
במאמר הזה מוסבר איך לעדכן עבודת סטרימינג שמתבצעת. יכול להיות שתרצו לעדכן את משימת Dataflow הקיימת מהסיבות הבאות:
- אתם רוצים לשפר את קוד צינור עיבוד הנתונים.
- אתם רוצים לתקן באגים בקוד של צינור העיבוד.
- אתם רוצים לעדכן את צינור הנתונים כדי לטפל בשינויים בפורמט הנתונים, או כדי להתחשב בגרסה או בשינויים אחרים במקור הנתונים.
- אתם רוצים לתקן פגיעות אבטחה שקשורה ל-מערכת הפעלה שמותאמת לקונטיינרים בכל ה-workers של Dataflow.
- רוצים לשנות את מספר העובדים בצינור Apache Beam להזרמת נתונים.
יש שתי דרכים לעדכן משרות:
- עדכון של עבודות בזמן שהן פועלות: בעבודות סטרימינג שמשתמשות ב-Streaming Engine, אפשר לעדכן את אפשרויות העבודה
min-num-workersו-max-num-workersבלי לעצור את העבודה או לשנות את מזהה העבודה. - החלפת משימה: כדי להריץ קוד מעודכן של צינור נתונים או כדי לעדכן אפשרויות של משימה שעדכונים של משימות פעילות לא תומכים בהן, מפעילים משימה חדשה שמחליפה את המשימה הקיימת. כדי לוודא שהחלפת העבודה תקפה, מאמתים את גרף העבודה לפני שמפעילים את העבודה החדשה.
כשמעדכנים את העבודה, שירות Dataflow מבצע בדיקת תאימות בין העבודה שפועלת כרגע לבין העבודה החלופית הפוטנציאלית. בדיקת התאימות מוודאת שאפשר להעביר מהעבודה הקודמת לעבודה החדשה דברים כמו מידע על מצב ביניים ונתונים שנשמרו במאגר זמני.
אפשר גם להשתמש בתשתית הרישום המובנית של Apache Beam SDK כדי לרשום מידע ביומן כשמעדכנים את העבודה. מידע נוסף זמין במאמר בנושא עבודה עם יומני צינורות.
כדי לזהות בעיות בקוד של צינור עיבוד הנתונים, משתמשים ברמת הרישום ביומן DEBUG.
- הוראות לעדכון של משימות סטרימינג שמשתמשות בתבניות קלאסיות מפורטות במאמר עדכון של משימת סטרימינג של תבנית בהתאמה אישית.
- כדי לעדכן משימות של סטרימינג שמשתמשות בתבניות Flex, אפשר לפעול לפי ההוראות ל-CLI של gcloud שמופיעות בדף הזה, או לעיין במאמר עדכון משימה של תבנית Flex.
עדכון אפשרויות של משרות במהלך הטיסה
במקרה של עבודת סטרימינג שמשתמשת ב-Streaming Engine, אפשר לעדכן את אפשרויות העבודה הבאות בלי להפסיק את העבודה או לשנות את מזהה העבודה:
-
min-num-workers: מספר המינימום של מכונות Compute Engine. -
max-num-workers: המספר המקסימלי של מכונות Compute Engine. -
worker-utilization-hint: ניצול המעבד (CPU) הרצוי, בטווח [0.1, 0.9]
לגבי עדכונים אחרים של משרות, צריך להחליף את המשרה הנוכחית במשרה המעודכנת. מידע נוסף מופיע במאמר בנושא הפעלת עבודת החלפה.
ביצוע עדכון במהלך הטיסה
כדי לעדכן אפשרות של משימה בזמן שהיא פועלת, מבצעים את השלבים הבאים.
gcloud
משתמשים בפקודה gcloud dataflow jobs update-options:
gcloud dataflow jobs update-options \ --region=REGION \ --min-num-workers=MINIMUM_WORKERS \ --max-num-workers=MAXIMUM_WORKERS \ --worker-utilization-hint=TARGET_UTILIZATION \ JOB_ID
מחליפים את מה שכתוב בשדות הבאים:
- REGION: המזהה של האזור של המשימה
- MINIMUM_WORKERS: מספר המינימום של מכונות Compute Engine
- MAXIMUM_WORKERS: המספר המקסימלי של מכונות Compute Engine
- TARGET_UTILIZATION: ערך בטווח [0.1, 0.9]
- JOB_ID: המזהה של העבודה שרוצים לעדכן
אפשר גם לעדכן את --min-num-workers, --max-num-workers ו-worker-utilization-hint בנפרד.
REST
משתמשים בשיטה projects.locations.jobs.update:
PUT https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs/JOB_ID?updateMask=MASK { "runtime_updatable_params": { "min_num_workers": MINIMUM_WORKERS, "max_num_workers": MAXIMUM_WORKERS, "worker_utilization_hint": TARGET_UTILIZATION } }
מחליפים את מה שכתוב בשדות הבאים:
- MASK: רשימה מופרדת בפסיקים של פרמטרים לעדכון, מתוך האפשרויות הבאות:
runtime_updatable_params.max_num_workersruntime_updatable_params.min_num_workersruntime_updatable_params.worker_utilization_hint
- PROJECT_ID: מזהה הפרויקט של משימת Dataflow Google Cloud
- REGION: המזהה של האזור של המשימה
- JOB_ID: המזהה של העבודה שרוצים לעדכן
- MINIMUM_WORKERS: מספר המינימום של מכונות Compute Engine
- MAXIMUM_WORKERS: המספר המקסימלי של מכונות Compute Engine
- TARGET_UTILIZATION: ערך בטווח [0.1, 0.9]
אפשר גם לעדכן את min_num_workers, max_num_workers ו-worker_utilization_hint בנפרד.
מציינים אילו פרמטרים לעדכן בפרמטר השאילתה updateMask, וכוללים את הערכים המעודכנים בשדה runtimeUpdatableParams של גוף הבקשה. בדוגמה הבאה מופיעים עדכונים של min_num_workers:
PUT https://dataflow.googleapis.com/v1b3/projects/my_project/locations/us-central1/jobs/job1?updateMask=runtime_updatable_params.min_num_workers { "runtime_updatable_params": { "min_num_workers": 5 } }
כדי שמשרה תעמוד בדרישות לעדכונים בזמן אמת, היא צריכה להיות במצב פעיל. שגיאה מתרחשת אם העבודה לא התחילה או שהיא כבר בוטלה. באופן דומה, אם מפעילים עבודה חלופית, צריך לחכות עד שהיא תתחיל לפעול לפני ששולחים עדכונים לגבי העבודה החדשה.
אחרי ששולחים בקשה לעדכון, מומלץ לחכות שהבקשה תושלם לפני ששולחים עדכון נוסף. כדי לראות מתי הבקשה מסתיימת, אפשר לעיין ביומני העבודות.
אימות של עבודת החלפה
כדי לוודא שעבודת ההחלפה תקפה, לפני שמפעילים את העבודה החדשה, צריך לאמת את גרף העבודה שלה. ב-Dataflow, תרשים משימות הוא ייצוג גרפי של צינור. אימות של גרף העבודה מפחית את הסיכון לשגיאות או לכשלים בצינור לאחר העדכון. בנוסף, אתם יכולים לאמת עדכונים בלי להפסיק את העבודה המקורית, כך שלא תהיה השבתה של העבודה.
כדי לאמת את גרף העבודות, פועלים לפי השלבים להפעלת עבודת החלפה. כוללים את graph_validate_only
Dataflow service option בפקודת העדכון.
Java
- מעבירים את האפשרות
--update. - מגדירים את האפשרות
--jobNameב-PipelineOptionsלאותו שם של המשרה שרוצים לעדכן. - מגדירים את האפשרות
--regionלאותו אזור כמו האזור של המשימה שרוצים לעדכן. - כוללים את
--dataflowServiceOptions=graph_validate_onlyאפשרות השירות. - אם שמות של טרנספורמציות בצינור השתנו, צריך לספק מיפוי טרנספורמציות ולהעביר אותו באמצעות האפשרות
--transformNameMapping. - אם אתם שולחים עבודת החלפה שמשתמשת בגרסה מאוחרת יותר של Apache Beam SDK, צריך להגדיר את
--updateCompatibilityVersionלגרסת Apache Beam SDK שבה נעשה שימוש בעבודה המקורית.
Python
- מעבירים את האפשרות
--update. - מגדירים את האפשרות
--job_nameב-PipelineOptionsלאותו שם של המשרה שרוצים לעדכן. - מגדירים את האפשרות
--regionלאותו אזור כמו האזור של המשימה שרוצים לעדכן. - כוללים את
--dataflow_service_options=graph_validate_onlyאפשרות השירות. - אם שמות של טרנספורמציות בצינור השתנו, צריך לספק מיפוי טרנספורמציות ולהעביר אותו באמצעות האפשרות
--transform_name_mapping. - אם אתם שולחים עבודת החלפה שמשתמשת בגרסה מאוחרת יותר של Apache Beam SDK, צריך להגדיר את
--updateCompatibilityVersionלגרסת Apache Beam SDK שבה נעשה שימוש בעבודה המקורית.
המשך
- מעבירים את האפשרות
--update. - מגדירים את האפשרות
--job_nameלאותו שם של המשרה שרוצים לעדכן. - מגדירים את האפשרות
--regionלאותו אזור כמו האזור של המשימה שרוצים לעדכן. - כוללים את
--dataflow_service_options=graph_validate_onlyאפשרות השירות. - אם שמות של טרנספורמציות בצינור השתנו, צריך לספק מיפוי טרנספורמציות ולהעביר אותו באמצעות האפשרות
--transform_name_mapping.
gcloud
כדי לאמת את תרשים העבודה של משימת Flex Template, משתמשים בפקודה gcloud dataflow flex-template run עם האפשרות additional-experiments:
- מעבירים את האפשרות
--update. - מגדירים את JOB_NAME לאותו שם של המשרה שרוצים לעדכן.
- מגדירים את האפשרות
--regionלאותו אזור כמו האזור של המשימה שרוצים לעדכן. - כוללים את האפשרות
--additional-experiments=graph_validate_only. - אם שמות של טרנספורמציות בצינור השתנו, צריך לספק מיפוי טרנספורמציות ולהעביר אותו באמצעות האפשרות
--transform-name-mappings.
לדוגמה:
gcloud dataflow flex-template run JOB_NAME --additional-experiments=graph_validate_only
מחליפים את JOB_NAME בשם של העבודה שרוצים לעדכן.
REST
משתמשים בשדה additionalExperiments באובייקט FlexTemplateRuntimeEnvironment (תבניות Flex) או באובייקט RuntimeEnvironment.
{
additionalExperiments : ["graph_validate_only"]
...
}
אפשרות השירות graph_validate_only מאמתת רק עדכונים של צינורות. אל תשתמשו באפשרות הזו כשאתם יוצרים או מפעילים צינורות. כדי לעדכן את צינור העיבוד, מפעילים משימת החלפה בלי אפשרות השירות graph_validate_only.
אם האימות של תרשים העבודה מצליח, הסטטוסים הבאים מוצגים בסטטוס העבודה וביומני העבודה:
- מצב העבודה הוא
JOB_STATE_DONE. - במסוף Google Cloud , סטטוס העבודה הוא
Succeeded. ההודעה הבאה מופיעה ביומני העבודות:
Workflow job: JOB_ID succeeded validation. Marking graph_validate_only job as Done.
אם האימות של תרשים העבודה נכשל, הסטטוסים הבאים יוצגו במצב העבודה וברישומי הפעילות של העבודה:
- מצב העבודה הוא
JOB_STATE_FAILED. - במסוף Google Cloud , סטטוס העבודה הוא
Failed. - הודעה מופיעה ביומני העבודות ומתארת את שגיאת חוסר התאימות. תוכן ההודעה תלוי בשגיאה.
הפעלת משימת החלפה
יכול להיות שתצטרכו להחליף משרה קיימת מהסיבות הבאות:
- כדי להריץ קוד מעודכן של צינור הנתונים.
- כדי לעדכן אפשרויות של משרות שלא תומכות בעדכונים בזמן ההפעלה.
כדי לוודא שעבודת ההחלפה תקפה, לפני שמפעילים את העבודה החדשה, צריך לאמת את גרף העבודה שלה.
כשמפעילים משימת החלפה, צריך להגדיר את האפשרויות הבאות של הפייפליין כדי לבצע את תהליך העדכון בנוסף לאפשרויות הרגילות של המשימה:
Java
- מעבירים את האפשרות
--update. - מגדירים את האפשרות
--jobNameב-PipelineOptionsלאותו שם של המשרה שרוצים לעדכן. - מגדירים את האפשרות
--regionלאותו אזור כמו האזור של המשימה שרוצים לעדכן. - אם שמות של טרנספורמציות בצינור השתנו, צריך לספק מיפוי טרנספורמציות ולהעביר אותו באמצעות האפשרות
--transformNameMapping. - אם אתם שולחים עבודת החלפה שמשתמשת בגרסה מאוחרת יותר של Apache Beam SDK, צריך להגדיר את
--updateCompatibilityVersionלגרסת Apache Beam SDK שבה נעשה שימוש בעבודה המקורית.
Python
- מעבירים את האפשרות
--update. - מגדירים את האפשרות
--job_nameב-PipelineOptionsלאותו שם של המשרה שרוצים לעדכן. - מגדירים את האפשרות
--regionלאותו אזור כמו האזור של המשימה שרוצים לעדכן. - אם שמות של טרנספורמציות בצינור השתנו, צריך לספק מיפוי טרנספורמציות ולהעביר אותו באמצעות האפשרות
--transform_name_mapping. - אם אתם שולחים עבודת החלפה שמשתמשת בגרסה מאוחרת יותר של Apache Beam SDK, צריך להגדיר את
--updateCompatibilityVersionלגרסת Apache Beam SDK שבה נעשה שימוש בעבודה המקורית.
המשך
- מעבירים את האפשרות
--update. - מגדירים את האפשרות
--job_nameלאותו שם של המשרה שרוצים לעדכן. - מגדירים את האפשרות
--regionלאותו אזור כמו האזור של המשימה שרוצים לעדכן. - אם שמות של טרנספורמציות בצינור השתנו, צריך לספק מיפוי טרנספורמציות ולהעביר אותו באמצעות האפשרות
--transform_name_mapping.
gcloud
כדי לעדכן עבודה של תבנית Flex באמצעות ה-CLI של gcloud, משתמשים בפקודה gcloud dataflow flex-template run. אין תמיכה בעדכון של משימות אחרות באמצעות ה-CLI של gcloud.
- מעבירים את האפשרות
--update. - מגדירים את JOB_NAME לאותו שם של המשרה שרוצים לעדכן.
- מגדירים את האפשרות
--regionלאותו אזור כמו האזור של המשימה שרוצים לעדכן. - אם שמות של טרנספורמציות בצינור השתנו, צריך לספק מיפוי טרנספורמציות ולהעביר אותו באמצעות האפשרות
--transform-name-mappings.
REST
בקטע הזה מוסבר איך לעדכן משימות שאינן מבוססות על תבניות באמצעות REST API. כדי להשתמש ב-REST API כדי לעדכן משימת תבנית קלאסית, אפשר לעיין במאמר בנושא עדכון משימת סטרימינג של תבנית בהתאמה אישית. כדי להשתמש ב-API בארכיטקטורת REST לעדכון של עבודת תבנית Flex, אפשר לעיין במאמר בנושא עדכון של עבודת תבנית Flex.
מאחזרים את המשאב של המשימה שרוצים להחליף באמצעות השיטה
projects.locations.jobs.get.jobכוללים את פרמטר השאילתהviewעם הערךJOB_VIEW_DESCRIPTION. הכללתJOB_VIEW_DESCRIPTIONמגבילה את כמות הנתונים בתגובה, כך שהבקשה הבאה לא תחרוג ממגבלות הגודל. אם אתם צריכים מידע מפורט יותר על המשימה, השתמשו בערךJOB_VIEW_ALL.GET https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs/JOB_ID?view=JOB_VIEW_DESCRIPTIONמחליפים את הערכים הבאים:
- PROJECT_ID: מזהה הפרויקט של משימת Dataflow Google Cloud
- REGION: האזור של המשימה שרוצים לעדכן
- JOB_ID: מזהה העבודה שרוצים לעדכן
כדי לעדכן את המשימה, משתמשים בשיטה
projects.locations.jobs.create. בגוף הבקשה, משתמשים במשאבjobשאוחזר.POST https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs { "id": JOB_ID, "replaceJobId": JOB_ID, "name": JOB_NAME, "type": "JOB_TYPE_STREAMING", "transformNameMapping": { string: string, ... }, }מחליפים את מה שכתוב בשדות הבאים:
- JOB_ID: מזהה העבודה זהה למזהה העבודה שרוצים לעדכן.
- JOB_NAME: אותו שם של משימה כמו השם של המשימה שרוצים לעדכן.
אם השתנו שמות של טרנספורמציות בצינור, צריך לספק מיפוי טרנספורמציות ולהעביר אותו באמצעות השדה
transformNameMapping.אופציונלי: כדי לשלוח את הבקשה באמצעות curl (ב-Linux, ב-macOS או ב-Cloud Shell), שומרים את הבקשה בקובץ JSON ומריצים את הפקודה הבאה:
curl -X POST -d "@FILE_PATH" -H "Content-Type: application/json" -H "Authorization: Bearer $(gcloud auth print-access-token)" https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobsמחליפים את FILE_PATH בנתיב לקובץ ה-JSON שמכיל את גוף הבקשה.
מציינים את שם התפקיד החדש
Java
כשמפעילים את המשרה החדשה, הערך שמעבירים לאפשרות --jobName
צריך להיות זהה בדיוק לשם המשרה שרוצים להחליף.
Python
כשמפעילים את המשרה החדשה, הערך שמעבירים לאפשרות --job_name
צריך להיות זהה בדיוק לשם המשרה שרוצים להחליף.
המשך
כשמפעילים את המשרה החדשה, הערך שמעבירים לאפשרות --job_name
צריך להיות זהה בדיוק לשם המשרה שרוצים להחליף.
gcloud
כשמפעילים את העבודה להחלפה, השם JOB_NAME צריך להיות זהה בדיוק לשם העבודה שרוצים להחליף.
REST
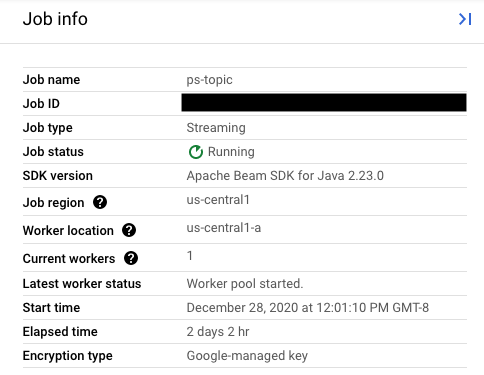
מגדירים את הערך של השדה replaceJobId לאותו מזהה משימה של המשימה שרוצים לעדכן. כדי למצוא את הערך הנכון של שם המשימה, בוחרים את המשימה הקודמת בממשק המעקב של Dataflow.
לאחר מכן, בחלונית הצדדית פרטי משימה, מאתרים את השדה מזהה משימה.
כדי למצוא את הערך הנכון של שם המשימה, בוחרים את המשימה הקודמת בממשק המעקב של Dataflow. לאחר מכן, בחלונית הצדדית Job info, מחפשים את השדה Job name:
אפשר גם לשלוח שאילתה כדי לקבל רשימה של משימות קיימות באמצעות ממשק שורת הפקודה של Dataflow.
מזינים את הפקודה gcloud dataflow jobs list בחלון של מעטפת הפקודות או של הטרמינל כדי לקבל רשימה של משימות Dataflow בפרויקט Google Cloud, ומחפשים את השדה NAME של המשימה שרוצים להחליף:
JOB_ID NAME TYPE CREATION_TIME STATE REGION 2020-12-28_12_01_09-yourdataflowjobid ps-topic Streaming 2020-12-28 20:01:10 Running us-central1
יצירת מיפוי טרנספורמציה
אם צינור ההחלפה משנה שמות של טרנספורמציות מהשמות בצינור הקודם, שירות Dataflow דורש מיפוי טרנספורמציות. מיפוי הטרנספורמציות ממפה את הטרנספורמציות שצוינו בשם בקוד של צינור עיבוד הנתונים הקודם לשמות בקוד של צינור עיבוד הנתונים החדש.
Java
מעבירים את המיפוי באמצעות האפשרות --transformNameMapping בשורת הפקודה, בפורמט הכללי הבא:
--transformNameMapping= .
{"oldTransform1":"newTransform1","oldTransform2":"newTransform2",...}
צריך לספק רק רשומות מיפוי ב---transformNameMapping לשמות של טרנספורמציות שהשתנו בין צינור עיבוד הנתונים הקודם לבין צינור עיבוד הנתונים החדש.
כשמריצים את הפקודה עם --transformNameMapping, יכול להיות שיהיה צורך להשתמש בתו בריחה עבור המירכאות, בהתאם למעטפת הפקודות. לדוגמה, ב-Bash:
--transformNameMapping='{"oldTransform1":"newTransform1",...}'
Python
מעבירים את המיפוי באמצעות האפשרות --transform_name_mapping בשורת הפקודה, בפורמט הכללי הבא:
--transform_name_mapping= .
{"oldTransform1":"newTransform1","oldTransform2":"newTransform2",...}
צריך לספק רק רשומות מיפוי ב---transform_name_mapping לשמות של טרנספורמציות שהשתנו בין צינור עיבוד הנתונים הקודם לבין צינור עיבוד הנתונים החדש.
כשמריצים את הפקודה עם --transform_name_mapping, יכול להיות שיהיה צורך להשתמש בתו בריחה עבור המירכאות, בהתאם למעטפת הפקודות. לדוגמה, ב-Bash:
--transform_name_mapping='{"oldTransform1":"newTransform1",...}'
המשך
מעבירים את המיפוי באמצעות האפשרות --transform_name_mapping בשורת הפקודה, בפורמט הכללי הבא:
--transform_name_mapping= .
{"oldTransform1":"newTransform1","oldTransform2":"newTransform2",...}
צריך לספק רק רשומות מיפוי ב---transform_name_mapping לשמות של טרנספורמציות שהשתנו בין צינור עיבוד הנתונים הקודם לבין צינור עיבוד הנתונים החדש.
כשמריצים את הפקודה עם --transform_name_mapping, יכול להיות שיהיה צורך להשתמש בתו בריחה עבור המירכאות, בהתאם למעטפת הפקודות. לדוגמה, ב-Bash:
--transform_name_mapping='{"oldTransform1":"newTransform1",...}'
gcloud
מעבירים את המיפוי באמצעות האפשרות --transform-name-mappings
בפורמט הכללי הבא:
--transform-name-mappings= .
{"oldTransform1":"newTransform1","oldTransform2":"newTransform2",...}
צריך לספק רק רשומות מיפוי ב---transform-name-mappings לשמות של טרנספורמציות שהשתנו בין צינור עיבוד הנתונים הקודם לבין צינור עיבוד הנתונים החדש.
כשמריצים את הפקודה עם --transform-name-mappings, יכול להיות שיהיה צורך להוסיף תו escape למירכאות בהתאם למעטפת. לדוגמה, ב-Bash:
--transform-name-mappings='{"oldTransform1":"newTransform1",...}'
REST
מעבירים את המיפוי באמצעות השדה transformNameMapping
בפורמט הכללי הבא:
"transformNameMapping": {
oldTransform1: newTransform1,
oldTransform2: newTransform2,
...
}
צריך לספק רק רשומות מיפוי ב-transformNameMapping לשמות של טרנספורמציות שהשתנו בין צינור עיבוד הנתונים הקודם לבין צינור עיבוד הנתונים החדש.
קביעת שמות הטרנספורמציות
שם הטרנספורמציה בכל מופע במפה הוא השם שסיפקתם כשיישמתם את הטרנספורמציה בצינור. לדוגמה:
Java
.apply("FormatResults", ParDo
.of(new DoFn<KV<String, Long>>, String>() {
...
}
}))
Python
| 'FormatResults' >> beam.ParDo(MyDoFn())
המשך
// In Go, this is always the package-qualified name of the DoFn itself.
// For example, if the FormatResults DoFn is in the main package, its name
// is "main.FormatResults".
beam.ParDo(s, FormatResults, results)
אפשר גם לקבל את שמות הטרנספורמציות של העבודה הקודמת על ידי בדיקת גרף הביצוע של העבודה בממשק המעקב של Dataflow:
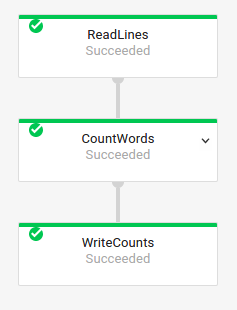
שמות של טרנספורמציות מורכבות
שמות הטרנספורמציות הם היררכיים, על סמך היררכיית הטרנספורמציות בצינור. אם צינור העיבוד כולל טרנספורמציה מורכבת, הטרנספורמציות המקוננות נקראות לפי הטרנספורמציה שמכילה אותן. לדוגמה, נניח שצינור הנתונים מכיל טרנספורמציה מורכבת בשם CountWidgets, שמכילה טרנספורמציה פנימית בשם Parse. השם המלא של ההמרה הוא CountWidgets/Parse, ואתם צריכים לציין את השם המלא הזה במיפוי ההמרה.
אם צינור הנתונים החדש ממפה טרנספורמציה מורכבת לשם אחר, כל הטרנספורמציות המקוננות מקבלות גם הן שם חדש באופן אוטומטי. במיפוי ההמרות צריך לציין את השמות החדשים של ההמרות הפנימיות.
שינוי מבנה ההיררכיה של הטרנספורמציות
אם צינור ההחלפה משתמש בהיררכיית טרנספורמציות שונה מזו של צינור הנתונים הקודם, צריך להצהיר במפורש על המיפוי. יכול להיות שיש לכם היררכיית טרנספורמציות שונה כי ביצעתם רפקטורינג של טרנספורמציות מורכבות, או שצינור הנתונים שלכם תלוי בטרנספורמציה מורכבת מספרייה שהשתנתה.
לדוגמה, בצינור הקודם הוחל טרנספורמציה מורכבת, CountWidgets, שהכילה טרנספורמציה פנימית בשם Parse. צינור ההחלפה מבצע רפקטורינג של CountWidgets ומקנן את Parse בתוך טרנספורמציה אחרת בשם Scan. כדי שהעדכון יצליח, צריך למפות באופן מפורש את שם הטרנספורמציה המלא בצינור הקודם (CountWidgets/Parse) לשם הטרנספורמציה בצינור החדש (CountWidgets/Scan/Parse):
Java
--transformNameMapping={"CountWidgets/Parse":"CountWidgets/Scan/Parse"}
אם מוחקים טרנספורמציה לגמרי בצינור ההחלפה, צריך לספק מיפוי null. נניח שצינור ההחלפה מסיר את טרנספורמציית CountWidgets/Parse לחלוטין:
--transformNameMapping={"CountWidgets/Parse":""}
Python
--transform_name_mapping={"CountWidgets/Parse":"CountWidgets/Scan/Parse"}
אם מוחקים טרנספורמציה לגמרי בצינור ההחלפה, צריך לספק מיפוי null. נניח שצינור ההחלפה מסיר את טרנספורמציית CountWidgets/Parse לחלוטין:
--transform_name_mapping={"CountWidgets/Parse":""}
המשך
--transform_name_mapping={"CountWidgets/main.Parse":"CountWidgets/Scan/main.Parse"}
אם מוחקים טרנספורמציה לגמרי בצינור ההחלפה, צריך לספק מיפוי null. נניח שצינור ההחלפה מסיר את טרנספורמציית CountWidgets/Parse לחלוטין:
--transform_name_mapping={"CountWidgets/main.Parse":""}
gcloud
--transform-name-mappings={"CountWidgets/Parse":"CountWidgets/Scan/Parse"}
אם מוחקים טרנספורמציה לגמרי בצינור ההחלפה, צריך לספק מיפוי null. נניח שצינור עיבוד הנתונים החלופי מסיר את טרנספורמציית CountWidgets/Parse לחלוטין:
--transform-name-mappings={"CountWidgets/main.Parse":""}
REST
"transformNameMapping": {
CountWidgets/Parse: CountWidgets/Scan/Parse
}
אם מוחקים טרנספורמציה לגמרי בצינור ההחלפה, צריך לספק מיפוי null. נניח שצינור עיבוד הנתונים החלופי מסיר את טרנספורמציית CountWidgets/Parse לחלוטין:
"transformNameMapping": {
CountWidgets/main.Parse: null
}
ההשפעות של החלפת משרה
כשמחליפים משימה קיימת, משימה חדשה מריצה את קוד צינור העיבוד המעודכן. שם המשימה נשמר בשירות Dataflow, אבל מריצים את משימת ההחלפה עם מזהה משימה מעודכן. התהליך הזה עלול לגרום להשבתה זמנית בזמן שהמשימה הקיימת מפסיקה, בדיקת התאימות פועלת והמשימה החדשה מתחילה.
עבודת ההחלפה שומרת את הפריטים הבאים:
- נתונים ממצב ביניים מהעבודה הקודמת. מטמון בזיכרון לא נשמר.
- רשומות נתונים שנמצאות בזיכרון המטמון או מטא-נתונים שנמצאים כרגע בתהליך העברה מהעבודה הקודמת. לדוגמה, יכול להיות שחלק מהרשומות בצינור יאגרו בזיכרון בזמן ההמתנה לחלון שיסתיים.
- עדכונים לגבי אפשרויות של משרות פעילות שהחלתם על המשרה הקודמת.
אם צינור עיבוד הנתונים מכיל מחברי קלט/פלט מנוהל, מערכת Dataflow בודקת אם יש עדכונים למחברים ומשתמשת אוטומטית בגרסה האחרונה הידועה כטובה. מידע נוסף מופיע במאמר בנושא שדרוגים אוטומטיים
נתונים של מצב ביניים
נתוני מצב ביניים מהעבודה הקודמת נשמרים. נתוני מצב לא כוללים מטמון בזיכרון. אם רוצים לשמור את נתוני המטמון בזיכרון כשמעדכנים את צינור העיבוד, אפשר לשנות את המבנה של צינור העיבוד כדי להמיר את המטמון לנתוני מצב או לקלט צדדי. מידע נוסף על שימוש בקלט צדדי זמין במאמר תבניות של קלט צדדי במסמכי התיעוד של Apache Beam.
לצינורות עיבוד נתונים של סטרימינג יש מגבלות גודל עבור ValueState ועבור קלט צדדי.
לכן, אם יש לכם מטמון גדול שאתם רוצים לשמור, יכול להיות שתצטרכו להשתמש באחסון חיצוני, כמו Memorystore או Bigtable.
נתונים במהלך הטיסה
הנתונים 'במהלך ההעברה' עדיין מעובדים על ידי הטרנספורמציות בצינור החדש. עם זאת, יכול להיות שטרנספורמציות נוספות שמוסיפים בקוד של צינור ההחלפה יופעלו או לא יופעלו, בהתאם למקום שבו הרשומות נשמרות במאגר. בדוגמה הזו, צינור העיבוד הקיים כולל את טרנספורמציות הנתונים הבאות:
Java
p.apply("Read", ReadStrings())
.apply("Format", FormatStrings());
Python
p | 'Read' >> beam.io.ReadFromPubSub(subscription=known_args.input_subscription)
| 'Format' >> FormatStrings()
המשך
beam.ParDo(s, ReadStrings) beam.ParDo(s, FormatStrings)
אפשר להחליף את הג'וב בקוד חדש של צינור, באופן הבא:
Java
p.apply("Read", ReadStrings())
.apply("Remove", RemoveStringsStartingWithA())
.apply("Format", FormatStrings());
Python
p | 'Read' >> beam.io.ReadFromPubSub(subscription=known_args.input_subscription)
| 'Remove' >> RemoveStringsStartingWithA()
| 'Format' >> FormatStrings()
המשך
beam.ParDo(s, ReadStrings) beam.ParDo(s, RemoveStringsStartingWithA) beam.ParDo(s, FormatStrings)
גם אם מוסיפים טרנספורמציה כדי לסנן מחרוזות שמתחילות באות A, יכול להיות שהטרנספורמציה הבאה (FormatStrings) עדיין תראה מחרוזות בזיכרון או מחרוזות בתהליך שמתחילות באות A והועברו מהעבודה הקודמת.
שינוי החלונות
אפשר לשנות את האסטרטגיות של חלונות הזמן ושל הטריגרים עבור רכיבי PCollection בצינור ההחלפה, אבל צריך לעשות את זה בזהירות.
שינוי האסטרטגיות של חלונות או טריגרים לא משפיע על נתונים שכבר נמצאים במאגר או בשידור.
מומלץ לנסות לבצע רק שינויים קטנים בחלונות של צינור הנתונים, כמו שינוי משך הזמן של חלונות זמן קבועים או נעים. ביצוע שינויים משמעותיים בחלונות או בטריגרים, כמו שינוי אלגוריתם החלונות, עלול להניב תוצאות בלתי צפויות בפלט של צינור הנתונים.
בדיקת התאמה למשרה
כשמפעילים את משימת ההחלפה, שירות Dataflow מבצע בדיקת תאימות בין משימת ההחלפה לבין המשימה הקודמת. אם בדיקת התאימות עוברת, העבודה הקודמת שלכם מופסקת. לאחר מכן, משימת ההחלפה מופעלת בשירות Dataflow, תוך שמירה על אותו שם משימה. אם בדיקת התאימות נכשלת, העבודה הקודמת ממשיכה לפעול בשירות Dataflow ועבודת ההחלפה מחזירה שגיאה.
Java
בגלל מגבלה, צריך להשתמש בחסימת הביצוע כדי לראות שגיאות של ניסיון עדכון שנכשל במסוף או בטרמינל. הפתרון העקיף הנוכחי כולל את השלבים הבאים:
- משתמשים ב-pipeline.run().waitUntilFinish() בקוד של צינור עיבוד הנתונים.
- מריצים את התוכנית של צינור ההחלפה עם האפשרות
--update. - מחכים שמשימת ההחלפה תעבור בהצלחה את בדיקת התאימות.
- כדי לצאת מתהליך ההפעלה של החסימה, מקלידים
Ctrl+C.
לחלופין, אפשר לעקוב אחרי הסטטוס של עבודת ההחלפה בממשק המעקב של Dataflow. אם העבודה שלכם התחילה בהצלחה, סימן שהיא עברה גם את בדיקת התאימות.
Python
בגלל מגבלה, צריך להשתמש בחסימת הביצוע כדי לראות שגיאות של ניסיון עדכון שנכשל במסוף או בטרמינל. הפתרון העקיף הנוכחי כולל את השלבים הבאים:
- משתמשים ב-pipeline.run().wait_until_finish() בקוד של צינור עיבוד הנתונים.
- מריצים את התוכנית של צינור ההחלפה עם האפשרות
--update. - מחכים שמשימת ההחלפה תעבור בהצלחה את בדיקת התאימות.
- כדי לצאת מתהליך ההפעלה של החסימה, מקלידים
Ctrl+C.
לחלופין, אפשר לעקוב אחרי הסטטוס של עבודת ההחלפה בממשק המעקב של Dataflow. אם העבודה שלכם התחילה בהצלחה, סימן שהיא עברה גם את בדיקת התאימות.
המשך
בגלל מגבלה, צריך להשתמש בחסימת הביצוע כדי לראות שגיאות של ניסיון עדכון שנכשל במסוף או בטרמינל.
באופן ספציפי, צריך לציין ביצוע לא חוסם באמצעות הדגלים --execute_async או --async. הפתרון העקיף הנוכחי כולל את השלבים הבאים:
- מריצים את תוכנית צינור ההחלפה עם האפשרות
--updateובלי הדגלים--execute_asyncאו--async. - מחכים שמשימת ההחלפה תעבור בהצלחה את בדיקת התאימות.
- כדי לצאת מתהליך ההפעלה של החסימה, מקלידים
Ctrl+C.
gcloud
בגלל מגבלה, צריך להשתמש בחסימת הביצוע כדי לראות שגיאות של ניסיון עדכון שנכשל במסוף או בטרמינל. הפתרון העקיף הנוכחי כולל את השלבים הבאים:
- בצינורות עיבוד נתונים של Java, משתמשים ב-pipeline.run().waitUntilFinish() בקוד של צינור עיבוד הנתונים. בצינורות עיבוד נתונים של Python, משתמשים ב-pipeline.run().wait_until_finish() בקוד של צינור עיבוד הנתונים. לצינורות Go, פועלים לפי השלבים בכרטיסייה Go.
- מריצים את התוכנית של צינור ההחלפה עם האפשרות
--update. - מחכים שמשימת ההחלפה תעבור בהצלחה את בדיקת התאימות.
- כדי לצאת מתהליך ההפעלה של החסימה, מקלידים
Ctrl+C.
REST
בגלל מגבלה, צריך להשתמש בחסימת הביצוע כדי לראות שגיאות של ניסיון עדכון שנכשל במסוף או בטרמינל. הפתרון העקיף הנוכחי כולל את השלבים הבאים:
- בצינורות עיבוד נתונים של Java, משתמשים ב-pipeline.run().waitUntilFinish() בקוד של צינור עיבוד הנתונים. בצינורות עיבוד נתונים של Python, משתמשים ב-pipeline.run().wait_until_finish() בקוד של צינור עיבוד הנתונים. לצינורות Go, פועלים לפי השלבים בכרטיסייה Go.
- מריצים את תוכנית צינור ההחלפה עם השדה
replaceJobId. - מחכים שמשימת ההחלפה תעבור בהצלחה את בדיקת התאימות.
- כדי לצאת מתהליך ההפעלה של החסימה, מקלידים
Ctrl+C.
בבדיקת התאימות נעשה שימוש במיפוי הטרנספורמציה שסיפקתם כדי לוודא ש-Dataflow יכול להעביר נתוני מצב ביניים מהשלבים בעבודה הקודמת לעבודה החדשה. בדיקת התאימות מוודאת גם ש-PCollection בצינור עיבוד הנתונים משתמשים באותם Coders.
שינוי של Coder עלול לגרום לכך שבדיקת התאימות תיכשל, כי יכול להיות שנתונים שנמצאים בתהליך או רשומות שנשמרו במאגר הזמני לא יעברו סריאליזציה בצורה נכונה בצינור ההחלפה.
מניעת בעיות תאימות
הבדלים מסוימים בין צינור עיבוד הנתונים הקודם לבין צינור עיבוד הנתונים החדש יכולים לגרום לכך שבדיקת התאימות תיכשל. ההבדלים האלה כוללים:
- שינוי תרשים צינור העיבוד בלי לספק מיפוי. כשמעדכנים משימה, Dataflow מנסה להתאים את הטרנספורמציות במשימה הקודמת לטרנספורמציות במשימת ההחלפה. תהליך ההתאמה הזה עוזר להעביר את נתוני המצב הביניים של כל שלב ב-Dataflow. אם משנים את השם של שלב כלשהו או מסירים אותו, צריך לספק מיפוי טרנספורמציה כדי ש-Dataflow יוכל להתאים את נתוני המצב בהתאם.
- שינוי של קלט צדדי לשלב מסוים. הוספה של קלט צדדי לטרנספורמציה בצינור ההחלפה או הסרה שלו ממנה גורמת לכך שבדיקת התאימות תיכשל.
- שינוי הקודן בשלב מסוים. כשמעדכנים עבודה, Dataflow שומר את כל רשומות הנתונים שנמצאות כרגע במאגר הזמני ומטפל בהן בעבודה החלופית. לדוגמה, יכול להיות שיהיו נתונים באגירה בזמן שמתבצעת חלוקה לחלונות. אם עבודת ההחלפה משתמשת בקידוד נתונים שונה או לא תואם, Dataflow לא יכול לבצע סריאליזציה או דה-סריאליזציה של הרשומות האלה.
הסרת פעולה 'עם שמירת מצב' מצינור הנתונים. אם מסירים מהצינור פעולות עם שמירת מצב, יכול להיות שהתאימות של העבודה החלופית תיכשל. Dataflow יכול למזג כמה שלבים כדי לייעל את התהליך. אם מסירים פעולה שתלויה במצב מתוך שלב מאוחד, הבדיקה נכשלת. פעולות עם שמירת מצב כוללות:
- טרנספורמציות שמייצרות או צורכות קלט צדדי.
- קריאות קלט/פלט.
- טרנספורמציות שמשתמשות במצב עם מפתח.
- טרנספורמציות שכוללות מיזוג חלונות.
שינוי משתנים
DoFnעם שמירת מצב. במשימות סטרימינג מתמשכות, אם צינור הנתונים כוללDoFns עם שמירת מצב, שינוי המשתנים שלDoFns עם שמירת מצב עלול לגרום לצינור הנתונים להיכשל.מנסים להריץ את עבודת ההחלפה באזור גיאוגרפי אחר. מריצים את משימת ההחלפה באותו אזור שבו הרצתם את המשימה הקודמת, אחרת משימת ההחלפה תיכשל.
עדכון סכימות
Apache Beam מאפשר ל-PCollection להיות סכימות עם שדות בעלי שם, ובמקרה כזה לא צריך Coders מפורשים. אם שמות השדות והסוגים של סכימה מסוימת לא השתנו (כולל שדות מקוננים), הסכימה הזו לא תגרום לכך שבדיקת העדכון תיכשל. עם זאת, יכול להיות שהעדכון עדיין ייחסם אם קטעים אחרים של צינור הנתונים החדש לא תואמים.
פיתוח סכימות
לעתים קרובות יש צורך לפתח סכימה של PCollection עקב דרישות עסקיות משתנות. שירות Dataflow מאפשר לבצע את השינויים הבאים בסכימה כשמעדכנים צינור:
- הוספה של שדה חדש אחד או יותר לסכימה, כולל שדות מקוננים.
- הפיכת סוג שדה חובה (שלא ניתן להגדיר כ-null) לאופציונלי (ניתן להגדיר כ-null).
במהלך העדכון אסור להסיר שדות, לשנות את שמות השדות או לשנות את סוגי השדות.
העברת נתונים נוספים לפעולת ParDo קיימת
אתם יכולים להעביר נתונים נוספים (מחוץ לפס) לפעולת ParDo קיימת באמצעות אחת מהשיטות הבאות, בהתאם לתרחיש השימוש:
- מבצעים סריאליזציה של המידע כשדות במחלקת המשנה
DoFn. - כל המשתנים שאליהם מתייחסות השיטות ב-
DoFnאנונימי עוברים סריאליזציה באופן אוטומטי. - חישוב נתונים בתוך
DoFn.startBundle(). - העברת נתונים באמצעות
ParDo.withSideInputs.
מידע נוסף זמין בדפים הבאים:
- מדריך התכנות של Apache Beam: ParDo, במיוחד הקטעים על יצירת DoFn וכניסות צד.
- מקורות מידע בנושא Apache Beam SDK for Java: ParDo