
בדף הזה מתוארים שיקולים ותהליכים להעברת נתונים מאשכול Apache HBase למופע Bigtable ב-Google Cloud.
כדי לבצע את התהליך שמתואר בדף הזה, צריך להעביר את האפליקציה למצב אופליין. אם רוצים לבצע העברה ללא השבתה, אפשר להיעזר בהנחיות להעברה אונליין במאמר שכפול מ-HBase ל-Bigtable.
לפני שמתחילים בהעברה הזו, כדאי לקחת בחשבון את ההשלכות על הביצועים, את עיצוב הסכימה של Bigtable, את הגישה לאימות ולהרשאה ואת מערך התכונות של Bigtable.
נקודות שכדאי לשים לב אליהן לפני ההעברה
בקטע הזה יש כמה הצעות לדברים שכדאי לבדוק ולחשוב עליהם לפני שמתחילים בהעברה.
ביצועים
במהלך עומס עבודה רגיל, הביצועים של Bigtable צפויים מאוד. לפני שמעבירים את הנתונים, חשוב להבין את הגורמים שמשפיעים על הביצועים של Bigtable.
עיצוב סכימה של Bigtable
ברוב המקרים, אפשר להשתמש באותו עיצוב סכימה ב-Bigtable כמו ב-HBase. אם רוצים לשנות את הסכימה או אם תרחיש השימוש משתנה, כדאי לעיין במושגים שמפורטים במאמר תכנון הסכימה לפני העברת הנתונים.
אימות והרשאה
לפני שמתכננים את בקרת הגישה ל-Bigtable, כדאי לעיין בתהליכי האימות וההרשאה הקיימים של HBase.
Bigtable משתמש במנגנונים סטנדרטיים של Google Cloudלאימות ובניהול זהויות והרשאות גישה (IAM) כדי לספק בקרת גישה, ולכן צריך להמיר את ההרשאה הקיימת ב-HBase ל-IAM. אפשר למפות את קבוצות Hadoop הקיימות שמספקות מנגנוני בקרת גישה ל-HBase לחשבונות שירות שונים.
ב-Bigtable אפשר לשלוט בגישה ברמת הפרויקט, המופע והטבלה. מידע נוסף מופיע במאמר בנושא בקרת גישה.
דרישה לגבי זמן השבתה
הגישה להעברה שמתוארת בדף הזה כוללת העברה של האפליקציה למצב אופליין למשך ההעברה. אם העסק שלכם לא יכול להרשות לעצמו השבתה בזמן המעבר ל-Bigtable, כדאי לעיין בהנחיות בנושא העברה אונליין במאמר שכפול מ-HBase ל-Bigtable.
העברה של HBase ל-Bigtable
כדי להעביר את הנתונים מ-HBase ל-Bigtable, מייצאים תמונת מצב של HBase לכל טבלה ל-Cloud Storage, ואז מייבאים את הנתונים ל-Bigtable. השלבים האלה מיועדים לאשכול HBase יחיד, והם מתוארים בפירוט בכמה מהקטעים הבאים.
- מפסיקים לשלוח פעולות כתיבה לאשכול HBase.
- מצלמים תמונות של הטבלאות באשכול HBase.
- מייצאים את קובצי התמונות ל-Cloud Storage.
- חישוב של גיבובים וייצוא שלהם ל-Cloud Storage.
- יוצרים טבלאות יעד ב-Bigtable.
- מייבאים את נתוני HBase מ-Cloud Storage אל Bigtable.
- מאמתים את הנתונים שיובאו.
- המסלול נכתב ל-Bigtable.
לפני שמתחילים
יוצרים קטגוריה של Cloud Storage כדי לאחסן את התמונות. יוצרים את קטגוריית האחסון באותו מיקום שבו מתכננים להפעיל את משימת Dataflow.
יוצרים מופע Bigtable כדי לאחסן את הטבלאות החדשות.
מזהים את אשכול Hadoop שממנו מייצאים. אפשר להריץ את העבודות להעברה ישירות באשכול HBase או באשכול Hadoop נפרד שיש לו קישוריות לרשת של Namenode ו-Datanodes באשכול HBase.
מתקינים ומגדירים את המחבר של Cloud Storage בכל צומת באשכול Hadoop, וגם במארח שממנו מתבצעת הפעלת המשימה. הוראות מפורטות להתקנה מופיעות במאמר התקנת המחבר של Cloud Storage.
פותחים מעטפת פקודה במארח שיכול להתחבר לאשכול HBase ולפרויקט Bigtable. כאן תצטרכו להשלים את השלבים הבאים.
כדי להשתמש בכלי לתרגום סכימות:
wget BIGTABLE_HBASE_TOOLS_URLמחליפים את
BIGTABLE_HBASE_TOOLS_URLבכתובת ה-URL שלJAR with dependenciesהאחרון שזמין במאגר Maven של הכלי. שם הקובץ דומה ל-https://repo1.maven.org/maven2/com/google/cloud/bigtable/bigtable-hbase-1.x-tools/1.24.0/bigtable-hbase-1.x-tools-1.24.0-jar-with-dependencies.jar.כדי למצוא את כתובת ה-URL או להוריד את קובץ ה-JAR באופן ידני:
- עוברים אל המאגר.
- לוחצים על מספר הגרסה העדכנית ביותר.
- מזהים את
JAR with dependencies file(בדרך כלל בחלק העליון). - לוחצים לחיצה ימנית ומעתיקים את כתובת ה-URL, או לוחצים כדי להוריד את הקובץ.
כדי להשתמש בכלי הייבוא:
wget BIGTABLE_BEAM_IMPORT_URLמחליפים את
BIGTABLE_BEAM_IMPORT_URLבכתובת ה-URL שלshaded JARהאחרון שזמין במאגר Maven של הכלי. שם הקובץ דומה ל-https://repo1.maven.org/maven2/com/google/cloud/bigtable/bigtable-beam-import/1.24.0/bigtable-beam-import-1.24.0-shaded.jar.כדי למצוא את כתובת ה-URL או להוריד את קובץ ה-JAR באופן ידני:
- עוברים אל המאגר.
- לוחצים על מספר הגרסה העדכנית ביותר.
- לוחצים על הורדות.
- מעבירים את העכבר מעל shaded.jar.
- לוחצים לחיצה ימנית ומעתיקים את כתובת ה-URL, או לוחצים כדי להוריד את הקובץ.
מגדירים את משתני הסביבה הבאים:
#Google Cloud export PROJECT_ID=PROJECT_ID export INSTANCE_ID=INSTANCE_ID export REGION=REGION export CLUSTER_NUM_NODES=CLUSTER_NUM_NODES #JAR files export TRANSLATE_JAR=TRANSLATE_JAR export IMPORT_JAR=IMPORT_JAR #Cloud Storage export BUCKET_NAME="gs://BUCKET_NAME" export MIGRATION_DESTINATION_DIRECTORY="$BUCKET_NAME/hbase-migration-snap" #HBase export ZOOKEEPER_QUORUM=ZOOKEPER_QUORUM export ZOOKEEPER_PORT=2181 export ZOOKEEPER_QUORUM_AND_PORT="$ZOOKEEPER_QUORUM:$ZOOKEEPER_PORT" export MIGRATION_SOURCE_DIRECTORY=MIGRATION_SOURCE_DIRECTORYמחליפים את מה שכתוב בשדות הבאים:
-
PROJECT_ID: Google Cloud הפרויקט שבו נמצא המופע -
INSTANCE_ID: המזהה של מופע Bigtable שאליו מייבאים את הנתונים -
REGION: אזור שמכיל אחד מהאשכולות במופע Bigtable. לדוגמה:northamerica-northeast2 -
CLUSTER_NUM_NODES: מספר הצמתים במופע Bigtable -
TRANSLATE_JAR: השם ומספר הגרסה של קובץ ה-JARbigtable hbase toolsשהורדתם מ-Maven. הערך צריך להיראות בערך כך:bigtable-hbase-1.x-tools-1.24.0-jar-with-dependencies.jar. -
IMPORT_JAR: השם ומספר הגרסה של קובץ ה-JARbigtable-beam-importשהורדתם מ-Maven. הערך צריך להיראות בערך כך:bigtable-beam-import-1.24.0-shaded.jar. -
BUCKET_NAME: השם של קטגוריית Cloud Storage שבה מאחסנים את התמונות של מצב המערכת -
ZOOKEEPER_QUORUM: מארח Zookeeper שהכלי יתחבר אליו, בפורמטhost1.myownpersonaldomain.com -
MIGRATION_SOURCE_DIRECTORY: הספרייה במארח HBase שמכילה את הנתונים שרוצים להעביר, בפורמטhdfs://host1.myownpersonaldomain.com:8020/hbase
-
(אופציונלי) כדי לוודא שהמשתנים הוגדרו בצורה נכונה, מריצים את הפקודה
printenvכדי לראות את כל משתני הסביבה.
הפסקת שליחת פעולות כתיבה ל-HBase
לפני שיוצרים תמונות מצב של טבלאות HBase, צריך להפסיק לשלוח פעולות כתיבה לאשכול HBase.
צילום תמונות מצב של טבלאות HBase
כשהנתונים כבר לא מוזנים לאשכול HBase, מצלמים תמונת מצב של כל טבלה שמתכננים להעביר ל-Bigtable.
בתחילה, לגיבוי יש טביעת רגל מינימלית באשכול HBase, אבל עם הזמן הוא עשוי לגדול לאותו גודל כמו הטבלה המקורית. התמונה לא צורכת משאבי CPU.
מריצים את הפקודה הבאה לכל טבלה, ומשתמשים בשם ייחודי לכל תמונת מצב:
echo "snapshot 'TABLE_NAME', 'SNAPSHOT_NAME'" | hbase shell -n
מחליפים את מה שכתוב בשדות הבאים:
-
TABLE_NAME: השם של טבלת HBase שממנה מייצאים נתונים. -
SNAPSHOT_NAME: השם של קובץ ה-snapshot החדש
ייצוא תמונות המצב של HBase ל-Cloud Storage
אחרי שיוצרים את התמונות, צריך לייצא אותן. כשמריצים משימות ייצוא באשכול HBase של סביבת ייצור, צריך לעקוב אחרי האשכול ומשאבי HBase אחרים כדי לוודא שהאשכולות יישארו במצב תקין.
לכל תמונת מצב שרוצים לייצא, מריצים את הפקודה הבאה:
hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot \
-Dhbase.zookeeper.quorum=$ZOOKEEPER_QUORUM_AND_PORT -snapshot SNAPSHOT_NAME \
-copy-from $MIGRATION_SOURCE_DIRECTORY \
-copy-to $MIGRATION_DESTINATION_DIRECTORY/data
מחליפים את SNAPSHOT_NAME בשם של התמונה לגיבוי שרוצים לייצא.
חישוב וייצוא של גיבובים (hash)
לאחר מכן, יוצרים גיבובים לשימוש באימות אחרי שההעברה תושלם.
HashTable הוא כלי אימות שמסופק על ידי HBase. הכלי מחשב גיבובים לטווחים של שורות ומייצא אותם לקבצים. אפשר להריץ משימת sync-table בטבלת היעד כדי להשוות את הגיבובים ולוודא שהנתונים שהועברו תקינים.
מריצים את הפקודה הבאה לכל טבלה שייצאתם:
hbase org.apache.hadoop.hbase.mapreduce.HashTable --batchsize=32000 --numhashfiles=20 \
TABLE_NAME $MIGRATION_DESTINATION_DIRECTORY/hashtable/TABLE_NAME
מחליפים את מה שכתוב בשדות הבאים:
-
TABLE_NAME: השם של טבלת HBase שיצרתם עבורה קובץ snapshot וייצאתם אותה
יצירת טבלאות יעד
בשלב הבא, יוצרים טבלת יעד בכל מופע Bigtable שאליו ייצאתם את התמונה. משתמשים בחשבון שיש לו הרשאה למופע bigtable.tables.create.
במדריך הזה נעשה שימוש בכלי לתרגום סכימות של Bigtable, שיוצר את הטבלה באופן אוטומטי. עם זאת, אם אתם לא רוצים שסכימת Bigtable תהיה זהה לסכימת HBase, אתם יכולים ליצור טבלה באמצעות כלי שורת הפקודה cbt או במסוף Google Cloud .
כלי תרגום הסכימה של Bigtable לוכד את הסכימה של טבלת HBase, כולל שם הטבלה, משפחות העמודות, מדיניות איסוף האשפה ופיצולים. אחר כך הוא יוצר טבלה דומה ב-Bigtable.
עבור כל טבלה שרוצים לייבא, מריצים את הפקודה הבאה כדי להעתיק את הסכימה מ-HBase ל-Bigtable.
java \
-Dgoogle.bigtable.project.id=$PROJECT_ID \
-Dgoogle.bigtable.instance.id=$INSTANCE_ID \
-Dgoogle.bigtable.table.filter=TABLE_NAME \
-Dhbase.zookeeper.quorum=$ZOOKEEPER_QUORUM \
-Dhbase.zookeeper.property.clientPort=$ZOOKEEPER_PORT \
-jar $TRANSLATE_JAR
מחליפים את TABLE_NAME בשם של טבלת HBase שרוצים לייבא. כלי התרגום של הסכימה משתמש בשם הזה עבור טבלת Bigtable החדשה.
אפשר גם להחליף את TABLE_NAME בביטוי רגולרי, כמו ".*", שמייצג את כל הטבלאות שרוצים ליצור, ואז להריץ את הפקודה רק פעם אחת.
ייבוא נתוני HBase ל-Bigtable באמצעות Dataflow
אחרי שיש לכם טבלה שאליה אפשר להעביר את הנתונים, אתם יכולים לייבא ולאמת את הנתונים.
טבלאות לא דחוסות
אם טבלאות HBase שלכם לא דחוסות, מריצים את הפקודה הבאה לכל טבלה שרוצים להעביר:
java -jar $IMPORT_JAR importsnapshot \
--runner=DataflowRunner \
--project=$PROJECT_ID \
--bigtableInstanceId=$INSTANCE_ID \
--bigtableTableId=TABLE_NAME \
--hbaseSnapshotSourceDir=$MIGRATION_DESTINATION_DIRECTORY/data \
--snapshotName=SNAPSHOT_NAME \
--stagingLocation=$MIGRATION_DESTINATION_DIRECTORY/staging \
--tempLocation=$MIGRATION_DESTINATION_DIRECTORY/temp \
--maxNumWorkers=$(expr 3 \* $CLUSTER_NUM_NODES) \
--region=$REGION
מחליפים את מה שכתוב בשדות הבאים:
-
TABLE_NAME: שם טבלת ה-HBase שאתם מייבאים. הכלי לתרגום סכימות משתמש בשם הזה עבור טבלת Bigtable החדשה. אין תמיכה בשמות טבלאות חדשים. -
SNAPSHOT_NAME: השם שהקציתם לתמונת המצב של הטבלה שאתם מייבאים
אחרי שמריצים את הפקודה, הכלי משחזר את תמונת המצב של HBase לקטגוריה של Cloud Storage, ואז מתחיל את עבודת הייבוא. תהליך השחזור של התמונה המיידית עשוי להימשך כמה דקות, בהתאם לגודל התמונה המיידית.
כשמייבאים נתונים, חשוב לזכור את הטיפים הבאים:
- כדי לשפר את הביצועים של טעינת הנתונים, חשוב להגדיר את
maxNumWorkers. הערך הזה עוזר לוודא שלמשימת הייבוא יש מספיק כוח מחשוב כדי להסתיים בפרק זמן סביר, אבל לא יותר מדי כוח מחשוב כדי שלא ייווצר עומס יתר על מופע Bigtable.- אם אתם לא משתמשים במופע Bigtable גם לעומס עבודה אחר, תכפילו את מספר הצמתים במופע Bigtable ב-3 ותשתמשו במספר הזה בשביל
maxNumWorkers. - אם אתם משתמשים במופע לעומס עבודה אחר בזמן שאתם מייבאים את נתוני HBase, כדאי להקטין את הערך של
maxNumWorkersבהתאם.
- אם אתם לא משתמשים במופע Bigtable גם לעומס עבודה אחר, תכפילו את מספר הצמתים במופע Bigtable ב-3 ותשתמשו במספר הזה בשביל
- שימוש בסוג ברירת המחדל של העובד.
- במהלך הייבוא, כדאי לעקוב אחרי השימוש ב-CPU במופע Bigtable. אם ניצול המעבד (CPU) במופע Bigtable גבוה מדי, יכול להיות שתצטרכו להוסיף עוד צמתים. יכול להיות שיחלפו עד 20 דקות עד שהיתרון בביצועים של הצמתים הנוספים יורגש באשכול.
מידע נוסף על מעקב אחרי מופע Bigtable זמין במאמר בנושא מעקב.
טבלאות דחוסות בפורמט Snappy
אם מייבאים טבלאות דחוסות בפורמט Snappy, צריך להשתמש בתמונה של קונטיינר מותאם אישית בצינור עיבוד הנתונים של Dataflow. קובץ אימג' של קונטיינר המותאם אישית שבו אתם משתמשים כדי לייבא נתונים דחוסים ל-Bigtable מספק תמיכה בספריית הדחיסה המקורית של Hadoop. כדי להשתמש ב-Dataflow Runner v2, צריך להשתמש ב-Apache Beam SDK מגרסה 2.30.0 ואילך, ובספריית הלקוח של HBase ל-Java מגרסה 2.3.0 ואילך.
כדי לייבא טבלאות דחוסות בפורמט Snappy, מריצים את אותה פקודה שמריצים עבור טבלאות לא דחוסות, אבל מוסיפים את האפשרות הבאה:
--enableSnappy=true
אימות הנתונים המיובאים ב-Bigtable
כדי לאמת את הנתונים המיובאים, צריך להריץ את המשימה sync-table. המשימה sync-table מחשבת גיבובים לטווחים של שורות ב-Bigtable, ואז מתאימה אותם לפלט של HashTable שחישבתם קודם.
כדי להריץ את המשימה sync-table, מריצים את הפקודה הבאה במעטפת הפקודה:
java -jar $IMPORT_JAR sync-table \
--runner=dataflow \
--project=$PROJECT_ID \
--bigtableInstanceId=$INSTANCE_ID \
--bigtableTableId=TABLE_NAME \
--outputPrefix=$MIGRATION_DESTINATION_DIRECTORY/sync-table/output-TABLE_NAME-$(date +"%s") \
--stagingLocation=$MIGRATION_DESTINATION_DIRECTORY/sync-table/staging \
--hashTableOutputDir=$MIGRATION_DESTINATION_DIRECTORY/hashtable/TABLE_NAME \
--tempLocation=$MIGRATION_DESTINATION_DIRECTORY/sync-table/dataflow-test/temp \
--region=$REGION
מחליפים את TABLE_NAME בשם של טבלת HBase שרוצים לייבא.
כשהעבודה sync-table מסתיימת, פותחים את הדף פרטי עבודה של Dataflow ובודקים את הקטע Custom counters של העבודה. אם עבודת הייבוא מייבאת את כל הנתונים בהצלחה, הערך של ranges_matched הוא ערך כלשהו והערך של ranges_not_matched הוא 0.
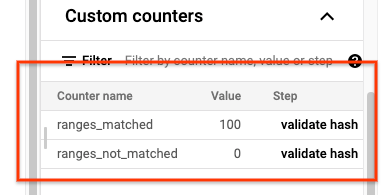
אם הערך של ranges_not_matched הוא מספר, פותחים את הדף Logs, בוחרים באפשרות Worker Logs ומסננים לפי Mismatch on range. הפלט של היומנים האלה שניתן לקריאה על ידי מכונה מאוחסן ב-Cloud Storage ביעד הפלט שאתם יוצרים באפשרות outputPrefix של טבלת הסנכרון.
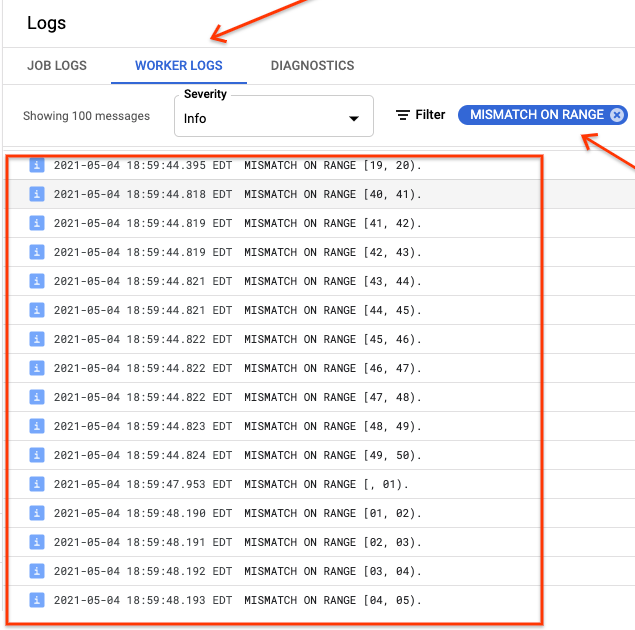
אפשר לנסות שוב את פעולת הייבוא או לכתוב סקריפט לקריאת קובצי הפלט כדי לזהות איפה היו אי התאמות. כל שורה בקובץ הפלט היא רשומה של JSON שעברה סריאליזציה של טווח לא תואם.
כתיבת מסלול ל-Bigtable
אחרי שמאמתים את הנתונים של כל טבלה באשכול, אפשר להגדיר את האפליקציות כך שכל התנועה שלהן תנותב ל-Bigtable, ואז להוציא משימוש את מופע HBase.
אחרי שההעברה מסתיימת, אפשר למחוק את התמונות של מצב המערכת במופע HBase.