
本教程将逐步为您介绍使用分布式复制块设备 (DRBD) 和 Compute Engine 将 MySQL 5.6 数据库部署到Google Cloud 的过程。DRBD 是适用于 Linux 平台的分布式复制存储系统。
如果您是系统管理员、开发者、工程师、数据库管理员或 DevOps 工程师,那么本教程非常适合您。出于多方面的原因,您可能希望自行管理 MySQL 实例,而不是使用托管式服务,此类原因包括:
- 您正在使用 MySQL 的跨地区实例。
- 您需要设置在代管版本的 MySQL 中不可用的参数。
- 您希望以代管版本中无法设置的方式优化性能。
DRBD 在块存储设备级层上提供复制功能。这意味着您不必在 MySQL 本身中配置复制,并且可以立即享受 DRBD 的优势 - 例如,支持读取负载均衡和安全连接。
本教程使用以下产品和服务:
虽然本文档提及了 MySQL 集群、DRBD 配置和 Linux 资源管理等高级功能,但您不需要掌握相关高级知识也能使用这些资源。
架构
Pacemaker 是一种集群资源管理器。Corosync 是 Pacemaker 使用的一种集群通信和参与软件包。在本教程中,您要使用 DRBD 将 MySQL 磁盘从主实例复制到备用实例。为了让客户端连接到 MySQL 集群,您还需要部署内部负载均衡器。
您要部署由三个计算实例组成的 Pacemaker 代管式集群。您在分别充当主实例和备用实例的两个实例上安装 MySQL。第三个实例用作仲裁设备。
在集群中,每个节点都会投票选择其认为理想的活跃节点 - 也就是运行 MySQL 的节点。在双节点集群中,只需一次投票即可确定活跃节点。在这种情况下,集群行为可能会导致脑裂 (split-brain) 问题或停机。当两个节点都获得控制权时会发生脑裂问题,因为在双节点场景中只需要一次投票。如果所关停的节点是已经配置为在在连接丢失的情况下始终作为主节点,那么就会发生停机。如果两个节点彼此失去连接,则存在多个集群节点将其视为活跃节点的风险。
添加仲裁设备可以避免出现这种情况。仲裁设备充当仲裁者,其唯一的作用就是投票。这样,在 database1 和 database2 实例无法通信的情况下,这个仲裁设备节点可以与两个实例之一进行通信,并且仍然可以到达多数票决。
下图展示了此处所述的系统架构。

目标
- 创建集群实例。
- 在两个实例上安装 MySQL 和 DRBD。
- 配置 DRBD 复制。
- 在实例上安装 Pacemaker。
- 在实例上配置 Pacemaker 集群。
- 创建实例并将其配置为仲裁设备。
- 测试故障切换。
费用
您可使用价格计算器根据您的预计使用情况来估算费用。
准备工作
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.
在本教程中,除非另有说明,否则您将使用 Cloud Shell 输入命令。
完成本文档中描述的任务后,您可以通过删除所创建的资源来避免继续计费。如需了解详情,请参阅清理。
准备工作
在本部分中,您将设置服务账号、创建环境变量并预留 IP 地址。
为集群实例设置服务账号
打开 Cloud Shell:
创建服务账号:
gcloud iam service-accounts create mysql-instance \ --display-name "mysql-instance"将本教程所需的角色附加到服务账号:
gcloud projects add-iam-policy-binding ${DEVSHELL_PROJECT_ID} \ --member=serviceAccount:mysql-instance@${DEVSHELL_PROJECT_ID}.iam.gserviceaccount.com \ --role=roles/compute.instanceAdmin.v1 gcloud projects add-iam-policy-binding ${DEVSHELL_PROJECT_ID} \ --member=serviceAccount:mysql-instance@${DEVSHELL_PROJECT_ID}.iam.gserviceaccount.com \ --role=roles/compute.viewer gcloud projects add-iam-policy-binding ${DEVSHELL_PROJECT_ID} \ --member=serviceAccount:mysql-instance@${DEVSHELL_PROJECT_ID}.iam.gserviceaccount.com \ --role=roles/iam.serviceAccountUser
创建 Cloud Shell 环境变量
创建一个包含本教程所需环境变量的文件:
cat <<EOF > ~/.mysqldrbdrc # Cluster instance names DATABASE1_INSTANCE_NAME=database1 DATABASE2_INSTANCE_NAME=database2 QUORUM_INSTANCE_NAME=qdevice CLIENT_INSTANCE_NAME=mysql-client # Cluster IP addresses DATABASE1_INSTANCE_IP="10.140.0.2" DATABASE2_INSTANCE_IP="10.140.0.3" QUORUM_INSTANCE_IP="10.140.0.4" ILB_IP="10.140.0.6" # Cluster zones and region DATABASE1_INSTANCE_ZONE="asia-east1-a" DATABASE2_INSTANCE_ZONE="asia-east1-b" QUORUM_INSTANCE_ZONE="asia-east1-c" CLIENT_INSTANCE_ZONE="asia-east1-c" CLUSTER_REGION="asia-east1" EOF在当前会话中加载环境变量,并将 Cloud Shell 设置为日后登录时自动加载这些变量:
source ~/.mysqldrbdrc grep -q -F "source ~/.mysqldrbdrc" ~/.bashrc || echo "source ~/.mysqldrbdrc" >> ~/.bashrc
预留 IP 地址
在 Cloud Shel l中,为三个集群节点中的每个节点预留一个内部 IP 地址:
gcloud compute addresses create ${DATABASE1_INSTANCE_NAME} ${DATABASE2_INSTANCE_NAME} ${QUORUM_INSTANCE_NAME} \ --region=${CLUSTER_REGION} \ --addresses "${DATABASE1_INSTANCE_IP},${DATABASE2_INSTANCE_IP},${QUORUM_INSTANCE_IP}" \ --subnet=default
创建 Compute Engine 实例
在以下步骤中,集群实例使用 Debian 9,客户端实例使用 Ubuntu 16。
在 Cloud Shell 中,在区域
asia-east1-a内创建一个名为database1的 MySQL 实例:gcloud compute instances create ${DATABASE1_INSTANCE_NAME} \ --zone=${DATABASE1_INSTANCE_ZONE} \ --machine-type=n1-standard-2 \ --network-tier=PREMIUM \ --maintenance-policy=MIGRATE \ --image-family=debian-9 \ --image-project=debian-cloud \ --boot-disk-size=50GB \ --boot-disk-type=pd-standard \ --boot-disk-device-name=${DATABASE1_INSTANCE_NAME} \ --create-disk=mode=rw,size=300,type=pd-standard,name=disk-1 \ --private-network-ip=${DATABASE1_INSTANCE_NAME} \ --tags=mysql --service-account=mysql-instance@${DEVSHELL_PROJECT_ID}.iam.gserviceaccount.com \ --scopes="https://www.googleapis.com/auth/compute,https://www.googleapis.com/auth/servicecontrol,https://www.googleapis.com/auth/service.management.readonly" \ --metadata="DATABASE1_INSTANCE_IP=${DATABASE1_INSTANCE_IP},DATABASE2_INSTANCE_IP=${DATABASE2_INSTANCE_IP},DATABASE1_INSTANCE_NAME=${DATABASE1_INSTANCE_NAME},DATABASE2_INSTANCE_NAME=${DATABASE2_INSTANCE_NAME},QUORUM_INSTANCE_NAME=${QUORUM_INSTANCE_NAME},DATABASE1_INSTANCE_ZONE=${DATABASE1_INSTANCE_ZONE},DATABASE2_INSTANCE_ZONE=${DATABASE2_INSTANCE_ZONE}"在区域
asia-east1-b内创建一个名为database2的 MySQL 实例:gcloud compute instances create ${DATABASE2_INSTANCE_NAME} \ --zone=${DATABASE2_INSTANCE_ZONE} \ --machine-type=n1-standard-2 \ --network-tier=PREMIUM \ --maintenance-policy=MIGRATE \ --image-family=debian-9 \ --image-project=debian-cloud \ --boot-disk-size=50GB \ --boot-disk-type=pd-standard \ --boot-disk-device-name=${DATABASE2_INSTANCE_NAME} \ --create-disk=mode=rw,size=300,type=pd-standard,name=disk-2 \ --private-network-ip=${DATABASE2_INSTANCE_NAME} \ --tags=mysql \ --service-account=mysql-instance@${DEVSHELL_PROJECT_ID}.iam.gserviceaccount.com \ --scopes="https://www.googleapis.com/auth/compute,https://www.googleapis.com/auth/servicecontrol,https://www.googleapis.com/auth/service.management.readonly" \ --metadata="DATABASE1_INSTANCE_IP=${DATABASE1_INSTANCE_IP},DATABASE2_INSTANCE_IP=${DATABASE2_INSTANCE_IP},DATABASE1_INSTANCE_NAME=${DATABASE1_INSTANCE_NAME},DATABASE2_INSTANCE_NAME=${DATABASE2_INSTANCE_NAME},QUORUM_INSTANCE_NAME=${QUORUM_INSTANCE_NAME},DATABASE1_INSTANCE_ZONE=${DATABASE1_INSTANCE_ZONE},DATABASE2_INSTANCE_ZONE=${DATABASE2_INSTANCE_ZONE}"在区域
asia-east1-c内创建一个供 Pacemaker 使用的仲裁节点:gcloud compute instances create ${QUORUM_INSTANCE_NAME} \ --zone=${QUORUM_INSTANCE_ZONE} \ --machine-type=n1-standard-1 \ --network-tier=PREMIUM \ --maintenance-policy=MIGRATE \ --image-family=debian-9 \ --image-project=debian-cloud \ --boot-disk-size=10GB \ --boot-disk-type=pd-standard \ --boot-disk-device-name=${QUORUM_INSTANCE_NAME} \ --private-network-ip=${QUORUM_INSTANCE_NAME}创建一个 MySQL 客户端实例:
gcloud compute instances create ${CLIENT_INSTANCE_NAME} \ --image-family=ubuntu-1604-lts \ --image-project=ubuntu-os-cloud \ --tags=mysql-client \ --zone=${CLIENT_INSTANCE_ZONE} \ --boot-disk-size=10GB \ --metadata="ILB_IP=${ILB_IP}"
安装和配置 DRBD
在本部分中,您将在 database1 和 database2 实例上安装和配置 DRBD 程序包,然后启动从 database1 到 database2 的 DRBD 复制。
在 database1 上配置 DRBD
在 Google Cloud 控制台中,前往虚拟机实例页面:
在
database1实例行中,点击 SSH 以连接到实例。创建一个文件,以检索实例元数据并将其存储到环境变量中:
sudo bash -c cat <<EOF > ~/.varsrc DATABASE1_INSTANCE_IP=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/DATABASE1_INSTANCE_IP" -H "Metadata-Flavor: Google") DATABASE2_INSTANCE_IP=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/DATABASE2_INSTANCE_IP" -H "Metadata-Flavor: Google") DATABASE1_INSTANCE_NAME=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/DATABASE1_INSTANCE_NAME" -H "Metadata-Flavor: Google") DATABASE2_INSTANCE_NAME=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/DATABASE2_INSTANCE_NAME" -H "Metadata-Flavor: Google") DATABASE2_INSTANCE_ZONE=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/DATABASE2_INSTANCE_ZONE" -H "Metadata-Flavor: Google") DATABASE1_INSTANCE_ZONE=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/DATABASE1_INSTANCE_ZONE" -H "Metadata-Flavor: Google") QUORUM_INSTANCE_NAME=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/QUORUM_INSTANCE_NAME" -H "Metadata-Flavor: Google") EOF加载文件中的元数据变量:
source ~/.varsrc格式化数据磁盘:
sudo bash -c "mkfs.ext4 -m 0 -F -E \ lazy_itable_init=0,lazy_journal_init=0,discard /dev/sdb"如需详细了解
mkfs.ext4选项,请参阅 mkfs.ext4 联机帮助页。安装 DRBD:
sudo apt -y install drbd8-utils创建 DRBD 配置文件:
sudo bash -c 'cat <<EOF > /etc/drbd.d/global_common.conf global { usage-count no; } common { protocol C; } EOF'创建 DRBD 资源文件:
sudo bash -c "cat <<EOF > /etc/drbd.d/r0.res resource r0 { meta-disk internal; device /dev/drbd0; net { allow-two-primaries no; after-sb-0pri discard-zero-changes; after-sb-1pri discard-secondary; after-sb-2pri disconnect; rr-conflict disconnect; } on database1 { disk /dev/sdb; address 10.140.0.2:7789; } on database2 { disk /dev/sdb; address 10.140.0.3:7789; } } EOF"加载 DRBD 内核模块:
sudo modprobe drbd清除
/dev/sdb磁盘的内容:sudo dd if=/dev/zero of=/dev/sdb bs=1k count=1024创建 DRBD 资源
r0:sudo drbdadm create-md r0启用 DRBD:
sudo drbdadm up r0系统启动时停用 DRBD,让集群资源管理软件按顺序启用所有必要的服务:
sudo update-rc.d drbd disable
在 database2 上配置 DRBD
您现在可以在 database2 实例上安装和配置 DRBD 程序包。
- 通过 SSH 连接到
database2实例。 创建一个
.varsrc文件,以检索实例元数据并将其存储到环境变量中:sudo bash -c cat <<EOF > ~/.varsrc DATABASE1_INSTANCE_IP=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/DATABASE1_INSTANCE_IP" -H "Metadata-Flavor: Google") DATABASE2_INSTANCE_IP=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/DATABASE2_INSTANCE_IP" -H "Metadata-Flavor: Google") DATABASE1_INSTANCE_NAME=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/DATABASE1_INSTANCE_NAME" -H "Metadata-Flavor: Google") DATABASE2_INSTANCE_NAME=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/DATABASE2_INSTANCE_NAME" -H "Metadata-Flavor: Google") DATABASE2_INSTANCE_ZONE=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/DATABASE2_INSTANCE_ZONE" -H "Metadata-Flavor: Google") DATABASE1_INSTANCE_ZONE=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/DATABASE1_INSTANCE_ZONE" -H "Metadata-Flavor: Google") QUORUM_INSTANCE_NAME=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/QUORUM_INSTANCE_NAME" -H "Metadata-Flavor: Google") EOF从文件加载元数据变量:
source ~/.varsrc格式化数据磁盘:
sudo bash -c "mkfs.ext4 -m 0 -F -E lazy_itable_init=0,lazy_journal_init=0,discard /dev/sdb"安装 DRBD 程序包:
sudo apt -y install drbd8-utils创建 DRBD 配置文件:
sudo bash -c 'cat <<EOF > /etc/drbd.d/global_common.conf global { usage-count no; } common { protocol C; } EOF'创建 DRBD 资源文件:
sudo bash -c "cat <<EOF > /etc/drbd.d/r0.res resource r0 { meta-disk internal; device /dev/drbd0; net { allow-two-primaries no; after-sb-0pri discard-zero-changes; after-sb-1pri discard-secondary; after-sb-2pri disconnect; rr-conflict disconnect; } on ${DATABASE1_INSTANCE_NAME} { disk /dev/sdb; address ${DATABASE1_INSTANCE_IP}:7789; } on ${DATABASE2_INSTANCE_NAME} { disk /dev/sdb; address ${DATABASE2_INSTANCE_IP}:7789; } } EOF"加载 DRBD 内核模块:
sudo modprobe drbd清除
/dev/sdb磁盘:sudo dd if=/dev/zero of=/dev/sdb bs=1k count=1024创建 DRBD 资源
r0:sudo drbdadm create-md r0启用 DRBD:
sudo drbdadm up r0系统启动时停用 DRBD,让集群资源管理软件按顺序启用所有必要的服务:
sudo update-rc.d drbd disable
启动从 database1 到 database2 的 DRBD 复制
- 通过 SSH 连接到
database1实例。 覆盖主节点上的所有
r0资源:sudo drbdadm -- --overwrite-data-of-peer primary r0 sudo mkfs.ext4 -m 0 -F -E lazy_itable_init=0,lazy_journal_init=0,discard /dev/drbd0检查 DRBD 的状态:
sudo cat /proc/drbd | grep ============输出类似于以下内容:
[===================>] sync'ed:100.0% (208/307188)M
将
/dev/drbd装载到/srv:sudo mount -o discard,defaults /dev/drbd0 /srv
安装 MySQL 和 Pacemaker
在本部分中,您将在每个实例上安装 MySQL 和 Pacemaker。
在 database1 上安装 MySQL
- 通过 SSH 连接到
database1实例。 使用 MySQL 5.6 软件包定义更新 APT 代码库:
sudo bash -c 'cat <<EOF > /etc/apt/sources.list.d/mysql.list deb http://repo.mysql.com/apt/debian/ stretch mysql-5.6\ndeb-src http://repo.mysql.com/apt/debian/ stretch mysql-5.6 EOF'将 GPG 密钥添加到 APT
repository.srv文件:wget -O /tmp/RPM-GPG-KEY-mysql https://repo.mysql.com/RPM-GPG-KEY-mysql sudo apt-key add /tmp/RPM-GPG-KEY-mysql更新软件包列表:
sudo apt update安装 MySQL 服务器:
sudo apt -y install mysql-server系统提示输入密码时,请输入
DRBDha2。停止 MySQL 服务器:
sudo /etc/init.d/mysql stop创建 MySQL 配置文件:
sudo bash -c 'cat <<EOF > /etc/mysql/mysql.conf.d/my.cnf [mysqld] bind-address = 0.0.0.0 # You may want to listen at localhost at the beginning datadir = /var/lib/mysql tmpdir = /srv/tmp user = mysql EOF'为 MySQL 服务器创建一个临时目录(在
mysql.conf中配置):sudo mkdir /srv/tmp sudo chmod 1777 /srv/tmp将所有 MySQL 数据移动到 DRBD 目录
/srv/mysql下:sudo mv /var/lib/mysql /srv/mysql将
/var/lib/mysql链接到 DRBD 复制存储卷下的/srv/mysql中:sudo ln -s /srv/mysql /var/lib/mysql将
/srv/mysql所有者更改为mysql进程:sudo chown -R mysql:mysql /srv/mysql移除
InnoDB初始数据,尽可能确保磁盘干净:sudo bash -c "cd /srv/mysql && rm ibdata1 && rm ib_logfile*"InnoDB 是 MySQL 数据库管理系统的存储引擎。
启动 MySQL:
sudo /etc/init.d/mysql start为根用户授予远程连接的访问权限,以便稍后测试部署:
mysql -uroot -pDRBDha2 -e "GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'DRBDha2' WITH GRANT OPTION;"停用由集群资源管理模块负责的 MySQL 自动启动:
sudo update-rc.d -f mysql disable
在 database1 上安装 Pacemaker
从先前创建的
.varsrc文件中加载元数据变量:source ~/.varsrc停止 MySQL 服务器:
sudo /etc/init.d/mysql stop安装 Pacemaker:
sudo apt -y install pcs系统启动时在主实例上启用
pcsd、corosync和pacemaker:sudo update-rc.d -f pcsd enable sudo update-rc.d -f corosync enable sudo update-rc.d -f pacemaker enable将
corosync配置为在pacemaker之前启动:sudo update-rc.d corosync defaults 20 20 sudo update-rc.d pacemaker defaults 30 10将集群用户密码设置为
haCLUSTER3,以便进行身份验证:sudo bash -c "echo hacluster:haCLUSTER3 | chpasswd"运行
corosync-keygen脚本以生成 128 位集群授权密钥,并将其写入/etc/corosync/authkey:sudo corosync-keygen -l将
authkey复制到database2实例。当系统提示输入密码时,请按Enter:sudo chmod 444 /etc/corosync/authkey gcloud beta compute scp /etc/corosync/authkey ${DATABASE2_INSTANCE_NAME}:~/authkey --zone=${DATABASE2_INSTANCE_ZONE} --internal-ip sudo chmod 400 /etc/corosync/authkey创建 Corosync 集群配置文件:
sudo bash -c "cat <<EOF > /etc/corosync/corosync.conf totem { version: 2 cluster_name: mysql_cluster transport: udpu interface { ringnumber: 0 Bindnetaddr: ${DATABASE1_INSTANCE_IP} broadcast: yes mcastport: 5405 } } quorum { provider: corosync_votequorum two_node: 1 } nodelist { node { ring0_addr: ${DATABASE1_INSTANCE_NAME} name: ${DATABASE1_INSTANCE_NAME} nodeid: 1 } node { ring0_addr: ${DATABASE2_INSTANCE_NAME} name: ${DATABASE2_INSTANCE_NAME} nodeid: 2 } } logging { to_logfile: yes logfile: /var/log/corosync/corosync.log timestamp: on } EOF"totem部分配置 Totem 协议以实现可靠通信。Corosync 通过此通信控制集群成员资格,并指定集群成员之间的通信方式。设置过程中的重要设置项说明如下:
transport:指定单播模式 (udpu)。Bindnetaddr:指定 Corosync 所绑定到的网络地址。nodelist:定义集群中的节点及其访问方式 - 在本例中是database1和database2节点。quorum/two_node:默认情况下,在双节点集群中,没有任何节点会在仲裁中胜出。您可以通过在quorum部分中为two_node指定“1”值来覆盖这种设置。
此设置允许您配置集群,并使其准备好应对后续您添加第三个节点作为仲裁设备时的情况。
为
corosync创建服务目录:sudo mkdir -p /etc/corosync/service.d对
corosync进行配置,使其知晓 Pacemaker:sudo bash -c 'cat <<EOF > /etc/corosync/service.d/pcmk service { name: pacemaker ver: 1 } EOF'默认启用
corosync服务:sudo bash -c 'cat <<EOF > /etc/default/corosync # Path to corosync.conf COROSYNC_MAIN_CONFIG_FILE=/etc/corosync/corosync.conf # Path to authfile COROSYNC_TOTEM_AUTHKEY_FILE=/etc/corosync/authkey # Enable service by default START=yes EOF'重启
corosync和pacemaker服务:sudo service corosync restart sudo service pacemaker restart安装 Corosync 仲裁设备软件包:
sudo apt -y install corosync-qdevice安装 shell 脚本以处理 DRBD 失败事件:
sudo bash -c 'cat << 'EOF' > /var/lib/pacemaker/drbd_cleanup.sh #!/bin/sh if [ -z \$CRM_alert_version ]; then echo "\$0 must be run by Pacemaker version 1.1.15 or later" exit 0 fi tstamp="\$CRM_alert_timestamp: " case \$CRM_alert_kind in resource) if [ \${CRM_alert_interval} = "0" ]; then CRM_alert_interval="" else CRM_alert_interval=" (\${CRM_alert_interval})" fi if [ \${CRM_alert_target_rc} = "0" ]; then CRM_alert_target_rc="" else CRM_alert_target_rc=" (target: \${CRM_alert_target_rc})" fi case \${CRM_alert_desc} in Cancelled) ;; *) echo "\${tstamp}Resource operation "\${CRM_alert_task}\${CRM_alert_interval}" for "\${CRM_alert_rsc}" on "\${CRM_alert_node}": \${CRM_alert_desc}\${CRM_alert_target_rc}" >> "\${CRM_alert_recipient}" if [ "\${CRM_alert_task}" = "stop" ] && [ "\${CRM_alert_desc}" = "Timed Out" ]; then echo "Executing recovering..." >> "\${CRM_alert_recipient}" pcs resource cleanup \${CRM_alert_rsc} fi ;; esac ;; *) echo "\${tstamp}Unhandled \$CRM_alert_kind alert" >> "\${CRM_alert_recipient}" env | grep CRM_alert >> "\${CRM_alert_recipient}" ;; esac EOF' sudo chmod 0755 /var/lib/pacemaker/drbd_cleanup.sh sudo touch /var/log/pacemaker_drbd_file.log sudo chown hacluster:haclient /var/log/pacemaker_drbd_file.log
在 database2 上安装 MySQL
- 通过 SSH 连接到
database2实例。 使用 MySQL 5.6 软件包更新 APT 代码库:
sudo bash -c 'cat <<EOF > /etc/apt/sources.list.d/mysql.list deb http://repo.mysql.com/apt/debian/ stretch mysql-5.6\ndeb-src http://repo.mysql.com/apt/debian/ stretch mysql-5.6 EOF'将 GPG 密钥添加到 APT 代码库:
wget -O /tmp/RPM-GPG-KEY-mysql https://repo.mysql.com/RPM-GPG-KEY-mysql sudo apt-key add /tmp/RPM-GPG-KEY-mysql更新软件包列表:
sudo apt update安装 MySQL 服务器:
sudo apt -y install mysql-server系统提示输入密码时,请输入
DRBDha2。停止 MySQL 服务器:
sudo /etc/init.d/mysql stop创建 MySQL 配置文件:
sudo bash -c 'cat <<EOF > /etc/mysql/mysql.conf.d/my.cnf [mysqld] bind-address = 0.0.0.0 # You may want to listen at localhost at the beginning datadir = /var/lib/mysql tmpdir = /srv/tmp user = mysql EOF'移除
/var/lib/mysql下的数据,并添加指向复制 DRBD 卷的装载点目标的符号链接。仅在发生故障切换的情况下,DRBD 卷 (/dev/drbd0) 才会装载到/srv处。sudo rm -rf /var/lib/mysql sudo ln -s /srv/mysql /var/lib/mysql停用由集群资源管理模块负责的 MySQL 自动启动:
sudo update-rc.d -f mysql disable
在 database2 上安装 Pacemaker
从
.varsrc文件加载元数据变量:source ~/.varsrc安装 Pacemaker:
sudo apt -y install pcs将您先前复制的 Corosync
authkey文件复制到/etc/corosync/:sudo mv ~/authkey /etc/corosync/ sudo chown root: /etc/corosync/authkey sudo chmod 400 /etc/corosync/authkey系统启动时在备用实例上启用
pcsd、corosync和pacemaker:sudo update-rc.d -f pcsd enable sudo update-rc.d -f corosync enable sudo update-rc.d -f pacemaker enable将
corosync配置为在pacemaker之前启动:sudo update-rc.d corosync defaults 20 20 sudo update-rc.d pacemaker defaults 30 10设置集群用户密码以便进行身份验证。此密码与您用于
database1实例的密码相同 (haCLUSTER3)。sudo bash -c "echo hacluster:haCLUSTER3 | chpasswd"创建
corosync配置文件:sudo bash -c "cat <<EOF > /etc/corosync/corosync.conf totem { version: 2 cluster_name: mysql_cluster transport: udpu interface { ringnumber: 0 Bindnetaddr: ${DATABASE2_INSTANCE_IP} broadcast: yes mcastport: 5405 } } quorum { provider: corosync_votequorum two_node: 1 } nodelist { node { ring0_addr: ${DATABASE1_INSTANCE_NAME} name: ${DATABASE1_INSTANCE_NAME} nodeid: 1 } node { ring0_addr: ${DATABASE2_INSTANCE_NAME} name: ${DATABASE2_INSTANCE_NAME} nodeid: 2 } } logging { to_logfile: yes logfile: /var/log/corosync/corosync.log timestamp: on } EOF"创建 Corosync 服务目录:
sudo mkdir /etc/corosync/service.d对
corosync进行配置,使其知晓 Pacemaker:sudo bash -c 'cat <<EOF > /etc/corosync/service.d/pcmk service { name: pacemaker ver: 1 } EOF'默认启用
corosync服务:sudo bash -c 'cat <<EOF > /etc/default/corosync # Path to corosync.conf COROSYNC_MAIN_CONFIG_FILE=/etc/corosync/corosync.conf # Path to authfile COROSYNC_TOTEM_AUTHKEY_FILE=/etc/corosync/authkey # Enable service by default START=yes EOF'重启
corosync和pacemaker服务:sudo service corosync restart sudo service pacemaker restart安装 Corosync 仲裁设备软件包:
sudo apt -y install corosync-qdevice安装 shell 脚本以处理 DRBD 失败事件:
sudo bash -c 'cat << 'EOF' > /var/lib/pacemaker/drbd_cleanup.sh #!/bin/sh if [ -z \$CRM_alert_version ]; then echo "\$0 must be run by Pacemaker version 1.1.15 or later" exit 0 fi tstamp="\$CRM_alert_timestamp: " case \$CRM_alert_kind in resource) if [ \${CRM_alert_interval} = "0" ]; then CRM_alert_interval="" else CRM_alert_interval=" (\${CRM_alert_interval})" fi if [ \${CRM_alert_target_rc} = "0" ]; then CRM_alert_target_rc="" else CRM_alert_target_rc=" (target: \${CRM_alert_target_rc})" fi case \${CRM_alert_desc} in Cancelled) ;; *) echo "\${tstamp}Resource operation "\${CRM_alert_task}\${CRM_alert_interval}" for "\${CRM_alert_rsc}" on "\${CRM_alert_node}": \${CRM_alert_desc}\${CRM_alert_target_rc}" >> "\${CRM_alert_recipient}" if [ "\${CRM_alert_task}" = "stop" ] && [ "\${CRM_alert_desc}" = "Timed Out" ]; then echo "Executing recovering..." >> "\${CRM_alert_recipient}" pcs resource cleanup \${CRM_alert_rsc} fi ;; esac ;; *) echo "\${tstamp}Unhandled \$CRM_alert_kind alert" >> "\${CRM_alert_recipient}" env | grep CRM_alert >> "\${CRM_alert_recipient}" ;; esac EOF' sudo chmod 0755 /var/lib/pacemaker/drbd_cleanup.sh sudo touch /var/log/pacemaker_drbd_file.log sudo chown hacluster:haclient /var/log/pacemaker_drbd_file.log检查 Corosync 集群状态:
sudo corosync-cmapctl | grep "members...ip"输出类似于以下内容:
runtime.totem.pg.mrp.srp.members.1.ip (str) = r(0) ip(10.140.0.2) runtime.totem.pg.mrp.srp.members.2.ip (str) = r(0) ip(10.140.0.3)
启动集群
- 通过 SSH 连接到
database2实例。 从
.varsrc文件加载元数据变量:source ~/.varsrc针对集群节点进行身份验证:
sudo pcs cluster auth --name mysql_cluster ${DATABASE1_INSTANCE_NAME} ${DATABASE2_INSTANCE_NAME} -u hacluster -p haCLUSTER3启动集群:
sudo pcs cluster start --all验证集群状态:
sudo pcs status输出类似于以下内容:
Cluster name: mysql_cluster WARNING: no stonith devices and stonith-enabled is not false Stack: corosync Current DC: database2 (version 1.1.16-94ff4df) - partition with quorum Last updated: Sat Nov 3 07:24:53 2018 Last change: Sat Nov 3 07:17:17 2018 by hacluster via crmd on database2 2 nodes configured 0 resources configured Online: [ database1 database2 ] No resources Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled
配置 Pacemaker 以管理集群资源
接下来,您需要使用 DRBD、磁盘、MySQL 和仲裁资源配置 Pacemaker。
- 通过 SSH 连接到
database1实例。 使用 Pacemaker
pcs实用程序在一个文件中安排多项更改,可在稍后以原子方式将这些更改推送到集群信息库 (CIB):sudo pcs cluster cib clust_cfg停用 STONITH,因为您稍后将部署仲裁设备:
sudo pcs -f clust_cfg property set stonith-enabled=false停用与仲约相关的设置。稍后您将设置仲裁设备节点。
sudo pcs -f clust_cfg property set no-quorum-policy=stop防止 Pacemaker 在恢复后移回资源:
sudo pcs -f clust_cfg resource defaults resource-stickiness=200在集群中创建 DRBD 资源:
sudo pcs -f clust_cfg resource create mysql_drbd ocf:linbit:drbd \ drbd_resource=r0 \ op monitor role=Master interval=110 timeout=30 \ op monitor role=Slave interval=120 timeout=30 \ op start timeout=120 \ op stop timeout=60确保仅为 DRBD 资源分配了一个主要角色:
sudo pcs -f clust_cfg resource master primary_mysql mysql_drbd \ master-max=1 master-node-max=1 \ clone-max=2 clone-node-max=1 \ notify=true创建文件系统资源,以装载 DRBD 磁盘:
sudo pcs -f clust_cfg resource create mystore_FS Filesystem \ device="/dev/drbd0" \ directory="/srv" \ fstype="ext4"配置集群,以使 DRBD 资源与同一虚拟机上的磁盘资源共置:
sudo pcs -f clust_cfg constraint colocation add mystore_FS with primary_mysql INFINITY with-rsc-role=Master对集群进行配置,使之仅在 DRBD 主节点提升之后启用磁盘资源:
sudo pcs -f clust_cfg constraint order promote primary_mysql then start mystore_FS创建一项 MySQL 服务:
sudo pcs -f clust_cfg resource create mysql_service ocf:heartbeat:mysql \ binary="/usr/bin/mysqld_safe" \ config="/etc/mysql/my.cnf" \ datadir="/var/lib/mysql" \ pid="/var/run/mysqld/mysql.pid" \ socket="/var/run/mysqld/mysql.sock" \ additional_parameters="--bind-address=0.0.0.0" \ op start timeout=60s \ op stop timeout=60s \ op monitor interval=20s timeout=30s配置集群,以使 MySQL 资源与同一虚拟机上的磁盘资源共置:
sudo pcs -f clust_cfg constraint colocation add mysql_service with mystore_FS INFINITY确保 DRBD 文件系统在启动顺序中位于 MySQL 服务之前:
sudo pcs -f clust_cfg constraint order mystore_FS then mysql_service创建提醒代理,并将补丁程序添加到作为其接收方的日志文件中:
sudo pcs -f clust_cfg alert create id=drbd_cleanup_file description="Monitor DRBD events and perform post cleanup" path=/var/lib/pacemaker/drbd_cleanup.sh sudo pcs -f clust_cfg alert recipient add drbd_cleanup_file id=logfile value=/var/log/pacemaker_drbd_file.log将更改提交到集群:
sudo pcs cluster cib-push clust_cfg验证所有资源是否联机:
sudo pcs status输出类似于以下内容:
Online: [ database1 database2 ] Full list of resources: Master/Slave Set: primary_mysql [mysql_drbd] Masters: [ database1 ] Slaves: [ database2 ] mystore_FS (ocf::heartbeat:Filesystem): Started database1 mysql_service (ocf::heartbeat:mysql): Started database1
配置仲裁设备
- 通过 SSH 连接到
qdevice实例。 安装
pcs和corosync-qnetd:sudo apt update && sudo apt -y install pcs corosync-qnetd启动 Pacemaker 或 Corosync 配置系统守护程序 (
pcsd) 服务,并在系统启动时启用该服务:sudo service pcsd start sudo update-rc.d pcsd enable设置集群用户密码 (
haCLUSTER3),以便进行身份验证。sudo bash -c "echo hacluster:haCLUSTER3 | chpasswd"检查仲裁设备状态:
sudo pcs qdevice status net --full输出类似于以下内容:
QNetd address: *:5403 TLS: Supported (client certificate required) Connected clients: 0 Connected clusters: 0 Maximum send/receive size: 32768/32768 bytes
在 database1 上配置仲裁设备设置
- 通过 SSH 连接到
database1节点。 从
.varsrc文件加载元数据变量:source ~/.varsrc验证集群的仲裁设备节点:
sudo pcs cluster auth --name mysql_cluster ${QUORUM_INSTANCE_NAME} -u hacluster -p haCLUSTER3将仲裁设备添加到集群。使用
ffsplit算法,这样可确保根据 50% 或更高投票得票结果认定活跃节点:sudo pcs quorum device add model net host=${QUORUM_INSTANCE_NAME} algorithm=ffsplit将仲裁设置添加到
corosync.conf:sudo bash -c "cat <<EOF > /etc/corosync/corosync.conf totem { version: 2 cluster_name: mysql_cluster transport: udpu interface { ringnumber: 0 Bindnetaddr: ${DATABASE1_INSTANCE_IP} broadcast: yes mcastport: 5405 } } quorum { provider: corosync_votequorum device { votes: 1 model: net net { tls: on host: ${QUORUM_INSTANCE_NAME} algorithm: ffsplit } } } nodelist { node { ring0_addr: ${DATABASE1_INSTANCE_NAME} name: ${DATABASE1_INSTANCE_NAME} nodeid: 1 } node { ring0_addr: ${DATABASE2_INSTANCE_NAME} name: ${DATABASE2_INSTANCE_NAME} nodeid: 2 } } logging { to_logfile: yes logfile: /var/log/corosync/corosync.log timestamp: on } EOF"重启
corosync服务以重新加载新的仲裁设备设置:sudo service corosync restart启动
corosync仲裁设备守护程序,并在系统启动时启用该守护程序:sudo service corosync-qdevice start sudo update-rc.d corosync-qdevice defaults
在 database2 上配置仲裁设备设置
- 通过 SSH 连接到
database2节点。 从
.varsrc文件加载元数据变量:source ~/.varsrc将仲裁设置添加到
corosync.conf:sudo bash -c "cat <<EOF > /etc/corosync/corosync.conf totem { version: 2 cluster_name: mysql_cluster transport: udpu interface { ringnumber: 0 Bindnetaddr: ${DATABASE2_INSTANCE_IP} broadcast: yes mcastport: 5405 } } quorum { provider: corosync_votequorum device { votes: 1 model: net net { tls: on host: ${QUORUM_INSTANCE_NAME} algorithm: ffsplit } } } nodelist { node { ring0_addr: ${DATABASE1_INSTANCE_NAME} name: ${DATABASE1_INSTANCE_NAME} nodeid: 1 } node { ring0_addr: ${DATABASE2_INSTANCE_NAME} name: ${DATABASE2_INSTANCE_NAME} nodeid: 2 } } logging { to_logfile: yes logfile: /var/log/corosync/corosync.log timestamp: on } EOF"重启
corosync服务以重新加载新的仲裁设备设置:sudo service corosync restart启动 Corosync 仲裁设备守护程序,并将其配置为在系统启动时启用:
sudo service corosync-qdevice start sudo update-rc.d corosync-qdevice defaults
验证集群状态
下一步是验证集群资源是否联机。
- 通过 SSH 连接到
database1实例。 验证集群状态:
sudo pcs status输出类似于以下内容:
Cluster name: mysql_cluster Stack: corosync Current DC: database1 (version 1.1.16-94ff4df) - partition with quorum Last updated: Sun Nov 4 01:49:18 2018 Last change: Sat Nov 3 15:48:21 2018 by root via cibadmin on database1 2 nodes configured 4 resources configured Online: [ database1 database2 ] Full list of resources: Master/Slave Set: primary_mysql [mysql_drbd] Masters: [ database1 ] Slaves: [ database2 ] mystore_FS (ocf::heartbeat:Filesystem): Started database1 mysql_service (ocf::heartbeat:mysql): Started database1 Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled显示仲裁状态:
sudo pcs quorum status输出类似于以下内容:
Quorum information ------------------ Date: Sun Nov 4 01:48:25 2018 Quorum provider: corosync_votequorum Nodes: 2 Node ID: 1 Ring ID: 1/24 Quorate: Yes Votequorum information ---------------------- Expected votes: 3 Highest expected: 3 Total votes: 3 Quorum: 2 Flags: Quorate Qdevice Membership information ---------------------- Nodeid Votes Qdevice Name 1 1 A,V,NMW database1 (local) 2 1 A,V,NMW database2 0 1 Qdevice显示仲裁设备状态:
sudo pcs quorum device status输出类似于以下内容:
Qdevice information ------------------- Model: Net Node ID: 1 Configured node list: 0 Node ID = 1 1 Node ID = 2 Membership node list: 1, 2 Qdevice-net information ---------------------- Cluster name: mysql_cluster QNetd host: qdevice:5403 Algorithm: Fifty-Fifty split Tie-breaker: Node with lowest node ID State: Connected
将内部负载均衡器配置为集群 IP
打开 Cloud Shell:
创建一个非代管实例组,并将
database1实例添加到其中:gcloud compute instance-groups unmanaged create ${DATABASE1_INSTANCE_NAME}-instance-group \ --zone=${DATABASE1_INSTANCE_ZONE} \ --description="${DATABASE1_INSTANCE_NAME} unmanaged instance group" gcloud compute instance-groups unmanaged add-instances ${DATABASE1_INSTANCE_NAME}-instance-group \ --zone=${DATABASE1_INSTANCE_ZONE} \ --instances=${DATABASE1_INSTANCE_NAME}创建一个非代管实例组,并将
database2实例添加到其中:gcloud compute instance-groups unmanaged create ${DATABASE2_INSTANCE_NAME}-instance-group \ --zone=${DATABASE2_INSTANCE_ZONE} \ --description="${DATABASE2_INSTANCE_NAME} unmanaged instance group" gcloud compute instance-groups unmanaged add-instances ${DATABASE2_INSTANCE_NAME}-instance-group \ --zone=${DATABASE2_INSTANCE_ZONE} \ --instances=${DATABASE2_INSTANCE_NAME}为
port 3306创建健康检查:gcloud compute health-checks create tcp mysql-backend-healthcheck \ --port 3306创建地区内部后端服务:
gcloud compute backend-services create mysql-ilb \ --load-balancing-scheme internal \ --region ${CLUSTER_REGION} \ --health-checks mysql-backend-healthcheck \ --protocol tcp将两个实例组作为后端添加到该后端服务:
gcloud compute backend-services add-backend mysql-ilb \ --instance-group ${DATABASE1_INSTANCE_NAME}-instance-group \ --instance-group-zone ${DATABASE1_INSTANCE_ZONE} \ --region ${CLUSTER_REGION} gcloud compute backend-services add-backend mysql-ilb \ --instance-group ${DATABASE2_INSTANCE_NAME}-instance-group \ --instance-group-zone ${DATABASE2_INSTANCE_ZONE} \ --region ${CLUSTER_REGION}为负载均衡器创建转发规则:
gcloud compute forwarding-rules create mysql-ilb-forwarding-rule \ --load-balancing-scheme internal \ --ports 3306 \ --network default \ --subnet default \ --region ${CLUSTER_REGION} \ --address ${ILB_IP} \ --backend-service mysql-ilb创建一条防火墙规则,以允许内部负载均衡器运行状况检查:
gcloud compute firewall-rules create allow-ilb-healthcheck \ --direction=INGRESS --network=default \ --action=ALLOW --rules=tcp:3306 \ --source-ranges=130.211.0.0/22,35.191.0.0/16 --target-tags=mysql要检查负载均衡器的状态,请前往 Google Cloud 控制台中的负载均衡页面。
点击
mysql-ilb:
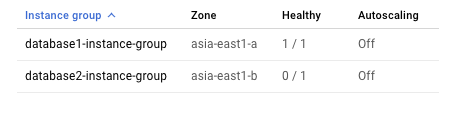
由于在任何给定时间,集群只允许一个实例运行 MySQL,因此从内部负载平衡器的角度来看,只有一个实例运行状况良好。
从 MySQL 客户端连接到集群
- 通过 SSH 连接到
mysql-client实例。 更新软件包定义:
sudo apt-get update安装 MySQL 客户端:
sudo apt-get install -y mysql-client创建一个脚本文件,并使用示例数据填充表:
cat <<EOF > db_creation.sql CREATE DATABASE source_db; use source_db; CREATE TABLE source_table ( id BIGINT NOT NULL AUTO_INCREMENT, timestamp timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP, event_data float DEFAULT NULL, PRIMARY KEY (id) ); DELIMITER $$ CREATE PROCEDURE simulate_data() BEGIN DECLARE i INT DEFAULT 0; WHILE i < 100 DO INSERT INTO source_table (event_data) VALUES (ROUND(RAND()*15000,2)); SET i = i + 1; END WHILE; END$$ DELIMITER ; CALL simulate_data() EOF创建表:
ILB_IP=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/ILB_IP" -H "Metadata-Flavor: Google") mysql -u root -pDRBDha2 "-h${ILB_IP}" < db_creation.sql
测试集群
为了测试已部署集群的 HA 功能,您可以执行以下测试:
- 关停
database1实例以测试主数据库能否故障切换到database2实例。 - 启动
database1实例以查看database1能否成功重新加入集群。 - 关停
database2实例以测试主数据库能否故障切换到database1实例。 - 启动
database2实例以查看database2能否成功重新加入集群,以及database1实例是否仍保留主实例角色。 - 在
database1和database2之间创建一个网络分区,以模拟脑裂问题。
打开 Cloud Shell:
停止
database1实例:gcloud compute instances stop ${DATABASE1_INSTANCE_NAME} \ --zone=${DATABASE1_INSTANCE_ZONE}检查集群状态:
gcloud compute ssh ${DATABASE2_INSTANCE_NAME} \ --zone=${DATABASE2_INSTANCE_ZONE} \ --command="sudo pcs status"输出如下所示。请验证您所执行的配置更改是否已生效:
2 nodes configured 4 resources configured Online: [ database2 ] OFFLINE: [ database1 ] Full list of resources: Master/Slave Set: primary_mysql [mysql_drbd] Masters: [ database2 ] Stopped: [ database1 ] mystore_FS (ocf::heartbeat:Filesystem): Started database2 mysql_service (ocf::heartbeat:mysql): Started database2 Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled启动
database1实例:gcloud compute instances start ${DATABASE1_INSTANCE_NAME} \ --zone=${DATABASE1_INSTANCE_ZONE}检查集群状态:
gcloud compute ssh ${DATABASE1_INSTANCE_NAME} \ --zone=${DATABASE1_INSTANCE_ZONE} \ --command="sudo pcs status"输出类似于以下内容:
2 nodes configured 4 resources configured Online: [ database1 database2 ] Full list of resources: Master/Slave Set: primary_mysql [mysql_drbd] Masters: [ database2 ] Slaves: [ database1 ] mystore_FS (ocf::heartbeat:Filesystem): Started database2 mysql_service (ocf::heartbeat:mysql): Started database2 Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled停止
database2实例:gcloud compute instances stop ${DATABASE2_INSTANCE_NAME} \ --zone=${DATABASE2_INSTANCE_ZONE}检查集群状态:
gcloud compute ssh ${DATABASE1_INSTANCE_NAME} \ --zone=${DATABASE1_INSTANCE_ZONE} \ --command="sudo pcs status"输出类似于以下内容:
2 nodes configured 4 resources configured Online: [ database1 ] OFFLINE: [ database2 ] Full list of resources: Master/Slave Set: primary_mysql [mysql_drbd] Masters: [ database1 ] Stopped: [ database2 ] mystore_FS (ocf::heartbeat:Filesystem): Started database1 mysql_service (ocf::heartbeat:mysql): Started database1 Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled启动
database2实例:gcloud compute instances start ${DATABASE2_INSTANCE_NAME} \ --zone=${DATABASE2_INSTANCE_ZONE}检查集群状态:
gcloud compute ssh ${DATABASE1_INSTANCE_NAME} \ --zone=${DATABASE1_INSTANCE_ZONE} \ --command="sudo pcs status"输出类似于以下内容:
2 nodes configured 4 resources configured Online: [ database1 database2 ] Full list of resources: Master/Slave Set: primary_mysql [mysql_drbd] Masters: [ database1 ] Slaves: [ database2 ] mystore_FS (ocf::heartbeat:Filesystem): Started database1 mysql_service (ocf::heartbeat:mysql): Started database1 Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled在
database1和database2之间创建一个网络分区:gcloud compute firewall-rules create block-comms \ --description="no MySQL communications" \ --action=DENY \ --rules=all \ --source-tags=mysql \ --target-tags=mysql \ --priority=800几分钟后,检查集群的状态。请注意
database1如何保持其主实例角色,因为在网络分区情景下,仲裁策略是最小 ID 节点优先。与此同时,database2MySQL 服务已停止。这种仲裁机制能够避免发生网络分区时存在的脑裂问题。gcloud compute ssh ${DATABASE1_INSTANCE_NAME} \ --zone=${DATABASE1_INSTANCE_ZONE} \ --command="sudo pcs status"输出类似于以下内容:
2 nodes configured 4 resources configured Online: [ database1 ] OFFLINE: [ database2 ] Full list of resources: Master/Slave Set: primary_mysql [mysql_drbd] Masters: [ database1 ] Stopped: [ database2 ] mystore_FS (ocf::heartbeat:Filesystem): Started database1 mysql_service (ocf::heartbeat:mysql): Started database1删除网络防火墙规则,以移除网络分区。(在看到系统提示时按
Y。)gcloud compute firewall-rules delete block-comms验证集群状态是否已恢复正常:
gcloud compute ssh ${DATABASE1_INSTANCE_NAME} \ --zone=${DATABASE1_INSTANCE_ZONE} \ --command="sudo pcs status"输出类似于以下内容:
2 nodes configured 4 resources configured Online: [ database1 database2 ] Full list of resources: Master/Slave Set: primary_mysql [mysql_drbd] Masters: [ database1 ] Slaves: [ database2 ] mystore_FS (ocf::heartbeat:Filesystem): Started database1 mysql_service (ocf::heartbeat:mysql): Started database1通过 SSH 连接到
mysql-client实例。在 shell 中,查询您之前创建的表:
ILB_IP=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/ILB_IP" -H "Metadata-Flavor: Google") mysql -uroot "-h${ILB_IP}" -pDRBDha2 -e "select * from source_db.source_table LIMIT 10"输出结果应按照如下形式列出 10 条记录,验证集群中的数据一致性:
+----+---------------------+------------+ | id | timestamp | event_data | +----+---------------------+------------+ | 1 | 2018-11-27 21:00:09 | 1279.06 | | 2 | 2018-11-27 21:00:09 | 4292.64 | | 3 | 2018-11-27 21:00:09 | 2626.01 | | 4 | 2018-11-27 21:00:09 | 252.13 | | 5 | 2018-11-27 21:00:09 | 8382.64 | | 6 | 2018-11-27 21:00:09 | 11156.8 | | 7 | 2018-11-27 21:00:09 | 636.1 | | 8 | 2018-11-27 21:00:09 | 14710.1 | | 9 | 2018-11-27 21:00:09 | 11642.1 | | 10 | 2018-11-27 21:00:09 | 14080.3 | +----+---------------------+------------+
故障切换序列
如果集群中的主节点发生故障,则相应的故障切换序列如下所示:
- 仲裁设备和备用节点均失去与主节点的连接。
- 仲裁设备投票给备用节点,备用节点投票给自身。
- 备用节点在仲裁中胜出。
- 备用节点升级为主节点。
- 新的主节点执行以下操作:
- 将 DRBD 升级为主节点
- 从 DRBD 装载 MySQL 数据磁盘
- 启动 MySQL
- 使得负载均衡器达到运行良好状态
- 负载均衡器开始将流量发送到新的主节点。
清理
删除项目
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
后续步骤
- 详细了解 DRBD。
- 详细了解 Pacemaker。
- 详细了解 Corosync Cluster Engine。
- 如需详细了解高级 MySQL 服务器 5.6 设置,请参阅 MySQL 服务器管理手册。
- 如果要设置对 MySQL 的远程访问,请参阅如何在 Compute Engine 上设置对 MySQL 的远程访问权限。
- 如需详细了解 MySQL,请参阅 MySQL 官方文档。
- 探索有关 Google Cloud 的参考架构、图表和最佳实践。查看我们的 Cloud 架构中心。