
Wenn Sie Ihre Daten in verschiedenen Speichersystemen speichern, kann die Verwaltung der fragmentierten Sicherheit zu einer großen Herausforderung werden. Sie möchten sicherstellen, dass sensible Informationen wie Finanzdaten geschützt bleiben, auch wenn Sie sie in offenen Formaten wie Apache Iceberg im Google Cloud Speicher ablegen.
Ihre Sicherheitsmaßnahmen müssen nahtlos in verschiedenen Abfrage-Engines wie BigQuery SQL und Apache Spark funktionieren. In dieser Architektur löst Knowledge Catalog dieses Problem, indem es als universelle Kontext-Engine fungiert. Es enthält die Metadaten, die erforderlich sind, um sicherzustellen, dass Ihr Sicherheitskontext einheitlich angewendet wird, unabhängig davon, welche Engine die Daten abfragt.
In dieser Anleitung erstellen Sie ein sicheres Data Lakehouse, um diese Herausforderungen zu bewältigen. Mithilfe von Skripts definieren Sie Sicherheitsrichtlinien und sehen, wie Knowledge Catalog (früher Dataplex Universal Catalog) und Lakehouse for Apache Iceberg zusammenarbeiten, um die Richtlinien in verschiedenen Abfrage-Engines durchzusetzen.
Architektur
Um eine detaillierte Zugriffssteuerung für ein offenes Tabellenformat wie Apache Iceberg einzurichten, müssen Sie eine strenge, einheitliche Sicherheitsarchitektur erstellen.
Bei diesem Design fungiert Knowledge Catalog als zentrale Steuerungsebene. Knowledge Catalog erzwingt Ihren Sicherheitskontext dynamisch in allen unterstützten Engines.
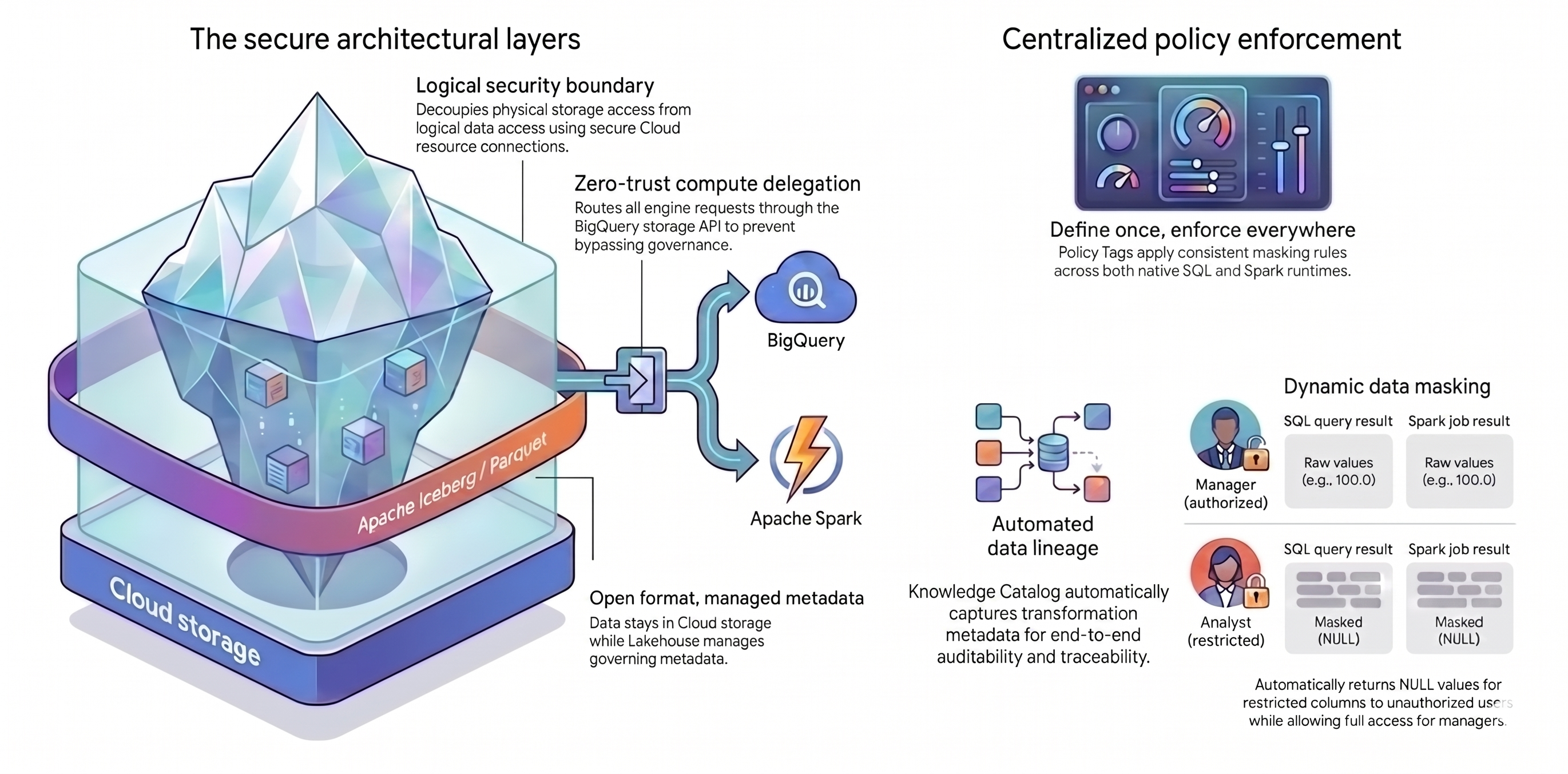
In dieser Anleitung werden zwei Hauptkonzepte verwendet, um diese einheitliche Architektur zu erstellen:
- Sichere Architekturebenen:Anstatt Nutzern oder Abfrage-Engines direkten Zugriff auf Ihre Cloud Storage-Buckets zu gewähren, erstellen Sie eine sichere, mehrschichtige Grundlage, die auf den folgenden Attributen basiert:
- Offenes Format mit verwalteten Metadaten:Ihre Daten bleiben im offenen Apache Iceberg-Format (Parquet) in Cloud Storage, während Lakehouse for Apache Iceberg die Tabellenmetadaten verwaltet.
- Logische Sicherheitsgrenze:Sie entkoppeln Speicherberechtigungen von Datenabfragen mithilfe einer sicheren Cloud-Ressourcenverbindung. Sie gewähren Endnutzern niemals direkten Zugriff auf die Dateien.
- Compute-Delegierung:Damit Abfrage-Engines Ihre Regeln nicht umgehen können, leiten Sie alle Datenanfragen über die BigQuery Storage API weiter. Durch das Weiterleiten von Anfragen über die BigQuery Storage API kann Knowledge Catalog Richtlinien auch für externe Verarbeitungs-Engines abfangen und erzwingen.
- Zentrale Richtliniendurchsetzung:Mit einer sicheren Grundlage können Sie Ihre Regeln universell mit Knowledge Catalog anwenden:
- Einmal definieren, überall erzwingen:Sie definieren Richtlinien-Tags nur einmal in Knowledge Catalog und die Plattform wendet einheitliche Maskierungsregeln auf alle unterstützten Abfrage-Engines an.
- Dynamische Datenmaskierung:Das System wertet die Nutzeridentität während der Abfragen aus. Autorisierte Nutzer sehen Rohwerte, während eingeschränkte Nutzer in allen Abfrage-Engines
NULL-Ausgaben erhalten. - Automatisierte Datenherkunft:Knowledge Catalog verfolgt Datentransformationen automatisch und erstellt einen Audit-Trail ohne benutzerdefinierten Logging-Code.
Ziele
- Von BigQuery verwaltete Apache Iceberg-Tabellen erstellen. Lakehouse verwaltet die Iceberg-Metadaten.
- Zentrale Sicherheitsregeln mit Richtlinien-Tags einrichten, um sensible Spalten zu maskieren und zu schützen.
- Physische Speicherberechtigungen von logischen Datenabfragen mithilfe einer Cloud-Ressourcenverbindung trennen.
- Abfragen sicher über Managed Service for Apache Spark weiterleiten, damit externe Engines Ihre Sicherheitsregeln nicht umgehen können.
- Eine interaktive Karte Ihrer Daten mit Data Lineage ansehen.
Hinweis
Führen Sie zuerst folgende Schritte aus:
- Wählen Sie ein Google Cloud Projekt für diese Anleitung aus.
- Prüfen Sie, ob die Abrechnung aktiviert ist für Ihr Projekt.
Umgebung vorbereiten
In dieser Anleitung wird Cloud Shell verwendet, eine Befehlszeilenumgebung, die in der Cloud ausgeführt wird.
Klicken Sie in der Google Cloud Console in der Symbolleiste rechts oben auf das Symbol Cloud Shell.
Legen Sie Ihre Projektvariablen fest:
export PROJECT_ID=$(gcloud config get-value project) export REGION="us-central1" export ICEBERG_BUCKET="iceberg-retail-demo-${PROJECT_ID}" export DATASET_ID="lakehouse_retail_demo" export CONN_NAME="iceberg-bq-conn-demo"Definieren Sie Variablen für zwei Nutzerrollen: einen Einzelhandelsanalysten und einen Einzelhandelsmanager:
export USER_ANALYST="retail-analyst-demo" export EMAIL_ANALYST="${USER_ANALYST}@${PROJECT_ID}.iam.gserviceaccount.com" export USER_MANAGER="retail-manager-demo" export EMAIL_MANAGER="${USER_MANAGER}@${PROJECT_ID}.iam.gserviceaccount.com" export CURRENT_USER=$(gcloud config get-value account)Aktivieren Sie die erforderlichen Google Cloud APIs.
gcloud services enable \ bigquery.googleapis.com \ bigqueryconnection.googleapis.com \ datacatalog.googleapis.com \ bigquerydatapolicy.googleapis.com \ datalineage.googleapis.com \ dataplex.googleapis.com \ dataproc.googleapis.com \ storage-component.googleapis.com
Quellcode der Anleitung herunterladen
Laden Sie die Python-Skripts für diese Anleitung aus dem Google Cloud DevRel-Repository herunter:
# Shallow clone without full history
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
# Download only the specific folder
git sparse-checkout set data-analytics/governed-lakehouse
cd data-analytics/governed-lakehouse
Storage-Bucket erstellen
Erstellen Sie einen neuen Bucket für Iceberg-Tabellendateien:
gcloud storage buckets create gs://${ICEBERG_BUCKET} --location=${REGION}
Identitäten und Sicherheit vorbereiten
In diesem Schritt richten Sie die Compute-Delegierung ein, indem Sie eine Cloud-Ressourcenverbindung erstellen. Diese Verbindung fungiert als sichere, delegierte Identität, die BigQuery zum Verwalten und Lesen Ihrer Iceberg-Dateien verwendet. So wird sichergestellt, dass einzelne Nutzer niemals direkten Zugriff auf Ihren Cloud Storage-Bucket haben.
Führen Sie die folgenden Befehle aus, um die Verbindung zu erstellen, das automatisch generierte Dienstkonto abzurufen und diesem Konto die Berechtigungen zu erteilen, die zum Verwalten Ihrer Iceberg-Daten erforderlich sind:
# Create the Cloud resource connection
bq mk --connection \
--connection_type=CLOUD_RESOURCE \
--location=${REGION} \
${CONN_NAME}
# Retrieve the connection's automatically generated Service Account
export BQ_CONN_SVC_ACCT=$(bq show --format=json --connection ${REGION}.${CONN_NAME} \
| jq -r '.cloudResource.serviceAccountId')
# Grant Storage Object Admin to the connection for the Iceberg bucket
gcloud storage buckets add-iam-policy-binding gs://${ICEBERG_BUCKET} \
--member="serviceAccount:${BQ_CONN_SVC_ACCT}" \
--role="roles/storage.objectAdmin" \
--quiet
Erstellen Sie Dienstkonten für zwei Rollen: Analyst und Manager. Mit den folgenden Befehlen werden diese Dienstkonten eingerichtet, Ihr aktueller Nutzer kann sie zu Testzwecken annehmen und ihnen bestimmte Rollen zum Ausführen von Abfragen und Anzeigen von Daten zugewiesen.
echo "Creating Service Accounts..."
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
gcloud iam service-accounts create ${USER} --display-name="Lakehouse ${USER}"
done
echo "⏳ Waiting 15 seconds for rules to apply..."
sleep 15
echo "Granting roles to service accounts..."
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
EMAIL="${USER}@${PROJECT_ID}.iam.gserviceaccount.com"
# Allow Cloud Shell to impersonate them for testing
gcloud iam service-accounts add-iam-policy-binding ${EMAIL} \
--member="user:${CURRENT_USER}" \
--role="roles/iam.serviceAccountTokenCreator" \
--quiet
# Allow logical viewing of the catalog, querying, and running Dataproc jobs
for ROLE in "roles/datacatalog.viewer" "roles/bigquery.dataViewer" "roles/bigquery.user" "roles/bigquery.connectionUser" "roles/serviceusage.serviceUsageConsumer" "roles/dataproc.worker"; do
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${EMAIL}" \
--role="${ROLE}" \
--quiet
done
done
# Grant the Manager data creation rights
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${EMAIL_MANAGER}" \
--role="roles/bigquery.dataEditor" \
--quiet
echo "✅ Identity and Security setup completed!"
Apache Iceberg-Tabellen erstellen
Erstellen Sie Apache Iceberg-Tabellen mit der BigQuery SQL-Engine. Obwohl Sie die Erstellungsbefehle mit BigQuery ausführen, fungiert Lakehouse als Verwaltungsebene, die die Tabellenmetadaten speichert und die zugrunde liegenden Parquet-Dateien in Cloud Storage schützt.
Nachdem Sie die Tabellen erstellt haben, führen Sie eine schnelle Transformation aus, um zu sehen, wie Knowledge Catalog die Sicherheit handhabt und die Datenreise automatisch verfolgt.
BigQuery-Dataset erstellen
Erstellen Sie zuerst ein BigQuery-Dataset, um Ihre Tabellen zu gruppieren:
echo "Creating BigQuery Dataset..."
bq mk --location=${REGION} --dataset ${PROJECT_ID}:${DATASET_ID}
Iceberg-Tabellen erstellen
Führen Sie die folgenden Befehle aus, um Bestands- und Transaktionstabellen zu erstellen:
echo "Creating Iceberg tables..."
# Inventory table
bq query --use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`${PROJECT_ID}.${DATASET_ID}.inventory\` (
product_id INT64,
product_name STRING,
stock_count INT64
)
WITH CONNECTION \`${REGION}.${CONN_NAME}\`
OPTIONS (
file_format = 'PARQUET',
table_format = 'ICEBERG',
storage_uri = 'gs://${ICEBERG_BUCKET}/inventory/'
);"
# Transactions table
bq query --use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`${PROJECT_ID}.${DATASET_ID}.transactions\` (
id INT64,
item STRING,
amount FLOAT64,
transaction_date DATE
)
WITH CONNECTION \`${REGION}.${CONN_NAME}\`
OPTIONS (
file_format = 'PARQUET',
table_format = 'ICEBERG',
storage_uri = 'gs://${ICEBERG_BUCKET}/transactions/'
);"
Beispieldaten einfügen
Fügen Sie Beispieldaten in die Tabellen ein:
echo "Inserting data into Iceberg tables..."
# Insert into Inventory table
bq query --use_legacy_sql=false \
"INSERT INTO \`${PROJECT_ID}.${DATASET_ID}.inventory\` (product_id, product_name, stock_count)
VALUES (101, 'Widget A', 500), (102, 'Widget B', 250), (103, 'Widget C', 800);"
# Insert into Transactions table
bq query --use_legacy_sql=false \
"INSERT INTO \`${PROJECT_ID}.${DATASET_ID}.transactions\` (id, item, amount, transaction_date)
VALUES
(1, 'Widget A', 100.0, DATE '2024-01-01'),
(2, 'Widget B', 150.0, DATE '2024-01-02'),
(3, 'Widget C', 50.0, DATE '2024-01-03');"
Sie haben jetzt zwei Iceberg-Tabellen mit Rohdaten. Lakehouse verwaltet die Metadaten, die eigentlichen Parquet-Dateien befinden sich jedoch in Ihrem Cloud Storage-Bucket.
Daten für die automatisierte Herkunft transformieren
Fassen Sie Ihre Rohdaten zu einer täglichen Umsatzübersicht zusammen. Bei dieser Transformation wird eine neue Tabelle erstellt und die Metadaten generiert, mit denen Knowledge Catalog die Datenreise automatisch zuordnet.
echo "Creating transactions summary table..."
bq query --use_legacy_sql=false \
"CREATE TABLE \`${PROJECT_ID}.${DATASET_ID}.transactions_summary\` AS
SELECT transaction_date, SUM(amount) as total_sales, COUNT(id) as transaction_count
FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`
GROUP BY transaction_date;"
Richtlinien für die Zugriffssteuerung definieren
In einer Produktionsumgebung werden Ihre Sicherheitsregeln als Code geschrieben (Infrastruktur als Code), wodurch Ihre Richtlinien wiederholbar, versionskontrolliert und einfacher zu verwalten sind. In diesem Abschnitt verwenden Sie das Google Cloud Python SDK, um Ihre Regeln automatisch zu definieren und zu erzwingen.
Virtuelle Python-Umgebung vorbereiten
Richten Sie eine isolierte virtuelle Python-Umgebung ein, um Ihre Abhängigkeiten zu verwalten und sicherzustellen, dass die Skripts zuverlässig ausgeführt werden:
# Create and activate a virtual environment
python3 -m venv lakehouse_env
source lakehouse_env/bin/activate
# Install required Knowledge Catalog and BigQuery governance libraries
pip install google-cloud-datacatalog google-cloud-bigquery-datapolicies google-cloud-bigquery --quiet
echo "✅ Python environment is ready!"
Sicherheitstaxonomien und -tags definieren
Erstellen Sie zuerst die Grundlage für Ihre Sicherheitsregeln. In diesem Schritt erstellen Sie eine Taxonomie als Container und ein Richtlinien-Tag als spezifisches Sicherheitslabel für sensible Daten.
Führen Sie das Skript aus, um die Ressourcen zu erstellen:
python 1_create_taxonomy.py
Sehen Sie sich 1_create_taxonomy.py an, um die Kernlogik zu sehen:
# Create Taxonomy with Fine-Grained Access Control enabled
taxonomy = datacatalog_v1.Taxonomy(
display_name="BusinessCritical",
activated_policy_types=[datacatalog_v1.Taxonomy.PolicyType.FINE_GRAINED_ACCESS_CONTROL]
)
created_taxonomy = client.create_taxonomy(parent=parent, taxonomy=taxonomy)
# Create Policy Tag inside the Taxonomy
policy_tag = datacatalog_v1.PolicyTag(display_name="RestrictedFinancial")
created_policy_tag = client.create_policy_tag(parent=created_taxonomy.name, policy_tag=policy_tag)
Wenn Sie den Richtlinientyp FINE_GRAINED_ACCESS_CONTROL explizit festlegen, wandeln Sie ein Standard-Metadaten-Tag in eine strenge Sicherheitsgrenze um, die standardmäßig den Zugriff verweigert. Für jede Spalte mit diesem Tag wird der Zugriff standardmäßig für alle Nutzer verweigert.
Richtlinie zur dynamischen Datenmaskierung erstellen
Definieren Sie nun, was passiert, wenn jemand ohne Berechtigungen eine Spalte mit einem Tag abfragt. Erstellen Sie eine Richtlinie zur Datenmaskierung , die sensible Werte für die Rolle Analyst automatisch durch NULL ersetzt.
Führen Sie das Skript aus, um die Maskierungsregel zu konfigurieren:
python 2_create_masking.py
In 2_create_masking.py sucht das Skript die ID für das von Ihnen erstellte Richtlinien-Tag und wendet die Datenrichtlinie auf das Dienstkonto Analyst an:
# Define a Masking Policy that always returns NULL
data_policy = bigquery_datapolicies_v1.DataPolicy(
data_policy_id="mask_financial_null",
policy_tag=policy_tag_id,
data_policy_type=bigquery_datapolicies_v1.DataPolicy.DataPolicyType.DATA_MASKING_POLICY,
data_masking_policy=bigquery_datapolicies_v1.DataMaskingPolicy(
predefined_expression=bigquery_datapolicies_v1.DataMaskingPolicy.PredefinedExpression.ALWAYS_NULL
)
)
# ... (Policy creation code) ...
# Bind the Masked Reader role to the Analyst
iam_policy.bindings.add(
role="roles/bigquerydatapolicy.maskedReader",
members=[f"serviceAccount:{analyst_email}"]
)
Privilegierten Zugriff auf Ihre Daten gewähren
Aufgrund Ihrer Standardeinstellung „Zugriff verweigern“ kann niemand die Spalte mit dem Tag lesen. Sie müssen autorisierten Nutzern explizit Zugriff gewähren. Weisen Sie der Rolle Manager und Ihrem eigenen Konto die Rolle „Detaillierter Lesezugriff“ zu. So können diese Nutzer die Maskierungsregeln umgehen und die nicht maskierten Daten lesen.
Führen Sie das Skript aus, um Zugriff zu gewähren:
python 3_grant_access.py
In 3_grant_access.py ändert das Skript die IAM-Richtlinie des Richtlinien-Tags:
# Grant original data read access
iam_policy.bindings.add(
role="roles/datacatalog.categoryFineGrainedReader",
members=[f"serviceAccount:{manager_email}", f"user:{current_user}"]
)
client.set_iam_policy(request=iam_policy_pb2.SetIamPolicyRequest(resource=policy_tag_id, policy=iam_policy))
Sicherheitstags an das Tabellenschema anhängen
Schließlich können Sie Ihre logischen Regeln mit den tatsächlichen Daten verknüpfen. Aktualisieren Sie Ihr Iceberg-Tabellenschema, um das Richtlinien-Tag direkt an die Spalte amount anzuhängen. Danach erzwingt Lakehouse Ihre Schutzmaßnahmen sofort für die Iceberg-Tabellendateien in Ihrem Bucket.
Führen Sie das Skript aus, um das Richtlinien-Tag anzuhängen:
python 4_attach_tag.py
Sehen Sie sich 4_attach_tag.py an. Das Skript ruft das BigQuery-Tabellenschema ab, durchläuft die Felder und hängt das Tag speziell an die Spalte amount an:
new_schema =[]
for field in table.schema:
if field.name == 'amount':
# Wrap the Policy Tag ID and attach it to the column
policy_tags_list = bigquery.PolicyTagList(names=[policy_tag_id])
new_field = bigquery.SchemaField(
name=field.name, field_type=field.field_type, mode=field.mode,
description=field.description, policy_tags=policy_tags_list
)
new_schema.append(new_field)
else:
new_schema.append(field)
# Update the table schema in BigQuery
table.schema = new_schema
client.update_table(table, ["schema"])
Sicherheitsrichtlinien prüfen
Führen Sie einige Testabfragen aus, um zu prüfen, ob Ihre Berechtigungen wie erwartet funktionieren. Um zu beweisen, dass Knowledge Catalog als universelle Kontext-Engine fungiert, indem es dieselben Sicherheitsrichtlinien erzwingt, wenn Sie die Abfrage-Engine wechseln, führen Sie diese Tests sowohl mit BigQuery als auch mit Apache Spark aus.
Mit BigQuery SQL testen
Prüfen Sie zuerst Ihre Richtlinien direkt in BigQuery. So können Sie am schnellsten bestätigen, dass Ihre Maskierungsregeln und Berechtigungen aktiv sind.
Als Manager prüfen
Die Rolle Manager hat privilegierten, detaillierten Lesezugriff. Sie sollten alle Details in der Tabelle sehen, einschließlich der Werte in der Spalte amount.
# Impersonate the Manager
gcloud config set auth/impersonate_service_account ${EMAIL_MANAGER}
# Query the transactions table
bq query --use_legacy_sql=false "SELECT * FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`"
Da der Manager die Rolle „Detaillierter Lesezugriff“ hat, werden in der Abfrage die Rohwerte für den Betrag angezeigt:
+----+----------+--------+------------------+
| id | item | amount | transaction_date |
+----+----------+--------+------------------+
| 1 | Widget A | 100.0 | 2024-01-01 |
| 3 | Widget C | 50.0 | 2024-01-03 |
| 2 | Widget B | 150.0 | 2024-01-02 |
+----+----------+--------+------------------+
Als Analyst prüfen
Wechseln Sie zur Rolle Analyst und führen Sie dieselbe Abfrage aus.
gcloud config set auth/impersonate_service_account ${EMAIL_ANALYST}
bq query --use_legacy_sql=false "SELECT * FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`"
Obwohl Sie dieselbe Abfrage ausführen, maskiert Knowledge Catalog die sensiblen Werte in der Spalte amount:
+----+----------+--------+------------------+
| id | item | amount | transaction_date |
+----+----------+--------+------------------+
| 1 | Widget A | NULL | 2024-01-01 |
| 3 | Widget C | NULL | 2024-01-03 |
| 2 | Widget B | NULL | 2024-01-02 |
+----+----------+--------+------------------+
Zu Ihrem Konto zurückkehren
Bereinigen Sie den Cloud Shell-Authentifizierungsstatus, um zu Ihrem Administratorkonto zurückzukehren.
gcloud config unset auth/impersonate_service_account
Mit Apache Spark testen
Die Sicherheit wird oft verletzt, wenn Nutzer direkt auf Datendateien in Cloud Storage zugreifen. Wenn ein Data Scientist Apache Spark verwendet, um die Iceberg-Tabellendateien direkt zu lesen, umgeht er normalerweise Ihre Regeln, da Cloud Storage nur Berechtigungen auf Bucket-Ebene versteht.
Verwenden Sie die Compute-Delegierung, um dies zu verhindern. Mit dem Spark-BigQuery-Connector erstellen Sie eine sichere Brücke, die alle Spark-Anfragen über die BigQuery Storage API weiterleitet. So wird sichergestellt, dass Knowledge Catalog Berechtigungen prüft und Maskierungsregeln anwendet, bevor Daten den Spark-Cluster erreichen.
Laden Sie das Skript read_transactions.py in Ihren Cloud Storage-Bucket hoch, damit Managed Service for Apache Spark darauf zugreifen kann:
# Upload script to Cloud Storage
gsutil cp read_transactions.py gs://${ICEBERG_BUCKET}/scripts/read_transactions.py
Sehen Sie sich die Kernlogik im hochgeladenen Skript an:
# Reading data via Compute Delegation (Knowledge Catalog policies are applied dynamically here)
df = spark.read \
.format("bigquery") \
.option("table", f"{project_id}.{dataset_id}.{table_name}") \
.load()
print("\n=== 📊 Data Preview ===")
df.show(truncate=False)
Das Skript verweist Spark nicht auf den gs://-Pfad der Iceberg-Dateien. Durch Angabe von .format("bigquery") fängt die BigQuery Storage API die Leseanfrage ab, prüft die Identität des Nutzers, der den Spark-Job ausführt, wendet die Knowledge Catalog-Maskierungsregeln an und gibt nur die autorisierten Daten an den Spark-DataFrame zurück.
Spark als Manager ausführen
Senden Sie einen Spark-Job als Rolle Manager. Verwenden Sie Managed Service for Apache Spark, einen verwalteten Dienst, mit dem Sie Spark-Arbeitslasten ausführen können, ohne eigene Cluster verwalten zu müssen:
echo "🚀 Submitting Dataproc Serverless Job as [MANAGER]..."
gcloud dataproc batches submit pyspark gs://${ICEBERG_BUCKET}/scripts/read_transactions.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--service-account=${EMAIL_MANAGER} \
--version=2.3 \
-- ${PROJECT_ID} ${DATASET_ID} \
--format="value(name)"
Sehen Sie sich die Ausgabelogs des Jobs im Terminal an. Da der Manager die Rolle „Detaillierter Lesezugriff“ hat, ruft Spark die nicht maskierten Beträge erfolgreich ab:
=== 📊 Data Preview ===
+---+--------+------+-------------------+
|id |item |amount|transaction_date |
+---+--------+------+-------------------+
|1 |Widget A|100.0 |2024-01-01 |
|2 |Widget B|150.0 |2024-01-02 |
|3 |Widget C|50.0 |2024-01-03 |
+---+--------+------+-------------------+
Spark als Analyst ausführen
Führen Sie schließlich denselben Spark-Code als Rolle Analyst aus:
echo "🚀 Submitting Dataproc Serverless Job as [ANALYST]..."
gcloud dataproc batches submit pyspark gs://${ICEBERG_BUCKET}/scripts/read_transactions.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--service-account=${EMAIL_ANALYST} \
--version=2.3 \
-- ${PROJECT_ID} ${DATASET_ID} \
--format="value(name)"
Sehen Sie sich die Logs noch einmal an. Obwohl der Analyst denselben Spark-Code ausgeführt hat, hat die BigQuery Storage API die Anfrage abgefangen und die Knowledge Catalog-Richtlinie erzwungen. Im Spark-DataFrame des Analysten wird für die Beträge null angezeigt.
=== 📊 Data Preview ===
+---+--------+------+-------------------+
|id |item |amount|transaction_date |
+---+--------+------+-------------------+
|1 |Widget A|null |2024-01-01 |
|2 |Widget B|null |2024-01-02 |
|3 |Widget C|null |2024-01-03 |
+---+--------+------+-------------------+
Sie haben gerade bewiesen, dass Knowledge Catalog als zentrale Steuerungsebene Ihre Sicherheitsrichtlinien unabhängig von der verwendeten Abfrage-Engine einheitlich erzwingt.
Datenreise mit automatisierter Herkunft nachvollziehen
Ein richtlinienkonformes Lakehouse erfordert mehr als nur Zugriffssteuerungen, sondern auch einen klaren Audit-Trail. Data Lineage hilft Ihnen zu verstehen, woher Ihre Daten stammen und wie sie sich verändern. Wenn Sie wichtige Fragen beantworten, z. B. „Welche Rohdaten wurden verwendet, um diesen Umsatzbericht zu erstellen?“, können Sie die Compliance einhalten, Daten-Pipelines schnell debuggen und eine zuverlässige Datengrundlage schaffen.
Anstatt komplexen Logging-Code manuell zu schreiben, verfolgt Knowledge Catalog diesen Lebenszyklus automatisch in Ihrer Architektur. Als Sie beispielsweise zuvor in dieser Anleitung eine Zusammenfassungstabelle erstellt haben, hat BigQuery die Details der Transformation sofort erfasst und an Knowledge Catalog gesendet. Dadurch wurden Kontext und Verlauf Ihrer Daten dynamisch aktualisiert.
Interaktives Herkunftsdiagramm ansehen
Sehen Sie sich die interaktive Karte an, die von Knowledge Catalog generiert wurde. Sie zeigt, wie Rohdaten aus der transactions Tabelle in die transactions_summary Tabelle fließen. Da Knowledge Catalog Metadaten als dynamische Kontext-Engine erfasst, zeigt dieses Diagramm die zuverlässige Echtzeit-Nachverfolgbarkeit, die Sie für ein Datenaudit benötigen.
- Gehen Sie in der Google Cloud Console zu Knowledge Catalog > Suchen.
- Geben Sie in der Suchleiste
lakehouse_retail_demo.transactions_summaryein und klicken Sie auf die Tabelle. - Klicken Sie auf den Tab Herkunft.
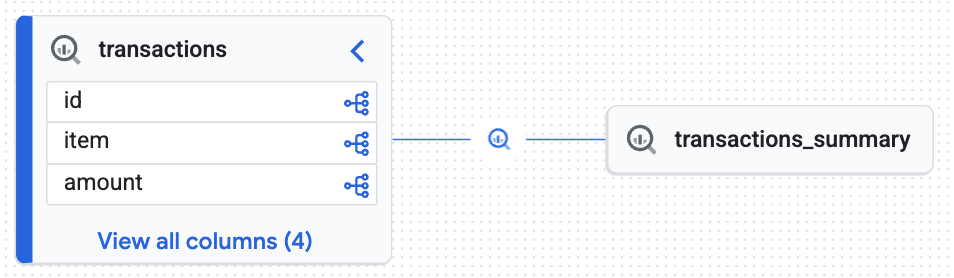
Das interaktive Diagramm bestätigt, dass die Zieltabelle (transactions_summary) aus der verwalteten Iceberg-Rohdatentabelle (transactions) abgeleitet wird. Diese Visualisierung zeigt die End-to-End-Nachverfolgbarkeit Ihrer Daten.
Bereinigen
Entfernen Sie die für diese Anleitung erstellten Ressourcen, um laufende Kosten zu vermeiden.
Richtlinien- und Metadaten-Assets entfernen
Bevor Sie das BigQuery-Dataset oder den Cloud Storage-Bucket löschen können, müssen Sie die Richtlinien zur Datenverwaltung und die Metadaten-Assets löschen.
Führen Sie das Python-Bereinigungsskript aus:
python cleanup_governance.py
Sehen Sie sich das Skript cleanup_governance.py aus dem Repository an, um die folgende Bereinigungslogik zu finden. Die Reihenfolge beim Löschen ist wichtig. Löschen Sie zuerst die Richtlinie zur Datenmaskierung. Löschen Sie dann die übergeordnete Taxonomie. Dadurch werden alle zugrunde liegenden Richtlinien-Tags automatisch entfernt und Fehler aufgrund von Ressourcenabhängigkeiten vermieden.
# 1. Delete Data Policy
data_policy_name = f"{parent_loc}/dataPolicies/mask_financial_null"
dp_client.delete_data_policy(name=data_policy_name)
# 2. Find and Delete Taxonomy (This auto-deletes child Policy Tags)
taxonomies = catalog_client.list_taxonomies(parent=parent_loc)
taxonomy_id = next((t.name for t in taxonomies if t.display_name == "BusinessCritical"), None)
catalog_client.delete_taxonomy(name=taxonomy_id)
Identitäten, Speicher- und Compute-Assets entfernen
Löschen Sie die BigQuery-Tabellen, Cloud Storage-Buckets, Dienstkonten und die lokale virtuelle Python-Umgebung.
Kopieren Sie das folgende Bereinigungsskript und führen Sie es in Cloud Shell aus:
echo "Deleting Service Accounts and Impersonation Bindings..."
export CURRENT_USER=$(gcloud config get-value account)
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
EMAIL="${USER}@${PROJECT_ID}.iam.gserviceaccount.com"
# Remove impersonation binding
gcloud iam service-accounts remove-iam-policy-binding ${EMAIL} \
--member="user:${CURRENT_USER}" \
--role="roles/iam.serviceAccountTokenCreator" \
--quiet > /dev/null 2>&1
# Delete the Service Account
gcloud iam service-accounts delete ${EMAIL} --quiet
done
echo "Removing BigQuery Dataset and Tables..."
bq rm -f ${DATASET_ID}.transactions_summary
bq rm -f ${DATASET_ID}.transactions
bq rm -f ${DATASET_ID}.inventory
bq rm -f -d ${DATASET_ID}
echo "Removing BigQuery Cloud Resource Connection..."
bq rm --connection --location=${REGION} ${CONN_NAME}
echo "Removing Iceberg Cloud Storage Bucket..."
gcloud storage rm --recursive gs://${ICEBERG_BUCKET} --quiet
echo "Removing Auto-generated Dataproc Staging & Temp Buckets..."
for BUCKET in $(gcloud storage ls | grep -E "gs://dataproc-(staging|temp)-${REGION}"); do
gcloud storage rm --recursive $BUCKET --quiet
done
echo "✅ Clean up completed successfully!"
Bereinigen Sie die Projektdateien:
echo "Deactivating and removing the local Python environment..."
deactivate
cd ../..
rm -rf devrel-demos
Fazit
Sie haben ein sicheres Data Lakehouse erstellt. Mit Lakehouse for Apache Iceberg zum Verwalten von Iceberg-Tabellen haben Sie die zugrunde liegenden Tabellendateien in Cloud Storage geschützt. Indem Sie Knowledge Catalog als universelle Kontext-Engine eingerichtet haben, haben Sie Richtlinien-Tags an einem zentralen Ort definiert und sie einheitlich in verschiedenen Abfrage-Engines wie BigQuery SQL und Apache Spark angewendet. Schließlich haben Sie die gesamte Datenreise mit Data Lineage in Echtzeit automatisch verfolgt.
Nächste Schritte
- Datenkontext für KI-Agenten abrufen: Rufen Sie Datenkontext mit der Context API ab.
- Data Lineage im Detail: Informationen zur Datenherkunft ansehen.
- Erweiterte Zugriffssteuerung:Informationen zum Implementieren komplexerer Sicherheitsszenarien finden Sie in der offiziellen Dokumentation zum Anpassen von Lakehouse mit zusätzlichen Funktionen.
- Managed Service for Apache Spark:Informationen zum Skalieren von Daten-Pipelines ohne Bereitstellung von Clustern finden Sie auf der Dokumentationsseite zu Serverless Spark.
- Weitere Anwendungsfälle: Weitere Anwendungsfälle für Knowledge Catalog ausprobieren.