
התכונה 'קלט/פלט מנוהל' מאפשרת ל-Dataflow לנהל מחברים ספציפיים של קלט/פלט שמשמשים בצינורות של Apache Beam. התכונה 'ניהול קלט/פלט' מפשטת את הניהול של צינורות נתונים שמשולבים עם מקורות ויעדים נתמכים.
I/O מנוהל מורכב משני רכיבים שפועלים יחד:
טרנספורמציה של Apache Beam שמספקת API משותף ליצירת מחברי קלט/פלט (מקורות ויעדים).
שירות Dataflow שמנהל את מחברי הקלט/פלט האלה בשמכם, כולל האפשרות לשדרג אותם בנפרד מגרסת Apache Beam.
היתרונות של קלט/פלט מנוהל כוללים את הדברים הבאים:
שדרוגים אוטומטיים. Dataflow משדרג באופן אוטומטי את מחברי הקלט/פלט המנוהלים בצינור הנתונים. כלומר, צינור הנתונים מקבל תיקוני אבטחה, שיפורי ביצועים ותיקוני באגים עבור המחברים האלה, בלי שנדרשים שינויים בקוד. מידע נוסף זמין במאמר בנושא שדרוגים אוטומטיים.
Consistent API. באופן מסורתי, למחברי קלט/פלט ב-Apache Beam יש ממשקי API נפרדים, וכל מחבר מוגדר בצורה שונה. Managed I/O מספק API יחיד להגדרה שמשתמש במאפיינים של ערך-מפתח, וכך קוד צינור עיבוד הנתונים פשוט ועקבי יותר. מידע נוסף זמין במאמר בנושא Configuration API.
דרישות
ערכות ה-SDK הבאות תומכות בניהול קלט/פלט:
- Apache Beam SDK ל-Java בגרסה 2.58.0 ואילך.
- Apache Beam SDK for Python בגרסה 2.61.0 ואילך.
השירות לקצה העורפי דורש Dataflow Runner v2. אם Runner v2 לא מופעל, הצינור עדיין פועל, אבל הוא לא נהנה מהיתרונות של שירות ה-I/O המנוהל.
שדרוגים אוטומטיים
צינורות Dataflow עם מחברי קלט/פלט מנוהלים משתמשים באופן אוטומטי בגרסה המהימנה האחרונה של המחבר. שדרוגים אוטומטיים מתרחשים בנקודות הבאות במחזור החיים של המשרה:
שליחת משרה. כששולחים עבודה של אצווה או סטרימינג, Dataflow משתמש בגרסה העדכנית ביותר של מחבר ה-I/O המנוהל שנבדקה ופועלת היטב.
שדרוגים מדורגים. במשימות של סטרימינג, מערכת Dataflow משדרגת את מחברי הקלט/פלט המנוהלים בצינורות עיבוד נתונים פעילים כשהגרסאות החדשות זמינות. אתם לא צריכים לדאוג לעדכון ידני של המחבר או של גרסת Apache Beam של צינור הנתונים.
כברירת מחדל, שדרוגים מתגלגלים מתבצעים בחלון של 30 יום – כלומר, השדרוגים מתבצעים בערך כל 30 יום. אפשר לשנות את חלון הזמנים או להשבית את השדרוגים המתגלגלים לכל משימה בנפרד. מידע נוסף מופיע במאמר בנושא הגדרת חלון השדרוג המתגלגל.
שבוע לפני השדרוג, Dataflow כותב הודעה ליומני ההודעות של המשימה.
משימות החלפה. במשימות סטרימינג, מערכת Dataflow בודקת אם יש עדכונים בכל פעם שמפעילים משימת החלפה, ומשתמשת אוטומטית בגרסה האחרונה הידועה כטובה. Dataflow מבצע את הבדיקה הזו גם אם לא משנים קוד בעבודת ההחלפה.
בתרשים הבא מוצג תהליך השדרוג. המשתמש יוצר צינור (pipeline) של Apache Beam באמצעות גרסת SDK X. Dataflow משדרג את הגרסה של Managed I/O לגרסה העדכנית ביותר שנתמכת. השדרוג מתבצע כשהמשתמש שולח את העבודה, אחרי חלון השדרוג המתגלגל, או כשהמשתמש שולח עבודה חלופית.
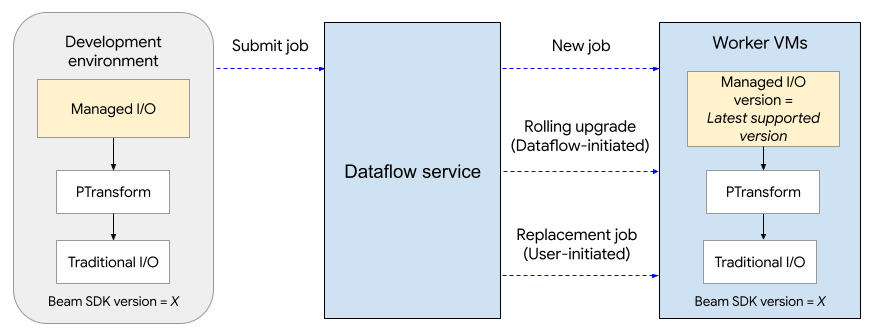
תהליך השדרוג מוסיף בערך שתי דקות לזמן ההפעלה של המשימה הראשונה (לכל פרויקט) שמשתמשת ב-I/O מנוהל, ויכול להוסיף בערך חצי דקה למשימות הבאות. בשדרוגים מתגלגלים, שירות Dataflow מפעיל עבודת החלפה. הפעולה הזו עלולה לגרום להשבתה זמנית של צינור הנתונים, כי מאגר העובדים הקיים מושבת ומופעל מאגר עובדים חדש. כדי לבדוק את הסטטוס של פעולות קלט/פלט מנוהלות, מחפשים רשומות ביומן שכוללות את המחרוזת Managed Transform(s).
הגדרת חלון השדרוג המתגלגל
כדי לציין את חלון השדרוג של משימת Dataflow בסטרימינג, מגדירים את managed_transforms_rolling_upgrade_window
service option כמספר הימים. הערך חייב להיות בין 10 ל-90 ימים, כולל.
Java
--dataflowServiceOptions=managed_transforms_rolling_upgrade_window=DAYS
Python
--dataflow_service_options=managed_transforms_rolling_upgrade_window=DAYS
gcloud
משתמשים בפקודה gcloud dataflow jobs run עם האפשרות additional-experiments. אם אתם משתמשים בתבנית Flex שמשתמשת ב-Managed I/O, אתם צריכים להשתמש בפקודה gcloud dataflow flex-template run.
--additional-experiments=managed_transforms_rolling_upgrade_window=DAYS
כדי להשבית את השדרוגים המתגלגלים, מגדירים את אפשרות השירות managed_transforms_rolling_upgrade_window
לערך never. עדיין אפשר להפעיל עדכון על ידי הפעלת משימת החלפה.
Java
--dataflowServiceOptions=managed_transforms_rolling_upgrade_window=never
Python
--dataflow_service_options=managed_transforms_rolling_upgrade_window=never
המשך
--dataflow_service_options=managed_transforms_rolling_upgrade_window=never
gcloud
משתמשים בפקודה gcloud dataflow jobs run עם האפשרות additional-experiments. אם משתמשים בתבניות Flex, משתמשים בפקודה gcloud dataflow flex-template run.
--additional-experiments=managed_transforms_rolling_upgrade_window=never
Configuration API
Managed I/O הוא טרנספורמציה מוכנה לשימוש ב-Apache Beam, שמספקת API עקבי להגדרת מקורות ויעדים.
Java
כדי ליצור מקור או יעד שנתמכים על ידי Managed I/O, משתמשים במחלקה Managed. מציינים איזה מקור או יעד ליצור, ומעבירים קבוצה של פרמטרים להגדרה, בדומה לדוגמה הבאה:
Map config = ImmutableMap.<String, Object>builder()
.put("config1", "abc")
.put("config2", 1);
pipeline.apply(Managed.read(/*Which source to read*/).withConfig(config))
.getSinglePCollection();
אפשר גם להעביר פרמטרים של הגדרות כקובץ YAML. דוגמה מלאה לקוד זמינה במאמר בנושא קריאה מ-Apache Iceberg.
Python
מייבאים את המודול apache_beam.transforms.managed ומבצעים קריאה לשיטה managed.Read או managed.Write. מציינים איזה מקור או יעד ליצור, ומעבירים קבוצה של פרמטרים להגדרה, בדומה לדוגמה הבאה:
pipeline
| beam.managed.Read(
beam.managed.SOURCE, # Example: beam.managed.KAFKA
config={
"config1": "abc",
"config2": 1
}
)
אפשר גם להעביר פרמטרים של הגדרות כקובץ YAML. דוגמה מלאה לקוד מופיעה במאמר בנושא קריאה מ-Apache Kafka.
יעדים דינמיים
בחלק מהיעדים, מחבר ה-I/O המנוהל יכול לבחור באופן דינמי יעד על סמך ערכי השדות ברשומות הנכנסות.
כדי להשתמש ביעדים דינמיים, צריך לספק מחרוזת תבנית ליעד. מחרוזת התבנית יכולה לכלול שמות של שדות בתוך סוגריים מסולסלים, כמו "tables.{field1}". בזמן הריצה, המחבר מחליף את הערך של השדה בכל רשומה נכנסת, כדי לקבוע את היעד של הרשומה.
לדוגמה, נניח שלנתונים שלכם יש שדה בשם airport. אפשר להגדיר את היעד ל-"flights.{airport}". אם airport=SFO, הרשומה נכתבת ב-flights.SFO. בשדות מקוננים, משתמשים בסימון נקודות. לדוגמה:
{top.middle.nested}.
דוגמאות לקוד שמציגות איך להשתמש ביעדים דינמיים זמינות במאמר כתיבה עם יעדים דינמיים.
סינון
אולי תרצו לסנן שדות מסוימים לפני שהם נכתבים לטבלת היעד. במקורות נתונים (sinks) שתומכים ביעדים דינמיים, אפשר להשתמש בפרמטרים drop, keep או only למטרה הזו. הפרמטרים האלה מאפשרים לכם לכלול מטא-נתונים של היעד ברשומות הקלט, בלי לכתוב את המטא-נתונים ביעד.
אפשר להגדיר לכל היותר אחד מהפרמטרים האלה לכל יעד.
| פרמטר להגדרה | סוג נתונים | תיאור |
|---|---|---|
drop |
list of strings | רשימה של שמות שדות שיושמטו לפני הכתיבה ליעד. |
keep |
list of strings | רשימה של שמות השדות שרוצים לשמור כשכותבים ליעד. המערכת משמיטה את שאר השדות. |
only |
מחרוזת | השם של שדה אחד בלבד לשימוש כרשומה ברמה העליונה לכתיבה כשכותבים ליעד. כל שאר השדות יוסרו. השדה הזה חייב להיות מסוג שורה. |
מקורות ו-Sinks נתמכים
Managed I/O תומך במקורות ובמטרות הבאים.
מידע נוסף זמין במאמר בנושא מחברים מנוהלים של קלט/פלט במאמרי העזרה של Apache Beam.