
Neste tutorial, mostramos como usar o plug-in do Cloud Data Fusion para o Cloud DLP para editar dados sensíveis.
Cenário
Considere o cenário a seguir, em que algumas informações sensíveis do cliente precisam ser editadas:
Sua equipe de suporte documenta os detalhes de cada caso de suporte processado em um tíquete de suporte. Todas as informações nos tíquetes de suporte são extraídas para um arquivo CSV. Os técnicos de suporte não devem documentar informações de clientes consideradas confidenciais, mas às vezes fazem isso por engano. Você percebe que os números de telefone de alguns clientes são exibidos no arquivo CSV.
Você quer analisar o arquivo CSV e ocultar todos os números de telefone. Você cria um pipeline do Cloud Data Fusion que edita os dados do cliente confidenciais usando o plug-in do Cloud DLP.
Neste tutorial, você criará um pipeline que faz o seguinte:
- Encobre os números de telefone dos clientes mascarando-os com o caractere
#. - Armazena os dados sensíveis mascarados e os não sensíveis em um bucket do Cloud Storage.
Objetivos
- Conectar o Cloud Data Fusion a uma origem do Cloud Storage.
- Implantar o plug-in do Cloud DLP.
- Criar um modelo personalizado do Cloud DLP.
- usar o plug-in de transformação Redact para mascarar dados confidenciais de clientes;
- Gravar os dados de saída no Cloud Storage.
Custos
Neste documento, você vai usar os seguintes componentes faturáveis do Google Cloud:
Para gerar uma estimativa de custo baseada na projeção de uso deste tutorial, use a calculadora de preços.
Antes de começar
- Faça login na sua conta do Google Cloud . Se você começou a usar o Google Cloud, crie uma conta para avaliar o desempenho de nossos produtos em situações reais. Clientes novos também recebem US$ 300 em créditos para executar, testar e implantar cargas de trabalho.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Ative as APIs Cloud Data Fusion, BigQuery, Cloud Storage e Dataproc.
Funções necessárias para ativar APIs
Para ativar APIs, você precisa da permissão
serviceusage.services.enable. Se você criou o projeto, provavelmente já tem essa permissão com o papel de Proprietário (roles/owner). Caso contrário, é possível receber essa permissão com o papel de Administrador do Service Usage (roles/serviceusage.serviceUsageAdmin). Saiba como conceder papéis.- Crie uma instância do Cloud Data Fusion.
Receber permissões do Cloud DLP
No console Google Cloud , acesse a página do IAM.
Na tabela de permissões, na coluna Membro, encontre a conta de serviço que corresponde ao formato
service-project-number@gcp-sa-datafusion.iam.gserviceaccount.com.
Clique em edit Editar.
Clique em Adicionar outro papel.
Use a barra de pesquisa para encontrar e selecionar a opção Administrador do DLP.
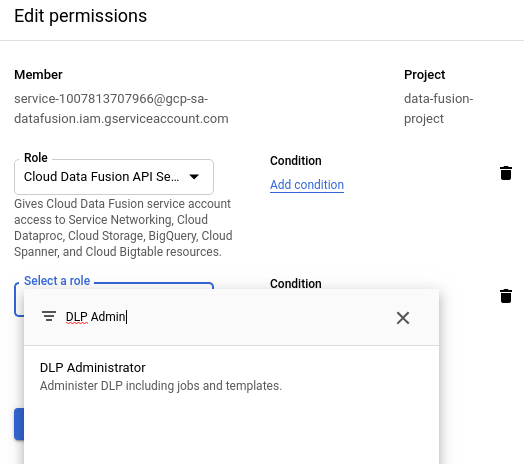
Clique em Save.
Verifique se o Administrador do DLP aparece na coluna Papel.

Navegar até a IU do Cloud Data Fusion
Ao usar o Cloud Data Fusion, você usa o console Google Cloud e a interface separada do Cloud Data Fusion. No console do Google Cloud , é possível criar um projeto do console do Google Cloud e criar e excluir instâncias do Cloud Data Fusion. Na interface do Cloud Data Fusion, é possível usar as várias páginas, como o Studio ou o Wrangler, para acessar os recursos.
No console do Google Cloud , abra a página Instâncias.
Na coluna Ações da instância, clique no link Visualizar instância. A IU do Cloud Data Fusion será aberta em uma nova guia do navegador.
Criar o pipeline
Crie um pipeline que edija dados confidenciais do cliente. O pipeline que você cria faz o seguinte:
- Lê os dados de entrada usando o plug-in de origem do Cloud Storage.
- Implanta o plug-in do Cloud DLP no Hub.
- Grava os dados de saída usando um plug-in de coletor do Cloud Storage.
Carregar os dados do cliente
Neste tutorial, usamos o conjunto de dados de entrada, CallCenterRecords.csv, fornecido em um bucket do Cloud Storage disponível publicamente.
Abra sua instância do Cloud Data Fusion e clique em menu Menu > Studio.
No menu Origem, clique no plug-in Cloud Storage.
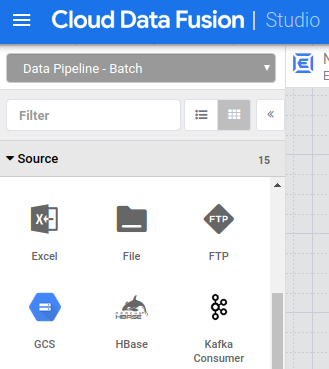
No nó Cloud Storage, clique em Propriedades.
No campo Nome de referência, insira um nome.
No campo Caminho, digite
gs://datafusion-sample-datasets/CallCenterRecords.csv.No campo Formato, selecione
CSV.Para o Esquema de saída, exclua os campos offset e body. Clique em Adicionar e insira os seguintes campos:
- Data
- Banco
- Estado
- CEP
- Observações
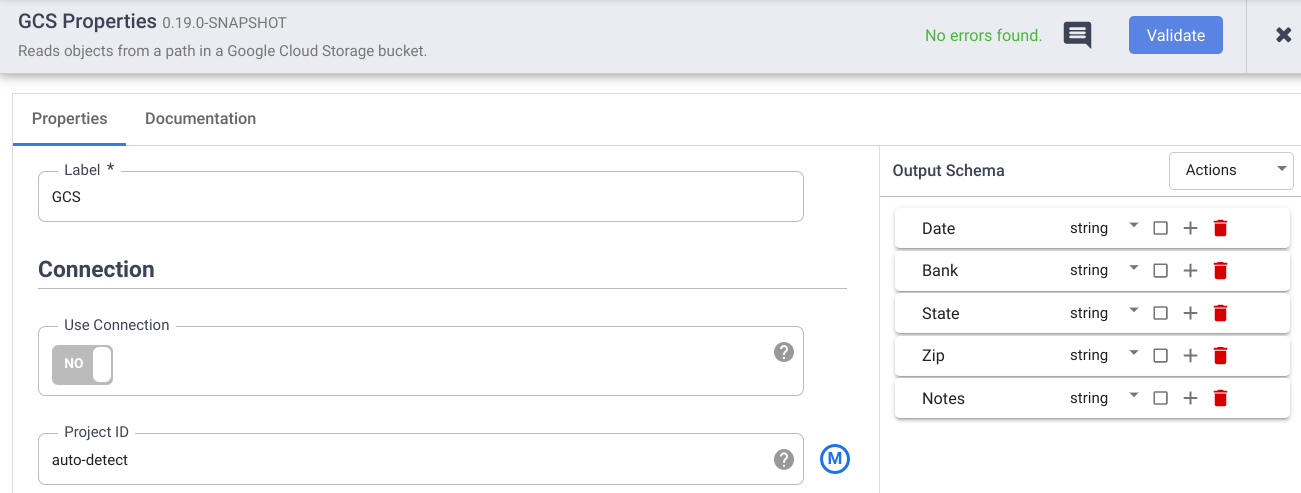
Clique em Validar para verificar se há erros.
Clique em Fechar.
encobrir dados sensíveis
O plug-in Redact do Cloud DLP identifica registros sensíveis no fluxo de entrada de dados e aplica transformações definidas a esses registros. Um registro de dados é considerado sensível se corresponder a filtros predefinidos do Cloud DLP escolhidos ou a um modelo personalizado definido por você.
Neste tutorial, você quer editar os números de telefone dos clientes que alguns técnicos de suporte da sua equipe anotaram acidentalmente. Eles inseriram as informações confidenciais na seção Observações dos tíquetes de suporte, que aparece como a coluna Observações no arquivo CSV. Crie um modelo personalizado do Cloud DLP e forneça o ID do modelo no menu de propriedades do plug-in.
Implantar o plug-in do Cloud DLP
Na sua instância do Cloud Data Fusion, clique em Hub.
Clique no plug-in Cloud DLP.
Clique em Implantar.
Clique em Concluir.
Clique em Fechar para sair da caixa de diálogo do Cloud DLP.
Clique em Fechar para sair do Hub.
Criar um modelo personalizado
No console Google Cloud , acesse a página do Cloud DLP.
No menu Criar, escolha Modelo.
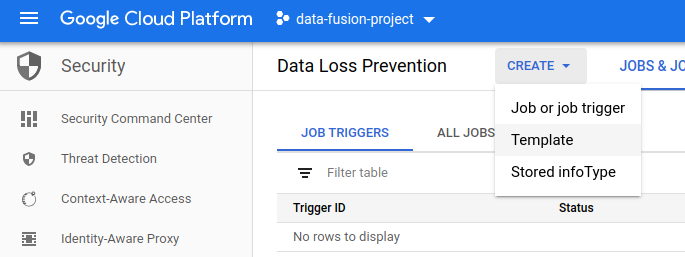
No campo ID do modelo, insira um ID para o modelo.
Clique em Continuar.
No campo Configurar detecção, clique em Gerenciar infotipos.
Na guia Incorporado, use o filtro para pesquisar "número de telefone".
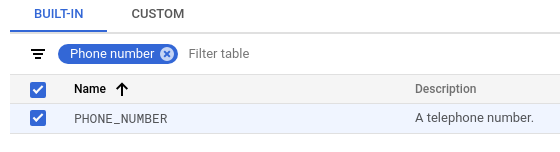
Selecione PHONE_NUMBER.
Clique em Concluído > Criar.
Saiba mais sobre como criar modelos do Cloud DLP.
Aplicar a transformação de edição do Cloud DLP
Acesse a página Studio do Cloud Data Fusion e clique para expandir o menu Transformar.
Clique no plug-in Redact do Cloud DLP.

Arraste uma seta de conexão do nó Cloud Storage para o nó Editar.

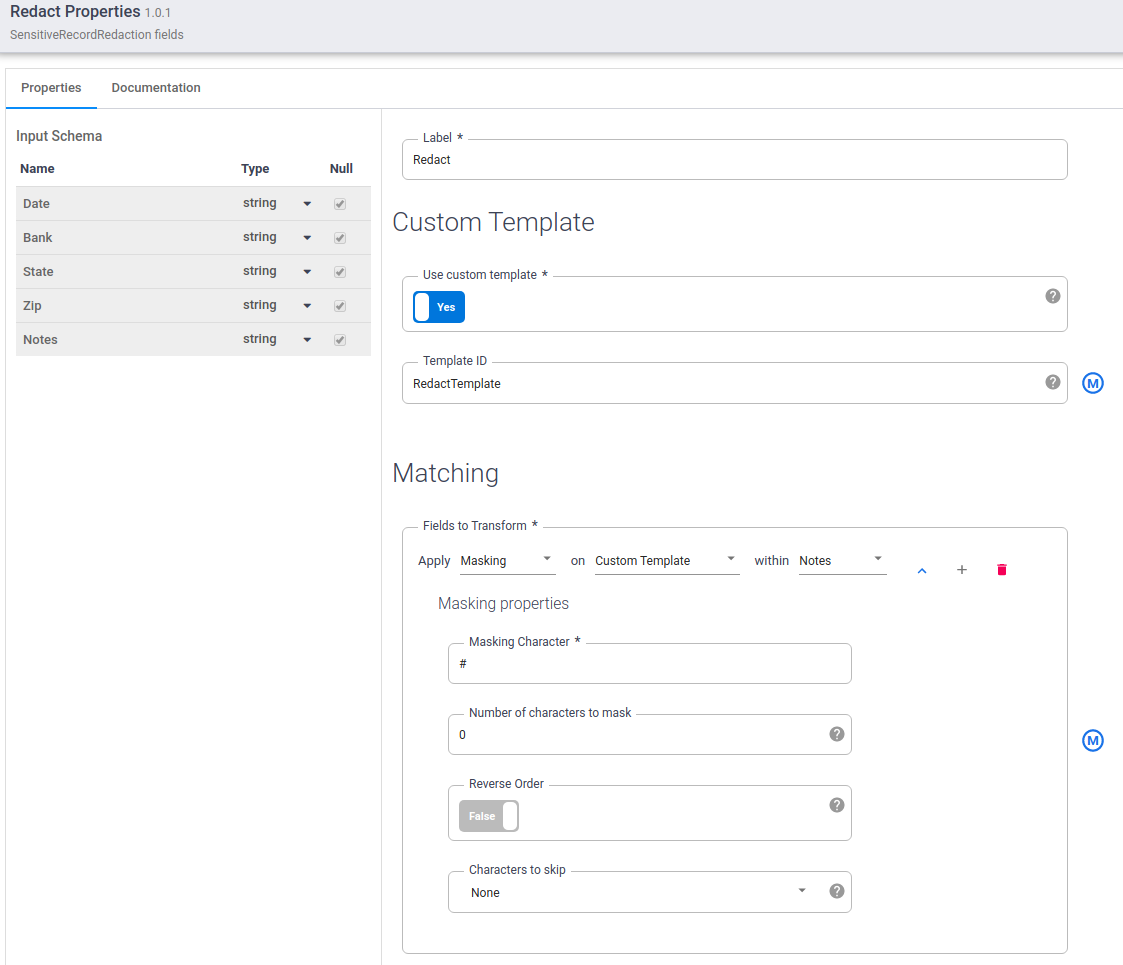
Mantenha o ponteiro sobre o nó Editar e clique em Propriedades.
Defina Modelo personalizado como
Yes.No campo ID do modelo, insira o ID do modelo personalizado que você criou.
No campo Correspondência , aplique Mascaramento em Modelo personalizado em Observações.
No campo Caractere de mascaramento, insira
#.
Clique em Validar para verificar se há erros.
Clique em Fechar.
Armazenar os dados de saída
Armazene os resultados do pipeline em um arquivo do Cloud Storage.
Na página Studio, clique para expandir o menu Coletor.
Clique em Cloud Storage.
Arraste uma seta de conexão do nó Editar para o nó Cloud Storage2.

Mantenha o ponteiro sobre o nó Cloud Storage2 e clique em Propriedades.
No campo Nome de referência, insira um nome.
No campo Caminho, insira o caminho de um bucket do Cloud Storage em que você quer armazenar os resultados do pipeline. O Cloud Data Fusion cria o bucket para você. Siga as diretrizes de nomenclatura de bucket.
No campo Formato, selecione CSV.
Clique em Validar para verificar se há erros.
Clique em Fechar.
Executar o pipeline no modo de visualização
Execute o pipeline no modo de visualização antes de implantá-lo.
Clique em Visualizar e em Executar.

Ao clicar em Executar, o status do pipeline é exibido. Ele começa com Iniciando, depois muda para Interromper e, por fim, para Executar.
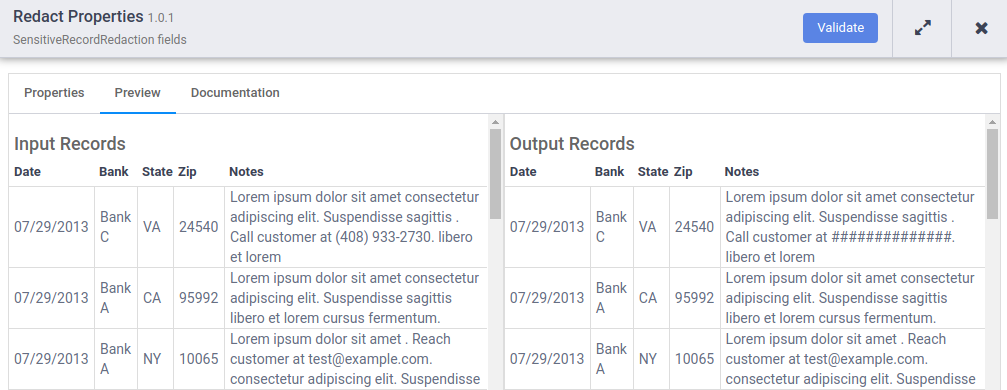
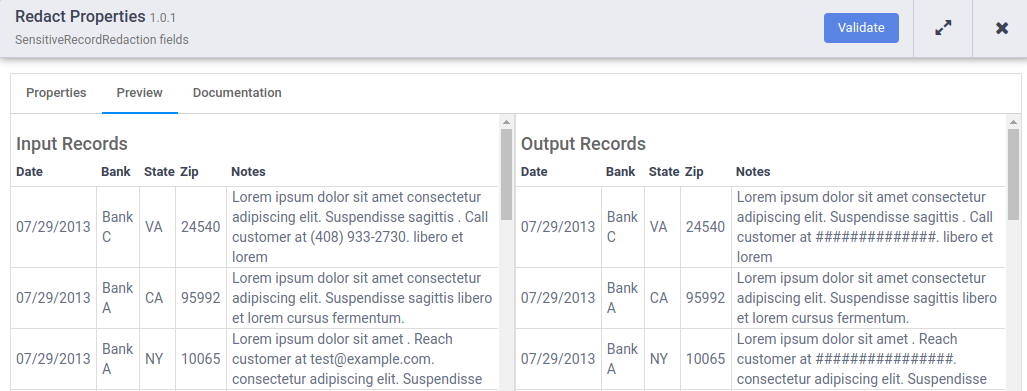
Quando a execução da visualização for concluída, no nó Editar, clique em Visualizar dados para ver uma comparação lado a lado dos dados de entrada e saída. Verifique se os números de telefone foram mascarados com o caractere
#.
Editar outro tipo de dado
Ao examinar os resultados da execução da visualização, você percebe que ainda há informações confidenciais que aparecem na coluna Observações: endereços de e-mail. Você também edita o modelo do Cloud DLP para editar endereços de e-mail.
No console Google Cloud , acesse a página do Cloud DLP.
Na guia Configuração, selecione seu modelo.
Clique em Editar.
Clique em Gerenciar infotipos.
Na guia Incorporado, use o filtro para pesquisar "OU" "endereço de e-mail".
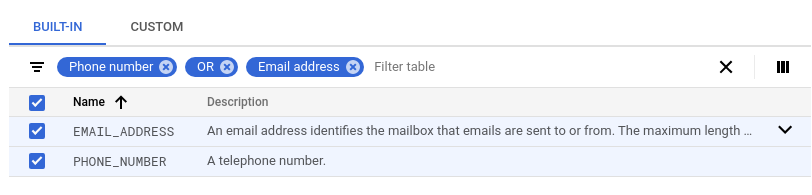
Selecione tudo e clique em Concluído.
Clique em Save.
Mais uma vez, execute o pipeline no modo de visualização. O Cloud Data Fusion usará automaticamente o modelo atualizado do Cloud DLP.
Verifique se os números de telefone e os endereços de e-mail foram mascarados com o caractere
#.
Implantar e executar o pipeline
Verifique se o modo Visualizar está desmarcado.
Clique em Salvar. Ao clicar em Salvar, será solicitado que você nomeie o pipeline. Em seguida, clique em OK.
Clique em Implantar.
Quando a implantação for concluída, clique em Executar. A execução do pipeline pode levar alguns minutos. Enquanto espera, observe o Status do pipeline mudar de Provisionando para Iniciando para Em execução para Desprovisionando para Concluído.
Ver os resultados
No console Google Cloud , acesse a página do Cloud Storage.
No navegador do Storage, navegue até o bucket do Cloud Storage do coletor especificado nas propriedades do plug-in do Cloud Storage do coletor.
Em URL do link, clique no link para fazer o download do arquivo CSV com os resultados. Verifique se os números de telefone e endereços de e-mail foram mascarados com o caractere
#.
Limpar
Para evitar cobranças na sua conta do Google Cloud pelos recursos usados no tutorial, exclua o projeto que os contém ou mantenha o projeto e exclua os recursos individuais.
Excluir a instância do Cloud Data Fusion
Siga estas instruções para excluir a instância do Cloud Data Fusion.
Exclua o projeto
O jeito mais fácil de evitar cobranças é excluindo o projeto que você criou para o tutorial.
Para excluir o projeto:
- No console Google Cloud , acesse a página Gerenciar recursos.
- Na lista de projetos, selecione o projeto que você quer excluir e clique em Excluir .
- Na caixa de diálogo, digite o ID do projeto e clique em Encerrar para excluí-lo.
A seguir
- Saiba mais sobre o Cloud Data Fusion.
- Veja como usar o plug-in do Cloud Data Fusion, que fornece os plug-ins de transformação Redact e Filter PII.