
Untuk meningkatkan performa di pipeline data, Anda dapat mendorong beberapa operasi transformasi ke BigQuery, bukan Apache Spark. Percepatan Transformasi mengacu pada setelan yang memungkinkan operasi di pipeline data Cloud Data Fusion didorong ke BigQuery sebagai mesin eksekusi. Akibatnya, operasi dan datanya ditransfer ke BigQuery dan operasi dilakukan di sana.
Pengoptimalan Transformasi meningkatkan performa pipeline yang memiliki
beberapa operasi
JOIN yang kompleks
atau transformasi lain yang didukung. Mengeksekusi beberapa transformasi di BigQuery mungkin lebih cepat daripada mengeksekusinya di Spark.
Transformasi yang tidak didukung dan semua transformasi pratinjau dijalankan di Spark.
Transformasi yang didukung
Percepatan Transformasi tersedia di Cloud Data Fusion versi 6.5.0 dan yang lebih baru, tetapi beberapa transformasi berikut hanya didukung di versi yang lebih baru.
Operasi JOIN
Percepatan Transformasi tersedia untuk operasi
JOINdi Cloud Data Fusion versi 6.5.0 dan yang lebih baru.Operasi
JOINdasar (pada tombol) dan lanjutan didukung.Gabungan harus memiliki tepat dua tahap input agar eksekusi dapat dilakukan di BigQuery.
Penggabungan yang dikonfigurasi untuk memuat satu atau beberapa input ke dalam memori dijalankan di Spark, bukan di BigQuery, kecuali dalam kasus berikut:
- Jika salah satu input untuk gabungan sudah didorong ke bawah.
- Jika Anda mengonfigurasi gabungan agar dieksekusi di SQL Engine (lihat opsi Tahapan untuk memaksakan eksekusi).
Sink BigQuery
Pushdown Transformasi tersedia untuk Sink BigQuery di Cloud Data Fusion versi 6.7.0 dan yang lebih baru.
Saat Sink BigQuery mengikuti tahap yang telah dieksekusi di BigQuery, operasi yang menuliskan data ke BigQuery dilakukan langsung di BigQuery.
Untuk meningkatkan performa dengan sink ini, Anda memerlukan hal berikut:
- Akun layanan harus memiliki izin untuk membuat dan memperbarui tabel dalam set data yang digunakan oleh BigQuery Sink.
- Set data yang digunakan untuk Pengoptimalan Pushdown dan Sink BigQuery harus disimpan di lokasi yang sama.
- Operasi harus berupa salah satu dari berikut ini:
Insert(opsiTruncate Tabletidak didukung)UpdateUpsert
GROUP BY agregasi
Percepatan Transformasi tersedia untuk agregasi GROUP BY di
Cloud Data Fusion versi 6.7.0 dan yang lebih baru.
Agregasi GROUP BY di BigQuery tersedia untuk operasi berikut:
AvgCollect List(nilai null dihapus dari array output)Collect Set(nilai null dihapus dari array output)ConcatConcat DistinctCountCount DistinctCount NullsLogical AndLogical OrMaxMinStandard DeviationSumSum of SquaresCorrected Sum of SquaresVarianceShortest StringLongest String
Agregasi GROUP BY dieksekusi di BigQuery dalam kasus berikut:
- Mengikuti tahap yang sudah diturunkan.
- Anda mengonfigurasinya agar dieksekusi di SQL Engine (lihat opsi Stages to force execution).
Menghapus duplikat agregasi
Pengoptimalan Transformasi tersedia untuk agregasi penghapusan duplikat di Cloud Data Fusion versi 6.7.0 dan yang lebih baru untuk operasi berikut:
- Tidak ada operasi filter yang ditentukan
ANY(nilai non-null untuk kolom yang diinginkan)MIN(nilai minimum untuk kolom yang ditentukan)MAX(nilai maksimum untuk kolom yang ditentukan)
Operasi berikut tidak didukung:
FIRSTLAST
Agregasi penghapusan duplikat dijalankan di mesin SQL dalam kasus berikut:
- Mengikuti tahap yang sudah diturunkan.
- Anda mengonfigurasinya agar dieksekusi di SQL Engine (lihat opsi Tahapan untuk memaksakan eksekusi).
Pengoptimalan Sumber BigQuery
Pushdown Sumber BigQuery tersedia di Cloud Data Fusion versi 6.8.0 dan yang lebih baru.
Jika Sumber BigQuery mengikuti tahap yang kompatibel untuk pengoptimalan BigQuery, pipeline dapat menjalankan semua tahap yang kompatibel dalam BigQuery.
Cloud Data Fusion menyalin rekaman yang diperlukan untuk menjalankan pipeline dalam BigQuery.
Saat Anda menggunakan BigQuery Source Pushdown, properti partisi dan pengelompokan tabel dipertahankan, sehingga Anda dapat menggunakan properti ini untuk mengoptimalkan operasi lebih lanjut, seperti gabungan.
Persyaratan tambahan
Untuk menggunakan BigQuery Source Pushdown, persyaratan berikut harus dipenuhi:
Akun layanan yang dikonfigurasi untuk BigQuery Transformation Pushdown harus memiliki izin untuk membaca tabel di set data BigQuery Source.
Set Data yang digunakan di Sumber BigQuery dan set data yang dikonfigurasi untuk Pengoptimalan Transformasi harus disimpan di lokasi yang sama.
Agregasi jendela
Percepatan Transformasi tersedia untuk agregasi Window di Cloud Data Fusion versi 6.9 dan yang lebih baru. Agregasi jendela di BigQuery didukung untuk operasi berikut:
RankDense RankPercent RankN tileRow NumberMedianContinuous PercentileLeadLagFirstLastCumulative distributionAccumulate
Agregasi jendela dieksekusi di BigQuery dalam kasus berikut:
- Mengikuti tahap yang sudah diturunkan.
- Anda mengonfigurasinya agar dieksekusi di SQL Engine (lihat opsi Tahapan untuk memaksa pushdown).
Pengurangan Filter Wrangler
Pengoptimalan Filter Wrangler tersedia di Cloud Data Fusion versi 6.9 dan yang lebih baru.
Saat menggunakan plugin Wrangler, Anda dapat mengirimkan filter, yang dikenal sebagai operasi Precondition, untuk dieksekusi di BigQuery, bukan Spark.
Filter pushdown hanya didukung dengan mode SQL untuk Prakondisi, yang juga dirilis di versi 6.9. Dalam mode ini, plugin menerima ekspresi prasyarat dalam SQL standar ANSI.
Jika mode SQL digunakan untuk prasyarat, Petunjuk dan Petunjuk yang Ditentukan Pengguna dinonaktifkan untuk plugin Wrangler, karena tidak didukung dengan prasyarat dalam mode SQL.
Mode SQL untuk prasyarat tidak didukung untuk plugin Wrangler dengan beberapa input saat Pengoptimalan Transformasi diaktifkan. Jika digunakan dengan beberapa input, tahap Wrangler dengan kondisi filter SQL ini dieksekusi di Spark.
Filter dijalankan di BigQuery dalam kasus berikut:
- Mengikuti tahap yang sudah diturunkan.
- Anda mengonfigurasinya agar dieksekusi di SQL Engine (lihat opsi Tahapan untuk memaksa pushdown).
Metrik
Untuk mengetahui informasi selengkapnya tentang metrik yang disediakan Cloud Data Fusion untuk bagian pipeline yang dieksekusi di BigQuery, lihat Metrik pipeline pushdown BigQuery.
Kapan harus menggunakan Transformasi Pushdown
Menjalankan transformasi di BigQuery melibatkan hal berikut:
- Menuliskan data ke BigQuery untuk tahap yang didukung dalam pipeline Anda.
- Mengeksekusi tahap yang didukung di BigQuery.
- Membaca rekaman dari BigQuery setelah transformasi yang didukung dijalankan, kecuali jika diikuti dengan BigQuery Sink.
Bergantung pada ukuran set data, mungkin ada overhead jaringan yang cukup besar, yang dapat berdampak negatif pada waktu eksekusi pipeline secara keseluruhan saat Pengoptimalan Transformasi diaktifkan.
Karena overhead jaringan, sebaiknya lakukan Pendorongan Transformasi dalam kasus berikut:
- Beberapa operasi yang didukung dijalankan secara berurutan (tanpa langkah-langkah di antara tahapan).
- Peningkatan performa dari BigQuery yang menjalankan transformasi, dibandingkan dengan Spark, lebih besar daripada latensi perpindahan data ke dan mungkin keluar dari BigQuery.
Cara kerjanya
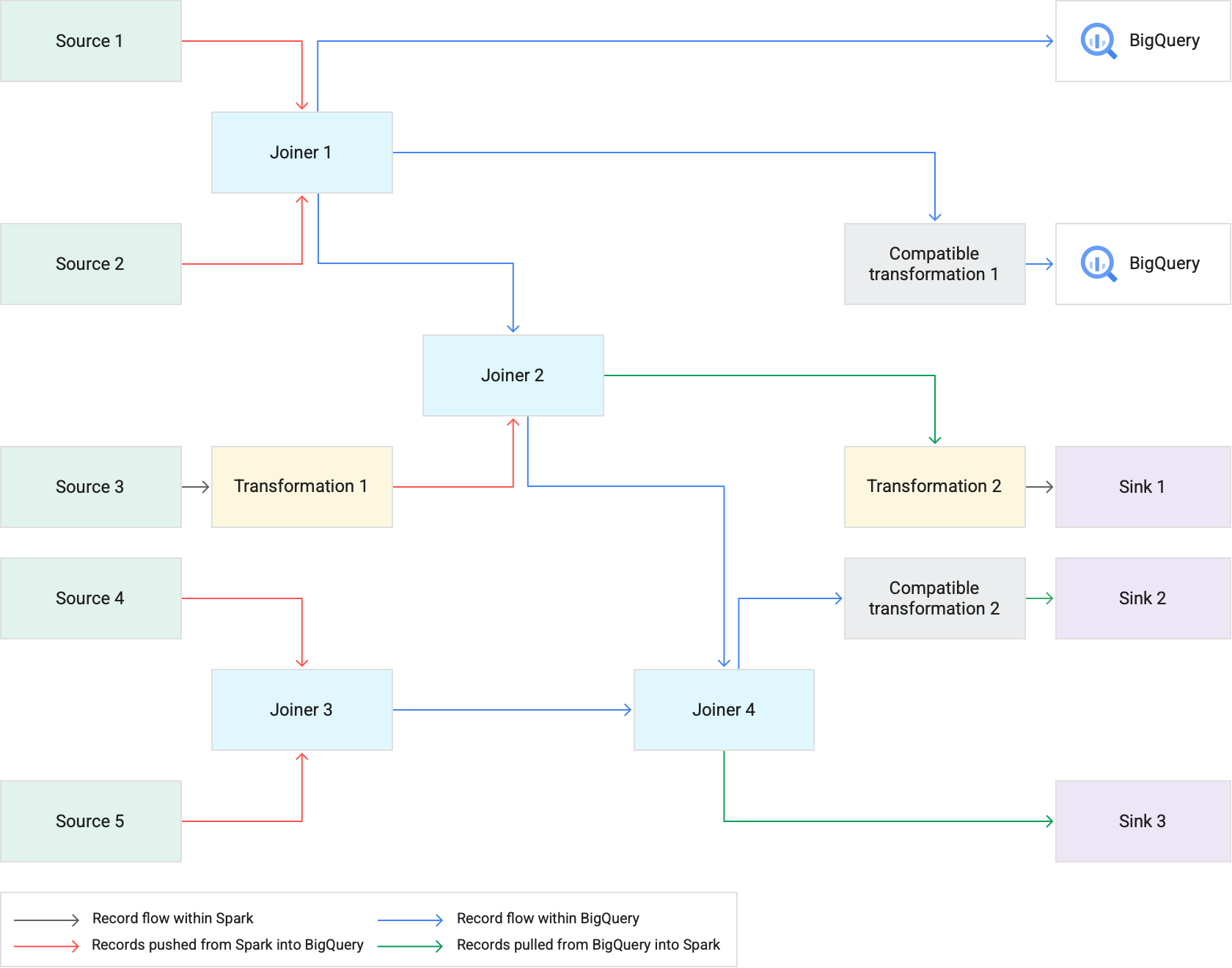
Saat Anda menjalankan pipeline yang menggunakan Pendorongan Transformasi, Cloud Data Fusion akan menjalankan tahap transformasi yang didukung di BigQuery. Semua tahap lainnya dalam pipeline dijalankan di Spark.
Saat menjalankan transformasi:
Cloud Data Fusion memuat set data input ke BigQuery dengan menulis rekaman ke Cloud Storage, lalu menjalankan tugas pemuatan BigQuery.
Operasi
JOINdan transformasi yang didukung kemudian dieksekusi sebagai tugas BigQuery menggunakan pernyataan SQL.Jika pemrosesan lebih lanjut diperlukan setelah tugas dijalankan, kumpulan data dapat diekspor dari BigQuery ke Spark. Namun, jika opsi Coba salin langsung ke sink BigQuery diaktifkan dan Sink BigQuery mengikuti tahap yang dieksekusi di BigQuery, data akan ditulis langsung ke tabel Sink BigQuery tujuan.
Diagram berikut menunjukkan cara Transformation Pushdown menjalankan transformasi yang didukung di BigQuery, bukan Spark.
Praktik terbaik
Menyesuaikan ukuran cluster dan eksekutor
Untuk mengoptimalkan pengelolaan resource di pipeline, lakukan hal berikut:
Gunakan jumlah cluster worker (node) yang tepat untuk workload. Dengan kata lain, manfaatkan cluster Managed Service for Apache Spark yang disediakan secara maksimal dengan menggunakan CPU dan memori yang tersedia sepenuhnya untuk instance Anda, sekaligus mendapatkan manfaat dari kecepatan eksekusi BigQuery untuk tugas berukuran besar.
Tingkatkan paralelisme di pipeline Anda dengan menggunakan cluster penskalaan otomatis.
Sesuaikan konfigurasi resource Anda di tahap pipeline tempat data didorong atau ditarik dari BigQuery selama eksekusi pipeline.
Direkomendasikan: Bereksperimenlah dengan meningkatkan jumlah core CPU untuk resource eksekutor Anda (hingga jumlah core CPU yang digunakan oleh node pekerja Anda). Eksekutor mengoptimalkan penggunaan CPU selama langkah-langkah serialisasi dan deserialisasi saat data masuk dan keluar dari BigQuery. Untuk mengetahui informasi selengkapnya, lihat Penentuan ukuran cluster.
Manfaat menjalankan transformasi di BigQuery adalah pipeline Anda dapat berjalan di cluster Managed Service for Apache Spark yang lebih kecil. Jika penggabungan adalah
operasi yang paling banyak menggunakan resource dalam pipeline, Anda dapat bereksperimen dengan
ukuran cluster yang lebih kecil, karena operasi JOIN yang berat kini dilakukan di
BigQuery), sehingga Anda berpotensi mengurangi biaya
komputasi secara keseluruhan.
Mengambil data lebih cepat dengan BigQuery Storage Read API
Setelah BigQuery mengeksekusi transformasi, pipeline Anda mungkin memiliki tahap tambahan untuk dieksekusi di Spark. Di Cloud Data Fusion versi 6.7.0 dan yang lebih baru, Pengoptimalan Transformasi mendukung BigQuery Storage Read API, yang meningkatkan latensi dan menghasilkan operasi baca yang lebih cepat ke Spark. Hal ini dapat mengurangi waktu eksekusi pipeline secara keseluruhan.
API membaca rekaman secara paralel, jadi sebaiknya sesuaikan ukuran eksekutor dengan tepat. Jika operasi yang menggunakan banyak resource dijalankan di BigQuery, kurangi alokasi memori untuk eksekutor guna meningkatkan paralelisme saat pipeline berjalan (lihat Menyesuaikan ukuran cluster dan eksekutor).
BigQuery Storage Read API dinonaktifkan secara default. Anda dapat mengaktifkannya di lingkungan eksekusi tempat Scala 2.12 diinstal (termasuk Managed Service for Apache Spark 2.0 dan Managed Service for Apache Spark 1.5).
Mempertimbangkan ukuran set data
Pertimbangkan ukuran set data dalam operasi JOIN. Untuk operasi JOIN
yang menghasilkan sejumlah besar rekaman output, seperti
sesuatu yang menyerupai operasi JOIN silang, ukuran set data yang dihasilkan
mungkin lebih besar beberapa kali lipat daripada set data input. Selain itu, pertimbangkan
overhead untuk menarik kembali rekaman ini ke Spark saat pemrosesan Spark
tambahan untuk rekaman ini terjadi, seperti transformasi atau sink, dalam
konteks performa pipeline secara keseluruhan.
Memitigasi data condong
Operasi JOIN untuk data yang sangat miring dapat menyebabkan tugas BigQuery melampaui batas penggunaan resource, sehingga menyebabkan operasi JOIN gagal. Untuk mencegah hal ini, buka setelan plugin Joiner dan identifikasi input miring di kolom Skewed Input Stage. Hal ini memungkinkan Cloud Data Fusion mengatur input sedemikian rupa sehingga mengurangi risiko pernyataan BigQuery melampaui batas.

Langkah berikutnya
- Pelajari cara mengaktifkan Pendorongan Transformasi di Cloud Data Fusion.