
Des bandes passantes réseau élevées peuvent améliorer les performances de vos instances de GPU pour prendre en charge les charges de travail distribuées exécutées sur Compute Engine.
La bande passante réseau maximale disponible pour les VM auxquelles sont associés des GPU sur Compute Engine est la suivante :
- Pour les instances optimisées pour les accélérateurs A4X, vous pouvez obtenir une bande passante réseau maximale de jusqu'à 2 000 Gbit/s, selon le type de machine.
- Pour les instances optimisées pour les accélérateurs A4 et A3, vous pouvez obtenir une bande passante réseau maximale de jusqu'à 3 600 Gbit/s, selon le type de machine.
- Pour les instances optimisées pour les accélérateurs G4, vous pouvez obtenir une bande passante réseau maximale de jusqu'à 400 Gbit/s, selon le type de machine.
- Pour les instances optimisées pour les accélérateurs A2 et G2, vous pouvez obtenir une bande passante réseau maximale de jusqu'à 100 Gbit/s, selon le type de machine.
- Pour les instances à usage général N1 auxquelles sont associés des GPU P100 et P4, la bande passante réseau maximale disponible est de 32 Gbit/s. Cela se rapproche du débit maximal disponible pour les instances N1 sans GPU. Pour en savoir plus sur les bandes passantes réseau, consultez Débit maximal de sortie de données.
- Pour les instances à usage général N1 auxquelles sont associés des GPU T4 et V100, vous pouvez obtenir une bande passante réseau maximale de 100 Gbit/s, en fonction de la combinaison du nombre de GPU et de vCPU (processeurs virtuels).
Examiner la bande passante réseau et la configuration de la carte d'interface réseau
Consultez la section suivante pour passer en revue la configuration réseau et la vitesse de bande passante pour chaque type de machine GPU.
Types de machines A4X
Les types de machines A4X sont associés à des superchips NVIDIA GB200. Ces superchips sont équipés de GPU NVIDIA B200.
Ce type de machine dispose de quatre cartes d'interface réseau NVIDIA ConnectX-7 (CX-7) et de deux cartes Titanium. Les quatre cartes d'interface réseau CX-7 offrent une bande passante réseau totale de 1 600 Gbit/s. Ces cartes CX-7 sont dédiées aux communications à bande passante élevée entre GPU uniquement et ne peuvent pas être utilisées pour d'autres besoins réseau, tels que l'accès à l'Internet public. Les deux cartes d'interface réseau Titanium sont des cartes intelligentes qui fournissent 400 Gbit/s de bande passante réseau supplémentaires pour les besoins généraux de mise en réseau. Combinées, les cartes d'interface réseau offrent une bande passante réseau maximale totale de 2 000 Gbit/s pour ces machines.
A4X est une plate-forme exaflopique basée sur l'architecture rack NVIDIA GB200 NVL72. Elle introduit l'architecture NVIDIA Grace Hopper Superchip, qui fournit des GPU NVIDIA Hopper et des CPU NVIDIA Grace rattachés par une interconnexion NVIDIA NVLink puce à puce (C2C) à haute bande passante.
L'architecture réseau A4X utilise une conception alignée sur rails, qui est une topologie dans laquelle la carte réseau correspondante d'une instance Compute Engine est connectée à la carte réseau d'une autre instance. Dans une topologie réseau quadridirectionnel aligné sur rails, les quatre cartes d'interface réseau CX-7 de chaque instance sont physiquement isolées, ce qui permet un scaling horizontal des instances A4X par groupes de 72 à plusieurs milliers de GPU dans un seul cluster non bloquant. Cette approche axée sur l'intégration matérielle offre des performances prévisibles et à faible latence qui s'avèrent essentielles pour les charges de travail distribuées à grande échelle.
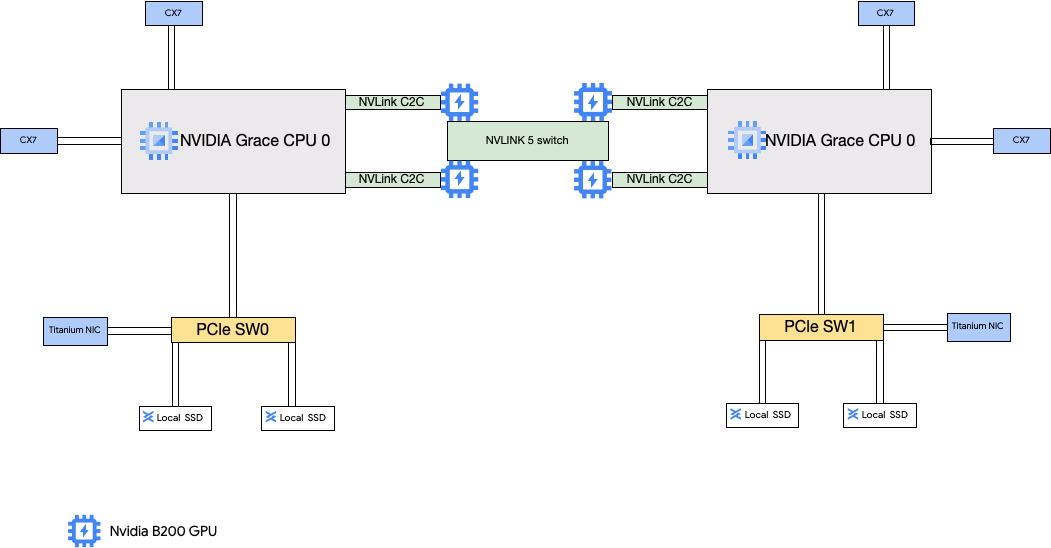
Pour utiliser ces multiples cartes d'interface réseau, vous devez créer trois réseaux de cloud privé virtuel comme suit :
- Deux réseaux VPC : chaque carte gVNIC doit être associée à un réseau VPC différent.
- Un réseau VPC avec le profil réseau RDMA : les quatre cartes d'interface réseau CX-7 partagent le même réseau VPC.
Pour configurer ces réseaux, consultez Créer des réseaux VPC dans la documentation d'AI Hypercomputer.
| Superchips NVIDIA GB200 Grace Blackwell associés | |||||||
|---|---|---|---|---|---|---|---|
| Type de machine | Nombre de vCPU1 | Mémoire de l'instance (Go) | SSD local associé (Gio) | Nombre de cartes d'interface réseau physiques | Bande passante réseau maximale (Gbit/s)2 | Nombre de GPU | Mémoire de GPU3 (GB HBM3e) |
a4x-highgpu-4g |
140 | 884 | 12 000 | 6 | 2 000 | 4 | 720 |
1 Un vCPU est mis en œuvre sous la forme d'une technologie hyper-threading matérielle unique sur l'une des plates-formes de processeur disponibles.
2 La bande passante de sortie maximale ne peut pas dépasser le nombre donné. La bande passante de sortie réelle dépend de l'adresse IP de destination et d'autres facteurs.
Pour en savoir plus sur la bande passante réseau, consultez Bande passante réseau.
3 La mémoire de GPU est la mémoire disponible sur un GPU pouvant être utilisée pour le stockage temporaire de données. Elle est distincte de la mémoire de l'instance et est spécialement conçue pour gérer les demandes de bande passante plus élevées de vos charges de travail exigeantes en ressources graphiques.
Types de machines A4 et A3 Ultra
Les types de machines A4 sont associés à des GPU NVIDIA B200, et les types de machines A3 Ultra sont associés à des GPU NVIDIA H200.
Ces types de machines fournissent huit cartes d'interface réseau NVIDIA ConnectX-7 (CX-7) et deux cartes d'interface réseau virtuelles Google (gVNIC). Les huit cartes d'interface réseau CX-7 offrent une bande passante réseau totale de 3 200 Gbit/s. Ces cartes d'interface réseau sont dédiées aux communications à bande passante élevée entre GPU et ne peuvent pas être utilisées pour d'autres besoins réseau, tels que l'accès à l'Internet public. Comme indiqué dans le schéma suivant, chaque carte d'interface réseau CX-7 est alignée sur un GPU pour optimiser l'accès non uniforme à la mémoire (NUMA). Les huit GPU peuvent communiquer rapidement entre eux grâce au pont NVLink maillé qui les relie. Les deux autres cartes d'interface réseau gVNIC sont des cartes intelligentes qui fournissent 400 Gbit/s de bande passante réseau supplémentaires pour les besoins généraux de mise en réseau. Combinées, les cartes d'interface réseau offrent une bande passante réseau maximale totale de 3 600 Gbit/s pour ces machines.

Pour utiliser ces multiples cartes d'interface réseau, vous devez créer trois réseaux de cloud privé virtuel comme suit :
- Deux réseaux VPC standards : chaque carte gVNIC doit être associée à un réseau VPC différent.
- Un réseau VPC RoCE : les huit cartes d'interface réseau CX-7 partagent le même réseau VPC RoCE.
Pour configurer ces réseaux, consultez Créer des réseaux VPC dans la documentation d'AI Hypercomputer.
VM A4
| GPU NVIDIA B200 Blackwell associés | |||||||
|---|---|---|---|---|---|---|---|
| Type de machine | Nombre de vCPU1 | Mémoire de l'instance (Go) | SSD local associé (Gio) | Nombre de cartes d'interface réseau physiques | Bande passante réseau maximale (Gbit/s)2 | Nombre de GPU | Mémoire de GPU3 (GB HBM3e) |
a4-highgpu-8g |
224 | 3 968 | 12 000 | 10 | 3 600 | 8 | 1 440 |
1 Un vCPU est mis en œuvre sous la forme d'une technologie hyper-threading matérielle unique sur l'une des plates-formes de processeur disponibles.
2 La bande passante de sortie maximale ne peut pas dépasser le nombre donné. La bande passante de sortie réelle dépend de l'adresse IP de destination et d'autres facteurs.
Pour en savoir plus sur la bande passante réseau, consultez Bande passante réseau.
3 La mémoire de GPU est la mémoire disponible sur un GPU pouvant être utilisée pour le stockage temporaire de données. Elle est distincte de la mémoire de l'instance et est spécialement conçue pour gérer les demandes de bande passante plus élevées de vos charges de travail exigeantes en ressources graphiques.
VM A3 Ultra
| GPU NVIDIA H200 associés | |||||||
|---|---|---|---|---|---|---|---|
| Type de machine | Nombre de vCPU1 | Mémoire de l'instance (Go) | SSD local associé (Gio) | Nombre de cartes d'interface réseau physiques | Bande passante réseau maximale (Gbit/s)2 | Nombre de GPU | Mémoire de GPU3 (GB HBM3e) |
a3-ultragpu-8g |
224 | 2 952 | 12 000 | 10 | 3 600 | 8 | 1128 |
1 Un vCPU est mis en œuvre sous la forme d'une technologie hyper-threading matérielle unique sur l'une des plates-formes de processeur disponibles.
2 La bande passante de sortie maximale ne peut pas dépasser le nombre donné. La bande passante de sortie réelle dépend de l'adresse IP de destination et d'autres facteurs.
Pour en savoir plus sur la bande passante réseau, consultez Bande passante réseau.
3 La mémoire de GPU est la mémoire disponible sur un GPU pouvant être utilisée pour le stockage temporaire de données. Elle est distincte de la mémoire de l'instance et est spécialement conçue pour gérer les demandes de bande passante plus élevées de vos charges de travail exigeantes en ressources graphiques.
Types de machines A3 Mega, High et Edge
Ces types de machines sont associés à des GPU H100. Chacun de ces types de machines possède un nombre de GPU, un nombre de vCPU et une taille de mémoire fixes.
- VM A3 à carte d'interface réseau unique : pour les VM A3 associées à un à quatre GPU, une seule carte d'interface réseau physique est disponible.
- VM A3 à plusieurs cartes d'interface réseau : pour les VM A3 avec huit GPU associés, plusieurs cartes d'interface réseau physiques sont disponibles. Pour ces types de machines A3, les cartes d'interface réseau sont organisées comme suit sur un bus Peripheral Component Interconnect Express (PCIe) :
- Pour le type de machine A3 Mega : une configuration de carte d'interface réseau de 8+1 est disponible. Avec cet agencement, huit cartes d'interface réseau partagent le même bus PCIe et une carte d'interface réseau réside sur un bus PCIe distinct.
- Pour le type de machine A3 High : une configuration de carte d'interface réseau de 4+1 est disponible. Avec cet agencement, quatre cartes d'interface réseau partagent le même bus PCIe et une carte d'interface réseau réside sur un bus PCIe distinct.
- Pour le type de machine A3 Edge : une configuration de carte d'interface réseau de 4+1 est disponible. Avec cet agencement, quatre cartes d'interface réseau partagent le même bus PCIe et une carte d'interface réseau réside sur un bus PCIe distinct. Ces cinq cartes d'interface réseau offrent une bande passante réseau totale de 400 Gbit/s pour chaque VM.
Les cartes d'interface réseau qui partagent le même bus PCIe ont un alignement non uniforme d'accès à la mémoire (NUMA) d'une carte d'interface réseau pour deux GPU NVIDIA H100 80 Go. Ces cartes d'interface réseau sont idéales pour les communications à bande passante élevée entre GPU. La carte d'interface réseau physique qui réside sur un bus PCIe distinct est idéale pour d'autres besoins de mise en réseau. Pour obtenir des instructions sur la configuration de la mise en réseau pour les VM A3 High et A3 Edge, consultez Configurer des réseaux avec une MTU de trame géante.
A3 Mega
| GPU NVIDIA H100 associés | |||||||
|---|---|---|---|---|---|---|---|
| Type de machine | Nombre de vCPU1 | Mémoire de l'instance (Go) | SSD local associé (Gio) | Nombre de cartes d'interface réseau physiques | Bande passante réseau maximale (Gbit/s)2 | Nombre de GPU | Mémoire GPU3 (GB HBM3) |
a3-megagpu-8g |
208 | 1 872 | 6 000 | 9 | 1 800 | 8 | 640 |
A3 High
| GPU NVIDIA H100 associés | |||||||
|---|---|---|---|---|---|---|---|
| Type de machine | Nombre de vCPU1 | Mémoire de l'instance (Go) | SSD local associé (Gio) | Nombre de cartes d'interface réseau physiques | Bande passante réseau maximale (Gbit/s)2 | Nombre de GPU | Mémoire GPU3 (GB HBM3) |
a3-highgpu-1g |
26 | 234 | 750 | 1 | 25 | 1 | 80 |
a3-highgpu-2g |
52 | 468 | 1 500 | 1 | 50 | 2 | 160 |
a3-highgpu-4g |
104 | 936 | 3 000 | 1 | 100 | 4 | 320 |
a3-highgpu-8g |
208 | 1 872 | 6 000 | 5 | 1 000 | 8 | 640 |
A3 Edge
| GPU NVIDIA H100 associés | |||||||
|---|---|---|---|---|---|---|---|
| Type de machine | Nombre de vCPU1 | Mémoire de l'instance (Go) | SSD local associé (Gio) | Nombre de cartes d'interface réseau physiques | Bande passante réseau maximale (Gbit/s)2 | Nombre de GPU | Mémoire GPU3 (GB HBM3) |
a3-edgegpu-8g |
208 | 1 872 | 6 000 | 5 |
|
8 | 640 |
1 Un vCPU est mis en œuvre sous la forme d'une technologie hyper-threading matérielle unique sur l'une des plates-formes de processeur disponibles.
2 La bande passante de sortie maximale ne peut pas dépasser le nombre donné. La bande passante de sortie réelle dépend de l'adresse IP de destination et d'autres facteurs.
Pour en savoir plus sur la bande passante réseau, consultez Bande passante réseau.
3 La mémoire de GPU est la mémoire disponible sur un GPU pouvant être utilisée pour le stockage temporaire de données. Elle est distincte de la mémoire de l'instance et est spécialement conçue pour gérer les demandes de bande passante plus élevées de vos charges de travail exigeantes en ressources graphiques.
Types de machines A2
Chaque type de machine A2 est associé à un nombre fixe de GPU NVIDIA A100 40 Go ou NVIDIA A100 80 Go. Chaque type de machine possède également un nombre de vCPU et une taille de mémoire fixes.
La série de machines A2 est disponible dans deux types :
- A2 Ultra : ces types de machines sont associés à des GPU A100 de 80 Go et à des disques SSD locaux.
- A2 Standard : ces types de machines sont associés à des GPU A100 de 40 Go.
A2 Ultra
| GPU NVIDIA A100 80 Go associés | ||||||
|---|---|---|---|---|---|---|
| Type de machine | Nombre de vCPU1 | Mémoire de l'instance (Go) | SSD local associé (Gio) | Bande passante réseau maximale (Gbit/s)2 | Nombre de GPU | Mémoire GPU3 (GB HBM2e) |
a2-ultragpu-1g |
12 | 170 | 375 | 24 | 1 | 80 |
a2-ultragpu-2g |
24 | 340 | 750 | 32 | 2 | 160 |
a2-ultragpu-4g |
48 | 680 | 1 500 | 50 | 4 | 320 |
a2-ultragpu-8g |
96 | 1 360 | 3 000 | 100 | 8 | 640 |
A2 Standard
| GPU NVIDIA A100 40 Go associés | ||||||
|---|---|---|---|---|---|---|
| Type de machine | Nombre de vCPU1 | Mémoire de l'instance (Go) | SSD local pris en charge | Bande passante réseau maximale (Gbit/s)2 | Nombre de GPU | Mémoire GPU3 (GB HBM2) |
a2-highgpu-1g |
12 | 85 | Oui | 24 | 1 | 40 |
a2-highgpu-2g |
24 | 170 | Oui | 32 | 2 | 80 |
a2-highgpu-4g |
48 | 340 | Oui | 50 | 4 | 160 |
a2-highgpu-8g |
96 | 680 | Oui | 100 | 8 | 320 |
a2-megagpu-16g |
96 | 1 360 | Oui | 100 | 16 | 640 |
1 Un vCPU est mis en œuvre sous la forme d'une technologie hyper-threading matérielle unique sur l'une des plates-formes de processeur disponibles.
2 La bande passante de sortie maximale ne peut pas dépasser le nombre donné. La bande passante de sortie réelle dépend de l'adresse IP de destination et d'autres facteurs.
Pour en savoir plus sur la bande passante réseau, consultez Bande passante réseau.
3 La mémoire de GPU est la mémoire disponible sur un GPU pouvant être utilisée pour le stockage temporaire de données. Elle est distincte de la mémoire de l'instance et est spécialement conçue pour gérer les demandes de bande passante plus élevées de vos charges de travail exigeantes en ressources graphiques.
Types de machines G4
Les types de machines G4 optimisées pour les accélérateurs utilisent des GPU NVIDIA RTX PRO 6000 Blackwell Server Edition (nvidia-rtx-pro-6000) et conviennent aux charges de travail de simulation NVIDIA Omniverse, aux applications exigeantes en ressources graphiques, au transcodage vidéo et aux bureaux virtuels. Les types de machines G4 offrent également une solution à faible coût pour l'inférence et le réglage de modèle sur un seul hôte, par rapport aux types de machines de la série A.
| GPU NVIDIA RTX PRO 6000 associés | |||||||
|---|---|---|---|---|---|---|---|
| Type de machine | Nombre de vCPU1 | Mémoire de l'instance (Go) | Volumes Titanium SSD maximaux pris en charge (Gio)2 | Nombre de cartes d'interface réseau physiques | Bande passante réseau maximale (Gbit/s)3 | Nombre de GPU | Mémoire de GPU4 (Go GDDR7) |
g4-standard-48 |
48 | 180 | 1 500 | 1 | 50 | 1 | 96 |
g4-standard-96 |
96 | 360 | 3 000 | 1 | 100 | 2 | 192 |
g4-standard-192 |
192 | 720 | 6 000 | 1 | 200 | 4 | 384 |
g4-standard-384 |
384 | 1 440 | 12 000 | 2 | 400 | 8 | 768 |
1 Un vCPU est mis en œuvre sous la forme d'une technologie hyper-threading matérielle unique sur l'une des plates-formes de processeur disponibles.
2 Vous pouvez ajouter des disques Titanium SSD lorsque vous créez une instance G4. Pour connaître le nombre de disques que vous pouvez associer, consultez Types de machines nécessitant le choix d'un nombre de disques SSD locaux.
3 La bande passante de sortie maximale ne peut pas dépasser le nombre donné. La bande passante de sortie réelle dépend de l'adresse IP de destination et d'autres facteurs.
Consultez Bande passante réseau.
4 La mémoire de GPU est la mémoire disponible sur un GPU pouvant être utilisée pour le stockage temporaire de données. Elle est distincte de la mémoire de l'instance et est spécialement conçue pour gérer les demandes de bande passante plus élevées de vos charges de travail exigeantes en ressources graphiques.
Types de machines G2
Les types de machines G2 optimisées pour les accélérateurs sont associés à des GPU NVIDIA L4 et sont idéaux pour les charges de travail d'inférence optimisées pour les coûts, les charges de travail de calcul hautes performances et celles nécessitant beaucoup de ressources graphiques.
Chaque type de machine G2 dispose également d'une mémoire par défaut et d'une plage de mémoire personnalisée. La plage de mémoire personnalisée définit la quantité de mémoire que vous pouvez allouer à votre instance pour chaque type de machine. Vous pouvez également ajouter des disques SSD locaux lorsque vous créez une instance G2. Pour connaître le nombre de disques que vous pouvez associer, consultez Types de machines nécessitant le choix d'un nombre de disques SSD locaux.
Pour obtenir les débits de bande passante réseau plus élevés (50 Gbit/s ou plus) appliqués à la plupart des instances de GPU, il est recommandé d'utiliser la carte d'interface réseau virtuelle Google (gVNIC). Pour en savoir plus sur la création d'instances de GPU qui utilisent gVNIC, consultez Créer des instances de GPU qui utilisent des bandes passantes élevées.
| GPU NVIDIA L4 associés | |||||||
|---|---|---|---|---|---|---|---|
| Type de machine | Nombre de vCPU1 | Mémoire d'instance par défaut (Go) | Plage de mémoire d'instance personnalisée (Go) | Disque SSD local maximal pris en charge (Gio) | Bande passante réseau maximale (Gbit/s)2 | Nombre de GPU | Mémoire de GPU3 (Go GDDR6) |
g2-standard-4 |
4 | 16 | 16 à 32 | 375 | 10 | 1 | 24 |
g2-standard-8 |
8 | 32 | 32 à 54 | 375 | 16 | 1 | 24 |
g2-standard-12 |
12 | 48 | 48 à 54 | 375 | 16 | 1 | 24 |
g2-standard-16 |
16 | 64 | 54 à 64 | 375 | 32 | 1 | 24 |
g2-standard-24 |
24 | 96 | 96 à 108 | 750 | 32 | 2 | 48 |
g2-standard-32 |
32 | 128 | 96 à 128 | 375 | 32 | 1 | 24 |
g2-standard-48 |
48 | 192 | 192 à 216 | 1 500 | 50 | 4 | 96 |
g2-standard-96 |
96 | 384 | 384 à 432 | 3 000 | 100 | 8 | 192 |
1 Un vCPU est mis en œuvre sous la forme d'une technologie hyper-threading matérielle unique sur l'une des plates-formes de processeur disponibles.
2 La bande passante de sortie maximale ne peut pas dépasser le nombre donné. La bande passante de sortie réelle dépend de l'adresse IP de destination et d'autres facteurs.
Pour en savoir plus sur la bande passante réseau, consultez Bande passante réseau.
3 La mémoire de GPU est la mémoire disponible sur un GPU pouvant être utilisée pour le stockage temporaire de données. Elle est distincte de la mémoire de l'instance et est spécialement conçue pour gérer les demandes de bande passante plus élevées de vos charges de travail exigeantes en ressources graphiques.
Types de machines N1 + GPU
Pour les instances à usage général N1 auxquelles sont associés des GPU T4 et V100, vous pouvez obtenir une bande passante réseau maximale de 100 Gbit/s, en fonction de la combinaison du nombre de GPU et de vCPU (processeurs virtuels). Pour toutes les autres instances de GPU N1, consultez Présentation.
Consultez la section suivante pour calculer la bande passante réseau maximale disponible pour vos instances T4 et V100 en fonction du modèle de GPU, du VCPU et du nombre de GPU.
Moins de 5 vCPU
Pour les instances T4 et V100 comportant cinq vCPU ou moins, la bande passante réseau maximale disponible est de 10 Gbit/s.
Plus de 5 vCPU
Pour les instances T4 et V100 comportant plus de cinq processeurs virtuels, la bande passante réseau maximale est calculée en fonction du nombre de vCPU et de GPU pour cette VM.
Pour obtenir les débits de bande passante réseau plus élevés (50 Gbit/s ou plus) appliqués à la plupart des instances de GPU, il est recommandé d'utiliser la carte d'interface réseau virtuelle Google (gVNIC). Pour en savoir plus sur la création d'instances de GPU qui utilisent gVNIC, consultez Créer des instances de GPU qui utilisent des bandes passantes élevées.
| Modèle GPU | Nombre de GPU | Calcul de la bande passante réseau maximale |
|---|---|---|
| NVIDIA V100 | 1 | min(vcpu_count * 2, 32) |
| 2 | min(vcpu_count * 2, 32) |
|
| 4 | min(vcpu_count * 2, 50) |
|
| 8 | min(vcpu_count * 2, 100) |
|
| NVIDIA T4 | 1 | min(vcpu_count * 2, 32) |
| 2 | min(vcpu_count * 2, 50) |
|
| 4 | min(vcpu_count * 2, 100) |
Paramètres MTU et types de machines avec GPU
Pour maximiser la bande passante du réseau, définissez une valeur d'unité de transmission maximale (MTU) plus élevée pour vos réseaux VPC. Des valeurs de MTU plus élevées augmentent la taille des paquets et réduisent la surcharge de l'en-tête du paquet, ce qui augmente le débit des données de charge utile.
Pour les types de machines GPU, nous vous recommandons les paramètres MTU suivants pour vos réseaux VPC.
| Type de machine GPU | MTU recommandée (en octets) | |
|---|---|---|
| Réseau VPC | Réseau VPC avec profils RDMA | |
|
8 896 | 8 896 |
|
8 244 | N/A |
|
8 896 | N/A |
Lorsque vous définissez la valeur MTU, tenez compte des points suivants :
- 8 192 correspond à deux pages de 4 Ko.
- 8 244 est recommandé dans les VM A3 Mega, A3 High et A3 Edge pour les cartes d'interface réseau GPU avec division d'en-tête activée.
- Utilisez la valeur 8 896, sauf indication contraire dans le tableau.
Créer des machines GPU à bande passante élevée
Pour créer des instances de GPU qui utilisent des bandes passantes réseau élevées, utilisez l'une des méthodes suivantes en fonction du type de machine :
Pour créer des instances A2, G2 et N1 qui utilisent des bandes passantes réseau élevées, consultez Utiliser une bande passante réseau élevée pour les instances A2, G2 et N1. Pour tester ou vérifier la vitesse de bande passante de ces machines, vous pouvez utiliser le test d'analyse comparative. Pour en savoir plus, consultez Vérifier la bande passante réseau.
Pour créer des instances A3 Mega qui utilisent des bandes passantes réseau élevées, consultez Déployer un cluster Slurm A3 Mega pour l'entraînement ML. Pour tester ou vérifier la vitesse de bande passante de ces machines, utilisez un test d'analyse comparative en suivant les étapes décrites dans Vérifier la bande passante réseau.
Pour les instances A3 High et A3 Edge qui utilisent des bandes passantes réseau élevées, consultez Créer une VM A3 avec GPUDirect-TCPX activé. Pour tester ou vérifier la vitesse de bande passante de ces machines, vous pouvez utiliser le test d'analyse comparative. Pour en savoir plus, consultez Vérifier la bande passante réseau.
Sur les autres types de machines optimisées pour les accélérateurs, aucune action n'est requise pour utiliser une bande passante réseau élevée. La création d'une instance, telle que décrite dans la documentation, utilise déjà une bande passante réseau élevée. Pour savoir comment créer des instances pour d'autres types de machines optimisées pour les accélérateurs, consultez Créer une VM avec des GPU associés.
Étapes suivantes
- Apprenez-en plus sur les plates-formes GPU.
- Découvrez comment créer des instances avec des GPU associés.
- Apprenez comment Utiliser une bande passante réseau élevée.
- Consultez les tarifs des GPU.