
Os pipelines de conectividade gerenciada importam metadados de fontes terceirizadas para o Knowledge Catalog (antigo Dataplex Universal Catalog). É possível usar esses pipelines para importar metadados para o Knowledge Catalog em grande escala e extrair dados das suas fontes. Os pipelines também criam grupos de entradas do Knowledge Catalog no projeto doGoogle Cloud , conforme necessário. Com essa abordagem, é possível orquestrar fluxos de trabalho e agendar jobs de importação de acordo com seus requisitos.
Você cria conectores personalizados para extrair metadados de várias fontes de terceiros, incluindo MySQL, SQL Server, Oracle, Snowflake e Databricks. Outra opção é usar conectores personalizados criados pela comunidade para uma variedade maior de fontes.
Como funciona a conectividade gerenciada
O diagrama a seguir mostra um pipeline de conectividade gerenciada.
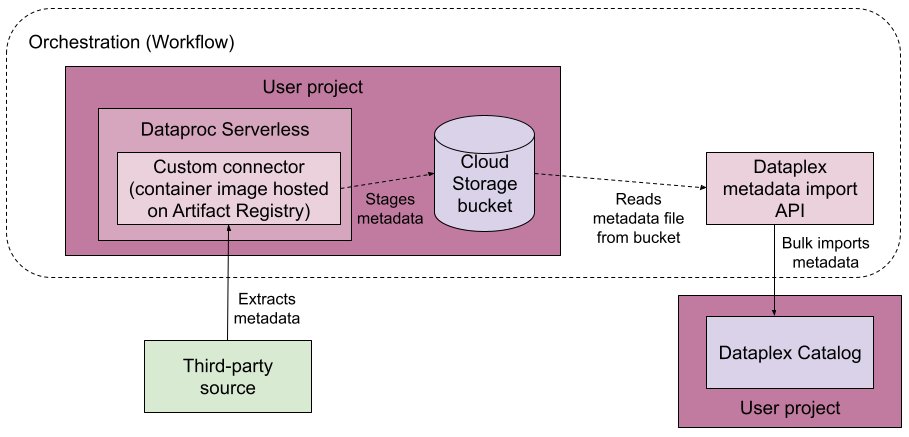
De modo geral, a conectividade gerenciada funciona assim:
Você cria um conector para a fonte de dados.
O conector precisa ser uma imagem do Artifact Registry que pode ser executada no Serviço Gerenciado para Apache Spark.
Você executa o pipeline de conectividade gerenciada no Workflows, uma plataforma de orquestração.
O pipeline de conectividade gerenciada realiza as seguintes ações:
- Cria um grupo de entrada de destino com base na configuração informada, se ele ainda não existir.
- Executa o conector. O conector extrai os metadados da fonte de dados e gera um arquivo para importação no Knowledge Catalog.
- Monitora o progresso da extração de metadados.
- Executa um job para importar os metadados para o Knowledge Catalog.
- Monitora o progresso do job de importação de metadados.
O pipeline de conectividade gerenciada usa o Serviço Gerenciado para Apache Spark para executar o conector. Também usa os métodos da API de importação de metadados do Knowledge Catalog para executar o job de importação.
Os metadados importados consistem em entradas do Knowledge Catalog e os respectivos aspectos. Para mais informações sobre os metadados do Knowledge Catalog, consulte Sobre o gerenciamento de metadados no Knowledge Catalog.
Conectores personalizados da comunidade
Uma opção para importar metadados de fontes de terceiros é usar os conectores personalizados da comunidade. O arquivo README de cada conector contém as instruções de configuração e mais informações sobre ele.
| Fonte de dados | Repositório |
|---|---|
| MySQL | mysql-connector |
| Oracle | oracle-connector |
| PostgreSQL | postgresql-connector |
| Snowflake | snowflake-connector |
| SQL Server | sql-server-connector |
A seguir
- Importar metadados de uma fonte personalizada usando o Workflows
- Desenvolver um conector personalizado para importação de metadados
- Importar metadados usando um pipeline personalizado