
O Knowledge Catalog é um catálogo de dados com tecnologia do Gemini que oferece contexto e governança de negócios universais para todo o patrimônio de dados. Ao extrair automaticamente a semântica de dados estruturados e não estruturados, ele cria um gráfico de contexto dinâmico que fundamenta os agentes de IA na verdade empresarial e reduz as alucinações. As equipes de dados e os desenvolvedores de IA usam o Knowledge Catalog para descobrir dados, aplicar políticas e recuperar um contexto avançado para análises e aplicativos autônomos. Para um tutorial detalhado do Knowledge Catalog, consulte o vídeo incorporado.
O Dataplex Universal Catalog agora é o Knowledge Catalog
Para refletir melhor a visão de unificação da governança de dados com os recursos de IA generativa, o Dataplex Universal Catalog agora é o Knowledge Catalog. Essa evolução do nome do produto representa uma mudança de um registro de metadados convencional e passivo para um gráfico de contexto ativo com tecnologia de IA.
Por que o Dataplex se tornou o Knowledge Catalog
À medida que as organizações aceleram a adoção da IA generativa, os agentes de IA precisam de um contexto de negócios profundo para fornecer respostas precisas e fundamentadas. O Knowledge Catalog preenche a lacuna entre a governança de dados corporativos e os fluxos de trabalho de agentes de IA.
Qual é a diferença entre o Dataplex e o Knowledge Catalog
As atualizações do Knowledge Catalog refletem novos recursos centrados em IA. Ao contrário dos catálogos passivos convencionais, o Knowledge Catalog organiza automaticamente metadados, lógica de negócios e relações de dados em um gráfico de contexto unificado. Esse gráfico fornece a verdade empresarial confiável de que os agentes de IA precisam para executar tarefas complexas com precisão. Ele aproveita recursos como a organização automática de contexto, consultas de exemplo verificadas e integrações do Protocolo de Contexto de Modelo (MCP) local e remoto.
O que não está mudando
As implantações, APIs e configurações atuais do Dataplex permanecem operacionais. Os principais recursos, como descoberta de dados, linhagem, qualidade de dados e glossários empresariais, não foram alterados e têm suporte. Os metadados, aspectos e configurações atuais fazem a transição para a nova experiência do Knowledge Catalog sem migração manual, movimentação de dados ou inatividade.
APIs e bibliotecas de cliente
A mudança de marca para o Knowledge Catalog não altera os endpoints de API, os comandos gcloud dataplex ou as bibliotecas de cliente atuais. Você pode continuar usando as APIs e bibliotecas de cliente do Knowledge Catalog para interagir com ele:
API REST. Consulte a documentação da API REST do Knowledge Catalog.
API RPC. Consulte a documentação da API RPC do Knowledge Catalog .
Bibliotecas de cliente. Comece a usar o Knowledge Catalog no idioma de sua preferência usando as bibliotecas de cliente do Knowledge Catalog.
Comandos gcloud. Gerencie os recursos do Knowledge Catalog usando o grupo de comandos
gcloud dataplex. Consulte a referência de comandos do gcloud Dataplex.
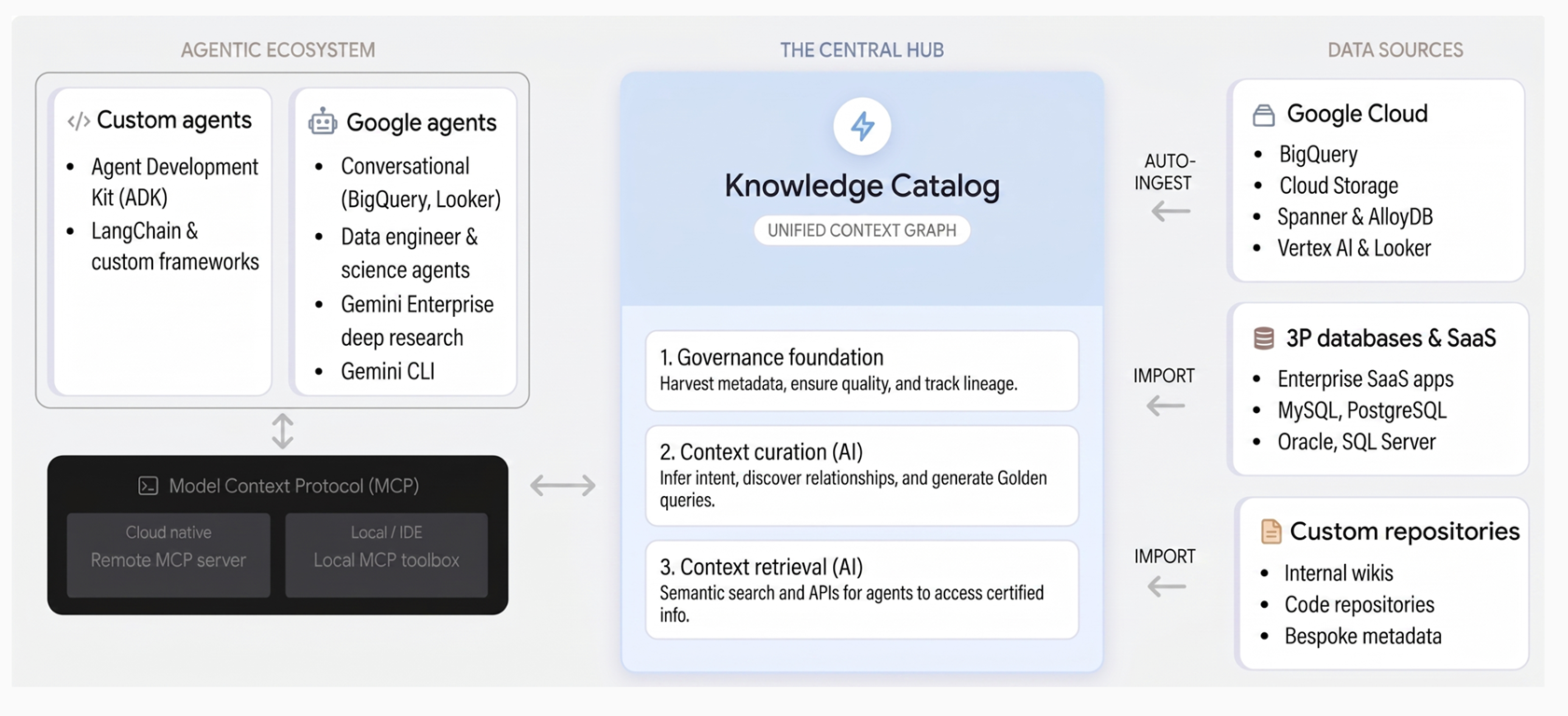
Como o Knowledge Catalog funciona
O Knowledge Catalog unifica a governança e o contexto por meio de três pilares principais:
Base de governança. O Knowledge Catalog coleta automaticamente metadados técnicos de Google Cloud serviços como BigQuery, AlloyDB para PostgreSQL e Spanner, além de sistemas de terceiros. Ele estabelece uma base de dados confiável por meio de um glossário empresarial centralizado, verificações de qualidade de dados, detecção de anomalias e governança baseada em políticas.
Organização de contexto. Usando o Gemini, o serviço infere a intenção comercial analisando esquemas, registros de consultas e modelos semânticos nos seus dados. Ele gera descrições de linguagem natural, descobre relações e propõe padrões SQL verificados na forma de consultas de exemplo que capturam a lógica de negócios complexa.
Recuperação de contexto. Os agentes e aplicativos de IA podem descobrir recursos e recuperar o contexto enriquecido instantaneamente por meio da pesquisa semântica e de ferramentas que oferecem suporte ao Protocolo de Contexto de Modelo (MCP). Isso permite que os agentes acessem a verdade organizacional para uma tomada de decisão confiável.
O diagrama a seguir ilustra a arquitetura do Knowledge Catalog e como ele unifica a governança de dados com fluxos de trabalho de IA generativa:
Casos de uso comuns
O Knowledge Catalog ajuda engenheiros de dados, cientistas de dados e desenvolvedores de IA a resolver desafios no gerenciamento de dados e no desenvolvimento de IA:
Enriqueça os dados para IA. Use insights de dados para dados não estruturados para extrair automaticamente metadados e entidades de arquivos não estruturados, como PDFs no Cloud Storage. Isso torna os dados ocultos e o conhecimento organizacional acessíveis aos modelos de IA.
Reduza as alucinações de IA. Forneça aos agentes de IA consultas de exemplo pré-verificadas e barreiras semânticas, permitindo que eles executem recuperações de dados complexas com mais precisão determinística.
Acelere a descoberta de dados. Use a pesquisa semântica e um gráfico de contexto centralizado para localizar recursos de dados relevantes em fontes diferentes para fluxos de trabalho de análise e ciência de dados.
Automatize a criação de produtos de dados. Infera relações em todo o patrimônio de dados para empacotar recursos em produtos de dados independentes com contratos de nível de serviço (SLAs) e restrições de governança integrados.
Exemplos de fluxos de trabalho no Knowledge Catalog
Para saber como criar seu gráfico de contexto e gerenciar seu patrimônio de dados, considere como uma empresa de varejo on-line pode usar os seguintes recursos do Knowledge Catalog:
Descubra e catalogue dados. O varejista ingere automaticamente dados de transações e coleta metadados de Google Cloud serviços como BigQuery, Pub/Sub e Cloud Storage. O serviço também importa metadados de bancos de dados de inventário personalizados para criar uma visualização unificada de todo o patrimônio de dados de varejo. Para mais informações, consulte Descobrir dados.
Pesquise recursos de dados. Um cientista de dados encontra os recursos de dados exatos do cliente de que precisa usando o mecanismo de pesquisa do Knowledge Catalog com filtragem facetada, pesquisa semântica de linguagem natural e operadores lógicos. Para mais informações, consulte Pesquisar recursos de dados.
Enriqueça os dados com contexto de negócios. A equipe de governança de dados define a terminologia de varejo (como "valor da vida útil" ou "SKU") usando glossários empresariais e usa insights de dados com tecnologia de IA para gerar automaticamente descrições de novas tabelas de produtos. Eles também aplicam manualmente metadados e tags personalizados estruturados (aspectos) de maneira uniforme em todos os recursos. Para mais informações, consulte Gerenciar aspectos e enriquecer metadados e Gerenciar um glossário empresarial.
Entenda as relações de dados com a linhagem. A equipe de engenharia rastreia automaticamente a linhagem de dados para saber como os dados de pedidos são movidos, transformados e consumidos nos sistemas. Eles usam gráficos de linhagem para solucionar problemas de pipelines de relatórios, realizar análises de causa raiz em erros de finalização de compra e garantir a conformidade. Para mais informações, consulte Linhagem de dados visão geral.
Crie um perfil de dados e meça a qualidade. O varejista usa a criação de perfil de dados automatizada para identificar padrões e anomalias nas tabelas de preços do BigQuery. Eles definem e executam verificações de qualidade de dados para garantir que os endereços de entrega dos clientes sejam precisos, completos e confiáveis para cargas de trabalho de IA e atendimento downstream. Para mais informações, consulte Visão geral da criação de perfil de dados e Visão geral da qualidade de dados automática.
Organize e compartilhe produtos de dados. A equipe da plataforma de dados empacota recursos de vendas regionais e os metadados, pontuações de qualidade e linhagem relacionados em produtos de dados "Cliente 360" organizados que são descobertos e consumidos pelas equipes de marketing e inventário. Para mais informações, consulte Produtos de dados visão geral.
Knowledge Catalog no Google Cloud ecossistema
Ao criar uma base de dados, é importante entender como o Knowledge Catalog se integra aos serviços relacionados Google Cloud :
| Serviço | Função principal | Quando usar |
|---|---|---|
| Knowledge Catalog | Contexto agêntico e governança de dados | Use para catalogar metadados, gerenciar a qualidade de dados e fornecer uma base semântica para agentes de IA. |
| BigQuery | Data warehouse corporativo | Use para armazenar, consultar e analisar conjuntos de dados enormes. O Knowledge Catalog enriquece os dados do BigQuery com contexto de negócios. |
| Vertex AI | Plataforma de IA e machine learning | Use para criar e implantar modelos de ML e agentes de IA. Os agentes usam as APIs do Knowledge Catalog para recuperar o contexto empresarial preciso. |
| Cloud Storage | Armazenamento de dados não estruturados | Use para armazenar arquivos brutos. O Knowledge Catalog verifica buckets do Cloud Storage para extrair entidades e metadados pesquisáveis. |
Principais conceitos
Para usar o Knowledge Catalog de maneira eficaz, entenda os seguintes conceitos principais:
Gráfico de contexto. Um mapa dinâmico e unificado de como os dados se relacionam com sua empresa. Ele conecta esquemas técnicos a entidades comerciais e conhecimento não estruturado.
Consultas de exemplo. Padrões SQL pré-gerados e verificados que capturam a lógica de negócios complexa. Essas consultas permitem que humanos e agentes de IA consultem dados com precisão sem reinventar junções de tabelas complexas.
Protocolo de Contexto de Modelo (MCP). Um padrão aberto que permite que os agentes de IA descubram e usem de forma adaptável as ferramentas disponíveis. O Knowledge Catalog usa ferramentas do MCP para fornecer a verdade organizacional certificada diretamente aos agentes, oferecendo servidores MCP remotos e locais para atender aos requisitos de acessibilidade e segurança.
-- Example: An example query retrieved by an AI agent to ensure accurate revenue calculation
SELECT customer_id, SUM(transaction_amount) AS total_revenue
FROM `sales.processed_transactions`
WHERE transaction_status = 'COMPLETED'
GROUP BY customer_id;
Processamentos
O Knowledge Catalog ingere automaticamente metadados das seguintes Google Cloud fontes. Para alguns serviços, como o AlloyDB para PostgreSQL e o Cloud SQL, primeiro é necessário ativar a integração do Knowledge Catalog antes que os metadados possam ser ingeridos:
Análise e lakehouse
- Conjuntos de dados, tabelas, visualizações, modelos, rotinas, conexões e conjuntos de dados vinculados do BigQuery
- Trocas e listagens do BigQuery Sharing (antigo Analytics Hub)
- Repositórios e recursos de código do Dataform
- Serviços, bancos de dados e tabelas do Dataproc Metastore
Tabelas do catálogo REST do Iceberg (incluindo Google Cloud o IRC do catálogo de execução do Lakehouse , o IRC do Databricks Unity, o IRC do AWS Glue Data Catalog e o IRC do Snowflake Horizon)
IA e machine learning
- Modelos, conjuntos de dados, grupos de recursos, visualizações de recursos e instâncias de loja on-line da Vertex AI
Business intelligence
- Instâncias, painéis, elementos de painel, Looks, projetos do LookML, modelos, Explores e visualizações do Looker (Google Cloud Core) (pré-lançamento)
Bancos de dados
- Instâncias, clusters e tabelas do Bigtable (incluindo detalhes do grupo de colunas)
- Instâncias, bancos de dados, tabelas e visualizações do Spanner
Streaming e mensagens
- Tópicos do Pub/Sub
Dados não estruturados
Bancos de dados operacionais
- Clusters, instâncias, bancos de dados, esquemas, tabelas e visualizações do AlloyDB para PostgreSQL (pré-lançamento). O Knowledge Catalog recupera metadados somente das instâncias principais do AlloyDB para PostgreSQL e não de réplicas de leitura. Para mais informações, consulte Gerenciar recursos do AlloyDB para PostgreSQL usando o Knowledge Catalog.
- Instâncias, bancos de dados, esquemas, tabelas e visualizações do Cloud SQL. O Knowledge Catalog recupera metadados somente das instâncias principais do Cloud SQL e não de réplicas de leitura. Para mais informações, consulte Gerenciar recursos do Cloud SQL usando o Knowledge Catalog.
Para importar metadados de uma fonte de terceiros para o Knowledge Catalog, use os conectores do Knowledge Catalog ou um pipeline de conectividade gerenciada. Para mais informações, consulte Sobre os conectores do Knowledge Catalog e Visão geral da conectividade gerenciada.
Limitações
Ao planejar a implantação, considere as seguintes limitações:
Integrações aceitas. Embora o Knowledge Catalog ofereça suporte a grandes sistemas de terceiros, algumas extrações semânticas automatizadas podem ser limitadas a serviços integrados Google Cloud .
Limites de cota. As cotas de API padrão se aplicam a operações de recuperação de contexto e extração de metadados. Google Cloud
A seguir
Saiba mais sobre o gerenciamento de metadados no Knowledge Catalog.
Saiba como pesquisar recursos de dados.
Saiba mais sobre a linhagem de dados.
Saiba mais sobre a qualidade de dados automática.