
בדף הזה מוסבר איך להריץ צינור עיבוד נתונים של Apache Beam ב-Dataflow עם מעבדי GPU. על משימות שמשתמשות במעבדי GPU חלים חיובים כמו שמפורט בדף התמחור של Dataflow.
למידע נוסף על שימוש ביחידות GPU עם Dataflow, אפשר לעיין במאמר בנושא תמיכה ב-GPU ב-Dataflow. מידע נוסף על תהליך העבודה של מפתחים ליצירת צינורות עיבוד נתונים באמצעות יחידות GPU זמין במאמר מידע על יחידות GPU ב-Dataflow.
שימוש ב-Notebooks של Apache Beam
אם כבר יש לכם צינור שאתם רוצים להריץ עם מעבדי GPU ב-Dataflow, אתם יכולים לדלג על הקטע הזה.
קובצי notebook של Apache Beam מאפשרים ליצור אב טיפוס ולפתח את צינור הנתונים באופן איטרטיבי באמצעות מעבדי GPU, בלי להגדיר סביבת פיתוח. כדי להתחיל, כדאי לקרוא את המדריך פיתוח באמצעות מחברות Apache Beam, להפעיל מופע של מחברות Apache Beam ולעיין במחברת לדוגמה שימוש במעבדי GPU עם Apache Beam.
הקצאת מכסת GPU
מכסת הזמינות של מכשירי GPU תלויה ב Google Cloud פרויקט. שליחת בקשה למכסת GPU באזור שבחרתם.
התקנת דרייברים של GPU
כדי להתקין דרייברים של NVIDIA ב-workers של Dataflow, מוסיפים install-nvidia-driver לאפשרות השירות worker_accelerator.
כשמציינים את האפשרות install-nvidia-driver, Dataflow מתקין דרייברים של NVIDIA על העובדים של Dataflow באמצעות כלי השירות cos-extensions שסופק על ידי Container-Optimized OS. בציון install-nvidia-driver,
אתם מסכימים לתנאי הסכם הרישיון של NVIDIA.
Dataflow תומך בהוספת גרסה לאפשרות install-nvidia-driver בתור install-nvidia-driver:VERSION. הגרסאות הבאות נתמכות:
- ברירת מחדל
- האחרון
אם לא מציינים גרסה, המשמעות היא install-nvidia-driver:default. אם מסופקת גרסה לא מזוהה, התקנת הדרייבר של ה-GPU נכשלת.
קובצי ההפעלה והספריות שמסופקים על ידי תוכנת ההתקנה של מנהל ההתקן של NVIDIA מותקנים בקונטיינר שמריץ את קוד המשתמש של צינור עיבוד הנתונים בנתיב /usr/local/nvidia/.
גרסת מנהל ההתקן של ה-GPU עבור גרסאות default ו-latest תלויה בגרסת מערכת ההפעלה שמותאמת לקונטיינרים שבה נעשה שימוש ב-Dataflow. כדי למצוא את גרסת מנהל ההתקן של ה-GPU עבור משימת Dataflow מסוימת, מחפשים את GPU driver ביומני השלבים של Dataflow של המשימה.
כשבודקים את היומנים של Dataflow אחרי התקנת הדרייבר, יכול להיות שתופיע שורה כמו:
| NVIDIA-SMI 535.261.03 Driver Version: 535.261.03 CUDA Version: 12.2 |
הגרסה של CUDA במקרה הזה היא גרסת ה-CUDA של מנהל ההתקן, ששונה מגרסת ה-CUDA של זמן הריצה שמותקנת בתמונת הקונטיינר המותאמת אישית או הקיימת. אם גרסת מנהל ההתקן הזו גדולה מגרסת זמן הריצה או שווה לה, לא צריך לבצע פעולות נוספות. אם זו גרסה מוקדמת יותר, תצטרכו לפעול לפי מסמכי התאימות של NVIDIA CUDA כשתיצרו את תמונת הקונטיינר.
יצירת אימג' מותאם אישית של קונטיינר
כדי ליצור אינטראקציה עם יחידות ה-GPU, יכול להיות שתצטרכו תוכנה נוספת של NVIDIA, כמו ספריות עם האצת GPU וCUDA Toolkit. אספקת הספריות האלה בקונטיינר Docker שבו מופעל קוד המשתמש.
כדי להתאים אישית את קובץ האימג' של הקונטיינר, צריך לספק קובץ אימג' שעומד בדרישות של חוזה קובץ האימג' של הקונטיינר של Apache Beam SDK, ושכולל את ספריות ה-GPU הנדרשות.
כדי לספק קובץ אימג' מותאם אישית של קונטיינר, משתמשים ב-Dataflow Portable Runner ומספקים את קובץ האימג' של הקונטיינר באמצעות האפשרות sdk_container_image pipeline.
אם אתם משתמשים בגרסה 2.29.0 או בגרסה מוקדמת יותר של Apache Beam, אתם צריכים להשתמש באפשרות worker_harness_container_image של צינור הנתונים. מידע נוסף מופיע במאמר בנושא שימוש במאגרי תגים בהתאמה אישית.
כדי ליצור קובץ אימג' מותאם אישית של מאגר תגים, אפשר להשתמש באחת משתי הגישות הבאות:
שימוש בתמונה קיימת שהוגדרה לשימוש ב-GPU
אתם יכולים ליצור קובץ אימג' של Docker שממלא את החוזה של קונטיינר Apache Beam SDK מתוך קובץ אימג' בסיסי קיים שהוגדר מראש לשימוש ב-GPU. לדוגמה, קובצי אימג' של TensorFlow Docker וקובצי אימג' של NVIDIA container מוגדרים מראש לשימוש ב-GPU.
קובץ Dockerfile לדוגמה שמתבסס על קובץ אימג' של TensorFlow Docker עם Python 3.6 נראה כמו בדוגמה הבאה:
ARG BASE=tensorflow/tensorflow:2.5.0-gpu
FROM $BASE
# Check that the chosen base image provides the expected version of Python interpreter.
ARG PY_VERSION=3.6
RUN [[ $PY_VERSION == `python -c 'import sys; print("%s.%s" % sys.version_info[0:2])'` ]] \
|| { echo "Could not find Python interpreter or Python version is different from ${PY_VERSION}"; exit 1; }
RUN pip install --upgrade pip \
&& pip install --no-cache-dir apache-beam[gcp]==2.29.0 \
# Verify that there are no conflicting dependencies.
&& pip check
# Copy the Apache Beam worker dependencies from the Beam Python 3.6 SDK image.
COPY --from=apache/beam_python3.6_sdk:2.29.0 /opt/apache/beam /opt/apache/beam
# Apache Beam worker expects pip at /usr/local/bin/pip by default.
# Some images have pip in a different location. If necessary, make a symlink.
# This line can be omitted in Beam 2.30.0 and later versions.
RUN [[ `which pip` == "/usr/local/bin/pip" ]] || ln -s `which pip` /usr/local/bin/pip
# Set the entrypoint to Apache Beam SDK worker launcher.
ENTRYPOINT [ "/opt/apache/beam/boot" ]
כשמשתמשים בקובצי אימג' של TensorFlow Docker, צריך להשתמש ב-TensorFlow 2.5.0 ואילך. בתמונות Docker קודמות של TensorFlow, חבילת tensorflow-gpu מותקנת במקום חבילת tensorflow. ההבחנה הזו לא חשובה אחרי שגרסה TensorFlow 2.1.0 יצאה, אבל כמה חבילות בהמשך, כמו tfx, דורשות את חבילת tensorflow.
גודל גדול של מאגרים מאט את זמן ההפעלה של העובד. השינוי הזה בביצועים יכול לקרות כשמשתמשים בקונטיינרים כמו Deep Learning Containers.
התקנה של גרסת Python ספציפית
אם יש לכם דרישות מחמירות לגבי גרסת Python, אתם יכולים ליצור את התמונה שלכם מתמונת בסיס של NVIDIA שיש בה את ספריות ה-GPU הנדרשות. לאחר מכן, מתקינים את רכיב התרגום של Python.
בדוגמה הבאה מוסבר איך בוחרים קובץ אימג' של NVIDIA שלא כולל את רכיב התרגום של Python מתוך קטלוג קובצי האימג' של CUDA. משנים את הדוגמה כדי להתקין את הגרסה הנדרשת של Python 3 ו-pip. בדוגמה הזו נעשה שימוש ב-TensorFlow. לכן, כשבוחרים תמונה, גרסאות CUDA ו-cuDNN בתמונת הבסיס עומדות בדרישות לגרסת TensorFlow.
דוגמה לקובץ Dockerfile:
# Select an NVIDIA base image with needed GPU stack from https://ngc.nvidia.com/catalog/containers/nvidia:cuda
FROM nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04
RUN \
# Add Deadsnakes repository that has a variety of Python packages for Ubuntu.
# See: https://launchpad.net/~deadsnakes/+archive/ubuntu/ppa
apt-key adv --keyserver keyserver.ubuntu.com --recv-keys F23C5A6CF475977595C89F51BA6932366A755776 \
&& echo "deb http://ppa.launchpad.net/deadsnakes/ppa/ubuntu focal main" >> /etc/apt/sources.list.d/custom.list \
&& echo "deb-src http://ppa.launchpad.net/deadsnakes/ppa/ubuntu focal main" >> /etc/apt/sources.list.d/custom.list \
&& apt-get update \
&& apt-get install -y curl \
python3.8 \
# With python3.8 package, distutils need to be installed separately.
python3-distutils \
&& rm -rf /var/lib/apt/lists/* \
&& update-alternatives --install /usr/bin/python python /usr/bin/python3.8 10 \
&& curl https://bootstrap.pypa.io/get-pip.py | python \
&& pip install --upgrade pip \
# Install Apache Beam and Python packages that will interact with GPUs.
&& pip install --no-cache-dir apache-beam[gcp]==2.29.0 tensorflow==2.4.0 \
# Verify that there are no conflicting dependencies.
&& pip check
# Copy the Apache Beam worker dependencies from the Beam Python 3.8 SDK image.
COPY --from=apache/beam_python3.8_sdk:2.29.0 /opt/apache/beam /opt/apache/beam
# Set the entrypoint to Apache Beam SDK worker launcher.
ENTRYPOINT [ "/opt/apache/beam/boot" ]
במערכות הפעלה מסוימות, יכול להיות שיהיה קשה להתקין גרסאות ספציפיות של Python באמצעות מנהל החבילות של מערכת ההפעלה. במקרה כזה, צריך להתקין את מתורגמן Python באמצעות כלים כמו Miniconda או pyenv.
דוגמה לקובץ Dockerfile:
FROM nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04
# The Python version of the Dockerfile must match the Python version you use
# to launch the Dataflow job.
ARG PYTHON_VERSION=3.8
# Update PATH so we find our new Conda and Python installations.
ENV PATH=/opt/python/bin:/opt/conda/bin:$PATH
RUN apt-get update \
&& apt-get install -y wget \
&& rm -rf /var/lib/apt/lists/* \
# The NVIDIA image doesn't come with Python pre-installed.
# We use Miniconda to install the Python version of our choice.
&& wget -q https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh \
&& bash Miniconda3-latest-Linux-x86_64.sh -b -p /opt/conda \
&& rm Miniconda3-latest-Linux-x86_64.sh \
# Create a new Python environment with needed version, and install pip.
&& conda create -y -p /opt/python python=$PYTHON_VERSION pip \
# Remove unused Conda packages, install necessary Python packages using pip
# to avoid mixing packages from pip and Conda.
&& conda clean -y --all --force-pkgs-dirs \
&& pip install --upgrade pip \
# Install Apache Beam and Python packages that will interact with GPUs.
&& pip install --no-cache-dir apache-beam[gcp]==2.29.0 tensorflow==2.4.0 \
# Verify that there are no conflicting dependencies.
&& pip check \
# Apache Beam worker expects pip at /usr/local/bin/pip by default.
# You can omit this line when using Beam 2.30.0 and later versions.
&& ln -s $(which pip) /usr/local/bin/pip
# Copy the Apache Beam worker dependencies from the Apache Beam SDK for Python 3.8 image.
COPY --from=apache/beam_python3.8_sdk:2.29.0 /opt/apache/beam /opt/apache/beam
# Set the entrypoint to Apache Beam SDK worker launcher.
ENTRYPOINT [ "/opt/apache/beam/boot" ]
שימוש בקובץ אימג' של קונטיינר Apache Beam
אתם יכולים להגדיר קובץ אימג' בקונטיינר לשימוש ב-GPU בלי להשתמש בקובצי אימג' שהוגדרו מראש. הגישה הזו מומלצת רק אם תמונות שהוגדרו מראש לא מתאימות לכם. כדי להגדיר קובץ אימג' משלכם בקונטיינר, צריך לבחור ספריות תואמות ולהגדיר את סביבת ההפעלה שלהן.
דוגמה לקובץ Dockerfile:
FROM apache/beam_python3.7_sdk:2.24.0
ENV INSTALLER_DIR="/tmp/installer_dir"
# The base image has TensorFlow 2.2.0, which requires CUDA 10.1 and cuDNN 7.6.
# You can download cuDNN from NVIDIA website
# https://developer.nvidia.com/cudnn
COPY cudnn-10.1-linux-x64-v7.6.0.64.tgz $INSTALLER_DIR/cudnn.tgz
RUN \
# Download CUDA toolkit.
wget -q -O $INSTALLER_DIR/cuda.run https://developer.download.nvidia.com/compute/cuda/10.1/Prod/local_installers/cuda_10.1.243_418.87.00_linux.run && \
# Install CUDA toolkit. Print logs upon failure.
sh $INSTALLER_DIR/cuda.run --toolkit --silent || (egrep '^\[ERROR\]' /var/log/cuda-installer.log && exit 1) && \
# Install cuDNN.
mkdir $INSTALLER_DIR/cudnn && \
tar xvfz $INSTALLER_DIR/cudnn.tgz -C $INSTALLER_DIR/cudnn && \
cp $INSTALLER_DIR/cudnn/cuda/include/cudnn*.h /usr/local/cuda/include && \
cp $INSTALLER_DIR/cudnn/cuda/lib64/libcudnn* /usr/local/cuda/lib64 && \
chmod a+r /usr/local/cuda/include/cudnn*.h /usr/local/cuda/lib64/libcudnn* && \
rm -rf $INSTALLER_DIR
# A volume with GPU drivers will be mounted at runtime at /usr/local/nvidia.
ENV LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/nvidia/lib64:/usr/local/cuda/lib64
ספריות של מנהלי התקנים ב-/usr/local/nvidia/lib64 צריכות להיות ניתנות לגילוי במאגר כספריות משותפות. כדי לאפשר לספריות של מנהלי ההתקנים להתגלות, צריך להגדיר את משתנה הסביבה LD_LIBRARY_PATH.
אם אתם משתמשים ב-TensorFlow, אתם צריכים לבחור שילוב תואם של גרסאות CUDA Toolkit ו-cuDNN. מידע נוסף זמין במאמרים בנושא דרישות התוכנה ותצורות build שנבדקו.
בחירה של סוג ומספר יחידות ה-GPU לעובדי Dataflow
כדי להגדיר את הסוג והמספר של יחידות ה-GPU שיוצמדו לעובדי Dataflow, משתמשים באפשרות השירות worker_accelerator.
בוחרים את הסוג והמספר של יחידות ה-GPU בהתאם לתרחיש השימוש ולאופן שבו מתכננים להשתמש ביחידות ה-GPU בצינור העיבוד.
רשימה של סוגי GPU שנתמכים ב-Dataflow זמינה במאמר תמיכה ב-GPU ב-Dataflow.
הרצת המשימה עם מעבדי GPU
השיקולים להרצת משימת Dataflow עם מעבדי GPU כוללים את הדברים הבאים:
קונטיינרים של GPU הם בדרך כלל גדולים, ולכן כדי למנוע מצב של חוסר מקום בדיסק, צריך לבצע את הפעולות הבאות:
- להגדיל את גודל דיסק האתחול שמוגדר כברירת מחדל ל-50 גיגה-בייט או יותר.
כדאי לחשוב על מספר התהליכים שמשתמשים בו-זמנית באותו GPU במכונה וירטואלית של worker. אחר כך מחליטים אם רוצים להגביל את ה-GPU לתהליך יחיד או לאפשר לכמה תהליכים להשתמש ב-GPU.
- אם תהליך אחד של Apache Beam SDK יכול להשתמש ברוב הזיכרון הזמין של ה-GPU, למשל על ידי טעינת מודל גדול ל-GPU, כדאי להגדיר את העובדים כך שישתמשו בתהליך יחיד על ידי הגדרת אפשרות הצינור
--experiments=no_use_multiple_sdk_containers. אפשרות אחרת היא להשתמש בתהליכי worker עם vCPU אחד באמצעות סוג מכונה בהתאמה אישית, כמוn1-custom-1-NUMBER_OF_MBאוn1-custom-1-NUMBER_OF_MB-ext, לזיכרון מורחב. מידע נוסף זמין במאמר שימוש בסוג מכונה עם יותר זיכרון לכל vCPU. - אם ה-GPU משותף לכמה תהליכים, צריך להפעיל עיבוד מקביל ב-GPU משותף באמצעות NVIDIA Multi-Processing Service (MPS).
מידע נוסף זמין במאמר GPUs and worker parallelism.
- אם תהליך אחד של Apache Beam SDK יכול להשתמש ברוב הזיכרון הזמין של ה-GPU, למשל על ידי טעינת מודל גדול ל-GPU, כדאי להגדיר את העובדים כך שישתמשו בתהליך יחיד על ידי הגדרת אפשרות הצינור
כדי להריץ משימת Dataflow עם מעבדי GPU, משתמשים בפקודה הבאה.
כדי להשתמש בהתאמה נכונה, במקום להשתמש באפשרות השירות worker_accelerator, משתמשים ברמז למשאב accelerator.
Python
python PIPELINE \
--runner="DataflowRunner" \
--project="PROJECT" \
--temp_location="gs://BUCKET/tmp" \
--region="REGION" \
--worker_harness_container_image="IMAGE" \
--disk_size_gb="DISK_SIZE_GB" \
--dataflow_service_options="worker_accelerator=type:GPU_TYPE;count:GPU_COUNT;install-nvidia-driver" \
--experiments="use_runner_v2"
מחליפים את מה שכתוב בשדות הבאים:
- PIPELINE: קובץ קוד המקור של צינור הנתונים
- PROJECT: שם הפרויקט Google Cloud
- BUCKET: הקטגוריה של Cloud Storage
- REGION: אזור Dataflow, לדוגמה,
us-central1. בוחרים `REGION` שיש בו אזורים שתומכים ב-GPU_TYPE. Dataflow מקצה באופן אוטומטי עובדים לאזור עם יחידות GPU באזור הזה. - IMAGE: הנתיב ב-Artifact Registry לקובץ האימג' של Docker
- DISK_SIZE_GB: הגודל של דיסק האתחול של כל מכונת VM של Worker, לדוגמה,
50 - GPU_TYPE: סוג GPU זמין, לדוגמה,
nvidia-tesla-t4. - GPU_COUNT: מספר יחידות ה-GPU לצירוף לכל מכונה וירטואלית של Worker, לדוגמה,
1
אימות של משימת Dataflow
כדי לוודא שהעבודה משתמשת במכונות וירטואליות של עובדים עם מעבדי GPU, פועלים לפי השלבים הבאים:
- מוודאים שעובדי Dataflow של המשימה התחילו לפעול.
- בזמן שהעבודה פועלת, מאתרים מכונת VM של Worker שמשויכת לעבודה.
- בהנחיה חיפוש מוצרים ומשאבים, מדביקים את מזהה המשימה.
- בוחרים את מכונת ה-VM ב-Compute Engine שמשויכת לעבודה.
אפשר גם למצוא רשימה של כל המופעים הפועלים במסוף Compute Engine.
נכנסים לדף VM instances במסוף Google Cloud .
לוחצים על פרטים של מופע VM.
מוודאים שבדף הפרטים יש קטע GPUs ושכרטיסי ה-GPU מצורפים.
אם העבודה לא הופעלה עם GPU, צריך לוודא שאפשרות השירות worker_accelerator מוגדרת כראוי ומוצגת בממשק המעקב של Dataflow ב-dataflow_service_options. הסדר של הטוקנים במטא-נתונים של התוסף חשוב.
לדוגמה, אפשרות לצינור עיבוד נתונים dataflow_service_options בממשק המעקב של Dataflow יכולה להיראות כך:
['worker_accelerator=type:nvidia-tesla-t4;count:1;install-nvidia-driver', ...]
צפייה בניצול ה-GPU
כדי לראות את השימוש ב-GPU במכונות הווירטואליות של העובדים, פועלים לפי השלבים הבאים:
במסוף Google Cloud , עוברים אל Monitoring או לוחצים על הלחצן הבא:
בחלונית הניווט של Monitoring, לוחצים על Metrics Explorer.
בשדה Resource Type, מציינים
Dataflow Job. במדד, מצייניםGPU utilizationאוGPU memory utilization, בהתאם למדד שרוצים לעקוב אחריו.
מידע נוסף זמין במאמר Metrics Explorer.
הפעלת שירות ריבוי המשימות של NVIDIA
בצינורות Python שפועלים על עובדים עם יותר מ-vCPU אחד, אפשר לשפר את המקביליות של פעולות GPU על ידי הפעלת NVIDIA Multi-Process Service (MPS). מידע נוסף ושלבים לשימוש ב-MPS זמינים במאמר שיפור הביצועים ב-GPU משותף באמצעות NVIDIA MPS.
אופציונלי: הגדרת מודל הקצאת הרשאות
כדי לשפר את היכולת לקבל גישה למשאבי GPU, אפשר להגדיר מודל הקצאת משאבים לצינור.
Dataflow תומך במודלים הבאים של הקצאת הרשאות: standard ו-flex-start.
הקצאת הרשאות רגילה
הקצאת משאבים רגילה היא מודל ברירת המחדל להקצאת משאבים לכל משימות Dataflow עם מעבדי GPU. מופעים שמשתמשים במשאבי האצה נוצרים באופן מיידי על סמך זמינות המשאבים.
לא צריך להגדיר שום דבר כדי להשתמש במודל ההקצאה הרגיל.
אם יחידות GPU לא זמינות באופן מיידי באזור או באזור שבו אתם מריצים את עבודת Dataflow, יכול להיות שהעבודה לא תתחיל. מידע נוסף מופיע במאמר בנושא העבודה נכשלת באופן מיידי בהפעלה.
Flex-start provisioning
במודל הקצאת המשאבים עם התחלה גמישה, המערכת מתזמנת את הקצאת המשאבים של המאיצים והאינסטנסים ומבצעת אותה על סמך זמינות המשאבים. אתם יכולים להשתמש במודל ההקצאה של flex-start כדי להגדיל את הסיכויים שלכם לקבל מעבדי GPU.
כדי להשתמש במודל הקצאת ההרשאות עם תחילת שימוש גמישה, מוסיפים provisioning_model:FLEX_START לאפשרות השירות worker_accelerator. לדוגמה:
worker_accelerator=type:nvidia-tesla-t4;count:1;install-nvidia-driver:latest;provisioning_model:FLEX_START
מגישים להרצה משימות שהופעלה בהן האפשרות 'התחלה גמישה', אבל הן מורצות רק כשהמשאבים הנדרשים הופכים לזמינים. כדי לוודא שהקצאת ההרשאות עם גמישות בתחילת התקופה הופעלה, מחפשים ביומן job-message את רשומת היומן הבאה:
האפשרות FLEX_START מופעלת למשימה JOB_ID
כדי לבדוק אם העבודה התחילה להתבצע, אפשר להציג את תרשים ההתאמה האוטומטית של קנה המידה בדף מדדי העבודה:
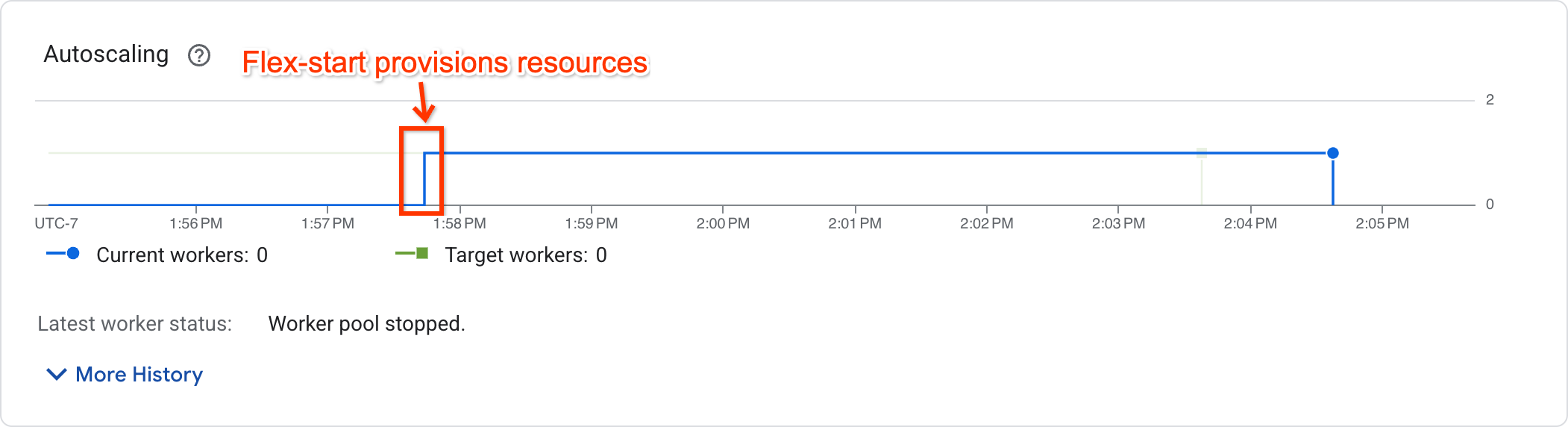
במשרות שהתחילו את ההרצה יוצג מספר worker שגדול מאפס, ואילו במשרות שממתינות למשאבים יוצג מספר worker ששווה לאפס.
תמיכה ומגבלות
- התחלה גמישה נתמכת רק בצינורות Batch. אין תמיכה בצינורות סטרימינג.
- למכונות וירטואליות של Worker שהוקצו באמצעות מודל ההקצאה flex-start יש זמן ריצה מקסימלי של שבעה ימים. אחרי התקופה הזו, מכונות וירטואליות של Worker עם מאיצים נדחקות. מערכת Dataflow תנסה להקצות מחדש משאבים. אם אי אפשר להקצות מחדש משאבים, הצינור ייכשל.
- התכונה 'התחלה גמישה' תנסה להקצות משאבים למשך שעה לכל היותר אחרי שליחת העבודה. אם לא ניתן להקצות משאבים אחרי שעה, העבודה תיכשל.
- הפעלת מכונות עם תשלום לפי שימוש צורכת את המכסה שניתנת להפעלת מכונות שניתנות להפסקת פעולה. אם בפרויקט שלכם אין מכסת משאבים שניתנים להפסקה, המערכת תשתמש במכסה הרגילה. מידע נוסף מופיע במאמר בנושא מכסות של מכונות שאפשר להפסיק את הפעולה שלהן.
- אם לא מספקים הגדרה של אזור עובד, Dataflow יבחר אזור יחיד ליצירת כל המשאבים על סמך תמיכה בחומרה, זמינות נוכחית של משאבים ומכסות, והתאמה לשריונים. יכול להיות שאזור הזמן הזה יהיה שונה מאזור הזמן שבו נמצאים משאבי השירות של העבודה.
- אין תמיכה בשינוי גודל אוטומטי אופקי. כדי להשתמש ביותר מעובד אחד, מגדירים את
--num_workerspipeline option. - אין תמיכה ב-TPU.
- אין תמיכה ב-Right fitting.
פתרון בעיות ב-Flex-start
אם המשימה נכשלת שעה אחרי השליחה עם השגיאה:
The Dataflow job appears to be stuck because no worker activity has been seen in the last 1h.
נכנסים לדף Quotas במסוף Google Cloud כדי לוודא שלפרויקט יש מכסת PREEMPTIBLE_GPU_TYPE_GPUS מספיקה באזור שהוגדר לעבודה.
אם הייתה מכסה מספקת בפרויקט, המשמעות היא שלא הייתה אפשרות להקצות משאבים תוך שעה באמצעות flex-start. כדאי להפעיל את צינור העיבוד באזור אחר או עם סוג אחר של מאיץ.
שימוש במעבדי GPU עם Dataflow Prime
בעזרת Dataflow Prime אפשר לבקש מאיצים לשלב ספציפי בצינור עיבוד הנתונים. כדי להשתמש ב-GPU עם Dataflow Prime, לא משתמשים באפשרות --dataflow-service_options=worker_accelerator של צינור העברת הנתונים. במקום זאת, צריך לבקש את יחידות ה-GPU באמצעות רמז המשאב accelerator.
מידע נוסף מפורט במאמר בנושא שימוש ברמזים למשאבים.
פתרון בעיות במשימת Dataflow
אם נתקלתם בבעיות בהרצת משימת Dataflow עם יחידות GPU, תוכלו להיעזר במאמר פתרון בעיות במשימת Dataflow GPU.
המאמרים הבאים
- מידע נוסף על תמיכה ב-GPU ב-Dataflow
- מריצים את צינור עיבוד הנתונים של למידת מכונה עם סוג ה-GPU NVIDIA L4.
- פועלים לפי ההוראות במאמר עיבוד תמונות לוויין של Landsat באמצעות מעבדי GPU.