
הסבר על נתוני הביצועים
בדף הזה מתוארים הביצועים המשוערים ש-Bigtable יכול לספק בתנאים אופטימליים, גורמים שיכולים להשפיע על הביצועים וטיפים לבדיקה ולפתרון בעיות בביצועים של Bigtable.
ביצועים לעומסי עבודה אופייניים
Bigtable מספק ביצועים צפויים מאוד, שניתנים להרחבה באופן לינארי. אם נמנעים מהגורמים לביצועים איטיים יותר שמתוארים בדף הזה, כל צומת Bigtable יכול לספק את נפח התפוקה המשוער הבא, בהתאם לסוג האחסון שבו נעשה שימוש באשכול:
| רמת אחסון | קריאות | כותב | סריקות | ||
|---|---|---|---|---|---|
| רמת ביניים בזיכרון (תצוגה מקדימה) | עד 120,000 שורות בשנייה1 | או | עד 10,000 שורות בשנייה2 | לא רלוונטי | |
| SSD | עד 17,000 שורות לשנייה | או | עד 14,000 שורות בשנייה | או | עד 220 MBps |
| HDD | עד 500 שורות בשנייה | או | עד 10,000 שורות לשנייה | או | עד 180 MBps |
| אחסון עם גישה לא תכופה | עד 100 שורות בשנייה | או | עד 10,000 שורות לשנייה | או | עד 36 MBps |
ההערכות האלה מניחות שכל שורה מכילה 1KB.
1 צומת Enterprise Plus כולל 40,000 שורות בשנייה, ויכול להתרחב אנכית עד 120,000 שורות בשנייה לכל צומת במרווחים של 40,000. מידע נוסף זמין במאמר בנושא שכבת זיכרון.
2 כתיבה גבוהה של שורות לשנייה לנתונים בשכבת הזיכרון יכולה להשפיע על תפוקת הכתיבה.
באופן כללי, הביצועים של אשכול משתפרים באופן לינארי ככל שמוסיפים צמתים לאשכול. לדוגמה, אם יוצרים אשכול SSD עם 10 צמתים, האשכול יכול לתמוך בעד 140,000 שורות בשנייה עבור עומס עבודה טיפוסי לקריאה בלבד או לכתיבה בלבד, ללא הפעלת שכבת הזיכרון. כשהשכבה של הזיכרון הפנימי מופעלת, האשכול יכול לתמוך בקצב העברת נתונים לקריאה של עד 1.2 מיליון שורות בשנייה.
תכנון הקיבולת של Bigtable
כשמתכננים את אשכולות Bigtable, צריך להחליט אם רוצים לבצע אופטימיזציה לזמן אחזור או לתפוקה. לדוגמה, כשמדובר במשימת עיבוד נתונים באצווה, יכול להיות שחשוב לכם יותר להגדיל את קצב העברת הנתונים ופחות להקטין את זמן האחזור. לעומת זאת, בשירות אונליין שמטפל בבקשות של משתמשים, יכול להיות שתעדיפו לתת עדיפות לזמן אחזור נמוך על פני קצב העברת נתונים. כדי להגיע למספרים שמופיעים בקטע ביצועים עבור עומסי עבודה אופייניים, צריך לבצע אופטימיזציה של קצב העברת הנתונים.
רמה בזיכרון
כשהרמה בזיכרון מופעלת, כל צומת כולל 40,000 שורות לשנייה. הוספת צמתים אופקית מגדילה את הקיבולת הכוללת של האשכול. בנוסף, כל צומת יכול להתרחב אנכית עד למקסימום של 120,000 שורות לשנייה לכל צומת, כדי לתמוך בנפח קריאה בזיכרון. כשמגיעים למגבלת ההתאמה לעומס (scaling) האנכית, התאמה אוטומטית לעומס ב-Bigtable מוסיפה עוד צמתים כדי לבצע התאמה לעומס אופקית. במקרה של אשכול עם התאמה ידנית לעומס (scaling), יש תמיכה בהתאמה אנכית לעומס בזיכרון עד שמגיעים לקיבולת התפוקה. חיוב על שינוי קנה מידה אנכי מעבר ל-40,000 השורות הבסיסיות לשנייה מתבצע על ידי החלת מכפיל על העלות השעתית של הצומת. מידע נוסף מפורט בקטע תמחור.
כל צומת בזיכרון כולל קיבולת אחסון של 8 GB. למרות שניתן להגדיל את קצב העברת הנתונים באופן אנכי, קיבולת האחסון נשארת קבועה לכל צומת. עם זאת, הרחבה אופקית מוסיפה עוד 8GB של זיכרון לכל צומת חדש. מכיוון שנפח האחסון לא גדל במהלך שינוי גודל אנכי, יכול להיות ששיעור השגיאות של עומס עבודה יעלה כשצומת משנה את גודל התפוקה בזיכרון באופן אנכי.
ניצול יחידת העיבוד המרכזית (CPU)
ברוב המקרים, מומלץ להשתמש בהתאמה אוטומטית לעומס, שמאפשרת ל-Bigtable להוסיף או להסיר צמתים על סמך השימוש. מידע נוסף זמין במאמר בנושא שינוי אוטומטי של גודל הקבוצה.
כשמגדירים את יעדי ההתאמה האוטומטית לעומס או כשבוחרים בהקצאת צמתים ידנית, צריך לפעול לפי ההנחיות הבאות. ההנחיות האלה חלות ללא קשר למספר האשכולות במופע שלכם. במקרה של אשכול עם הקצאת צמתים ידנית, צריך לעקוב אחרי ניצול המעבד באשכול כדי לשמור על ניצול המעבד מתחת לערכים האלה, וכך להשיג ביצועים אופטימליים.
| יעד אופטימיזציה | ניצול מקסימלי של המעבד |
|---|---|
| תפוקה | 90% |
| זמן אחזור | 60% |
מידע נוסף על מעקב זמין במאמר מעקב.
ניצול נפח האחסון
אחסון הוא שיקול נוסף בתכנון הקיבולת. קיבולת האחסון של אשכול נקבעת לפי סוג האחסון ומספר הצמתים באשכול. כמות הנתונים שמאוחסנים באשכול גדלה, Bigtable מבצע אופטימיזציה של האחסון על ידי חלוקת הנתונים בין כל הצמתים באשכול.
כדי לחשב את נפח האחסון שנוצל בכל צומת, מחלקים את נפח האחסון (בבייטים) של האשכול במספר הצמתים באשכול. לדוגמה, ניקח אשכול עם שלושה צמתים של כונני HDD ו-9TB של נתונים. כל צומת מאחסן כ-3TB, שהם 18.75% ממגבלת האחסון בכונן הקשיח לכל צומת של 16TB.
כשניצול האחסון עולה, יכול להיות שזמן האחזור של עיבוד השאילתות בעומסי העבודה יתארך, גם אם יש באשכול מספיק צמתים כדי לעמוד בדרישות הכוללות של המעבד. הסיבה לכך היא שככל שנפח האחסון לכל צומת גדול יותר, נדרשת יותר עבודה ברקע, כמו יצירת אינדקסים. הגידול בעבודת הרקע שנדרשת כדי לטפל בנפח אחסון גדול יותר עלול להוביל לזמן אחזור ארוך יותר ולתפוקה נמוכה יותר.
כשמגדירים את ההגדרות של התאמה אוטומטית לעומס (automatic scaling), כדאי להתחיל עם ההגדרות הבאות. אם בוחרים בהקצאת צמתים ידנית, צריך לעקוב אחרי ניצול האחסון של האשכול ולהוסיף או להסיר צמתים כדי לשמור על התנאים הבאים.
| יעד אופטימיזציה | ניצול מקסימלי של נפח האחסון |
|---|---|
| תפוקה | 70% |
| זמן אחזור | 60% |
מידע נוסף זמין במאמר בנושא אחסון לכל צומת.
הרצת עומסי העבודה ב-Bigtable
כשמתכננים את הקיבולת כדי לקבוע את הקצאת המשאבים הטובה ביותר לאפליקציות, תמיד מריצים את עומסי העבודה מול אשכול Bigtable.
PerfKit Benchmarker של Google משתמש ב-YCSB כדי לבצע השוואה בין שירותי ענן. אתם יכולים לפעול לפי המדריך ל-PerfKitBenchmarker ל-Bigtable כדי ליצור בדיקות לעומסי העבודה שלכם. כשעושים את זה, צריך לשנות את הפרמטרים בקובצי ה-YAML של הגדרות ההשוואה כדי לוודא שההשוואה שנוצרה משקפת את מאפייני הייצור הבאים:
- הגודל הכולל של הטבלה (יחסי, אבל לפחות 100GB).
- צורת נתוני השורה (גודל מפתח השורה, מספר העמודות, גדלי נתוני השורה וכו')
- דפוס גישה לנתונים (חלוקת מפתחות השורות)
- תערובת של קריאות מול כתיבות
במאמר בנושא בדיקת ביצועים באמצעות Bigtable מפורטות שיטות מומלצות נוספות.
סיבות לביצועים איטיים יותר
הגורמים הבאים יכולים לגרום ל-Bigtable לפעול לאט יותר מההערכה:
- קראתם מספר גדול של מפתחות שורות או טווחי שורות לא רציפים בבקשת קריאה אחת. Bigtable סורק את הטבלה וקורא את השורות המבוקשות באופן רציף. היעדר המקביליות הזה משפיע על זמן האחזור הכולל, ופעולות קריאה שמגיעות לצומת פעיל עלולות להגדיל את זמן האחזור הקיצוני. לפרטים נוספים, אפשר לעיין במאמר בנושא קריאות וביצועים.
- הסכימה של הטבלה לא מתוכננת בצורה נכונה. כדי להשיג ביצועים טובים מ-Bigtable, חשוב לתכנן סכימה שתאפשר לפזר את הקריאות והכתיבות באופן שווה בכל טבלה. בנוסף, אזורים פופולריים בטבלה אחת יכולים להשפיע על הביצועים של טבלאות אחרות באותו מופע. מידע נוסף זמין במאמר בנושא שיטות מומלצות לעיצוב סכימה.
- השורות בטבלת Bigtable מכילות כמויות גדולות של נתונים. ההערכות לגבי הביצועים מבוססות על ההנחה שכל שורה מכילה נתונים בגודל 1KB. אפשר לקרוא ולכתוב כמויות גדולות יותר של נתונים לכל שורה, אבל הגדלת כמות הנתונים לכל שורה תגרום גם להקטנת מספר השורות לשנייה.
- השורות בטבלת Bigtable מכילות מספר גדול מאוד של תאים. לוקח זמן ל-Bigtable לעבד כל תא בשורה. בנוסף, כל תא מוסיף תקורה מסוימת לכמות הנתונים שמאוחסנים בטבלה ונשלחים ברשת. לדוגמה, אם מאחסנים נתונים בגודל 1KB (1,024 בייט), הרבה יותר יעיל לאחסן את הנתונים האלה בתא אחד, במקום לפצל אותם ל-1,024 תאים שכל אחד מהם מכיל בייט אחד. אם תפצלו את הנתונים ליותר תאים מהנדרש, יכול להיות שלא תקבלו את הביצועים הכי טובים שאפשר. אם השורות מכילות מספר גדול של תאים כי העמודות מכילות כמה גרסאות של נתונים עם חותמת זמן, כדאי לשמור רק את הערך האחרון. אפשרות נוספת לטבלה קיימת היא לשלוח בקשת מחיקה לכל הגרסאות הקודמות בכל כתיבה מחדש.
אין מספיק צמתים באשכול. הצמתים של אשכול מספקים מחשוב לאשכול כדי לטפל בפעולות קריאה וכתיבה נכנסות, לעקוב אחרי האחסון ולבצע משימות תחזוקה כמו דחיסה. צריך לוודא שיש מספיק צמתים באשכול כדי לעמוד במגבלות המומלצות גם לחישוב וגם לאחסון. אפשר להשתמש בכלי המעקב כדי לבדוק אם העומס על האשכול גבוה מדי.
- חישוב – אם העומס על המעבד (CPU) של אשכול Bigtable גבוה מדי, הוספת צמתים נוספים משפרת את הביצועים כי עומס העבודה מתחלק בין יותר צמתים.
- אחסון – אם נפח אחסון נדרש לכל צומת גבוה מהמומלץ, צריך להוסיף עוד צמתים כדי לשמור על זמן טעינה ותפוקה אופטימליים, גם אם יש מספיק מעבד (CPU) באשכול כדי לעבד בקשות. הסיבה לכך היא שככל שמגדילים את נפח האחסון לכל צומת, גדלה כמות עבודת התחזוקה ברקע לכל צומת. מידע נוסף זמין במאמר הפשרות בין נפח אחסון נדרש לבין ביצועים.
הייתה לאחרונה סילומיות אנכית (scale up) או הפחתה בהתאם לעומס (scale down) של אשכול Bigtable. אחרי שהתאמה אוטומטית לעומס מגדילה את מספר הצמתים באשכול, יכולות לעבור עד 20 דקות בעומס עד שרואים שיפור משמעותי בביצועים. Bigtable משנה את גודל הצמתים באשכול בהתאם לעומס שמופעל עליהם.
כשמקטינים את מספר הצמתים באשכול כדי לבצע הקטנה, מומלץ לא להקטין את גודל האשכול ביותר מ-10% בפרק זמן של 10 דקות, כדי למזער את העליות החדות בערכי השהייה.
האשכול של Bigtable משתמש בדיסקים מסוג HDD. ברוב המקרים, כדאי להשתמש בדיסקים מסוג SSD באשכול, כי הביצועים שלהם טובים משמעותית מאלה של דיסקים מסוג HDD. פרטים נוספים זמינים במאמר בחירה בין אחסון SSD לבין אחסון HDD.
יש בעיות בחיבור לרשת. בעיות ברשת יכולות להקטין את קצב העברת הנתונים ולגרום לכך שפעולות קריאה וכתיבה יימשכו זמן רב יותר מהרגיל. בפרט, יכול להיות שתיתקלו בבעיות אם הלקוחות שלכם לא פועלים באותו אזור כמו אשכול Bigtable, או אם הלקוחות שלכם פועלים מחוץ ל- Google Cloud.
אתם משתמשים בשכפול, אבל האפליקציה שלכם משתמשת בספריית לקוח לא מעודכנת. אם אתם מבחינים בזמן אחזור ארוך יותר אחרי הפעלת השכפול, ודאו שספריית הלקוח של Cloud Bigtable שבה האפליקציה שלכם משתמשת מעודכנת. יכול להיות שגרסאות קודמות של ספריות הלקוח לא עברו אופטימיזציה לתמיכה בשכפול. במאמר ספריות לקוח של Cloud Bigtable אפשר למצוא את מאגר GitHub של ספריית הלקוח, שבו אפשר לבדוק את הגרסה ולשדרג אותה אם צריך.
הפעלתם שכפול אבל לא הוספתם עוד צמתים לאשכולות. במופע שמשתמש בשכפול, כל אשכול צריך לטפל בעבודת השכפול בנוסף לעומס שהוא מקבל מהאפליקציות. אשכולות עם הקצאת יתר של משאבים עלולים לגרום לזמן אחזור מוגבר. כדי לוודא זאת, אפשר לבדוק את התרשימים של השימוש במעבד של המופע במסוף Google Cloud .
עומסי עבודה שונים יכולים לגרום לשינויים בביצועים, ולכן כדי לקבל את נקודות ההשוואה המדויקות ביותר, מומלץ לבצע בדיקות עם עומסי העבודה שלכם.
הפעלות במצב התחלתי וערכי QPS נמוכים
הפעלות במצב התחלתי (cold start) וערכי QPS נמוכים יכולים להגדיל את זמן האחזור. הביצועים של Bigtable הכי טובים עם טבלאות גדולות שניגשים אליהן לעיתים קרובות. לכן, אם מתחילים לשלוח בקשות אחרי תקופה של חוסר שימוש (הפעלה במצב התחלתי), יכול להיות שתבחינו בזמן אחזור גבוה בזמן ש-Bigtable יוצר מחדש את החיבורים. זמן האחזור גם גבוה יותר כשערך ה-QPS נמוך.
אם קצב השאילתות לשנייה נמוך, או אם אתם יודעים שלפעמים תשלחו בקשות לטבלת Bigtable אחרי תקופה של חוסר פעילות, נסו את האסטרטגיות הבאות כדי לשמור על החיבור פעיל ולמנוע זמן אחזור ארוך.
- לשלוח לטבלה תנועה מלאכותית בקצב נמוך בכל זמן.
- מגדירים את מאגר החיבורים כדי לוודא שקצב השאילתות הקבוע לשנייה ישמור על פעילות המאגר.
בתקופות שבהן ערך ה-QPS נמוך, מספר השגיאות ש-Bigtable מחזירה רלוונטי יותר מאחוז הפעולות שמחזירות שגיאה.
הפעלה במצב התחלתי (cold start) בזמן אתחול הלקוח. אם אתם משתמשים בגרסה של לקוח Cloud Bigtable ל-Java שקודמת לגרסה 2.17.1, אתם יכולים להפעיל רענון ערוצים. בגרסאות מאוחרות יותר, רענון הערוצים מופעל כברירת מחדל. רענון הערוץ כולל שתי פעולות:
- כשהלקוח מאותחל, הוא מכין את הערוץ לפני שליחת הבקשות הראשונות.
- השרת מנתק חיבורים ארוכי טווח כל שעה. התכונה 'הכנת ערוצים' מחליפה מראש ערוצים שתוקף השימוש בהם עומד לפוג.
עם זאת, הפעולה הזו לא תשאיר את הערוץ פעיל בתקופות של חוסר פעילות.
איך Bigtable מבצע אופטימיזציה של הנתונים לאורך זמן
כדי לאחסן את נתוני הבסיס של כל אחת מהטבלאות, Bigtable מחלק את הנתונים למספר טאבלטים שאפשר להעביר בין הצמתים באשכול Bigtable. שיטת האחסון הזו מאפשרת ל-Bigtable להשתמש בשתי אסטרטגיות לאופטימיזציה של הנתונים לאורך זמן:
- ב-Bigtable, בערך אותה כמות של נתונים מאוחסנת בכל צומת של Bigtable.
- Bigtable מחלק את פעולות הקריאה והכתיבה באופן שווה בין כל הצמתים של Bigtable.
לפעמים האסטרטגיות האלה סותרות. לדוגמה, אם שורות של טאבלט מסוים נקראות בתדירות גבוהה מאוד, יכול להיות ש-Bigtable ישמור את הטאבלט הזה בצומת משלו, גם אם זה יגרום לכך שחלק מהצמתים יאחסנו יותר נתונים מאחרים.
כחלק מהתהליך הזה, יכול להיות ש-Bigtable יפצל טאבלט לשני טאבלטים קטנים יותר או יותר, כדי להקטין את הגודל שלו או כדי לבודד שורות פעילות בתוך טאבלט קיים.
בקטעים הבאים מוסבר על כל אחת מהשיטות האלה בפירוט.
חלוקת כמות הנתונים בין הצמתים
כשכותבים נתונים לטבלה ב-Bigtable, המערכת מפצלת את הנתונים בטבלה ל-tablets. כל טאבלט מכיל טווח רציף של שורות בטבלה.
אם כתבתם לטבלה פחות מכמה GB של נתונים, Bigtable מאחסן את כל ה-tablet בצומת יחיד באשכול:
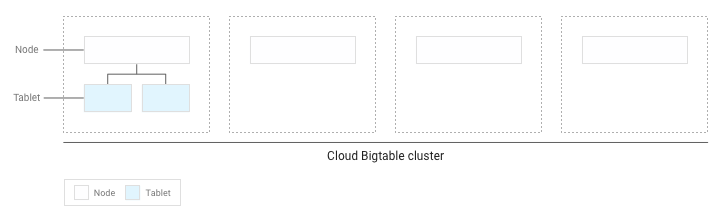
ככל שמצטברים יותר טאבלטים, Bigtable מעביר חלק מהם לצמתים אחרים באשכול כדי לאזן את כמות הנתונים בצורה שווה יותר באשכול:
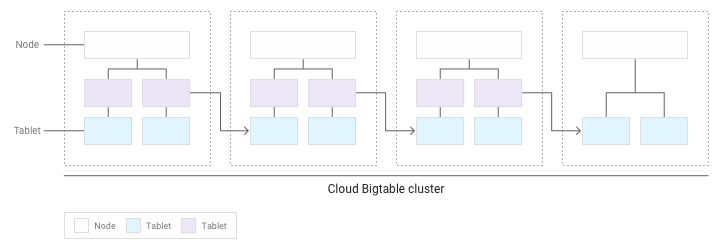
חלוקת פעולות קריאה וכתיבה באופן שווה בין הצמתים
אם תכננתם את הסכימה בצורה נכונה, פעולות הקריאה והכתיבה אמורות להתחלק באופן שווה יחסית בכל הטבלה. עם זאת, יש מקרים שבהם אין ברירה אלא לגשת לשורות מסוימות בתדירות גבוהה יותר מאשר לשורות אחרות. Bigtable עוזר לכם להתמודד עם המקרים האלה על ידי התחשבות בפעולות קריאה וכתיבה כשמאזנים טאבלטים בין צמתים.
לדוגמה, נניח ש-25% מהקריאות מופנות למספר קטן של טאבלטים באשכול, והקריאות מתפזרות באופן שווה בין כל הטאבלטים האחרים:
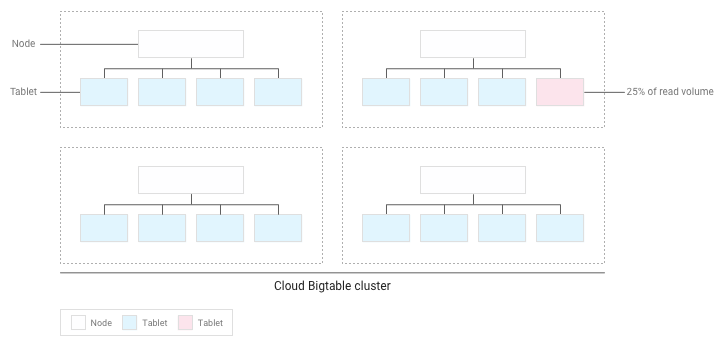
Bigtable יחלק מחדש את הטבליות הקיימות כך שפעולות הקריאה יתפרסו באופן שווה ככל האפשר בכל האשכול:
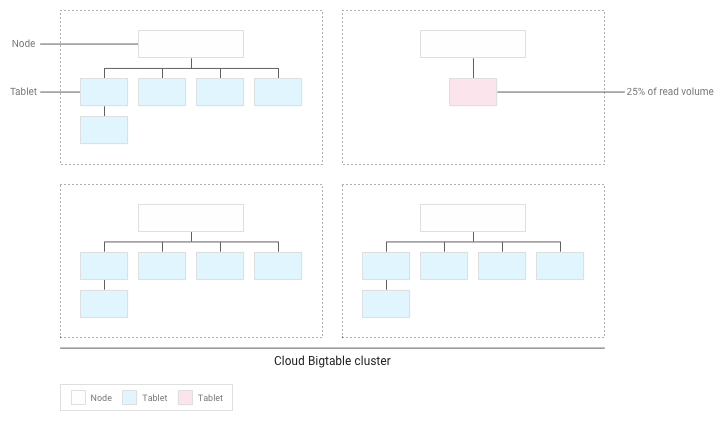
בדיקת הביצועים באמצעות Bigtable
אם אתם מריצים בדיקת ביצועים לאפליקציה שמסתמכת על Bigtable, כדאי לפעול לפי ההנחיות הבאות כשמתכננים ומבצעים את הבדיקה:
- חשוב לבדוק עם מספיק נתונים.
- אם הטבלאות במופע הייצור מכילות סך של 100 GB של נתונים או פחות לכל צומת, כדאי לבצע בדיקה עם טבלה שמכילה את אותה כמות נתונים.
- אם הטבלאות מכילות יותר מ-100GB של נתונים לכל צומת, צריך לבדוק עם טבלה שמכילה לפחות 100GB של נתונים לכל צומת. לדוגמה, אם במופע הייצור יש אשכול אחד עם ארבעה צמתים, והטבלאות במופע מכילות נתונים בנפח כולל של 1TB, צריך להריץ את הבדיקה באמצעות טבלה בנפח של 400GB לפחות.
- בודקים עם טבלה אחת.
- חשוב להקפיד על ניצול נפח האחסון המומלץ לכל צומת. פרטים נוספים זמינים במאמר בנושא ניצול נפח האחסון בכל צומת.
- לפני שמבצעים בדיקה, מריצים בדיקה מקדימה אינטנסיבית למשך כמה דקות. השלב הזה מאפשר ל-Bigtable לאזן את הנתונים בין הצמתים על סמך דפוסי הגישה שהוא מזהה.
- מריצים את הבדיקה למשך 10 דקות לפחות. השלב הזה מאפשר ל-Bigtable לבצע אופטימיזציה נוספת של הנתונים, ועוזר להבטיח שתבדקו קריאות מהדיסק וגם קריאות מהזיכרון במטמון.
- בדיקות של רמת הביניים בזיכרון (גרסת Preview): חשוב לוודא שמשך הבדיקה מספיק כדי לאכלס את רמת הביניים בזיכרון בקריאות.
פתרון בעיות בביצועים
אם אתם חושבים ש-Bigtable עלול ליצור צוואר בקבוק בביצועים של האפליקציה, הקפידו לבדוק את כל הדברים הבאים:
- בודקים את הסריקות של Key Visualizer לטבלה. הכלי Key Visualizer ל-Bigtable יוצר נתוני סריקה חדשים כל 15 דקות, שבהם מוצגים דפוסי השימוש בכל טבלה באשכול. הכלי Key Visualizer מאפשר לבדוק אם דפוסי השימוש גורמים לתוצאות לא רצויות, כמו נקודות חמות בשורות ספציפיות או שימוש מוגזם במעבד. מידע נוסף מופיע במאמר שימוש בכלי Key Visualizer.
- מוסיפים הערות לקוד שמבצע קריאות וכתיבות ב-Bigtable. אם בעיית הביצועים נעלמת, כנראה שאתם משתמשים ב-Bigtable באופן שמוביל לביצועים לא אופטימליים. אם בעיית הביצועים נמשכת, כנראה שהבעיה לא קשורה ל-Bigtable.
חשוב ליצור כמה שפחות לקוחות. יצירת לקוח ל-Bigtable היא פעולה יקרה יחסית. לכן, כדאי ליצור את המספר הקטן ביותר האפשרי של לקוחות:
- אם אתם משתמשים בשכפול או בפרופילי אפליקציות כדי לזהות סוגים שונים של תנועה למופע שלכם, אתם צריכים ליצור לקוח אחד לכל פרופיל אפליקציה ולשתף את הלקוחות באפליקציה.
- אם אתם לא משתמשים בשכפול או בפרופילים של אפליקציות, אתם צריכים ליצור לקוח יחיד ולשתף אותו בכל האפליקציה.
אם אתם משתמשים בלקוח HBase ל-Java, אתם יוצרים אובייקט
Connectionולא לקוח, ולכן כדאי ליצור כמה שפחות חיבורים.חשוב לוודא שאתם קוראים וכותבים שורות רבות ושונות בטבלה. הביצועים של Bigtable הכי טובים כשפעולות הקריאה והכתיבה מתבצעות באופן שווה בכל הטבלה. כך Bigtable יכול לחלק את עומס העבודה בין כל הצמתים באשכול. אם פעולות הקריאה והכתיבה לא יתפרסו על כל הצמתים של Bigtable, הביצועים ייפגעו.
אם אתם קוראים וכותבים רק מספר קטן של שורות, יכול להיות שתצטרכו לתכנן מחדש את הסכימה כדי שהקריאות והכתיבות יתחלקו בצורה שווה יותר.
מוודאים שרואים בערך את אותם ביצועים עבור קריאות וכתיבות. אם אתם מגלים שפעולות הקריאה מהירות בהרבה מפעולות הכתיבה, יכול להיות שאתם מנסים לקרוא מפתחות שורות שלא קיימים, או טווח גדול של מפתחות שורות שמכיל רק מספר קטן של שורות.
כדי לבצע השוואה תקפה בין קריאות וכתיבות, כדאי לשאוף לכך שלפחות 90% מהקריאות יחזירו תוצאות תקפות. בנוסף, אם קוראים טווח גדול של מפתחות שורות, כדאי למדוד את הביצועים על סמך המספר בפועל של השורות בטווח הזה, ולא על סמך המספר המקסימלי של השורות שיכולות להיות קיימות.
משתמשים בסוג הנכון של בקשות כתיבה לנתונים. בחירה בדרך האופטימלית לכתיבת הנתונים עוזרת לשמור על ביצועים גבוהים.
בדיקת זמן האחזור של שורה אחת אם אתם מבחינים בחביון לא צפוי כשאתם שולחים בקשות
ReadRows, אתם יכולים לבדוק את החביון של השורה הראשונה בבקשה כדי לצמצם את הסיבה. כברירת מחדל, זמן התגובה הכולל של בקשתReadRowsכולל את זמן התגובה של כל שורה בבקשה, וגם את זמן העיבוד בין השורות. אם זמן האחזור הכולל גבוה אבל זמן האחזור של השורה הראשונה נמוך, זה מצביע על כך שזמן האחזור נגרם בגלל מספר הבקשות או זמן העיבוד, ולא בגלל בעיה ב-Bigtable.אם אתם משתמשים בספריית הלקוח של Bigtable ל-Java, תוכלו לראות את המדד
read_rows_first_row_latencyבGoogle Cloud מסוף Metrics Explorer אחרי הפעלת מדדים בצד הלקוח.משתמשים בפרופיל אפליקציה נפרד לכל עומס עבודה. אם נתקלתם בבעיות בביצועים אחרי הוספה של עומס עבודה חדש, צרו פרופיל אפליקציה חדש לעומס העבודה החדש. לאחר מכן תוכלו לעקוב אחרי מדדים של פרופילי האפליקציות בנפרד כדי לפתור בעיות נוספות. במאמר איך פרופילים של אפליקציות פועלים מוסבר למה מומלץ להשתמש בכמה פרופילים של אפליקציות.
מפעילים מדדים בצד הלקוח. אתם יכולים להגדיר מדדים בצד הלקוח כדי לבצע אופטימיזציה ולפתור בעיות בביצועים. לדוגמה, מכיוון ש-Bigtable פועל בצורה הכי טובה עם QPS גבוה שמפוזר באופן שווה, עלייה בזמן האחזור של P100 (מקסימום) עבור אחוז קטן של בקשות לא בהכרח מצביעה על בעיית ביצועים גדולה יותר ב-Bigtable. מדדים בצד הלקוח יכולים לתת לכם תובנות לגבי החלק במחזור החיים של הבקשה שעלול לגרום לחביון.
חשוב לוודא שהאפליקציה צורכת בקשות קריאה לפני שהן פגות תוקף. אם האפליקציה שלכם מעבדת נתונים במהלך קריאת נתונים, קיים סיכון שזמן האחזור של הבקשה יפוג לפני שתקבלו את כל התשובות מהשיחה. התוצאה היא הודעה
ABORTED. אם השגיאה הזו מופיעה, צריך לצמצם את כמות העיבוד במהלך קריאת הנתונים.
המאמרים הבאים
- איך מעצבים סכימה של Bigtable
- איך עוקבים אחרי הביצועים של Bigtable
- כך פותרים בעיות בכלי Key Visualizer
- כך פותרים בעיות שקשורות לזמן האחזור
- אפשר לראות קוד לדוגמה להוספת צמתים באופן פרוגרמטי לאשכול Bigtable.