
In diesem Szenario verwalten Sie eine Datenbank, in der Datensätze zur Nutzung verschiedener Dienste eines Gesundheitsdienstleisters gespeichert sind. Um die Daten einfacher zu verwenden, durchsuchen Sie die Tabellen, um potenzielle Änderungen zu ermitteln. Bevor Sie die Änderungen implementieren, prüfen Sie, ob sich Verbesserungen auf vorhandene Arbeitsabläufe auswirken und ob zusätzliche Anpassungen erforderlich sind.
In dieser Anleitung verwenden Sie Data-Lineage, um zu ermitteln, wie sich Datentransformationen auf Downstream-Ressourcen und die Workflows auswirken, zu denen die Ressourcen gehören.
Jetzt starten
Um den Anwendungsfall abzuschließen, müssen Sie zuerst die Umgebung einrichten und die Datentransformationen ausführen. Auf der Seite Voraussetzungen und Einrichtung können Sie ein Remote-Repository mit Dataform verbinden. Dieses Repository enthält den Code, der zum Einrichten des Datasets und zum Transformieren der Daten erforderlich ist.
Nachdem Sie die Umgebung eingerichtet haben, können Sie mit BigQuery und dem Lineage Explorer Datentransformationen und ihre Auswirkungen auf die Workflows nachvollziehen.
Datentransformationen mit dem Lineage Explorer analysieren
Nachdem Sie das Dataset vorbereitet haben, können Sie die Auswirkungen der Datentransformation auf dem Tab Herkunft in BigQuery analysieren.
Datenintegrität von Spalten mit Lineage-Diagrammen prüfen
Sehen Sie sich in diesem Beispiel die Spalte medicare_participation_indicator an. Sie gibt an, ob ein Arzt oder Lieferant bereit ist, Leistungen für Medicare zu erbringen. Im Lineage-Diagramm sehen Sie, wie sich durch Datenumwandlungen zwischen den abgeleiteten Tabellen die Datentypen von Spalten ändern:
- Rufen Sie in der Google Cloud Console die Seite BigQuery auf.
- Suchen Sie über das Suchfeld nach der Tabelle
physicians_and_other_supplier_2012_original. - Klicken Sie auf den Tab Lineage.
- Führen Sie im Bereich Lineage Explorer die folgenden Schritte aus:
- Wählen Sie im Abschnitt Spaltenbezogene Herkunft den Spaltennamen
medicare_participation_indicatoraus der Liste aus. - Wählen Sie im Abschnitt Richtung die Richtung Downstream aus.
- Klicken Sie auf Übernehmen.
- Wählen Sie im Abschnitt Spaltenbezogene Herkunft den Spaltennamen
- Maximieren Sie den Lineage-Pfad, bis Sie
vertex_ai_model_final_featureserreichen. So analysieren Sie die Pfadänderungen zwischen der Tabelle
supplier_stg3und der Tabellesupplier_transform1: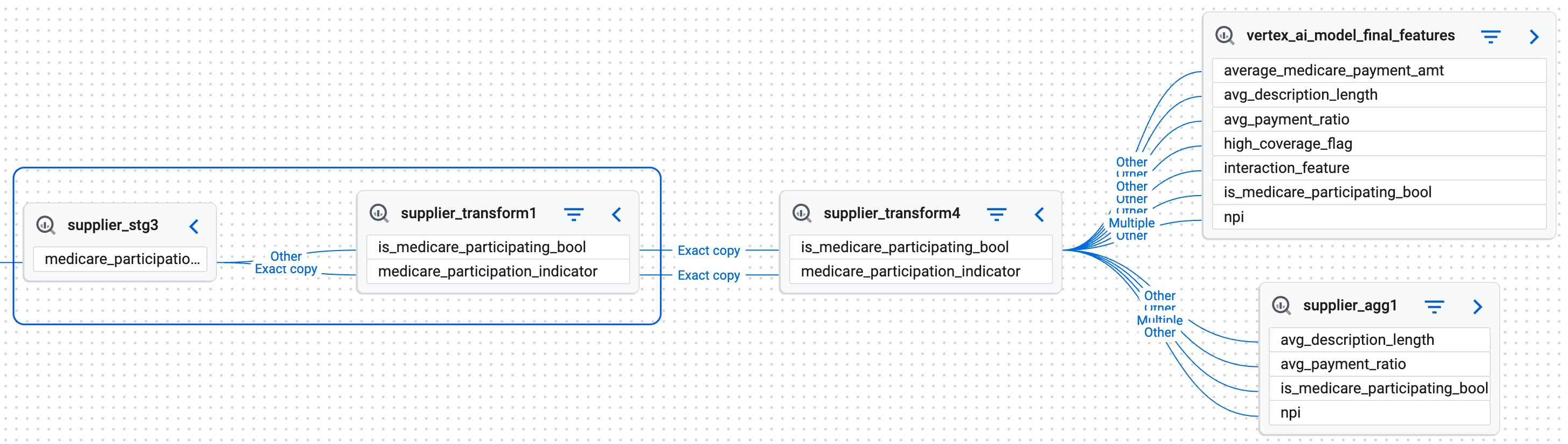
Visualisierung des Lineage-Tracking für die Spalte medicare_participation_indicator- Die Pfadmarkierung Exakte Kopie gibt an, dass die Spalte unverändert weitergegeben wird.
- Die Pfadmarkierung Other (Andere) weist auf eine Transformation hin. In diesem Pfad wird der Datentyp
StringwieBooleanbehandelt.
Der Pfad zeigt, dass sich die Datentypen der Spalten ändern. Das kann Anpassungen in den Workflows erfordern, in denen diese Tabellen verwendet werden.
Redundante Downstream-Spalten identifizieren
In diesem Beispiel wird die Spalte nppes_credentials untersucht, in der die National Provider Identifiers (NPIs) aufgeführt sind, die die Leistungserbringer im National Plan and Provider Enumeration System (NPPES) haben:
- Rufen Sie in der Google Cloud Console die Seite BigQuery auf.
- Suchen Sie über das Suchfeld nach der Tabelle
physicians_and_other_supplier_2012_original. - Klicken Sie auf den Tab Lineage.
- Führen Sie im Bereich Lineage Explorer die folgenden Schritte aus:
- Wählen Sie im Abschnitt Spaltenbezogene Herkunft den Spaltennamen
nppes_credentialsaus der Liste aus. - Wählen Sie im Abschnitt Richtung die Richtung Downstream aus.
- Klicken Sie auf Übernehmen.
- Wählen Sie im Abschnitt Spaltenbezogene Herkunft den Spaltennamen
- Maximieren Sie den Pfad, um zu prüfen, ob es nachgelagerte Lineage gibt, die zu
vertex_ai_model_final_featuresführt.
Wenn keine Herkunft angegeben ist, ist diese Spalte in diesem Workflow möglicherweise nicht relevant und kann sogar gelöscht werden.
Weitere Informationen zum Visualisieren von Daten mit dem Datenherkunftsdiagramm