
Knowledge Catalog es un catálogo de datos potenciado por Gemini que proporciona contexto y administración universales para todo tu conjunto de datos. Al extraer automáticamente la semántica de los datos estructurados y no estructurados, crea un gráfico de contexto dinámico que fundamenta los agentes de IA en la verdad empresarial y reduce las alucinaciones. Los equipos de datos y los desarrolladores de IA utilizan Knowledge Catalog para descubrir datos, aplicar políticas y recuperar contexto enriquecido para las aplicaciones autónomas y de análisis. Para obtener una explicación detallada de Knowledge Catalog, mira el video incorporado.
Dataplex Universal Catalog ahora es Knowledge Catalog
Para reflejar mejor la visión de unificar la administración de datos con las capacidades de la IA generativa, Dataplex Universal Catalog ahora se llama Knowledge Catalog. Esta evolución del nombre del producto representa un cambio de un registro de metadatos convencional y pasivo a un gráfico de contexto activo potenciado por IA.
Por qué Dataplex se convirtió en Knowledge Catalog
A medida que las organizaciones aceleran la adopción de la IA generativa, los agentes de IA necesitan un contexto comercial profundo para proporcionar respuestas precisas y fundamentadas. Knowledge Catalog cierra la brecha entre la administración de datos empresariales y los flujos de trabajo de los agentes de IA.
¿Cuál es la diferencia entre Dataplex y Knowledge Catalog?
Las actualizaciones de Knowledge Catalog reflejan nuevas capacidades centradas en la IA. A diferencia de los catálogos pasivos convencionales, Knowledge Catalog organiza automáticamente los metadatos, la lógica empresarial y las relaciones de datos en un gráfico de contexto unificado. Este gráfico proporciona la verdad empresarial confiable que los agentes de IA necesitan para ejecutar tareas complejas con precisión. Aprovecha funciones como la selección automática de contexto, las búsquedas de ejemplo verificadas y las integraciones locales y remotas del Protocolo de contexto del modelo (MCP).
Qué se mantendrá igual
Tus implementaciones, APIs y configuraciones existentes de Dataplex seguirán funcionando. Las funciones principales, como el descubrimiento de datos, el linaje, la calidad de los datos y los glosarios empresariales, no se modificaron y se siguen admitiendo. Tus metadatos, aspectos y configuraciones existentes se transfieren a la nueva experiencia de Knowledge Catalog sin necesidad de migraciones manuales, movimientos de datos ni tiempo de inactividad.
API y bibliotecas cliente
El cambio de marca a Knowledge Catalog no modifica los extremos de API, los comandos gcloud dataplex ni las bibliotecas cliente existentes. Puedes seguir usando las APIs y las bibliotecas cliente de Knowledge Catalog para interactuar con él:
API de REST. Consulta la documentación de la API de REST de Knowledge Catalog.
API de RPC. Consulta la documentación de la API de RPC de Knowledge Catalog.
Bibliotecas cliente. Comienza a usar Knowledge Catalog en el idioma que prefieras con las bibliotecas cliente de Knowledge Catalog.
Comandos de gcloud. Administra los recursos de Knowledge Catalog con el grupo de comandos
gcloud dataplex. Consulta la referencia de comandos de gcloud Dataplex.
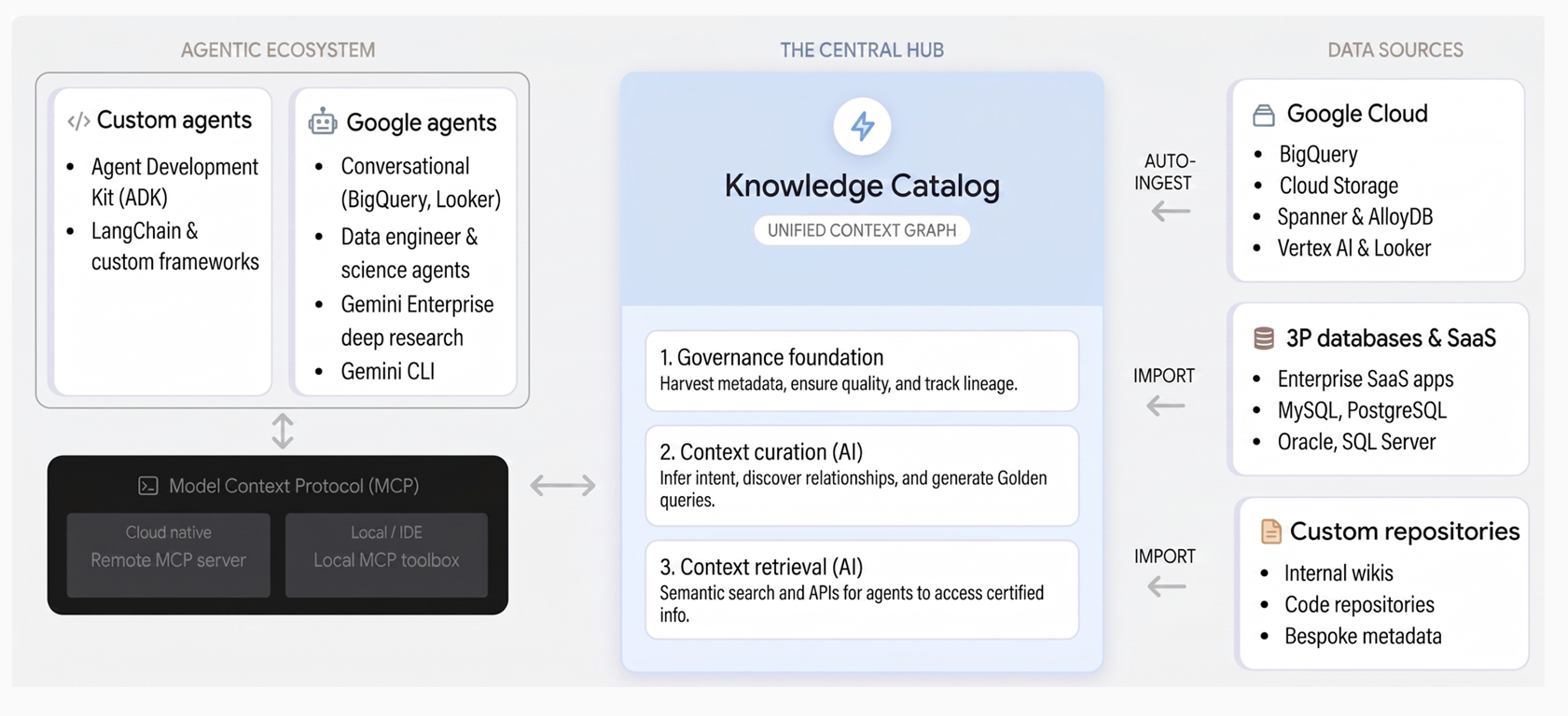
Cómo funciona Knowledge Catalog
Knowledge Catalog unifica la administración y el contexto a través de tres pilares fundamentales:
Base de la administración. Knowledge Catalog recopila automáticamente metadatos técnicos de servicios como BigQuery, AlloyDB para PostgreSQL y Spanner, junto con sistemas de terceros. Google Cloud Establece una base de datos confiable a través de un glosario empresarial centralizado, verificaciones de calidad de los datos, detección de anomalías y administración basada en políticas.
Curación de contexto: Con Gemini, el servicio infiere la intención comercial analizando esquemas, registros de búsquedas y modelos semánticos en tus datos. Genera descripciones en lenguaje natural, descubre relaciones y propone patrones de SQL verificados en forma de consultas de ejemplo que capturan la lógica empresarial compleja.
Recuperación de contexto: Las aplicaciones y los agentes de IA pueden descubrir instantáneamente recursos y recuperar contexto enriquecido a través de la búsqueda semántica y las herramientas que admiten el Protocolo de contexto del modelo (MCP). Esto permite que los agentes accedan a la verdad organizacional para tomar decisiones confiables.
En el siguiente diagrama, se ilustra la arquitectura de Knowledge Catalog y cómo unifica la administración de datos con los flujos de trabajo de IA generativa:
Casos de uso habituales
Knowledge Catalog ayuda a los ingenieros y científicos de datos, y a los desarrolladores de IA a resolver desafíos relacionados con la administración de datos y el desarrollo de IA:
Enriquece los datos para la IA. Usa estadísticas de datos para datos no estructurados y extrae automáticamente metadatos y entidades de archivos no estructurados, como PDFs en Cloud Storage. Esto hace que los datos oscuros y el conocimiento organizacional sean accesibles para los modelos de IA.
Reducir las alucinaciones de la IA Proporciona a los agentes de IA ejemplos de consultas verificadas previamente y barreras de protección semánticas, lo que les permite ejecutar recuperaciones de datos complejas con una precisión más determinística.
Acelera el descubrimiento de datos. Usa la búsqueda semántica y un gráfico de contexto centralizado para ubicar recursos de datos pertinentes en diversas fuentes para los flujos de trabajo de estadísticas y ciencia de datos.
Automatiza la creación de productos de datos. Infiere relaciones en todo tu patrimonio de datos para empaquetar recursos en productos de datos autónomos con acuerdos de nivel de servicio (ANS) y restricciones de administración integrados.
Flujos de trabajo de muestra en Knowledge Catalog
Para ver cómo puedes compilar tu gráfico de contexto y administrar tu patrimonio de datos, considera cómo una empresa de venta minorista en línea podría usar las siguientes funciones de Knowledge Catalog:
Descubre y cataloga datos. El comercio minorista transfiere automáticamente los datos de las transacciones y recopila metadatos de los servicios de Google Cloud como BigQuery, Pub/Sub y Cloud Storage. El servicio también importa metadatos de bases de datos de inventario personalizadas para crear una vista unificada de todo el patrimonio de datos minoristas. Para obtener más información, consulta Descubre datos.
Busca recursos de datos. Un científico de datos encuentra los recursos de datos de clientes exactos que necesita con el motor de búsqueda de Knowledge Catalog, que incluye filtros facetados, búsqueda semántica en lenguaje natural y operadores lógicos. Para obtener más información, consulta Cómo buscar activos de datos.
Enriquece los datos con contexto empresarial. El equipo de administración de datos define la terminología de venta minorista (como "valor del ciclo de vida del cliente" o "SKU") con glosarios empresariales y usa información de datos impulsada por IA para generar automáticamente descripciones de las nuevas tablas de productos. También aplican manualmente metadatos y etiquetas (aspectos) personalizados estructurados de manera uniforme en todos sus recursos. Para obtener más información, consulta Administra aspectos y enriquece metadatos y Administra un glosario empresarial.
Comprende las relaciones de datos con el linaje. El equipo de ingeniería realiza un seguimiento automático del linaje de datos para ver cómo se mueven, transforman y consumen los datos de pedidos en sus sistemas. Usan grafos de linaje para solucionar problemas en las canalizaciones de informes, realizar análisis de causa raíz en los errores de confirmación de compra y garantizar el cumplimiento. Para obtener más información, consulta la descripción general del linaje de datos.
Crear perfiles de datos y medir la calidad El comercio minorista usa la generación de perfiles de datos automatizada para identificar patrones y anomalías en sus tablas de precios de BigQuery. Definen y ejecutan verificaciones de calidad de los datos para garantizar que las direcciones de envío de los clientes sean precisas, completas y confiables para las cargas de trabajo de IA y cumplimiento posteriores. Para obtener más información, consulta Descripción general de la generación de perfiles de datos y Descripción general de la calidad de los datos automáticos.
Seleccionar y compartir productos de datos El equipo de la plataforma de datos empaqueta los recursos de ventas regionales y sus metadatos, calificaciones de calidad y linaje relacionados en productos de datos seleccionados de "Customer 360" que descubren y consumen los equipos de marketing y de inventario. Para obtener más información, consulta la descripción general de los productos de datos.
Knowledge Catalog en el ecosistema de Google Cloud
Cuando creas una base de datos, es importante comprender cómo Knowledge Catalog se integra con los servicios deGoogle Cloud relacionados:
| Servicio | Rol principal | Cuándo usar |
|---|---|---|
| Knowledge Catalog | Administración de datos y contexto basado en agentes | Se usa para catalogar metadatos, administrar la calidad de los datos y proporcionar fundamentación semántica para los agentes de IA. |
| BigQuery | Almacenamiento de datos empresariales | Se usa para almacenar, consultar y analizar conjuntos de datos masivos. Knowledge Catalog enriquece los datos de BigQuery con contexto empresarial. |
| Vertex AI | Plataforma de IA y aprendizaje automático | Se usa para compilar e implementar modelos de AA y agentes de IA. Los agentes usan las APIs de Knowledge Catalog para recuperar contexto empresarial preciso. |
| Cloud Storage | Almacenamiento de datos no estructurados | Se usa para almacenar archivos RAW. Knowledge Catalog analiza los buckets de Cloud Storage para extraer metadatos y entidades aptos para la búsqueda. |
Conceptos básicos
Para usar Knowledge Catalog de manera eficaz, debes comprender los siguientes conceptos clave:
Gráfico de contexto: Un mapa dinámico y unificado de cómo se relacionan los datos con tu empresa. Conecta esquemas técnicos con entidades comerciales y conocimiento no estructurado.
Ejemplos de búsquedas. Patrones de SQL verificados y generados previamente que capturan la lógica empresarial compleja. Estas consultas permiten que tanto los humanos como los agentes de IA consulten los datos con precisión sin necesidad de reinventar uniones de tablas complejas.
Protocolo de contexto del modelo (MCP). Es un estándar abierto que permite que los agentes de IA descubran y usen de forma adaptativa las herramientas disponibles. Knowledge Catalog usa herramientas de MCP para proporcionar información organizacional certificada directamente a los agentes, y ofrece servidores de MCP remotos y locales para satisfacer los requisitos de accesibilidad y seguridad.
-- Example: An example query retrieved by an AI agent to ensure accurate revenue calculation
SELECT customer_id, SUM(transaction_amount) AS total_revenue
FROM `sales.processed_transactions`
WHERE transaction_status = 'COMPLETED'
GROUP BY customer_id;
Transferencias
Knowledge Catalog ingiere automáticamente metadatos de las siguientes fuentes deGoogle Cloud . En el caso de algunos servicios, como AlloyDB para PostgreSQL y Cloud SQL, primero debes habilitar la integración de Knowledge Catalog para que se puedan ingerir los metadatos:
Analytics y lakehouse
- Conjuntos de datos, tablas, vistas, modelos, rutinas, conexiones y conjuntos de datos vinculados de BigQuery
- Intercambios y fichas de BigQuery sharing (anteriormente Analytics Hub)
- Repositorios de Dataform y recursos de código
- Servicios, base de datos y tablas de Dataproc Metastore
Tablas del catálogo de REST de Iceberg (incluidos el catálogo de tiempo de ejecución de Lakehouse, el IRC de Unity de Databricks, el IRC del Data Catalog de AWS Glue y el IRC de Horizon de Snowflake) Google Cloud
IA y aprendizaje automático
- Modelos, conjuntos de datos, grupos de atributos, vistas de atributos y instancias de almacén en línea de Vertex AI
Inteligencia empresarial
- Instancias de Looker (Google Cloud Core), paneles, elementos de paneles, Looks, proyectos de LookML, modelos, Explorar y vistas (versión preliminar)
Bases de datos
- Instancias, clústeres y tablas de Bigtable (incluidos los detalles de la familia de columnas)
- Instancias, bases de datos, tablas y vistas de Spanner
Transmisión y mensajería
- Temas de Pub/Sub
Datos no estructurados
Bases de datos operativas
- Clústeres, instancias, bases de datos, esquemas, tablas y vistas de AlloyDB para PostgreSQL (vista previa). Knowledge Catalog recupera metadatos solo de instancias principales de AlloyDB para PostgreSQL y no de réplicas de lectura. Para obtener más información, consulta Administra tus recursos de AlloyDB para PostgreSQL con Knowledge Catalog.
- Instancias, bases de datos, esquemas, tablas y vistas de Cloud SQL Knowledge Catalog recupera metadatos solo de instancias principales de Cloud SQL y no de réplicas de lectura. Para obtener más información, consulta Administra tus recursos de Cloud SQL con Knowledge Catalog.
Para importar metadatos de una fuente externa a Knowledge Catalog, puedes usar conectores de Knowledge Catalog o una canalización de conectividad administrada. Para obtener más información, consulta Acerca de los conectores de Knowledge Catalog y Descripción general de la conectividad administrada.
Limitaciones
Cuando planifiques tu implementación, ten en cuenta las siguientes limitaciones:
Integraciones admitidas. Si bien Knowledge Catalog admite los principales sistemas de terceros, es posible que algunas extracciones semánticas automatizadas se limiten a los servicios Google Cloud integrados.
Límites de cuota. Las cuotas estándar de la Google Cloud API se aplican a las operaciones de recuperación de contexto y extracción de metadatos.
¿Qué sigue?
Obtén información sobre la administración de metadatos en Knowledge Catalog.
Obtén más información para buscar recursos de datos.
Obtén más información sobre el linaje de datos.
Obtén más información sobre la generación de perfiles de datos.
Obtén más información sobre la calidad de los datos automática.