
אתם יכולים להפעיל רכיבים נוספים כמו Flink כשאתם יוצרים אשכול של Managed Service for Apache Spark באמצעות התכונה רכיבים אופציונליים. בדף הזה מוסבר איך ליצור אשכול של Managed Service for Apache Spark עם הפעלת הרכיב האופציונלי Apache Flink (אשכול Flink), ולאחר מכן להריץ משימות Flink באשכול.
אפשר להשתמש באשכול Flink כדי:
הפעלת משימות Flink באמצעות המשאב
Jobsממסוף Google Cloud , מ-Google Cloud CLI או מ-Dataproc API.מריצים משימות Flink באמצעות
flinkCLI שפועל בצומת הראשי של אשכול Flink.הפעלה של Flink באשכול עם Kerberos
יצירת אשכול Flink
אפשר להשתמש במסוף Google Cloud , ב-Google Cloud CLI או ב-Dataproc API כדי ליצור אשכול שרכיב Flink מופעל בו.
המלצה: כדאי להשתמש באשכול של מכונות וירטואליות עם מאסטר אחד ורכיב Flink. אשכולות במצב זמינות גבוהה של Managed Service for Apache Spark (עם 3 מכונות וירטואליות ראשיות) לא תומכים במצב זמינות גבוהה של Flink.
המסוף
כדי ליצור אשכול של Managed Service for Apache Spark Flink באמצעות מסוף Google Cloud , פועלים לפי השלבים הבאים:
- פותחים את הדף Create cluster.
- בקטע Define your cluster (הגדרת האשכול), מאשרים או משנים את גרסת התמונה:
- כדי להפעיל את רכיב Flink באשכול, גרסת התמונה צריכה להיות
1.5ומעלה. בקטע גרסאות נתמכות של Managed Service for Apache Spark מפורטות גרסאות הרכיבים שנכללות בכל גרסת תמונה. - במאמר הרצת משימות Flink ב-Managed Service for Apache Spark מפורטות הדרישות לגבי גרסת קובץ האימג' להרצת משימות Flink באמצעות משאב המשימות.
- כדי להפעיל את רכיב Flink באשכול, גרסת התמונה צריכה להיות
- לוחצים על הגדרה נוספת כדי להרחיב את הקטע.
- עורכים את הרכיבים האופציונליים.
- בחלונית שנפתחת, מסמנים את תיבת הסימון Flink ולוחצים על שמירה.
- עורכים את התאמה אישית ואחר.
- בחלונית שנפתחת:
- בקטע Cluster properties (מאפייני האשכול), לוחצים על + Add properties (+הוספת מאפיינים) כדי להגדיר מאפייני Flink (קידומת:
flink, מפתח: FLINK_KEY, ערך: VALUE) ב-/etc/flink/conf/flink-conf.yaml, שישמשו כברירות מחדל לאפליקציות Flink שמריצים באשכול.דוגמאות:
- מגדירים את
flink:historyserver.archive.fs.dirכדי לציין את המיקום ב-Cloud Storage שבו ייכתבו קובצי היסטוריית המשימות של Flink (המיקום הזה ישמש את Flink History Server שפועל באשכול Flink). - מגדירים את משבצות הזמן למשימות ב-Flink באמצעות
flink:taskmanager.numberOfTaskSlots=n.
- מגדירים את
- בקטע Custom cluster metadata (מטא-נתונים של אשכול בהתאמה אישית), לוחצים על + Add properties (הוספת מאפיינים), מגדירים את המפתח ל-
flink-start-yarn-sessionואת הערך ל-trueכדי להפעיל את ה-daemon של Flink YARN,/usr/bin/flink-yarn-daemon, ברקע בצומת של מנהל האשכול כדי להתחיל סשן של Flink YARN (ראו הפעלת משימות של Flink באמצעות ה-CLI של Flink – מצב סשן).
- בקטע Cluster properties (מאפייני האשכול), לוחצים על + Add properties (+הוספת מאפיינים) כדי להגדיר מאפייני Flink (קידומת:
- לוחצים על Save.
- אם אתם משתמשים בגרסה
2.0או בגרסה ישנה יותר של תמונת Managed Service for Apache Spark, לוחצים על Security. - בחלונית שנפתחת, בקטע Project access, מסמנים את התיבה Enables the cloud-platform scope for this cluster ואז לוחצים על Save (ההיקף
cloud-platformמופעל כברירת מחדל כשיוצרים אשכול שמשתמש בגרסה2.1או בגרסה מאוחרת יותר של תמונה של Managed Service for Apache Spark). - לוחצים על יצירת אשכול כדי ליצור את האשכול.
gcloud
כדי ליצור אשכול של Managed Service for Apache Spark Flink באמצעות ה-CLI של gcloud, מריצים את הפקודה הבאה gcloud dataproc clusters create באופן מקומי בחלון טרמינל או ב-Cloud Shell:
gcloud dataproc clusters create CLUSTER_NAME \ --region=REGION \ --image-version=DATAPROC_IMAGE_VERSION \ --optional-components=FLINK \ --enable-component-gateway \ --properties=PROPERTIES ... other flags
הערות:
- CLUSTER_NAME: מציינים את שם האשכול.
- REGION: מציינים אזור של Compute Engine שבו ימוקם האשכול.
DATAPROC_IMAGE_VERSION: אפשר לציין את גרסת התמונה שבה רוצים להשתמש באשכול. גרסת התמונה של האשכול קובעת את גרסת רכיב Flink שמותקנת באשכול.
- גירסת התמונה צריכה להיות
1.5ומעלה כדי להפעיל את רכיב Flink באשכול. במאמר גרסאות נתמכות של תמונות Managed Service for Apache Spark אפשר לראות רשימות של גרסאות הרכיבים שנכללות בכל גרסת תמונה. - במאמר הרצת משימות של Managed Service for Apache Spark Flink מפורטות דרישות גרסת התמונה להרצת משימות Flink באמצעות Dataproc Jobs API.
- גירסת התמונה צריכה להיות
--optional-components: צריך לציין את הרכיבFLINKכדי להריץ משימות של Flink ואת שירות האינטרנט Flink HistoryServer באשכול.
--enable-component-gateway: כדי להפעיל את הקישור של Component Gateway לממשק המשתמש של Flink History Server, צריך להפעיל את Component Gateway. הפעלת Component Gateway מאפשרת גם גישה לממשק האינטרנט של Flink Job Manager שפועל באשכול Flink.PROPERTIES. אופציונלי: מציינים מאפיינים של האשכול.
כשיוצרים אשכולות של Managed Service for Apache Spark עם גרסאות תמונה
2.0.67+ ו-2.1.15+, אפשר להשתמש בדגל--propertiesכדי להגדיר מאפייני Flink ב-/etc/flink/conf/flink-conf.yamlשישמשו כברירות מחדל לאפליקציות Flink שמריצים באשכול.אפשר להגדיר את
flink:historyserver.archive.fs.dirכדי לציין את המיקום ב-Cloud Storage שבו ייכתבו קובצי ההיסטוריה של משימות Flink (המיקום הזה ישמש את Flink History Server שפועל באשכול Flink).דוגמה עם כמה נכסים:
--properties=flink:historyserver.archive.fs.dir=gs://my-bucket/my-flink-cluster/completed-jobs,flink:taskmanager.numberOfTaskSlots=2סימונים אחרים:
- אפשר להוסיף את האפשרות
--metadata flink-start-yarn-session=trueכדי להריץ את דמון Flink YARN, /usr/bin/flink-yarn-daemon, ברקע בצומת הראשי של האשכול כדי להתחיל סשן Flink YARN (ראו הרצת משימות Flink באמצעות Flink CLI – מצב סשן).
- אפשר להוסיף את האפשרות
כשמשתמשים בגרסה 2.0 או בגרסאות קודמות של תמונות, מוסיפים את הדגל
--scopes=https://www.googleapis.com/auth/cloud-platformכדי להפעיל גישה לממשקי API על ידי האשכול (ראו שיטות מומלצות לשימוש בהיקפי הרשאות). Google Cloud ההיקףcloud-platformמופעל כברירת מחדל כשיוצרים אשכול שמשתמש בגרסת תמונה 2.1 ואילך של Managed Service for Apache Spark.
API
כדי ליצור אשכול של Managed Service for Apache Spark Flink באמצעות Dataproc API, שולחים בקשת clusters.create באופן הבא:
הערות:
מגדירים את SoftwareConfig.Component ל-
FLINK.אפשר גם להגדיר את
SoftwareConfig.imageVersionכדי לציין את גרסת התמונה שבה רוצים להשתמש באשכול. גרסת התמונה של האשכול קובעת את גרסת רכיב Flink שמותקנת באשכול.גרסת התמונה צריכה להיות
1.5ומעלה כדי להפעיל את רכיב Flink באשכול (במאמר גרסאות נתמכות של Managed Service for Apache Spark מפורטות גרסאות הרכיבים שנכללות בכל מהדורת תמונה של Managed Service for Apache Spark).במאמר הרצת משימות של Managed Service for Apache Spark Flink מפורטות דרישות גרסת התמונה להרצת משימות Flink באמצעות Dataproc Jobs API.
מגדירים את EndpointConfig.enableHttpPortAccess לערך
trueכדי להפעיל את הקישור Component Gateway לממשק המשתמש של Flink History Server. הפעלת Component Gateway מאפשרת גם גישה לממשק האינטרנט של Flink Job Manager שפועל באשכול Flink.אפשר גם להגדיר את
SoftwareConfig.propertiesכדי לציין מאפייני אשכול אחד או יותר.- אתם יכולים לציין מאפייני Flink שישמשו כברירות מחדל לאפליקציות Flink שאתם מריצים באשכול. לדוגמה, אפשר להגדיר את
flink:historyserver.archive.fs.dirכדי לציין את המיקום ב-Cloud Storage שבו ייכתבו קובצי היסטוריית המשימות של Flink (המיקום הזה ישמש את Flink History Server שפועל באשכול Flink).
- אתם יכולים לציין מאפייני Flink שישמשו כברירות מחדל לאפליקציות Flink שאתם מריצים באשכול. לדוגמה, אפשר להגדיר את
אפשר גם להגדיר:
-
GceClusterConfig.metadata. לדוגמה, כדי לציין אתflink-start-yarn-sessiontrueלהפעלת דימון (daemon) Flink YARN,/usr/bin/flink-yarn-daemon, ברקע בצומת מאסטר האשכולות (cluster master) כדי להתחיל סשן Flink YARN (ראו מצב סשן של Flink). - GceClusterConfig.serviceAccountScopes
ל-
https://www.googleapis.com/auth/cloud-platform(היקףcloud-platform) כשמשתמשים בגרסאות תמונה 2.0 או קודמות כדי להפעיל גישה ל- Google CloudAPI על ידי האשכול (ראו שיטות מומלצות לשימוש בהיקפים). ההיקףcloud-platformמופעל כברירת מחדל כשיוצרים אשכול שמשתמש בגרסת תמונה 2.1 ואילך של Managed Service for Apache Spark.
-
אחרי שיוצרים אשכול Flink
- משתמשים בקישור
Flink History ServerבComponent Gateway כדי לראות את Flink History Server שפועל באשכול Flink. - משתמשים ב-
YARN ResourceManager linkב-Component Gateway כדי להציג את ממשק האינטרנט של Flink Job Manager שפועל באשכול Flink . - כדי לראות את קובצי ההיסטוריה של משימות Flink שנכתבו על ידי אשכולות Flink קיימים ומחוקים, צריך ליצור Managed Service for Apache Spark Persistent History Server.
הרצת משימות Flink באמצעות משאב Jobs
אפשר להריץ משימות Flink באמצעות המשאב Managed Service for Apache Spark Jobs מGoogle Cloud console, Google Cloud CLI או Dataproc API.
המסוף
כדי לשלוח משימת ספירת מילים לדוגמה ב-Flink מהמסוף:
פותחים את הדף Submit a job של Managed Service for Apache Spark במסוףGoogle Cloud בדפדפן.
ממלאים את השדות בדף שליחת משרה:
- בוחרים את שם האשכול מתוך רשימת האשכולות.
- מגדירים את סוג העבודה לערך
Flink. - מגדירים את Main class or jar (הכיתה או קובץ ה-JAR הראשיים) ל-
org.apache.flink.examples.java.wordcount.WordCount. - מגדירים את Jar files לערך
file:///usr/lib/flink/examples/batch/WordCount.jar.-
file:///מציין קובץ שנמצא באשכול. Managed Service for Apache Spark התקין אתWordCount.jarכשנוצר אשכול Flink. - בשדה הזה אפשר גם להזין נתיב של Cloud Storage (
gs://BUCKET/JARFILE) או נתיב של מערכת קבצים מבוזרת של Hadoop (HDFS) (hdfs://PATH_TO_JAR).
-
לוחצים על שליחה.
- הפלט של מנהל המשימות מוצג בדף Job details (פרטי המשימה).
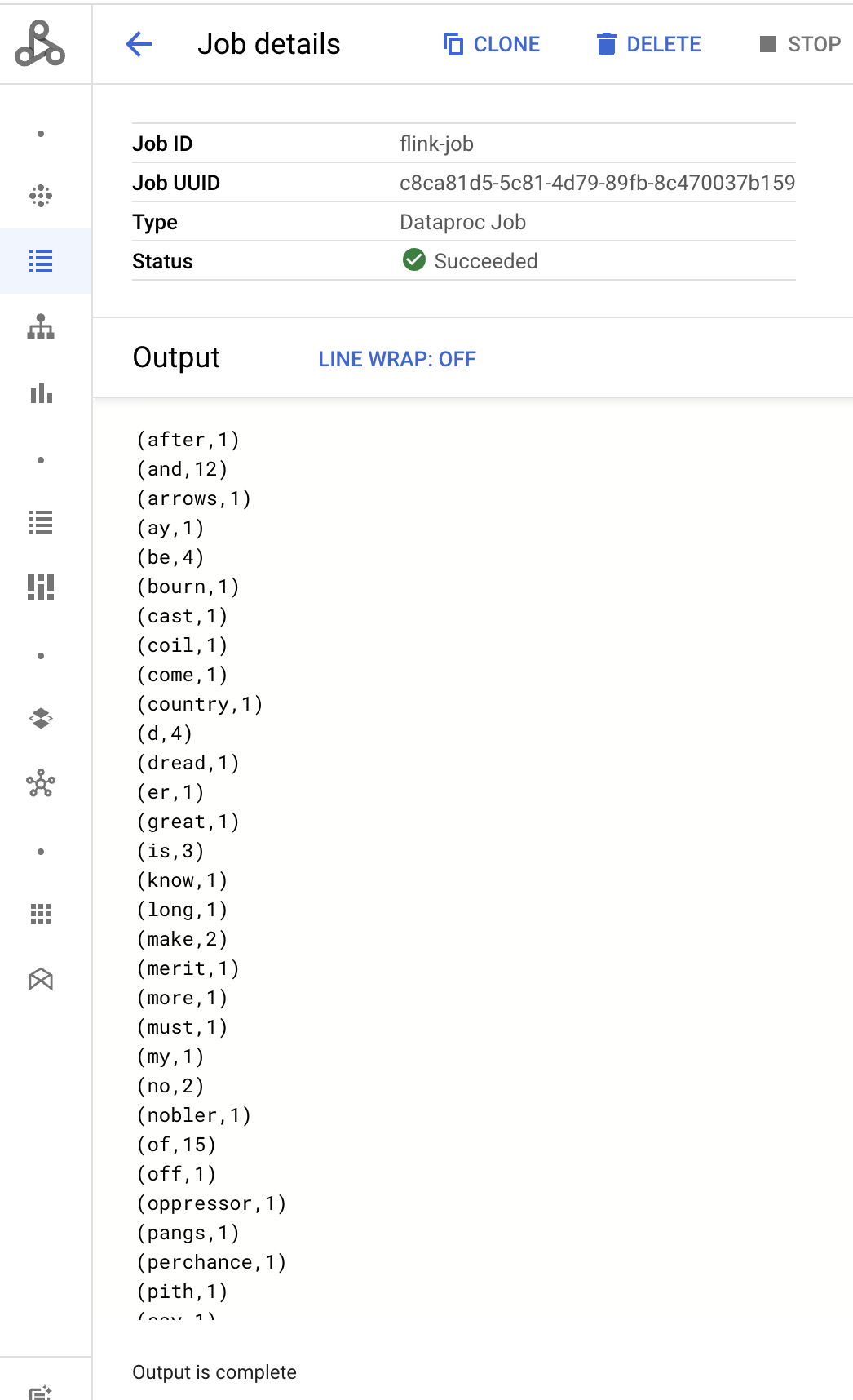
- משימות Flink מופיעות בדף Jobs של Managed Service for Apache Spark במסוף Google Cloud .
- לוחצים על הפסקה או על מחיקה בדף משימות או פרטי המשימה כדי להפסיק או למחוק משימה.
gcloud
כדי לשלוח משימת Flink לאשכול של Managed Service for Apache Spark Flink, מריצים את הפקודה gcloud dataproc jobs submit של ה-CLI של gcloud באופן מקומי בחלון טרמינל או ב-Cloud Shell.
gcloud dataproc jobs submit flink \ --cluster=CLUSTER_NAME \ --region=REGION \ --class=MAIN_CLASS \ --jar=JAR_FILE \ -- JOB_ARGS
הערות:
- CLUSTER_NAME: מציינים את השם של אשכול Managed Service for Apache Spark Flink שאליו רוצים לשלוח את העבודה.
- REGION: מציינים אזור של Compute Engine שבו נמצא האשכול.
- MAIN_CLASS: מציינים את המחלקה
mainשל אפליקציית Flink, למשל:org.apache.flink.examples.java.wordcount.WordCount
- JAR_FILE: מציינים את קובץ ה-JAR של אפליקציית Flink. אתם יכולים לציין:
- קובץ jar שהותקן באשכול, באמצעות הקידומת
file:///` :file:///usr/lib/flink/examples/streaming/TopSpeedWindowing.jarfile:///usr/lib/flink/examples/batch/WordCount.jar
- קובץ jar ב-Cloud Storage:
gs://BUCKET/JARFILE - קובץ jar ב-HDFS:
hdfs://PATH_TO_JAR
- קובץ jar שהותקן באשכול, באמצעות הקידומת
JOB_ARGS: אפשר להוסיף ארגומנטים של המשימה אחרי הקו המקף הכפול (
--).אחרי ששולחים את העבודה, הפלט של מנהל העבודה מוצג בטרמינל המקומי או ב-Cloud Shell.
Program execution finished Job with JobID 829d48df4ebef2817f4000dfba126e0f has finished. Job Runtime: 13610 ms ... (after,1) (and,12) (arrows,1) (ay,1) (be,4) (bourn,1) (cast,1) (coil,1) (come,1)
REST
בקטע הזה מוסבר איך לשלוח משימת Flink לאשכול Managed Service for Apache Spark Flink באמצעות Managed Service for Apache Spark API jobs.submit.
לפני שמשתמשים בנתוני הבקשה, צריך להחליף את הנתונים הבאים:
- PROJECT_ID: Google Cloud מזהה הפרויקט
- REGION: cluster region
- CLUSTER_NAME: מציינים את השם של אשכול Managed Service for Apache Spark Flink שאליו רוצים לשלוח את המשימה
ה-method של ה-HTTP וכתובת ה-URL:
POST https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION/jobs:submit
תוכן בקשת JSON:
{
"job": {
"placement": {
"clusterName": "CLUSTER_NAME"
},
"flinkJob": {
"mainClass": "org.apache.flink.examples.java.wordcount.WordCount",
"jarFileUris": [
"file:///usr/lib/flink/examples/batch/WordCount.jar"
]
}
}
}
כדי לשלוח את הבקשה צריך להרחיב אחת מהאפשרויות הבאות:
אתם אמורים לקבל תגובת JSON שדומה לזו:
{
"reference": {
"projectId": "PROJECT_ID",
"jobId": "JOB_ID"
},
"placement": {
"clusterName": "CLUSTER_NAME",
"clusterUuid": "CLUSTER_UUID"
},
"flinkJob": {
"mainClass": "org.apache.flink.examples.java.wordcount.WordCount",
"args": [
"1000"
],
"jarFileUris": [
"file:///usr/lib/flink/examples/batch/WordCount.jar"
]
},
"status": {
"state": "PENDING",
"stateStartTime": "2020-10-07T20:16:21.759Z"
},
"jobUuid": "JOB_UUID"
}
- משימות Flink מופיעות בדף Jobs של Managed Service for Apache Spark במסוף Google Cloud .
- כדי להפסיק או למחוק עבודה, אפשר ללחוץ על Stop או על Delete בדף Jobs או Job details במסוף Google Cloud .
הרצת משימות Flink באמצעות flink CLI
במקום להריץ משימות Flink באמצעות משאב Jobs של Managed Service for Apache Spark, אפשר להריץ משימות Flink בצומת דרייבר של אשכול Flink באמצעות flink CLI.
בקטעים הבאים מתוארות דרכים שונות להפעלת משימת flink CLI באשכול Managed Service for Apache Spark Flink.
התחברות באמצעות SSH לצומת הראשי: משתמשים בכלי SSH כדי לפתוח חלון טרמינל במכונה הווירטואלית הראשית של האשכול.
מגדירים את classpath: מאתחלים את classpath של Hadoop מחלון הטרמינל של SSH במכונה הווירטואלית הראשית של מאסטר אשכולות Flink:
export HADOOP_CLASSPATH=$(hadoop classpath)הפעלת משימות Flink: אפשר להפעיל משימות Flink במצבי פריסה שונים ב-YARN: מצב אפליקציה, מצב לכל משימה ומצב סשן.
מצב אפליקציה: מצב האפליקציה של Flink נתמך על ידי Managed Service for Apache Spark מגרסה 2.0 ואילך. במצב הזה, קוד ה-method של העבודה
main()מופעל ב-YARN Job Manager. האשכול מושבת אחרי שהעבודה מסתיימת.דוגמה לשליחת משרה:
flink run-application \ -t yarn-application \ -Djobmanager.memory.process.size=1024m \ -Dtaskmanager.memory.process.size=2048m \ -Djobmanager.heap.mb=820 \ -Dtaskmanager.heap.mb=1640 \ -Dtaskmanager.numberOfTaskSlots=2 \ -Dparallelism.default=4 \ /usr/lib/flink/examples/batch/WordCount.jarהצגת רשימה של משרות פעילות:
./bin/flink list -t yarn-application -Dyarn.application.id=application_XXXX_YYכדי לבטל עבודה שפועלת:
./bin/flink cancel -t yarn-application -Dyarn.application.id=application_XXXX_YY <jobId>מצב לכל עבודה: במצב הזה של Flink, קוד ה-method של העבודה
main()מופעל בצד הלקוח.דוגמה לשליחת משרה:
flink run \ -m yarn-cluster \ -p 4 \ -ys 2 \ -yjm 1024m \ -ytm 2048m \ /usr/lib/flink/examples/batch/WordCount.jarמצב סשן: מתחילים סשן Flink YARN שפועל לאורך זמן, ואז שולחים משימה אחת או יותר לסשן.
התחלת סשן: אפשר להתחיל סשן Flink באחת מהדרכים הבאות:
יוצרים אשכול Flink ומוסיפים את הדגל
--metadata flink-start-yarn-session=trueלפקודהgcloud dataproc clusters create(ראו יצירת אשכול Dataproc Flink). אם הדגל הזה מופעל, אחרי יצירת האשכול, Managed Service for Apache Spark מפעיל את הפקודה/usr/bin/flink-yarn-daemonכדי להתחיל סשן Flink באשכול.מזהה האפליקציה של YARN בסשן נשמר ב-
/tmp/.yarn-properties-${USER}. אפשר להציג את המזהה באמצעות הפקודהyarn application -list.מריצים את הסקריפט Flink
yarn-session.shשמותקן מראש במכונה הווירטואלית הראשית של מאסטר האשכולות, עם הגדרות בהתאמה אישית:דוגמה עם הגדרות מותאמות אישית:
/usr/lib/flink/bin/yarn-session.sh \ -s 1 \ -jm 1024m \ -tm 2048m \ -nm flink-dataproc \ --detachedמריצים את סקריפט העטיפה של Flink עם הגדרות ברירת המחדל:
/usr/bin/flink-yarn-daemon. /usr/bin/flink-yarn-daemon
שליחת משימה לסשן: מריצים את הפקודה הבאה כדי לשלוח משימת Flink לסשן.
flink run -m <var>FLINK_MASTER_URL</var>/usr/lib/flink/examples/batch/WordCount.jar- FLINK_MASTER_URL: כתובת ה-URL, כולל המארח והיציאה, של מכונת ה-VM הראשית של Flink שבה מופעלים העבודות.
מסירים את התו
http:// prefixמכתובת ה-URL. כתובת ה-URL הזו מופיעה בפלט פקודה כשמתחילים סשן של Flink. כדי להציג את כתובת ה-URL הזו בשדהTracking-URL, מריצים את הפקודה הבאה:
yarn application -list -appId=<yarn-app-id> | sed 's#http://##' ```- FLINK_MASTER_URL: כתובת ה-URL, כולל המארח והיציאה, של מכונת ה-VM הראשית של Flink שבה מופעלים העבודות.
מסירים את התו
הצגת רשימת המשימות בהפעלה: כדי להציג רשימה של משימות Flink בהפעלה, מבצעים אחת מהפעולות הבאות:
מריצים את הפקודה
flink listבלי ארגומנטים. הפקודה מחפשת את מזהה האפליקציה של YARN בסשן ב-/tmp/.yarn-properties-${USER}.מקבלים את מזהה אפליקציית YARN של הסשן מ-
/tmp/.yarn-properties-${USER}או מהפלט שלyarn application -list, ואז מריצים את הפקודה<code>flink list -yid YARN_APPLICATION_ID.מריצים את
flink list -m FLINK_MASTER_URL.
הפסקת סשן: כדי להפסיק את הסשן, צריך לקבל את מזהה האפליקציה של YARN של הסשן מ-
/tmp/.yarn-properties-${USER}או מהפלט שלyarn application -list, ואז להריץ אחת מהפקודות הבאות:echo "stop" | /usr/lib/flink/bin/yarn-session.sh -id YARN_APPLICATION_IDyarn application -kill YARN_APPLICATION_ID
הרצת משימות Apache Beam ב-Flink
אפשר להריץ משימות של Apache Beam ב-Managed Service for Apache Spark באמצעות FlinkRunner.
אפשר להריץ משימות Beam ב-Flink בדרכים הבאות:
- משימות Java Beam
- משרות ניידות של Beam
משימות Java Beam
אורזים את עבודות ה-Beam בקובץ JAR. מספקים את קובץ ה-JAR בחבילה עם יחסי התלות שנדרשים להפעלת העבודה.
בדוגמה הבאה מריצים משימת Java Beam מצומת הראשי של אשכול Managed Service for Apache Spark.
יוצרים אשכול Managed Service for Apache Spark עם רכיב Flink מופעל.
gcloud dataproc clusters create CLUSTER_NAME \ --optional-components=FLINK \ --image-version=DATAPROC_IMAGE_VERSION \ --region=REGION \ --enable-component-gateway \ --scopes=https://www.googleapis.com/auth/cloud-platform-
--optional-components: Flink. -
--image-version: גרסת התמונה של האשכול, שקובעת את גרסת Flink שמותקנת באשכול (לדוגמה, אפשר לראות את גרסאות הרכיבים של Apache Flink שמופיעות עבור ארבע גרסאות התמונה האחרונות של 2.0.x). -
--region: אזור נתמך של Managed Service for Apache Spark. -
--enable-component-gateway: מאפשר גישה לממשק המשתמש של Flink Job Manager. -
--scopes: מאפשר גישה לממשקי API על ידי האשכול Google Cloud (ראו שיטות מומלצות לשימוש בהיקפים). ההגדרהcloud-platformמופעלת כברירת מחדל (אין צורך לכלול את הגדרת הדגל הזו) כשיוצרים אשכול שמשתמש בגרסה 2.1 ואילך של תמונת Managed Service for Apache Spark.
-
משתמשים בכלי SSH כדי לפתוח חלון טרמינל בצומת הראשי של אשכול Flink.
מפעילים סשן Flink YARN בצומת מאסטר האשכולות של אשכול Managed Service for Apache Spark.
. /usr/bin/flink-yarn-daemonשימו לב לגרסת Flink באשכול Managed Service for Apache Spark.
flink --versionבמחשב המקומי, יוצרים את הדוגמה הקנונית של ספירת מילים ב-Beam ב-Java.
בוחרים גרסת Beam שתואמת לגרסת Flink באשכול Managed Service for Apache Spark. אפשר לעיין בטבלה Flink Version Compatibility שמפרטת את התאימות של גרסאות Beam-Flink.
פותחים את קובץ ה-POM שנוצר. בודקים את גרסת Beam Flink runner שצוינה בתג
<flink.artifact.name>. אם גרסת Beam Flink runner בשם הארטיפקט של Flink לא תואמת לגרסת Flink באשכול, צריך לעדכן את מספר הגרסה כך שיהיה תואם.mvn archetype:generate \ -DarchetypeGroupId=org.apache.beam \ -DarchetypeArtifactId=beam-sdks-java-maven-archetypes-examples \ -DarchetypeVersion=BEAM_VERSION \ -DgroupId=org.example \ -DartifactId=word-count-beam \ -Dversion="0.1" \ -Dpackage=org.apache.beam.examples \ -DinteractiveMode=falseדוגמה לאריזה של ספירת המילים.
mvn package -Pflink-runnerמעלים את קובץ ה-JAR המאוגד,
word-count-beam-bundled-0.1.jar(~135 MB) לצומת הראשי של אשכול Managed Service for Apache Spark. אתם יכולים להשתמש ב-gcloud storage cpכדי להעביר קבצים מהר יותר אל אשכול Managed Service for Apache Spark מ-Cloud Storage.במסוף המקומי, יוצרים קטגוריה של Cloud Storage ומעלים את קובץ ה-JAR הגדול.
gcloud storage buckets create BUCKET_NAMEgcloud storage cp target/word-count-beam-bundled-0.1.jar gs://BUCKET_NAME/בצומת הראשי של Managed Service for Apache Spark, מורידים את קובץ ה-JAR הגדול.
gcloud storage cp gs://BUCKET_NAME/word-count-beam-bundled-0.1.jar .
מריצים את משימת Java Beam בצומת הדרייבר של אשכול Managed Service for Apache Spark.
flink run -c org.apache.beam.examples.WordCount word-count-beam-bundled-0.1.jar \ --runner=FlinkRunner \ --output=gs://BUCKET_NAME/java-wordcount-outבודקים שהתוצאות נכתבו לקטגוריה של Cloud Storage.
gcloud storage cat gs://BUCKET_NAME/java-wordcount-out-SHARD_IDמפסיקים את סשן Flink YARN.
yarn application -listyarn application -kill YARN_APPLICATION_ID
משרות Beam ניידות
כדי להריץ משימות Beam שנכתבו ב-Python, ב-Go ובשפות נתמכות אחרות, אפשר להשתמש ב-FlinkRunner וב-PortableRunner כמו שמתואר בדף Flink Runner של Beam (אפשר גם לעיין בתוכנית הדרך של מסגרת הניוד).
בדוגמה הבאה מריצים משימת Beam ניידת ב-Python מהצומת הראשי של אשכול Managed Service for Apache Spark.
יוצרים אשכול Managed Service for Apache Spark עם הרכיבים Flink ו-Docker מופעלים.
gcloud dataproc clusters create CLUSTER_NAME \ --optional-components=FLINK,DOCKER \ --image-version=DATAPROC_IMAGE_VERSION \ --region=REGION \ --enable-component-gateway \ --scopes=https://www.googleapis.com/auth/cloud-platformהערות:
-
--optional-components: Flink ו-Docker. -
--image-version: גרסת התמונה של האשכול, שקובעת את גרסת Flink שמותקנת באשכול (לדוגמה, אפשר לראות את גרסאות הרכיבים של Apache Flink שמופיעות ב-2.0.x image release versions האחרונות וארבע הגרסאות הקודמות). -
--region: אזור זמין של Managed Service for Apache Spark. -
--enable-component-gateway: הפעלת גישה לממשק המשתמש של Flink Job Manager. -
--scopes: מאפשרים גישה לממשקי API על ידי האשכול Google Cloud (ראו שיטות מומלצות לשימוש בהיקפים). ההגדרהcloud-platformמופעלת כברירת מחדל (אין צורך לכלול את הגדרת הדגל הזו) כשיוצרים אשכול שמשתמש בגרסה 2.1 ואילך של תמונת Managed Service for Apache Spark.
-
משתמשים ב-CLI של gcloud באופן מקומי או ב-Cloud Shell כדי ליצור קטגוריה של Cloud Storage. תציינו את BUCKET_NAME כשמריצים תוכנית לדוגמה לספירת מילים.
gcloud storage buckets create BUCKET_NAMEבחלון טרמינל במכונת ה-VM של האשכול, מתחילים סשן Flink YARN. רושמים את כתובת ה-URL של Flink master, הכתובת של Flink master שבה מבוצעות משימות. תציינו את FLINK_MASTER_URL כשמריצים תוכנית לדוגמה לספירת מילים.
. /usr/bin/flink-yarn-daemonמציגים את גרסת Flink שמופעלת באשכול Managed Service for Apache Spark ומציינים אותה. תציינו את FLINK_VERSION כשמריצים תוכנית לדוגמה לספירת מילים.
flink --versionמתקינים את ספריות Python שנדרשות לעבודה במאסטר אשכולות (cluster master).
מתקינים גרסת Beam שתואמת לגרסת Flink באשכול.
python -m pip install apache-beam[gcp]==BEAM_VERSIONמריצים את הדוגמה של ספירת המילים בצומת הראשי של האשכול.
python -m apache_beam.examples.wordcount \ --runner=FlinkRunner \ --flink_version=FLINK_VERSION \ --flink_master=FLINK_MASTER_URL --flink_submit_uber_jar \ --output=gs://BUCKET_NAME/python-wordcount-outהערות:
--runner:FlinkRunner.-
--flink_version: FLINK_VERSION, כמו שצוין קודם. -
--flink_master: FLINK_MASTER_URL, כמו שצוין קודם. -
--flink_submit_uber_jar: שימוש ב-uber JAR להרצת משימת Beam. -
--output: BUCKET_NAME, נוצר קודם.
מוודאים שהתוצאות נכתבו לדלי.
gcloud storage cat gs://BUCKET_NAME/python-wordcount-out-SHARD_IDמפסיקים את סשן Flink YARN.
- מוצאים את מזהה האפליקציה.
yarn application -list1. Insert the <var>YARN_APPLICATION_ID</var>, then stop the session.yarn application -kill
הפעלת Flink באשכול עם Kerberos
רכיב Managed Service for Apache Spark Flink תומך באשכולות עם Kerberos. כדי לשלוח עבודת Flink ולשמור אותה או כדי להפעיל אשכול Flink, צריך כרטיס Kerberos תקף. כברירת מחדל, כרטיס Kerberos תקף למשך שבעה ימים.
גישה לממשק המשתמש של Flink Job Manager
ממשק האינטרנט של Flink Job Manager זמין בזמן שהפעלתם משימת Flink או אשכול של סשן Flink. כדי להשתמש בממשק האינטרנט:
- יצירת אשכול של Managed Service for Apache Spark Flink
- אחרי יצירת האשכול, לוחצים על Component Gateway YARN ResourceManager link בכרטיסייה Web Interface בדף Cluster details במסוף Google Cloud .
- בממשק המשתמש של YARN Resource Manager, מזהים את הרשומה של אפליקציית אשכול Flink. בהתאם לסטטוס ההשלמה של העבודה, יופיע קישור ל-ApplicationMaster או ל-History.
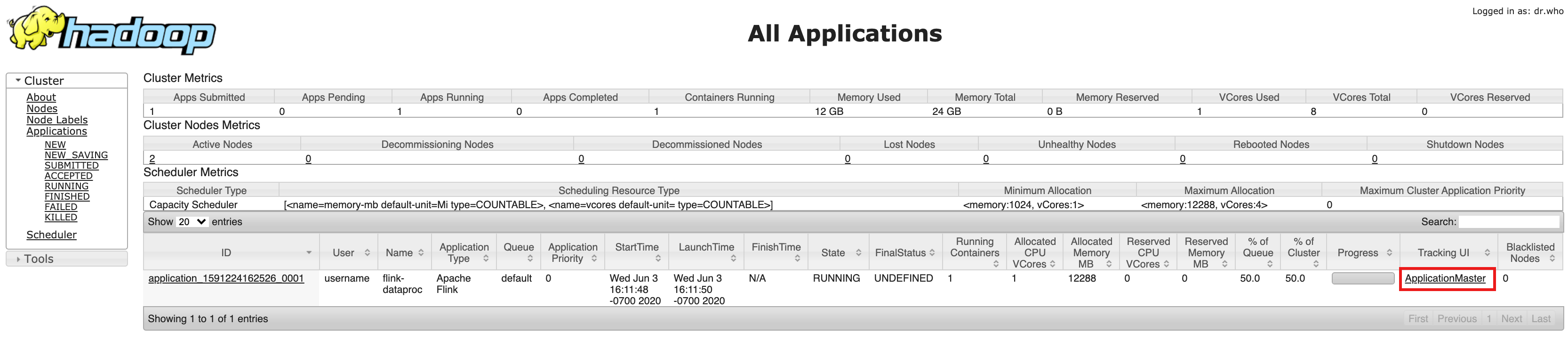
- כדי לפתוח את לוח הבקרה של Flink עבור משימת סטרימינג שפועלת במשך זמן רב, לוחצים על הקישור ApplicationManager. כדי לראות את פרטי המשימה שהושלמה, לוחצים על הקישור History.
