
Cloud Profiler הוא כלי ליצירת פרופילים סטטיסטיים עם תקורה נמוכה, שאוסף באופן רציף מידע על השימוש במעבד (CPU) ועל הקצאת הזיכרון מהאפליקציות שלכם בסביבת הייצור. פרטים נוספים זמינים במאמר מושגים של פרופילים. כדי לפתור בעיות בביצועים של צינור עיבוד נתונים או לעקוב אחרי הביצועים שלו, אפשר להשתמש בשילוב של Dataflow עם Cloud Profiler כדי לזהות את החלקים בקוד של צינור עיבוד הנתונים שצורכים הכי הרבה משאבים.
במאמר פתרון בעיות וניפוי באגים בצינורות עיבוד נתונים תוכלו לקרוא טיפים לפתרון בעיות ואסטרטגיות לניפוי באגים בתהליך של יצירה או הפעלה של צינור עיבוד נתונים ב-Dataflow.
לפני שמתחילים
להבין את המושגים שקשורים ליצירת פרופילים ולהכיר את הממשק של הכלי ליצירת פרופילים. במאמר בחירת הפרופילים לניתוח מוסבר איך מתחילים להשתמש בממשק של כלי הפרופילים.
צריך להפעיל את Cloud Profiler API בפרויקט לפני שמתחילים את העבודה.
הוא מופעל אוטומטית בפעם הראשונה שנכנסים לדף Profiler.
לחלופין, אפשר להפעיל את Cloud Profiler API באמצעות כלי שורת הפקודה Google Cloud CLI gcloud או באמצעות המסוף Google Cloud .
כדי להשתמש ב-Cloud Profiler, בפרויקט שלכם צריכה להיות מכסה מספקת.
בנוסף, לחשבון השירות של העובד של משימת Dataflow צריכות להיות הרשאות מתאימות ל-Profiler. לדוגמה, כדי ליצור פרופילים, לחשבון השירות של העובד צריכה להיות ההרשאה cloudprofiler.profiles.create, שכלולה בתפקיד Cloud Profiler Agent (roles/cloudprofiler.agent) ב-IAM.
מידע נוסף זמין במאמר בקרת גישה באמצעות IAM.
הפעלה של Cloud Profiler לצינורות עיבוד נתונים של Dataflow
Cloud Profiler זמין לצינורות Dataflow שנכתבו ב-Apache Beam SDK ל-Java ול-Python, בגרסה 2.33.0 ואילך. צינורות עיבוד נתונים של Python צריכים להשתמש ב-Dataflow Runner v2. אפשר להפעיל את Cloud Profiler בזמן ההתחלה של צינור העיבוד. התקורה המופחתת של המעבד והזיכרון צפויה להיות פחות מ-1% בצינורות שלכם.
Java
כדי להפעיל את התאמה לפרופיל של יחידת העיבוד המרכזית (CPU), מפעילים את צינור הנתונים עם האפשרות הבאה.
--dataflowServiceOptions=enable_google_cloud_profiler
כדי להפעיל את פרופיל הערימה, מפעילים את צינור הנתונים עם האפשרויות הבאות. כדי ליצור פרופיל של Heap נדרשת Java מגרסה 11 ואילך.
--dataflowServiceOptions=enable_google_cloud_profiler
--dataflowServiceOptions=enable_google_cloud_heap_sampling
Python
כדי להשתמש ב-Cloud Profiler, צינור הנתונים של Python צריך לפעול עם Runner v2 של Dataflow.
כדי להפעיל את התאמה לפרופיל של יחידת העיבוד המרכזית (CPU), מפעילים את צינור הנתונים עם האפשרות הבאה. עדיין אין תמיכה בפרופיל Heap ב-Python.
--dataflow_service_options=enable_google_cloud_profiler
Go
כדי להפעיל את התאמת הפרופיל של יחידת העיבוד המרכזית (CPU) ושל הערימה, מפעילים את צינור הנתונים עם האפשרות הבאה.
--dataflow_service_options=enable_google_cloud_profiler
אם אתם פורסים את צינורות הנתונים מתבניות Dataflow ורוצים להפעיל את Cloud Profiler, צריך לציין את הדגלים enable_google_cloud_profiler ו-enable_google_cloud_heap_sampling כניסויים נוספים.
המסוף
אם אתם משתמשים ב תבנית ש-Google מספקת, אתם יכולים לציין את הדגלים בשדה Additional experiments בדף Create job from template ב-Dataflow.
gcloud
אם משתמשים ב-Google Cloud CLI כדי להריץ תבניות, צריך להשתמש באפשרות --additional-experiments כדי לציין את הדגלים, בהתאם לסוג התבנית: gcloud
dataflow jobs run או gcloud dataflow flex-template run.
API
אם משתמשים ב-REST API כדי להריץ תבניות, צריך לציין את הדגלים בשדה additionalExperiments של סביבת זמן הריצה, RuntimeEnvironment או FlexTemplateRuntimeEnvironment, בהתאם לסוג התבנית.
צפייה בנתוני הפרופיל
אם Cloud Profiler מופעל, קישור לדף Profiler מוצג בדף המשרה.
בדף Profiler, אפשר למצוא גם את נתוני הפרופיל של צינור הנתונים של Dataflow. Service הוא שם המשימה ו-Version הוא מזהה המשימה.

שימוש ב-Cloud Profiler
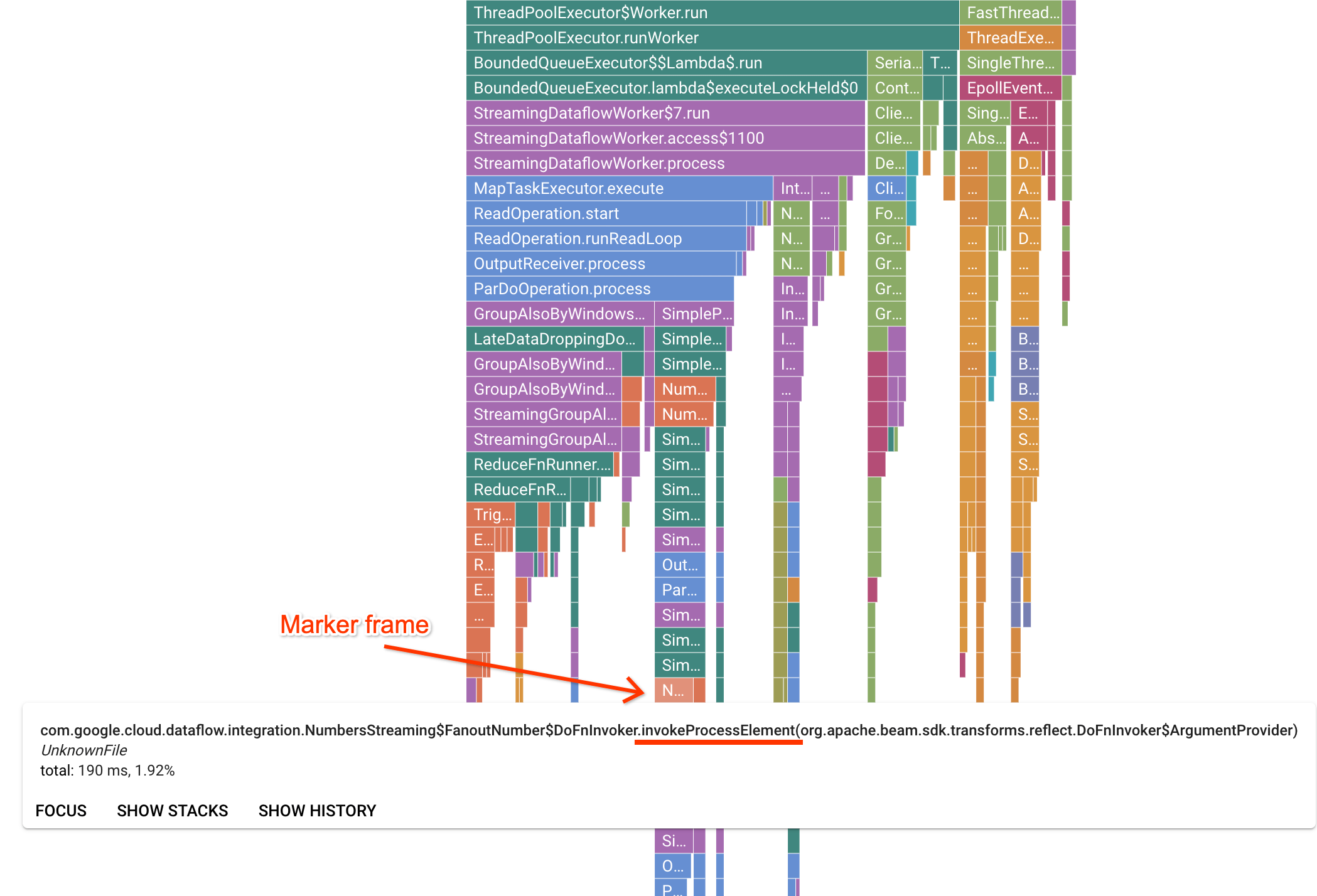
הדף Profiler מכיל תרשים להבה שמציג נתונים סטטיסטיים לכל פריים שפועל ב-worker. בכיוון האופקי, אפשר לראות כמה זמן לקח לכל פריים להתבצע מבחינת זמן המעבד. בכיוון האנכי, אפשר לראות את עקבות המחסנית ואת הקוד שפועל במקביל. בדוחות הקריסות יש בעיקר קוד תשתית של רכיב ההרצה. למטרות ניפוי באגים, בדרך כלל אנחנו מתעניינים בהרצת קוד משתמש, שבדרך כלל נמצא ליד הקצוות התחתונים של הגרף. אפשר לזהות קוד משתמש באמצעות חיפוש של מסגרות סימון, שמייצגות קוד של רץ שמוגבל לקריאה רק לקוד משתמש. במקרה של Beam ParDo runner, נוצרת שכבת מתאם דינמית כדי להפעיל את חתימת השיטה DoFn שסופקה על ידי המשתמש. אפשר לזהות את השכבה הזו כמסגרת עם הסיומת invokeProcessElement. בתמונה הבאה מוצגת הדגמה של איתור פריים של סמן.
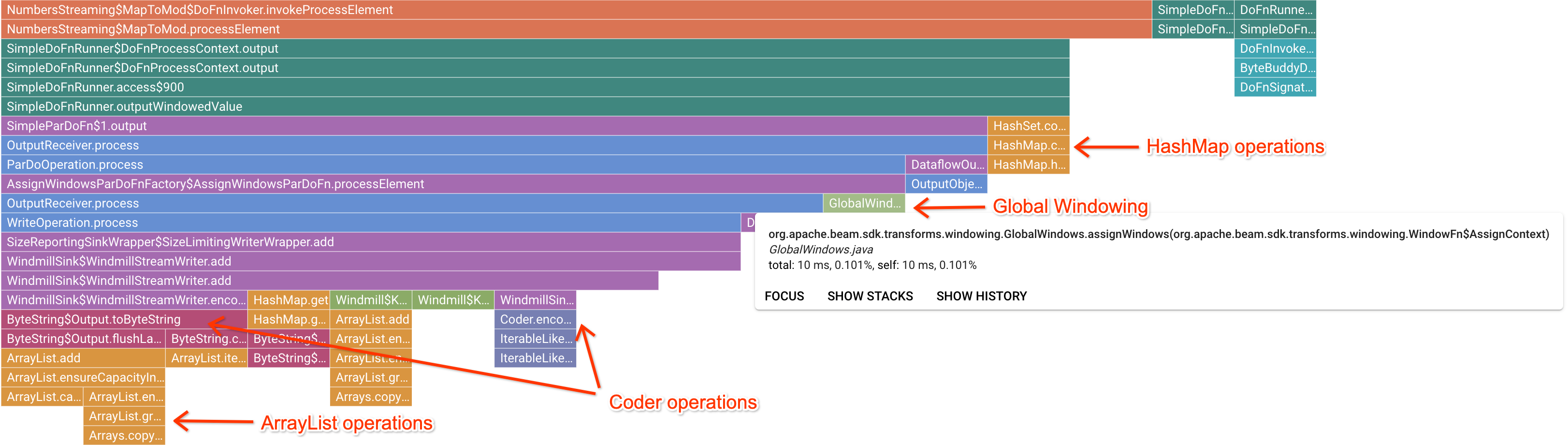
אחרי שלוחצים על מסגרת מעניינת של סמן, תרשים הלהבה מתמקד בדוח קריסות זה, ומספק תחושה טובה לגבי קוד משתמש שפועל לאורך זמן. הפעולות הכי איטיות יכולות להצביע על צווארי בקבוק שנוצרו, ולספק הזדמנויות לאופטימיזציה. בדוגמה הבאה אפשר לראות שנעשה שימוש ב-Global Windowing עם ByteArrayCoder. במקרה הזה, יכול להיות שכדאי לבצע אופטימיזציה של הקוד כי הוא תופס זמן משמעותי במעבד בהשוואה לפעולות של ArrayList ו-HashMap.
פתרון בעיות ב-Cloud Profiler
אם הפעלתם את Cloud Profiler והצינור לא יוצר נתוני פרופילים, יכול להיות שהסיבה לכך היא אחת מהסיבות הבאות.
בצינור שלך נעשה שימוש בגרסה ישנה של Apache Beam SDK. כדי להשתמש ב-Cloud Profiler, צריך להשתמש ב-Apache Beam SDK בגרסה 2.33.0 ואילך. אפשר לראות את גרסת Apache Beam SDK של צינור הנתונים בדף העבודה. אם העבודה נוצרה מתבניות Dataflow, התבניות צריכות להשתמש בגרסאות SDK נתמכות.
עומדת להיגמר המכסה של Cloud Profiler בפרויקט. אפשר לראות את השימוש במכסה בדף המכסה של הפרויקט. שגיאה כמו
Failed to collect and upload profile whose profile type is WALLיכולה להתרחש אם חורגים מהמכסה של Cloud Profiler. שירות Cloud Profiler דוחה את נתוני הפרופיל אם הגעתם למכסת השימוש. מידע נוסף על מכסות ב-Cloud Profiler זמין במאמר מכסות ומגבלות.העבודה לא פעלה מספיק זמן כדי ליצור נתונים עבור Cloud Profiler. יכול להיות שבמשימות שפועלות לפרקי זמן קצרים, למשל פחות מחמש דקות, לא יהיו מספיק נתונים ליצירת פרופיל כדי ש-Cloud Profiler יוכל ליצור תוצאות.
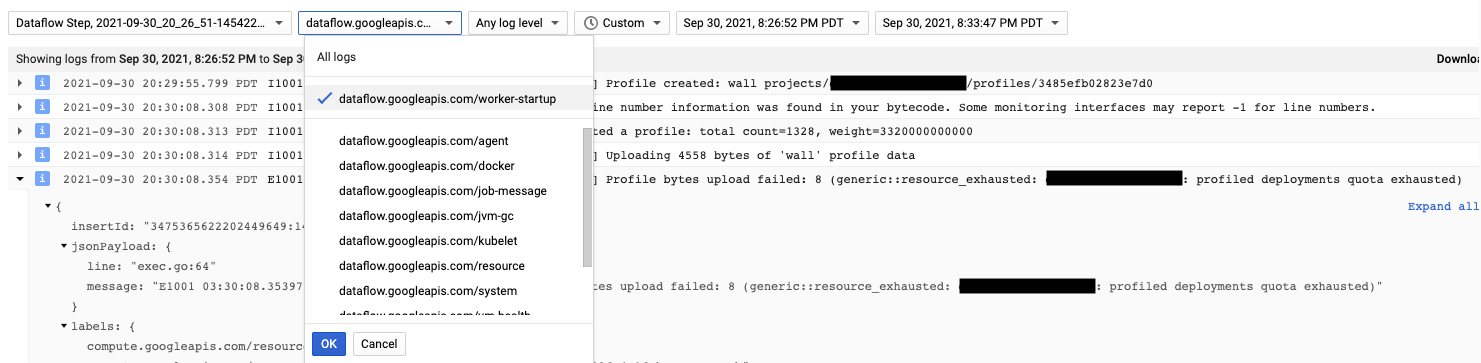
הסוכן של Cloud Profiler מותקן במהלך ההפעלה של העובד ב-Dataflow. הודעות היומן שנוצרות על ידי Cloud Profiler זמינות בסוג היומן dataflow.googleapis.com/worker-startup.
לפעמים נתוני הפרופיל קיימים, אבל Cloud Profiler לא מציג פלט. בכלי ליצירת פרופילים מוצגת הודעה דומה ל-There were
profiles collected for the specified time range, but none match the current
filters.
כדי לפתור את הבעיה, אפשר לנסות את השלבים הבאים.
מוודאים שטווח הזמן ושעת הסיום ב-Profiler כוללים את הזמן שחלף מאז התחלת העבודה.
מוודאים שהעבודה הנכונה נבחרה בכלי ליצירת פרופילים. Service הוא שם המשרה שלכם.
מוודאים שהערך של האפשרות
job_namepipeline זהה לשם המשימה בדף המשימה של Dataflow.אם ציינתם ארגומנט של שם שירות כשנטען סוכן Profiler, ודאו ששם השירות מוגדר בצורה נכונה.