats de table ouverts tels qu'Iceberg pour ajouter des fonctionnalités d'entreposage de données, telles que les transactions et l'évolution des schémas, aux données de Cloud Storage. Cette approche crée une source unique de vérité pour vos données, accessible par différents moteurs.
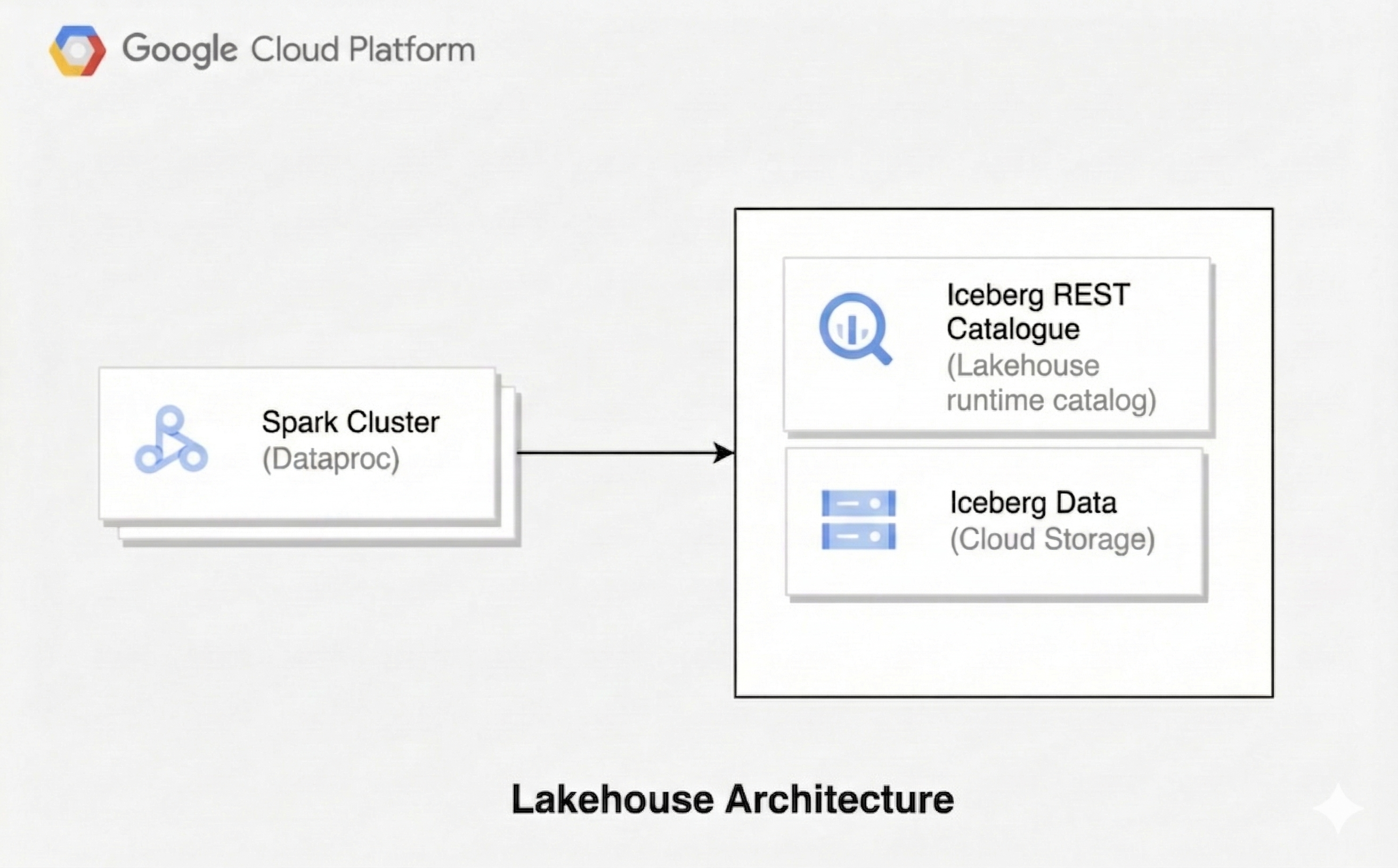
Avant de commencer
- Connectez-vous à votre Google Cloud compte. Si vous débutez sur Google Cloud, créez un compte pour évaluer les performances de nos produits en conditions réelles. Les nouveaux clients bénéficient également de 300 $ de crédits sans frais pour exécuter, tester et déployer des charges de travail.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that you have the permissions required to complete this guide.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc, BigQuery, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that you have the permissions required to complete this guide.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc, BigQuery, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.- Créez un bucket Cloud Storage pour stocker les données Iceberg.
Rôles requis
Certains rôles de Identity and Access Management (IAM) sont requis pour exécuter les exemples de cette page. En fonction des règles d'administration, ces rôles peuvent déjà avoir été attribués. Pour vérifier les attributions de rôles, consultez la section Devez-vous attribuer des rôles ?.
Pour en savoir plus sur l'attribution de rôles, consultez la page Gérer l'accès aux projets, aux dossiers et aux organisations.
Rôles utilisateur
Pour obtenir les autorisations nécessaires pour créer un cluster Managed Service pour Apache Spark, demandez à votre administrateur de vous accorder les rôles IAM suivants :
- Éditeur Dataproc (
roles/dataproc.editor) sur le projet - Utilisateur du compte de service (
roles/iam.serviceAccountUser) sur le compte de service Compute Engine par défaut
Rôle du compte de service
Pour vous assurer que le compte de service Compute Engine par défaut dispose des autorisations nécessaires pour créer un cluster Managed Service pour Apache Spark, demandez à votre administrateur d'accorder le rôle IAM Nœud de calcul Dataproc (roles/dataproc.worker) au compte de service Compute Engine par défaut sur le projet.
Créer un cluster Managed Service pour Apache Spark
Créez un cluster Managed Service pour Apache Spark avec les composants facultatifs Iceberg et Jupyter.
Pour créer le cluster, exécutez la commande
gcloudsuivante :gcloud dataproc clusters create CLUSTER_NAME \ --project=PROJECT_ID \ --region=REGION \ --image-version=2.3-debian12 \ --optional-components=ICEBERG,JUPYTER \ --enable-component-gateway \ --properties 'dataproc:dataproc.lineage.enabled=true'Remplacez les éléments suivants :
CLUSTER_NAME: nom de votre cluster.PROJECT_ID: ID de votre Google Cloud projet.REGION: région du cluster, par exempleus-central1. Google Cloud
Notez que la définition de
dataproc:dataproc.lineage.enabled=truen'est pas requise pour que le catalogue REST Iceberg du catalogue d'environnements d'exécution Lakehouse fonctionne correctement. Il est ajouté pour le suivi de la traçabilité dans l'exemple de traçabilité des données ci-dessous.Connectez-vous au cluster à l'aide d'un notebook Jupyter. Vous pouvez utiliser un notebook Vertex AI Workbench ou lancer un notebook directement sur le cluster.
Configurer une session Spark
Dans votre notebook Jupyter, créez une session Spark configurée pour utiliser le catalogue REST Iceberg du catalogue d'environnements d'exécution Lakehouse.
import pyspark
from pyspark.context import SparkContext
from pyspark.sql import SparkSession
catalog_name = "CATALOG_NAME"
spark = SparkSession.builder.appName("APP_NAME") \
.config(f'spark.sql.catalog.{catalog_name}', 'org.apache.iceberg.spark.SparkCatalog') \
.config(f'spark.sql.catalog.{catalog_name}.type', 'rest') \
.config(f'spark.sql.catalog.{catalog_name}.uri', 'https://biglake.googleapis.com/iceberg/v1beta/restcatalog') \
.config(f'spark.sql.catalog.{catalog_name}.warehouse', 'gs://GCS_BUCKET') \
.config(f'spark.sql.catalog.{catalog_name}.header.x-goog-user-project', 'PROJECT_ID') \
.config(f'spark.sql.catalog.{catalog_name}.rest.auth.type', 'org.apache.iceberg.gcp.auth.GoogleAuthManager') \
.config(f'spark.sql.catalog.{catalog_name}.io-impl', 'org.apache.iceberg.gcp.gcs.GCSFileIO') \
.config(f'spark.sql.catalog.{catalog_name}.rest-metrics-reporting-enabled', 'false') \
.config('spark.sql.extensions', 'org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions') \
.config('spark.sql.defaultCatalog', catalog_name) \
.getOrCreate()
Remplacez les éléments suivants :
CATALOG_NAME: nom de votre catalogue Iceberg, par exempleiceberg_catalog.APP_NAME: nom de votre application Spark.GCS_BUCKET: bucket Cloud Storage dans lequel stocker les données de votre table Iceberg.PROJECT_ID: ID de votre Google Cloud projet.
Gérer les données avec Spark SQL
Une fois la session Spark configurée, utilisez Spark SQL pour effectuer des opérations de gestion des données.
Créez un espace de noms. Dans le catalogue REST Iceberg du catalogue d'environnements d'exécution Lakehouse, un espace de noms correspond à un ensemble de données BigQuery.
spark.sql("CREATE NAMESPACE IF NOT EXISTS NAMESPACE_NAME") spark.sql("USE NAMESPACE_NAME")Remplacez
NAMESPACE_NAMEpar le nom de votre espace de noms, par exemplespark_lakehouse.Créez une table de base au format Iceberg et insérez des données.
spark.sql("DROP TABLE IF EXISTS base_table PURGE") spark.sql("CREATE TABLE base_table (id LONG) USING iceberg") spark.sql("INSERT INTO base_table VALUES 0, 1, 2, 3, 4") spark.sql("SELECT * FROM base_table").show()Le résultat ressemble à ce qui suit :
+---+ | id| +---+ | 0| | 1| | 2| | 3| | 4| +---+Créez une deuxième table pour les nouvelles données.
spark.sql("DROP TABLE IF EXISTS newdata PURGE") spark.sql("CREATE TABLE newdata(id LONG) USING iceberg") spark.sql("INSERT INTO newdata VALUES 3, 4, 5, 6") spark.sql("SELECT * FROM newdata").show()Le résultat ressemble à ce qui suit :
+---+ | id| +---+ | 3| | 4| | 5| | 6| +---+Fusionnez les nouvelles données dans la table de base.
spark.sql("""MERGE INTO base_table USING newdata ON base_table.id = newdata.id WHEN MATCHED THEN UPDATE SET base_table.id = newdata.id WHEN NOT MATCHED THEN INSERT * """) spark.sql("SELECT * FROM base_table").show()Le résultat ressemble à ce qui suit :
+---+ | id| +---+ | 0| | 1| | 2| | 3| | 4| | 5| | 6| +---+Mettez à jour les enregistrements dans la table de base.
spark.sql( "UPDATE base_table SET id = (id + 100) WHERE (id % 2 == 0)" ) spark.sql("SELECT * FROM base_table").show()Le résultat ressemble à ce qui suit :
+---+ | id| +---+ | 3| |104| | 5| |106| |100| |102| | 1| +---+Supprimez les enregistrements de la table de base.
spark.sql("DELETE FROM base_table WHERE (id % 2 == 0)") spark.sql("SELECT * FROM base_table").show()Le résultat ressemble à ce qui suit :
+---+ | id| +---+ | 3| | 5| | 1| +---+
Interroger un instantané historique
Récupérez une version précédente d'une table en interrogeant un ID d'instantané spécifique. Cette opération est également appelée "fonctionnalité temporelle".
Récupérez l'ID d'instantané de la version de la table avant les opérations
MERGE,UPDATEetDELETE.snapshot_ids = spark.sql( "SELECT snapshot_id FROM `NAMESPACE_NAME`.`base_table`.snapshots" ).collect() oldest_snapshot_id = snapshot_ids[1]["snapshot_id"]Remplacez
NAMESPACE_NAMEpar l'espace de noms que vous avez créé.Interrogez la table à l'aide de l'ID d'instantané récupéré.
df = ( spark.read.format("iceberg") .option("versionAsOf", oldest_snapshot_id) .load("base_table") ) df.show()Le résultat affiche l'état de la table après l'opération
MERGE, mais avant toute opérationUPDATEouDELETE.+---+ | id| +---+ | 0| | 1| | 2| | 3| | 4| | 5| | 6| +---+
Découvrir la traçabilité des données
Exemple de traçabilité des données
Créez des tables Iceberg source et cible, puis copiez les données.
spark.sql("DROP TABLE IF EXISTS source_table PURGE") spark.sql("DROP TABLE IF EXISTS target_table PURGE") spark.sql("CREATE TABLE source_table (id LONG) USING iceberg") spark.sql("""CREATE TABLE target_table USING ICEBERG AS SELECT max(id) as top_id FROM source_table """)Dans la Google Cloud console, accédez à la page Knowledge Catalog Rechercher.
Recherchez l'une des tables, puis cliquez sur l'onglet
Lineage: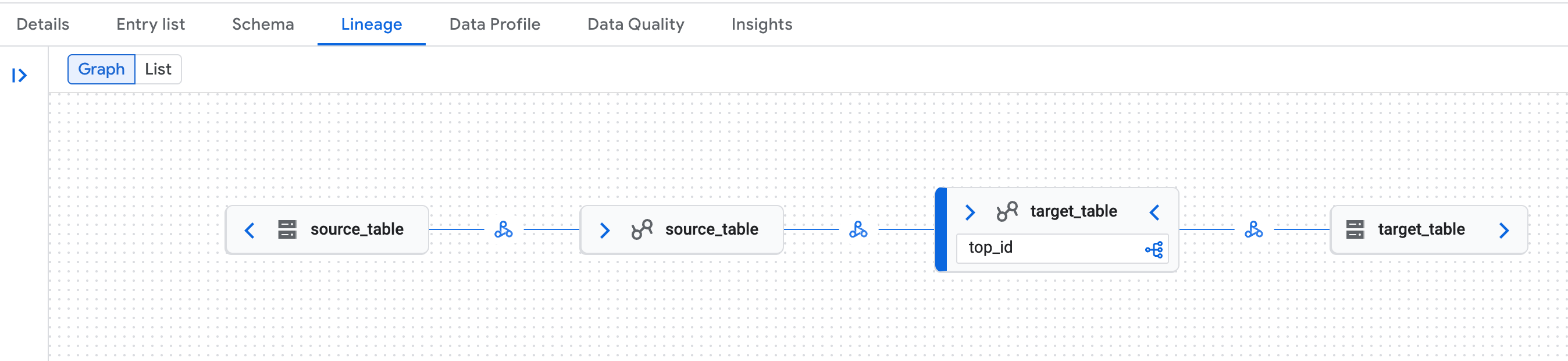
Exemple de graphique de traçabilité des données sur la page Knowledge Catalog de la Google Cloud console. La traçabilité des données reconnaît les représentations logiques (table du catalogue d'environnements d'exécution Lakehouse) et physiques (Cloud Storage) des tables du catalogue REST Iceberg du catalogue d'environnements d'exécution Lakehouse.
Problème connu lié à la traçabilité des données
Dans certains clusters Managed Service pour Apache Spark, la traçabilité complète des données peut ne pas être
générée en raison d'un OpenLineage.
Solution : dans la configuration de la session Spark, définissez la propriété spark.sql.catalog.{catalog_name}.uri sur https://biglake.googleapis.com/iceberg/v1beta/restcatalog.
Étape suivante
- En savoir plus sur le catalogue REST Iceberg du catalogue d'environnements d'exécution Lakehouse.
- Découvrir les fonctionnalités d'Apache Iceberg.
- Découvrir comment interroger des données Iceberg à partir du catalogue d'environnements d'exécution Lakehouse.
- En savoir plus sur la traçabilité des données et Managed Service pour Apache Spark.