
從 Aerospike 遷移至 Bigtable
本文將逐步說明如何將資料從 Aerospike 遷移至 Bigtable。並說明如何使用開放原始碼工具 (例如轉接程式庫) 執行遷移作業。
開始遷移前,請先熟悉適用於 Aerospike 使用者的 Bigtable。
遷移作業總覽
您可以將資料從 Aerospike 遷移至 Bigtable,停機時間最短或完全不停機。
下圖概述遷移步驟:
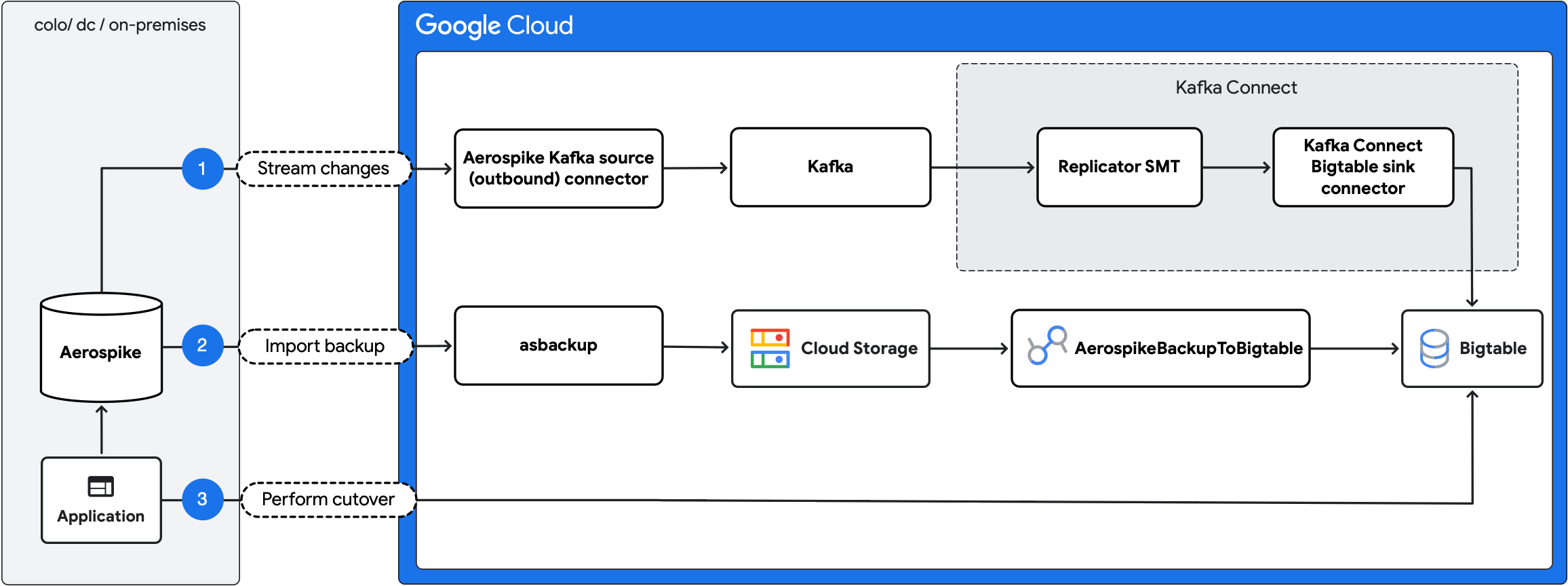
- 串流持續變更:使用 Aerospike Kafka 來源 (輸出) 連接器和 Kafka Connect Bigtable 接收器連接器,將 Aerospike 的持續更新複製到 Bigtable。
- 匯入備份:建立 Aerospike 備份,然後使用
AerospikeBackupToBigtableDataflow 工作匯入 Bigtable。 - 執行轉換:將應用程式流量移至 Bigtable。
遷移範圍和相容性
由於 Bigtable 是以原始位元組運作,而非以型別容器運作,因此遷移程序會將 Aerospike 功能和特性對應至相容的 Bigtable 結構。轉接程式庫提供必要的工具,可達成結構相容性並解決缺口,例如物件序列化。不過,由於系統間存在根本差異,因此無法遷移特定功能,例如使用者定義的函式 (UDF)。
下表摘要說明遷移程序如何處理 Aerospike 功能。
| 功能 | 支援 | 說明 |
|---|---|---|
| Aerospike 混合式記憶體架構 (HMA) | 支援 | 已遷移至 SSD 儲存空間層或記憶體內層。Bigtable Enterprise Plus 版提供記憶體內儲存空間,適用於對延遲時間敏感的工作負載,這類工作負載需要類似 Aerospike 效能的毫秒以下回應時間。 |
純量 (Int、Float、String、Bool) |
支援 | 已遷移至 Bigtable 儲存格。 |
| 清單和地圖 | 支援 | 對應表必須有字串鍵。轉接程式庫會將清單和對照表序列化為不同的資料欄。 |
| 次要索引 | 部分支援 | 不會直接遷移。必須重新實作為非同步次要索引。 |
| 記錄層級的存留時間 (TTL) | 支援 | 在資料欄系列層級設定,或在 Bigtable 中模擬每個儲存格。 |
| UDF | 不支援 | 自訂伺服器端邏輯必須移至用戶端應用程式。 |
| HyperLogLog | 不支援 | 遷移程序不支援這項功能。 |
| GeoJSON | 不支援 | 遷移程序不支援這項功能。 |
| 記錄鍵 | 不支援 | 記錄鍵不會直接遷移。遷移作業會改用記錄摘要做為資料列索引鍵。 |
事前準備
開始遷移前,請先完成下列準備步驟,以降低風險並確保順利轉換:
- 驗證資料:確認 Aerospike 部署作業不會使用不支援的資料類型、次要索引或 UDF。為確保安全,您可以將資料的代表性子集匯入 Bigtable,並驗證結構定義設計。
- 佈建基礎架構:設定遷移管道所需的服務:Bigtable、Kafka 和 Kafka Connect。
- 容量規劃:為 Bigtable 佈建足夠的容量,以處理預期工作負載。選取靠近現有 Aerospike 叢集的區域。如需估算所需資源的指南,請參閱「瞭解 Bigtable 效能」。
- 儲存層:如果工作負載需要不到 1 毫秒的回應時間,請考慮使用 Bigtable 記憶體內層。這個層級會將資料儲存在 RAM 中,為讀取量大或對延遲時間敏感的應用程式提供最高效能。詳情請參閱「記憶體內層總覽」。
- 設定存取權和網路:指派適當的 Identity and Access Management (IAM) 角色,並確保網路連線。
- 啟用監控和錯誤回報:為新環境設定可觀測性,包括記錄、指標和快訊。
- 基準效能基準:記錄目前的系統效能,做為遷移後驗證效能的參考。
- 建立備份:完整備份 Aerospike 資料。
- 執行測試遷移:在嘗試執行實際遷移作業前,請先在預備環境中驗證設定。
遷移資料
請完成下列步驟,將資料從 Aerospike 遷移至 Bigtable。
啟動變更串流
啟用 Aerospike 變更串流後,Aerospike Kafka 來源 (輸出) 連接器就會開始將 Aerospike 記錄更新發布至 Kafka 主題。請確認 Kafka 有足夠的儲存空間可緩衝處理變更,並將連接器設為以 JSON 格式輸出資料。
以下是 Kafka 連接器設定範例:
service:
port: <port_to_run_on>
producer-props:
bootstrap.servers:
- <kafka_host>
format:
mode: json
metadata-key: metadata
routing:
mode: static
destination: <kafka_topic>
如要使用 Aerospike Kafka 來源 (輸出) 連接器與 Kafka 通訊,必須使用 Aerospike 跨資料中心複製 (XDR),透過高延遲連結非同步複製叢集變更。XDR 僅適用於 Aerospike Enterprise 版。如果您使用 Aerospike Community 版,請改用 Enterprise 版,或只使用 AerospikeBackupToBigtable Dataflow 工作執行離線遷移作業。
以下是 Aerospike 中 XDR 的設定範例:
xdr {
dc aerospike-kafka-source {
connector true
node-address-port <aerospike_connect_host> <aerospike_connect_port>
namespace <your_namespace_to_replicate> {
}
}
}
從 Aerospike 匯出資料
啟動變更串流後,請產生現有 Aerospike 資料集的備份。使用 asbackup 指令列工具,從 Aerospike 資料庫叢集建立備份。部分更新可能會同時出現在備份和變更串流中,這是正常現象,不會影響遷移作業。如要在還原期間允許平行匯入,請將備份資料分割成多個檔案。
將資料匯入 Bigtable
如要將備份資料匯入 Bigtable,請按照下列步驟操作:
- 將備份上傳至 Cloud Storage bucket。
- 執行
AerospikeBackupToBigtableDataflow 工作,將備份資料匯入 Bigtable。如果備份資料分割成多個檔案,這項工作會平行處理這些檔案。如要處理增加的寫入負載並維持最佳總處理量,請佈建額外的 Bigtable 資源。
將記錄更新套用至 Bigtable
將備份匯入 Bigtable 後,請使用 Kafka Connect Bigtable 接收器連接器,將 Kafka 中緩衝的記錄更新套用至 Bigtable。
將訊息翻譯為相容格式
Aerospike 遷移工具包括 Replicator SMT,該工具會在 Kafka Connect 中執行。複寫器會將 Aerospike Kafka 來源 (外送) 連接器發布的訊息,轉換為與目標接收器相容的格式,並將記錄寫入 Bigtable。 由於接收器預期的資料格式與 Aerospike 串流變更的方式不同,因此需要進行轉換。
下表可協助您預估達到特定處理量所需的機器資源:
| 記錄結構 | 處理量 | p99 延遲時間 |
|---|---|---|
| 平面式 | 每個 vCPU 每秒最多 3,700 筆記錄 | 300 毫秒 |
| 巢狀 | 每個 vCPU 每秒最多 2,600 筆記錄 | 300 毫秒 |
這些預估值假設 JSON 序列化記錄的大小為 1 KB。訊息結構越複雜,剖析時間就越長,也就是說,儲存在 Aerospike 記錄中的巢狀物件需要較長時間剖析。
您可以使用 consumer_lag 指標,確認處理佇列中的訊息數量,並測量複製延遲。當接收器處理主題上積壓的訊息時,消費者延遲會減少,直到接近零為止,此時接收器會近乎即時地處理 Aerospike 更新,讓您準備好轉換。您可以透過 sink-record-active-count 驗證已處理的郵件數量。
使用 Kafka Connect Bigtable 接收器連接器擷取訊息
Kafka Connect Bigtable 接收器連接器會將 Kafka 中的訊息擷取至 Bigtable。設定連接器時,請將 insert.mode 設為 REPLACE_IF_NEWEST,確保寫入 Bigtable 目標列的記錄是最新記錄。詳情請參閱「Kafka Connect Bigtable 接收器連接器設定」。
下表提供不同工作負載的延遲時間和所需運算資源指引:
| 記錄結構 | 處理量 | p99 延遲時間 |
|---|---|---|
| 平面式 | 每個 vCPU 每秒最多 3,700 筆記錄 | 74 毫秒 |
| 巢狀 | 每個 vCPU 每秒最多 3,700 筆記錄 | 100 毫秒 |
這些預估值假設 JSON 序列化記錄的大小為 1 KB。回報的延遲時間是接收器中的處理時間。假設向 Bigtable 發出寫入要求時,額外負荷約為 600 毫秒。
切換至 Bigtable
將應用程式切換為使用 Bigtable 做為主要資料庫。
為確保讀後寫入一致性,請暫時關閉應用程式,直到複製延遲時間達到零為止。確保不會遺失任何突變,且資料讀取反映最新狀態。
舉例來說,在轉換前不久套用至 Aerospike 的變異可能尚未複製到 Bigtable,導致讀取過時資料。為避免這種情況,請讓應用程式保持離線狀態,直到 consumer_lag 和 sink-record-active-count 指標達到 0 為止。所有待處理的變更傳播完畢後,請以 Bigtable 做為主要資料庫,重新啟動應用程式。
即時遷移可避免停機,但有下列限制:
- 在 Bigtable 中套用的變異不會複製回 Aerospike。
- 源自 Aerospike 的突變可能會延遲出現在 Bigtable 中。
- Aerospike 延遲的突變可能會覆寫 Bigtable 中較新的更新。
驗證 Deployment
部署完成後,請查看錯誤率、延遲和費用等指標,驗證應用程式效能。您也可以執行資料完整性檢查。
監控與觀測能力
在遷移期間監控下列指標:
- 總延遲時間:計算方式為 Kafka 消費者延遲時間加上
sink-record-active-count。這些指標會指出 Bigtable 比 Aerospike 落後多少。您必須先取得穩定的延遲值,才能將流量重新導向 Bigtable。 - CPU 和記憶體使用率:監控所有變更串流管道元件的 CPU 和記憶體使用率。
- Kafka 儲存空間容量:監控自行管理的 Kafka 部署作業容量。如果儲存空間已滿,就無法緩衝處理新事件,導致遷移作業失敗。
- 應用程式錯誤率:監控所有變更串流管道元素的錯誤率和錯誤輸出內容。
限制
以下各節將說明從 Aerospike 遷移資料至 Bigtable 時的注意事項。
遷移期間的資料一致性
使用 asbackup 工具產生 Aerospike 備份時,備份程序可能會排除備份期間修改的記錄,因為備份程序不支援原子備份。這項限制不會影響正確性,因為所有變更都會顯示在變更串流中。
將備份匯入 Bigtable 時,每個資料列都會寫入 0 的上次更新時間 (LUT) 時間戳記。
系統會將變更串流中的更新套用至匯入的備份檔。從串流寫入的資料列會使用 LUT 值做為 Bigtable 資料列時間戳記。接收器設定會讓時間戳記較新的更新覆寫較舊的更新。這樣一來,從串流重播的任何變更都會覆寫對應的資料列。
使用 LUT
遷移程序會使用 Aerospike XDR 複製變更,並依賴 LUT 解決衝突。由於 LUT 是根據節點的系統時鐘,因此可能不是嚴格單調。因此,過時的記錄有時可能會具有較新的 LUT,並覆寫較新的記錄。此外,發布至 Kafka 時,Aerospike Kafka 來源 (輸出) 連接器可能無法保留確切的訊息順序。因此,LUT 可做為權威版本標記,確保只有具有最新 LUT 的記錄會套用至 Bigtable。
如果在啟動變更串流後,但在產生備份前更新記錄,備份可能會擷取較新版本,而串流則包含較舊版本。舊版可能會暫時覆寫新版。不過,當後續的串流事件傳送正確的 LUT 時,系統就會還原最新版本。為避免不一致,請等到複製作業穩定後再執行轉換,且管道中最舊的未處理訊息必須比備份資料新。
資料驗證
遷移管道不會對傳輸中的資料執行總和檢查碼作業。如要進行端對端資料完整性檢查,請務必導入驗證。
疑難排解
下列各節說明遷移程序中可能發生的常見錯誤,並提供解決方法。
備份匯入錯誤
將 Aerospike 備份資料匯入 Bigtable 時,可能會遇到下列錯誤:
| 錯誤類型 | 原因 | 解決方案 |
|---|---|---|
| 備份檔案毀損 | 備份檔案無法讀取或含有損毀的記錄。匯入工作失敗。 | 檢查受影響的檔案是否有完整性問題。如果無法復原,請產生新的備份檔,然後重複匯入程序。 |
| Bigtable 寫入失敗 | 發生 Bigtable 連線或服務問題。匯入作業不會失敗。 | 系統會將失敗的記錄匯出為 JSON 格式的錯誤輸出檔案。請手動重新套用,或重試完整匯入工作。 |
| 不支援的資料 | 備份內容包含無法匯入 Bigtable 的項目。匯入作業不會失敗。 | 系統會在工作記錄中以警告形式,回報不支援的資料 (例如 UDF)。查看記錄,確認是否有不支援的項目。 |
備份匯入完成並解決無效記錄後,即可繼續套用變更串流。
變更串流錯誤
套用變更串流時,可能會在下列層級發生失敗:
- Replicator SMT 錯誤:SMT 無法轉換 Aerospike 產生的資料。
- 接收器錯誤:事件無法套用至 Bigtable。
在這兩種情況下,失敗的事件都會重新導向至專屬的 Kafka 主題。您可以記錄事件以供稽核,或使用自訂復原邏輯處理事件。
後續步驟
- 瞭解如何設計 Bigtable 結構定義。
- 請參閱這篇文章 Google Cloud,瞭解如何開始遷移。
- 瞭解您移轉大型資料集的策略。