
In dieser Anleitung wird beschrieben, wie Sie eine Microsoft SQL Server 2022-Datenbank direkt in einem Cloud Storage-Bucket sichern und später wiederherstellen. Das native SQL Server-Sicherungsfeature wurde in SQL Server 2022 eingeführt und bietet eine nahtlose und kostengünstige Strategie für die cloudbasierte Notfallwiederherstellung und Datenmigration.
Das native SQL Server-Sicherungsfeature nutzt die Befehle BACKUP TO URL und RESTORE FROM URL, die S3-kompatiblen Objektspeicher unterstützen, einschließlich Cloud Storage. Dadurch ist kein lokaler Zwischenspeicher erforderlich, was den Sicherungsworkflow vereinfacht und den Betriebsaufwand reduziert.
Diese Anleitung richtet sich an Datenbankadministratoren und -entwickler.
Ziele
In dieser Anleitung erfahren Sie, wie Sie die folgenden Aufgaben ausführen, um Ihr Ziel zu erreichen:- Neuen Cloud Storage-Bucket erstellen
- SQL Server-Connector konfigurieren
- Datenbank sichern
- Datenbank aus der Sicherung wiederherstellen
Kosten
In diesem Dokument verwenden Sie die folgenden kostenpflichtigen Komponenten von Google Cloud:
Mit dem Preisrechner können Sie eine Kostenschätzung für Ihre voraussichtliche Nutzung vornehmen.
Verwenden Sie den Preisrechner.
Nach Abschluss der in diesem Dokument beschriebenen Aufgaben können Sie weitere Kosten vermeiden, indem Sie die erstellten Ressourcen löschen. Weitere Informationen finden Sie unter Bereinigen.
Hinweis
Für diese Anleitung benötigen Sie ein Google Cloud Projekt. Sie können ein neues Projekt erstellen oder ein vorhandenes Projekt auswählen:
-
Wählen Sie in der Google Cloud Console auf der Seite für die Projektauswahl ein Projekt aus oder erstellen Sie eines. Google Cloud
Rollen, die zum Auswählen oder Erstellen eines Projekts erforderlich sind
- Projekt auswählen: Für die Auswahl eines Projekts ist keine bestimmte IAM-Rolle erforderlich. Sie können jedes Projekt auswählen, für das Ihnen eine Rolle zugewiesen wurde.
-
Projekt erstellen: Zum Erstellen eines Projekts benötigen Sie die Rolle „Projektersteller“
(
roles/resourcemanager.projectCreator), die dieresourcemanager.projects.createBerechtigung enthält. Informationen zum Zuweisen von Rollen.
-
Prüfen Sie, ob für Ihr Google Cloud Projekt die Abrechnung aktiviert ist.
-
Aktivieren Sie Cloud Shell in der Google Cloud Console.
-
Prüfen Sie, ob Microsoft SQL Server 2022 oder höher installiert ist und ausgeführt wird.
Achten Sie darauf, dass sowohl Ihr Google Cloud-Projekt als auch SQL Server die erforderlichen Berechtigungen zum Ausführen von Sicherungs- und Wiederherstellungsaufgaben haben.
Achten Sie darauf, dass der Nutzer oder das Dienstkonto, das mit Zugriffsschlüsseln verknüpft ist, Berechtigungen zum Erstellen und Aufrufen von Objekten im Cloud Storage-Bucket hat.
Achten Sie darauf, dass das SQL Server-Nutzerkonto, das zum Ausführen der Sicherung verwendet wird, die Berechtigungen „Datenbank sichern“ und „Protokoll sichern“ hat.
Cloud Storage-Bucket erstellen
Sie können einen Cloud Storage-Bucket erstellen über die Google Cloud Console oder mit dem gcloud storage Befehl.
So erstellen Sie einen Cloud Storage-Bucket mit
dem gcloud storage Befehl:
Wählen Sie Ihr Google Cloud Projekt aus.
gcloud config set project PROJECT_ID
Erstellen Sie den Bucket. Führen Sie dazu den Befehl
gcloud storage buckets createwie folgt aus:gcloud storage buckets create gs://BUCKET_NAME --location=BUCKET_LOCATION
Ersetzen Sie Folgendes:
BUCKET_NAME: durch einen eindeutigen Namen für Ihren Bucket.BUCKET_LOCATION: durch den Standort Ihres Buckets.
S3-Interoperabilität konfigurieren und Zugriffsschlüssel erstellen
Damit SQL Server über das S3-Protokoll mit Cloud Storage kommunizieren kann, müssen Sie die Interoperabilität aktivieren und einen Zugriffsschlüssel generieren. Gehen Sie dazu so vor:
Rufen Sie in der Google Cloud Console die Cloud Storage-Einstellungen auf.
Wählen Sie den Tab Interoperabilität aus.
Klicken Sie unter Zugriffsschlüssel für Ihr Nutzerkonto auf Schlüssel erstellen.
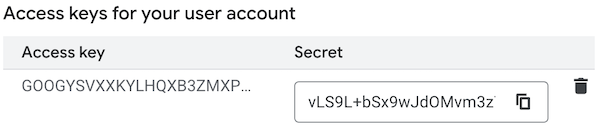
Speichern Sie den generierten Zugriffsschlüssel und das Secret sicher. Sie benötigen sie im nächsten Schritt.
Für Produktionsumgebungen empfehlen wir die Verwendung eines Dienstkonto-HMAC-Schlüssels (HMAC), um die Sicherheit und Verwaltung zu verbessern.
Anmeldedaten zu SQL Server hinzufügen
Damit sich SQL Server bei Ihrem Cloud Storage-Bucket authentifizieren kann, müssen Sie in SQL Server ein Anmeldedatenobjekt erstellen, in dem der Cloud Storage-Zugriffsschlüssel und das Secret gespeichert werden. Führen Sie dazu den folgenden T-SQL-Befehl in SQL Server Management Studio (SSMS) aus:
CREATE CREDENTIAL CREDENTIAL_NAME
WITH
IDENTITY = 'S3 Access Key',
SECRET = 'ACCESS_KEY:SECRET';
Ersetzen Sie Folgendes:
CREDENTIAL_NAME: durch einen Namen für Ihre Anmeldedaten.ACCESS_KEY: durch den Zugriffsschlüssel, den Sie im vorherigen Abschnitt erstellt haben.SECRET: durch das Secret, das Sie im vorherigen Abschnitt erstellt haben.
IDENTITY = 'S3 Access Key' ist wichtig, da SQL Server angewiesen wird, den neuen S3-Connector zu verwenden. Das Secret sollte wie der Zugriffsschlüssel formatiert sein, gefolgt von einem Doppelpunkt und dann dem geheimen Schlüssel.
Beispiel:
CREATE CREDENTIAL sql_backup_credentials
WITH
IDENTITY = 'S3 Access Key',
SECRET = 'GOOGGE3SVF7OQE5JRMLQ7KWB:b31Pl8Tx1ARJfdGOsbgMFQNbk3nPdlT2UCYzs1iC';
Daten in Cloud Storage sichern
Nachdem Sie die Anmeldedaten eingerichtet haben, können Sie Ihre Datenbank mit dem Befehl BACKUP DATABASE und der Option TO URL direkt im Cloud Storage-Bucket sichern. Setzen Sie der URL das Präfix s3://storage.googleapis.com voran, um den S3-Connector zu verwenden.
BACKUP DATABASE DATABASE_NAME
TO URL = 's3://storage.googleapis.com/BUCKET_NAME/FOLDER_NAME/BACKUP_FILE_NAME.bak'
WITH
CREDENTIAL = 'CREDENTIAL_NAME',
FORMAT,
STATS = 10,
MAXTRANSFERSIZE = 10485760,
COMPRESSION;
Ersetzen Sie Folgendes:
CREDENTIAL_NAME: Der Name der Anmeldedaten, die Sie in Schritt 3 erstellt haben. Beispiel:sql_backup_credentials.BUCKET_NAME: Der Name des Buckets, den Sie in Schritt 1 erstellt haben.FOLDER_NAME: Der Name des Ordners, in dem Sie die Sicherungsdatei speichern möchten.BACKUP_FILE_NAME: Der Name der Sicherungsdatei.
Die Beschreibungen der in diesem Befehl verwendeten Sicherungsparameter sind wie folgt:
FORMAT: Überschreibt die vorhandenen Sicherungsdateien und erstellt einen neuen Mediensatz.STATS: Meldet den Fortschritt der Sicherung.COMPRESSION: Komprimiert die Sicherung, wodurch die Dateigröße und die Uploadzeit reduziert werden können.MAXTRANSFERSIZE: Empfohlen, um E/A-Fehler bei großen Sicherungsdateien zu vermeiden.
Weitere Informationen finden Sie unter SQL Server-Sicherung in einer URL für S3-kompatiblen Objektspeicher.
Bei sehr großen Datenbanken können Sie die Sicherung wie folgt in mehrere Dateien aufteilen.
BACKUP DATABASE DATABASE_NAME
TO
URL = 's3://storage.googleapis.com/BUCKET_NAME/FOLDER_NAME/BACKUP_FILE_NAME_0.bak',
URL = 's3://storage.googleapis.com/BUCKET_NAME/FOLDER_NAME/BACKUP_FILE_NAME_1.bak'
-- ... more files
WITH
CREDENTIAL = 'CREDENTIAL_NAME',
FORMAT,
STATS = 10,
MAXTRANSFERSIZE = 10485760,
COMPRESSION;
Daten aus Cloud Storage wiederherstellen
Sie können Ihre Datenbank mit dem Befehl RESTORE DATABASE wie folgt direkt aus einer in Cloud Storage gespeicherten Sicherungsdatei wiederherstellen.
RESTORE DATABASE DATABASE_NAME
FROM URL = 's3://storage.googleapis.com/BUCKET_NAME/FOLDER_NAME/BACKUP_FILE_NAME.bak'
WITH
CREDENTIAL = 'CREDENTIAL_NAME';
Ersetzen Sie Folgendes:
CREDENTIAL_NAME: Der Name der Anmeldedaten, die Sie in Schritt 3 erstellt haben. Beispiel:sql_backup_credentials.BUCKET_NAME: Der Name des Buckets, den Sie in Schritt 1 erstellt haben.FOLDER_NAME: Der Name des Ordners, in dem Sie die Sicherungsdatei speichern möchten.BACKUP_FILE_NAME: Der Name der Sicherungsdatei.
Bereinigen
So vermeiden Sie, dass Ihrem Google Cloud Konto die in dieser Anleitung verwendeten Ressourcen in Rechnung gestellt werden:
Projekt löschen
- Wechseln Sie in der Google Cloud Console zur Seite Ressourcen verwalten.
- Wählen Sie in der Projektliste das Projekt aus, das Sie löschen möchten, und klicken Sie dann auf Löschen.
- Geben Sie im Dialogfeld die Projekt-ID ein und klicken Sie auf Shut down (Beenden), um das Projekt zu löschen.
Nächste Schritte
- Referenzarchitekturen, Diagramme und Best Practices zu Google Cloud kennenlernen. Weitere Informationen zu Cloud Architecture Center