
Sie können die Datenherkunft aufrufen, um die Beziehungen zwischen den Ressourcen Ihres Projekts und den Prozessen zu verstehen, mit denen sie erstellt wurden. Diese Beziehungen zeigen, wie Daten-Assets wie Tabellen und Datasets durch Prozesse wie Abfragen und Pipelines transformiert werden. In dieser Anleitung wird beschrieben, wie Sie Details zur Datenherkunft in der Google Cloud Console aufrufen oder mit der Data Lineage API abrufen.
Rollen und Berechtigungen
Die Datenherkunft erfasst automatisch Informationen zur Herkunft, wenn Sie die Data Lineage APIaktivieren. Sie benötigen keine Administrator- oder Bearbeiterrollen, um die Herkunft für Ihre Daten-Assets zu erfassen.
Zum Aufrufen der Datenherkunft benötigen Sie bestimmte IAM-Berechtigungen (Identity and Access Management). Informationen zur Herkunft werden projektübergreifend erfasst. Daher benötigen Sie Berechtigungen in mehreren Projekten.
Wenn Sie die Herkunft in Knowledge Catalog, BigQuery oder Vertex AI aufrufen, benötigen Sie Berechtigungen, um Informationen zur Herkunft in dem Projekt aufzurufen, in dem Sie sie ansehen.
Wenn Sie die Herkunft aufrufen, die in anderen Projekten erfasst wurde, benötigen Sie Berechtigungen, um Informationen zur Herkunft in diesen Projekten aufzurufen.
Bitten Sie Ihren Administrator, Ihnen die folgenden IAM-Rollen zuzuweisen, um die Berechtigungen zu erhalten, die Sie zum Aufrufen der Datenherkunft benötigen:
- Data Lineage-Betrachter (
roles/datalineage.viewer) für das Projekt, in dem die Herkunft erfasst wird, und das Projekt, in dem die Herkunft aufgerufen wird -
BigQuery-Tabellendetails aufrufen:
BigQuery-Datenbetrachter (
roles/bigquery.dataViewer) für das Speicherprojekt der Tabelle -
BigQuery-Jobdetails aufrufen:
BigQuery-Ressourcenbetrachter (
roles/bigquery.resourceViewer) für das Compute-Projekt des Jobs -
Details zu anderen katalogisierten Assets aufrufen:
Dataplex Catalog-Betrachter (
roles/dataplex.catalogViewer) für das Projekt, in dem Katalogeinträge gespeichert sind
Weitere Informationen zum Zuweisen von Rollen finden Sie unter Zugriff auf Projekte, Ordner und Organisationen verwalten.
Diese vordefinierten Rollen enthalten die Berechtigungen, die zum Aufrufen der Datenherkunft erforderlich sind. Maximieren Sie den Abschnitt Erforderliche Berechtigungen , um die notwendigen Berechtigungen anzuzeigen, die erforderlich sind:
Erforderliche Berechtigungen
Zum Aufrufen der Datenherkunft sind die folgenden Berechtigungen erforderlich:
-
BigQuery-Tabellendetails aufrufen:
bigquery.tables.getfür das Speicherprojekt der Tabelle -
BigQuery-Jobdetails aufrufen:
bigquery.jobs.getfür das Compute-Projekt des Jobs
Sie können diese Berechtigungen auch mit benutzerdefinierten Rollen oder anderen vordefinierten Rollen erhalten.
Arten von Datenherkunftsansichten
Sie können Informationen zur Herkunft in der Google Cloud Console als interaktives Diagramm oder als strukturierte Liste aufrufen.
Eine detaillierte Beschreibung der Diagrammelemente (z. B. Knoten, Kanten, Prozesssymbole und Labels) und der in den Listenansichten verfügbaren Spalten finden Sie unter Datenherkunft in Knowledge Catalog visualisieren.
Datenherkunft aktivieren
Aktivieren Sie die Datenherkunft, um automatisch Informationen zur Herkunft für unterstützte Systeme zu erfassen. Standardmäßig wird durch das Aktivieren der API die Erfassung der Herkunft für die meisten unterstützten Dienste aktiviert. Informationen zum Steuern der Erfassung der Herkunft für Managed Service for Apache Spark finden Sie unter Erfassung der Herkunft für einen Dienst steuern.
Sie müssen die Data Lineage API sowohl in dem Projekt aktivieren, in dem Sie die Herkunft aufrufen, als auch in den Projekten, in denen die Herkunft erfasst wird. Weitere Informationen finden Sie unter Projekttypen.
- Führen Sie die folgenden Schritte aus, um Informationen zur Herkunft zu erfassen:
-
Wählen Sie in der Google Cloud Console auf der Seite Projektauswahl das Projekt aus, in dem Sie die Herkunft erfassen möchten.
Aktivieren Sie die Data Lineage API.
- Wiederholen Sie die vorherigen Schritte für jedes Projekt, in dem Sie die Herkunft erfassen möchten.
-
Aktivieren Sie im Projekt, in dem Sie die Herkunft aufrufen, die Data Lineage API und die Dataplex API.
Erfassung der Herkunft für einen Dienst steuern
Sie können die automatische Erfassung der Herkunft für bestimmte Dienste auf Projekt-, Ordner- oder Organisationsebene selektiv aktivieren oder deaktivieren.
Weitere Informationen dazu, wie diese Konfigurationen hierarchisch über die Ressourcenstruktur angewendet werden, finden Sie unter Erfassung der Herkunft steuern.
Herkunft ansehen
Wenn Sie nachverfolgen möchten, wie Daten transformiert und zwischen Systemen verschoben werden, können Sie die Datenherkunft in der Google Cloud Console oder mit der API aufrufen.
Console
Sie können in der Google Cloud Console von verschiedenen Ausgangspunkten aus auf Informationen zur Datenherkunft zugreifen:
- Knowledge Catalog:Rufen Sie die Seite Suchen in Knowledge Catalog auf, wählen Sie Knowledge Catalog als Suchmodus aus, suchen Sie nach dem Eintrag, den Sie aufrufen möchten, und klicken Sie dann darauf. Weitere Informationen finden Sie unter Nach Ressourcen in Knowledge Catalog suchen.
- BigQuery:Rufen Sie die Seite BigQuery auf und öffnen Sie die Tabelle, für die Sie die Datenherkunft aufrufen möchten.
- Vertex AI:Rufen Sie die Seite Datasets oder Model Registry auf und klicken Sie auf das Dataset oder Modell, für das Sie die Datenherkunft aufrufen möchten.
So rufen Sie das Herkunftsdiagramm auf:
Klicken Sie auf den Tab Herkunft.
Die Standardansicht Diagramm wird geöffnet und zeigt die Herkunft auf Tabellenebene über Systeme und Regionen hinweg. Weitere Informationen finden Sie unter Herkunftsdiagrammansicht.
Wenn Sie das Herkunftsdiagramm manuell untersuchen möchten, klicken Sie neben einem Knoten auf Maximieren , um jeweils fünf weitere Knoten zu laden.
Weitere Informationen finden Sie unter Herkunftsdiagramm manuell untersuchen.
Klicken Sie in der Ansicht Diagramm auf einen Knoten.
Der Bereich Details wird mit Informationen zum Asset geöffnet, z. B. mit dem voll qualifizierten Namen und dem Typ. Weitere Informationen finden Sie unter Knotendetails.
Klicken Sie in der Ansicht Diagramm auf eine Kante mit einem Prozesssymbol.
Der Bereich Abfrage wird geöffnet. Weitere Informationen finden Sie unter Transformationslogik prüfen und Audit und Verlauf von Ausführungen.
- Klicken Sie auf den Tab Details, um die Transformationslogik zu prüfen.
- Klicken Sie auf den Tab Ausführungen, um Audit und Verlauf von Ausführungen aufzurufen.
Wählen Sie im Bereich Lineage Explorer Filterkriterien aus, z. B. Richtung, Abhängigkeitstyp oder Zeitraum, und klicken Sie dann auf Anwenden.
Dadurch wird eine fokussierte Ansicht in einer bestimmten Region geöffnet (Vorschau). In dieser Ansicht wird das Diagramm automatisch auf bis zu drei Knotenebenen erweitert. Weitere Informationen finden Sie unter Filter für eine fokussierte Herkunftsansicht anwenden.
Wählen Sie in der fokussierten Ansicht Diagramm einen Knoten aus und klicken Sie dann im Bereich mit den Knotendetails auf Pfad visualisieren , um den Herkunftspfad vom ausgewählten Knoten zurück zum Stammeintrag zu visualisieren (nur in der fokussierten Ansicht).
Weitere Informationen finden Sie unter Visualisierung des Herkunftspfads.
Führen Sie einen der folgenden Schritte aus, um die Herkunft auf Spaltenebene aufzurufen (nur für BigQuery- und Managed Service for Apache Spark-Jobs):
- Klicken Sie in einer fokussierten Ansicht Diagramm auf das Spaltensymbol in einer Tabelle.
Spaltensymbol - Filtern Sie im Bereich Lineage Explorer nach Spaltenname und klicken Sie auf Anwenden.
Weitere Informationen finden Sie unter Herkunft auf Spaltenebene.
- Klicken Sie in einer fokussierten Ansicht Diagramm auf das Spaltensymbol in einer Tabelle.
Klicken Sie auf Zurücksetzen.
Dadurch werden alle angewendeten Filter entfernt und Sie werden zum Anfang der Diagrammansicht weitergeleitet.
Klicken Sie auf Liste , um zur Listenansicht zu wechseln.
Die Ansicht Liste bietet vereinfachte und detaillierte tabellarische Darstellungen der Herkunft sowohl auf Tabellen- als auch auf Spaltenebene, die mit der Ansicht Diagramm synchronisiert sind. Standardmäßig wird die vereinfachte Listenansicht angezeigt. Sie können zur detaillierten Listenansicht wechseln, um einzelne Quell-Ziel-Beziehungen zu analysieren. Sie können konfigurieren, welche Spalten angezeigt werden, und Herkunftsdaten exportieren. Weitere Informationen finden Sie unter Herkunftslistenansicht.
Java
import com.google.api.gax.rpc.ApiException;
import com.google.cloud.datacatalog.lineage.v1.BatchSearchLinkProcessesRequest;
import com.google.cloud.datacatalog.lineage.v1.EntityReference;
import com.google.cloud.datacatalog.lineage.v1.EventLink;
import com.google.cloud.datacatalog.lineage.v1.LineageClient;
import com.google.cloud.datacatalog.lineage.v1.LineageEvent;
import com.google.cloud.datacatalog.lineage.v1.Link;
import com.google.cloud.datacatalog.lineage.v1.ListLineageEventsRequest;
import com.google.cloud.datacatalog.lineage.v1.ListRunsRequest;
import com.google.cloud.datacatalog.lineage.v1.LocationName;
import com.google.cloud.datacatalog.lineage.v1.ProcessLinks;
import com.google.cloud.datacatalog.lineage.v1.Run;
import com.google.cloud.datacatalog.lineage.v1.SearchLinksRequest;
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashSet;
import java.util.LinkedList;
import java.util.List;
import java.util.Queue;
import java.util.Set;
public class ViewLineageExample {
public static void main(String[] args) throws IOException {
// TODO(developer): Replace these variables before running the sample.
String projectId = "my-project-id";
String location = "us";
String targetFullyQualifiedName = "bigquery:my-project-id.my_dataset.my_table";
int maxDepth = 3;
viewLineage(projectId, location, targetFullyQualifiedName, maxDepth);
}
static class Node {
String fqn;
int depth;
Node(String fqn, int depth) {
this.fqn = fqn;
this.depth = depth;
}
}
public static void viewLineage(
String projectId, String location, String targetFullyQualifiedName, int maxDepth)
throws IOException {
// Initialize client that will be used to send requests. This client only needs
// to be created once, and can be reused for multiple requests.
try (LineageClient client = LineageClient.create()) {
String parent = LocationName.of(projectId, location).toString();
Set<String> visitedNodes = new HashSet<>();
Queue<Node> queue = new LinkedList<>();
visitedNodes.add(targetFullyQualifiedName);
queue.offer(new Node(targetFullyQualifiedName, 0));
while (!queue.isEmpty()) {
Node current = queue.poll();
System.out.printf("\nExploring node (Depth %d): %s\n", current.depth, current.fqn);
if (current.depth >= maxDepth) {
continue;
}
EntityReference targetEntity =
EntityReference.newBuilder().setFullyQualifiedName(current.fqn).build();
SearchLinksRequest searchLinksRequest =
SearchLinksRequest.newBuilder().setParent(parent).setTarget(targetEntity).build();
List<String> linkNames = new ArrayList<>();
try {
// 1. Search for links related to the target entity
for (Link link : client.searchLinks(searchLinksRequest).iterateAll()) {
linkNames.add(link.getName());
}
} catch (ApiException e) {
System.out.printf(" Failed to retrieve links for %s: %s\n", current.fqn, e.getMessage());
continue;
}
if (linkNames.isEmpty()) {
continue;
}
// 2. Batch search for processes in chunks of 100
for (int i = 0; i < linkNames.size(); i += 100) {
List<String> batch = linkNames.subList(i, Math.min(linkNames.size(), i + 100));
BatchSearchLinkProcessesRequest batchSearchRequest =
BatchSearchLinkProcessesRequest.newBuilder()
.setParent(parent)
.addAllLinks(batch)
.build();
try {
for (ProcessLinks processLinks :
client.batchSearchLinkProcesses(batchSearchRequest).iterateAll()) {
String processName = processLinks.getProcess();
System.out.printf(" Process: %s\n", processName);
// 3. List runs for the process
ListRunsRequest runsRequest =
ListRunsRequest.newBuilder().setParent(processName).build();
for (Run run : client.listRuns(runsRequest).iterateAll()) {
System.out.printf(" Run: %s\n", run.getName());
// 4. List events for the run
ListLineageEventsRequest eventsRequest =
ListLineageEventsRequest.newBuilder().setParent(run.getName()).build();
for (LineageEvent event : client.listLineageEvents(eventsRequest).iterateAll()) {
for (EventLink eventLink : event.getLinksList()) {
String sourceFqn = eventLink.getSource().getFullyQualifiedName();
// If exploring upstream, queue the source
if (!sourceFqn.isEmpty() && !visitedNodes.contains(sourceFqn)) {
visitedNodes.add(sourceFqn);
queue.offer(new Node(sourceFqn, current.depth + 1));
}
}
}
}
}
} catch (ApiException e) {
System.out.printf(" Failed to retrieve processes/runs: %s\n", e.getMessage());
}
}
}
}
}
}
Python
from google.cloud import datacatalog_lineage_v1
from google.api_core.exceptions import GoogleAPICallError
def view_lineage(project_id: str, location: str, target_fully_qualified_name: str, max_depth: int = 3):
"""Retrieves lineage for a given entity using a depth-limited search."""
client = datacatalog_lineage_v1.LineageClient()
parent = f"projects/{project_id}/locations/{location}"
# Store visited nodes to avoid infinite loops in cyclic graphs
visited_nodes = set([target_fully_qualified_name])
queue = [(target_fully_qualified_name, 0)]
while queue:
current_node, current_depth = queue.pop(0)
print(f"\nExploring node (Depth {current_depth}): {current_node}")
if current_depth >= max_depth:
continue
target_entity = datacatalog_lineage_v1.EntityReference(
fully_qualified_name=current_node
)
search_links_request = datacatalog_lineage_v1.SearchLinksRequest(
parent=parent,
target=target_entity,
)
try:
links = list(client.search_links(request=search_links_request))
except GoogleAPICallError as e:
print(f" Failed to retrieve links for {current_node}: {e.message}")
continue
if not links:
continue
# Extract link names to query processes in batches
link_names = [link.name for link in links]
# Batch max size is 100
for i in range(0, len(link_names), 100):
batch = link_names[i:i + 100]
batch_request = datacatalog_lineage_v1.BatchSearchLinkProcessesRequest(
parent=parent,
links=batch
)
try:
for process_links in client.batch_search_link_processes(request=batch_request):
process_name = process_links.process
print(f" Process: {process_name}")
runs_request = datacatalog_lineage_v1.ListRunsRequest(parent=process_name)
for run in client.list_runs(request=runs_request):
print(f" Run: {run.name}")
events_request = datacatalog_lineage_v1.ListLineageEventsRequest(parent=run.name)
for event in client.list_lineage_events(request=events_request):
for event_link in event.links:
source_fqn = event_link.source.fully_qualified_name
# If exploring upstream, queue the source
if source_fqn and source_fqn not in visited_nodes:
visited_nodes.add(source_fqn)
queue.append((source_fqn, current_depth + 1))
except GoogleAPICallError as e:
print(f" Failed to retrieve processes/runs: {e.message}")
Visualisierung der Herkunft optimieren
Sie können die Visualisierung der Herkunft mit den Optionen für Hervorhebung und Filterung im Lineage Explorer optimieren:
Verwenden Sie den Bereich Filter , um nach bestimmten Projekten, Datasets oder Entitätsnamen zu suchen.
Nachdem Sie Filter angewendet haben, werden Herkunftsknoten, die Ihren Filterkriterien entsprechen, als übereinstimmende Knoten betrachtet. Sie können die Darstellung von übereinstimmenden und nicht übereinstimmenden Knoten optimieren.
Klicken Sie im Herkunftsdiagramm auf das Dreipunkt-Menü neben der Schaltfläche Filter löschen, um die Anzeigeoptionen aufzurufen.
Wählen Sie eine oder beide der folgenden Optionen aus:
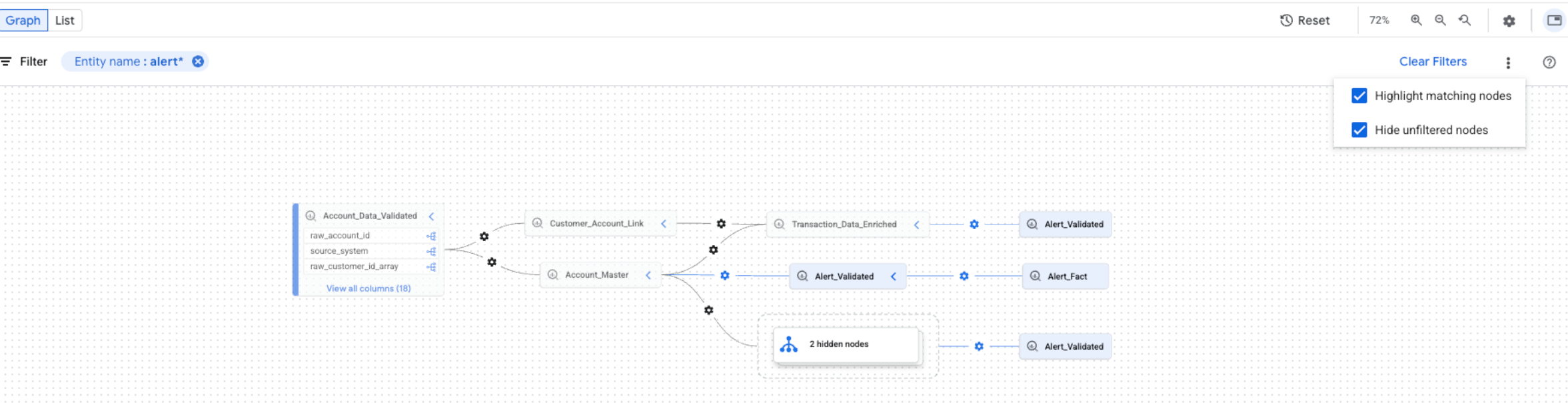
Sie können beide Optionen gleichzeitig auswählen. Wenn beide Optionen ausgewählt sind, werden ungefilterte Knoten ausgeblendet und übereinstimmende Knoten in der gefilterten Diagrammansicht hervorgehoben.
Nächste Schritte
- Datenherkunft für Kopier- und Abfragejobs einer BigQuery-Tabelle nachverfolgen.
- Informationen zum Datenherkunftsmodell
- Erfahren Sie mehr über Überlegungen und Einschränkungen zur Datenherkunft.
- Erfahren Sie mehr über das Audit-Logging für die Datenherkunft.
- Fehlerbehebung bei der Datenherkunft .
- Informationen zur Integration mit OpenLineage.
- Datenherkunft mit Managed Service for Apache Spark verwenden