
Migrar do Aerospike para o Bigtable
Este documento orienta o processo de migração de dados do Aerospike para o Bigtable. Ele descreve como usar ferramentas de código aberto, como a biblioteca de adaptadores, para realizar a migração.
Antes de iniciar a migração, familiarize-se com o Bigtable para usuários do Aerospike.
Visão geral da migração
É possível migrar seus dados do Aerospike para o Bigtable com tempo de inatividade mínimo ou zero.
O diagrama a seguir descreve as etapas da migração:
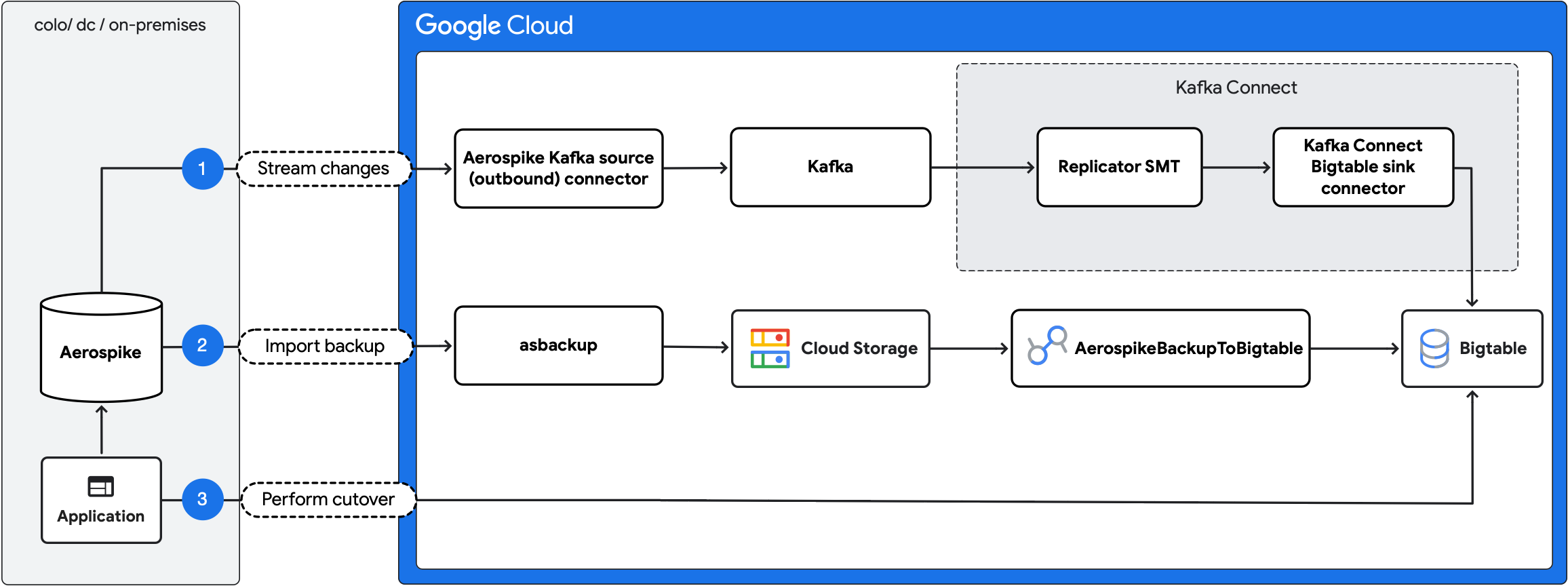
- Fazer streaming de mudanças em andamento:replique atualizações em andamento do Aerospike para o Bigtable usando o conector de origem do Aerospike Kafka (saída) e o conector de coletor do Kafka Connect Bigtable.
- Importar backup:crie um backup do Aerospike e importe-o para o Bigtable usando o job do Dataflow
AerospikeBackupToBigtable. - Realize a transição:mova o tráfego do aplicativo para o Bigtable.
Escopo e compatibilidade da migração
Como o Bigtable opera com bytes brutos em vez de intervalos tipados, o processo de migração envolve o mapeamento de recursos e funcionalidades do Aerospike para estruturas compatíveis do Bigtable. A biblioteca de adaptadores fornece as ferramentas necessárias para alcançar a compatibilidade estrutural e resolver lacunas, como a serialização de objetos. No entanto, alguns recursos, como funções definidas pelo usuário (UDFs), não podem ser migrados devido a diferenças fundamentais entre os sistemas.
A tabela a seguir resume como o processo de migração lida com os recursos do Aerospike.
| Recurso | Suporte | Descrição |
|---|---|---|
| Arquitetura de memória híbrida (HMA) do Aerospike | Com suporte | Migrados para o nível de armazenamento SSD ou para o nível na memória. A edição Enterprise Plus do Bigtable oferece acesso ao armazenamento na memória para cargas de trabalho sensíveis à latência que exigem tempos de resposta inferiores a um milissegundo, semelhantes ao desempenho do Aerospike. |
Escalares (Int, Float, String, Bool) |
Com suporte | Migradas para células do Bigtable. |
| Listas e mapas | Com suporte | Os mapas precisam ter chaves de string. As listas e os mapas são serializados em colunas separadas pela biblioteca do adaptador. |
| Índices secundários | Parcialmente compatível | Não são migradas diretamente. Precisa ser reimplementado como índices secundários assíncronos. |
| Time to live (TTL) no nível do registro | Com suporte | Configurado no nível do grupo de colunas ou simulado por célula no Bigtable. |
| UDFs | Sem suporte | A lógica personalizada do lado do servidor precisa ser movida para o aplicativo do lado do cliente. |
| HyperLogLog | Sem suporte | Indisponível no processo de migração. |
| GeoJSON | Sem suporte | Indisponível no processo de migração. |
| Chaves de registro | Sem suporte | As chaves de registro não são migradas diretamente. Em vez disso, a migração usa o resumo do registro como chave de linha. |
Antes de começar
Antes de iniciar a migração, conclua as etapas preparatórias a seguir para reduzir o risco e garantir uma transição tranquila:
- Valide seus dados:confirme se a implantação do Aerospike não depende de tipos de dados, índices secundários ou UDFs não compatíveis. Como proteção, importe um subconjunto representativo dos seus dados para o Bigtable e valide o design do esquema.
- Provisione a infraestrutura:configure os serviços necessários para o pipeline de migração: Bigtable, Kafka e Kafka Connect.
- Planejamento de capacidade: provisione o Bigtable com capacidade suficiente para processar a carga de trabalho esperada. Selecione uma região próxima ao cluster do Aerospike atual. Para orientações sobre como estimar os recursos necessários, consulte Noções básicas sobre o desempenho do Bigtable.
- Nível de armazenamento: para cargas de trabalho que exigem tempos de resposta inferiores a um milissegundo, considere usar o nível na memória do Bigtable. Essa camada armazena dados na RAM para oferecer o melhor desempenho para aplicativos com muitas leituras ou sensíveis à latência. Para mais informações, consulte Visão geral do nível na memória.
- Configure o acesso e a rede:atribua os papéis adequados do Identity and Access Management (IAM) e garanta a conectividade de rede.
- Ative o monitoramento e o Error Reporting:configure a observabilidade para o novo ambiente, incluindo geração de registros, métricas e alertas.
- Comparativo de mercado do desempenho da linha de base:registre o desempenho atual do sistema para fornecer uma referência para validação após a migração.
- Criar backups:crie um backup completo dos seus dados do Aerospike.
- Faça uma migração de teste:valide a configuração em um ambiente de preparo antes de tentar uma migração de produção.
Migrar dados
Siga estas etapas para migrar seus dados do Aerospike para o Bigtable.
Iniciar o fluxo de alterações
Quando você ativa o fluxo de mudanças do Aerospike, o conector de origem do Aerospike Kafka (de saída) começa a publicar as atualizações de registros do Aerospike em um tópico do Kafka. Verifique se o Kafka tem capacidade de armazenamento suficiente para armazenar em buffer as mudanças e configure o conector para gerar dados no formato JSON.
Confira a seguir um exemplo de configuração do conector do Kafka:
service:
port: <port_to_run_on>
producer-props:
bootstrap.servers:
- <kafka_host>
format:
mode: json
metadata-key: metadata
routing:
mode: static
destination: <kafka_topic>
A comunicação com o Kafka usando o conector de origem do Aerospike Kafka (de saída) exige a Replicação entre data centers (XDR, na sigla em inglês) do Aerospike, que replica de forma assíncrona as mudanças do cluster em links de maior latência. O XDR está disponível apenas na edição Enterprise do Aerospike. Se você usa o Aerospike Community Edition, mude para a Enterprise Edition ou faça uma migração off-line usando apenas o job do Dataflow AerospikeBackupToBigtable.
Um exemplo de configuração para XDR no Aerospike é assim:
xdr {
dc aerospike-kafka-source {
connector true
node-address-port <aerospike_connect_host> <aerospike_connect_port>
namespace <your_namespace_to_replicate> {
}
}
}
Exportar dados do Aerospike
Depois de iniciar o fluxo de alterações, gere um backup do conjunto de dados do Aerospike. Use a ferramenta de linha de comando asbackup para criar backups de um cluster de banco de dados do Aerospike. Algumas atualizações podem aparecer no backup e no fluxo de alterações, o que é esperado e não afeta a migração. Para permitir importações paralelas durante a restauração, divida os backups em vários arquivos.
Importar dados para o Bigtable
Para importar dados de backup para o Bigtable, faça o seguinte:
- Faça upload do backup para um bucket do Cloud Storage.
- Execute o job do Dataflow
AerospikeBackupToBigtablepara importar o backup para o Bigtable. Se o backup estiver dividido em vários arquivos, o job vai processá-los em paralelo. Para lidar com o aumento da carga de gravação e manter a capacidade de processamento ideal, provisione mais recursos do Bigtable.
Aplicar as atualizações de registro ao Bigtable
Depois de importar o backup para o Bigtable, aplique as atualizações de registros em buffer no Kafka para o Bigtable usando o conector de gravador do Kafka Connect Bigtable.
Traduzir mensagens para um formato compatível
As ferramentas de migração do Aerospike incluem o SMT do replicador, que é executado no Kafka Connect. O replicador traduz as mensagens publicadas pelo conector de origem do Aerospike Kafka (de saída) em um formato compatível com o coletor de destino que grava os registros no Bigtable. A tradução é necessária porque o coletor espera dados em um formato específico, que é diferente de como o Aerospike transmite as mudanças.
A tabela a seguir ajuda a estimar os recursos de máquina necessários para alcançar uma determinada capacidade de processamento:
| Estrutura do registro | Capacidade | Latência P99 |
|---|---|---|
| Fixa | Até 3.700 registros por segundo por vCPU | 300 ms |
| Aninhado | Até 2.600 registros por segundo por vCPU | 300 ms |
Essas estimativas pressupõem que os registros serializados em JSON tenham 1 KB de tamanho. O tempo de análise aumenta com a complexidade das estruturas de mensagens, o que significa que objetos aninhados armazenados em registros do Aerospike levam mais tempo para serem analisados.
Use a métrica consumer_lag para verificar quantas mensagens estão na fila de processamento e medir o atraso de replicação. Quando o coletor funciona com o backlog de mensagens no tópico, o atraso do consumidor diminui até se estabilizar perto de zero. Nesse ponto, o coletor processa as atualizações do Aerospike quase em tempo real, preparando você para a transição. Use o sink-record-active-count para verificar o número de mensagens já processadas.
Ingerir mensagens com o conector de coletor do Kafka Connect Bigtable
O conector de coletor do Kafka Connect Bigtable ingere mensagens do Kafka para o Bigtable. Ao configurar o conector, defina insert.mode como REPLACE_IF_NEWEST para garantir que o registro gravado na linha de destino no Bigtable seja o mais recente. Para mais informações, consulte Configuração do conector de gravador do Bigtable para Kafka Connect.
A tabela a seguir fornece orientações sobre a latência introduzida e os recursos de computação necessários para diferentes cargas de trabalho:
| Estrutura do registro | Capacidade | Latência P99 |
|---|---|---|
| Fixa | Até 3.700 registros por segundo por vCPU | 74 ms |
| Aninhado | Até 3.700 registros por segundo por vCPU | 100 ms |
Essas estimativas pressupõem que os registros serializados em JSON tenham 1 KB de tamanho. A latência informada é o tempo de processamento no coletor. Suponha uma sobrecarga adicional de aproximadamente 600 ms para fazer uma solicitação de gravação no Bigtable.
Mudar para o Bigtable
Mude o aplicativo para usar o Bigtable como o banco de dados principal.
Para garantir a consistência de leitura de gravações, desligue temporariamente o aplicativo até que o atraso de replicação chegue a zero. Isso garante que nenhuma mutação seja perdida e que as leituras de dados reflitam o estado mais recente.
Por exemplo, uma mutação aplicada no Aerospike pouco antes da transição pode não ser replicada no Bigtable ainda, causando leituras desatualizadas. Para evitar isso, mantenha o aplicativo off-line até que as métricas consumer_lag e sink-record-active-count alcancem 0. Depois que todas as mudanças pendentes forem propagadas, reinicie o aplicativo com o Bigtable como o banco de dados principal.
Embora uma migração em tempo real possa evitar o tempo de inatividade, ela tem as seguintes restrições:
- As mutações aplicadas no Bigtable não são replicadas de volta para o Aerospike.
- As mutações originadas do Aerospike podem aparecer no Bigtable com um atraso.
- Mutações atrasadas do Aerospike podem substituir atualizações mais recentes no Bigtable.
Verificar a implantação
Após a implantação, valide o desempenho do aplicativo revisando métricas como taxas de erro, latência e custo. Você também pode realizar verificações de integridade de dados.
Monitoramento e observabilidade
Monitore as seguintes métricas durante a migração:
- Atraso total: calculado como o atraso do consumidor do Kafka mais o
sink-record-active-count. Essas métricas indicam o quanto o Bigtable está atrás do Aerospike. É necessário ter um valor de atraso estável antes de redirecionar o tráfego para o Bigtable. - Utilização de CPU e memória: monitore a utilização de CPU e memória de todos os componentes do pipeline de fluxo de alterações.
- Capacidade de armazenamento do Kafka: monitora a capacidade de implantações autogerenciadas do Kafka. Se o armazenamento ficar cheio, não será possível armazenar em buffer novos eventos, o que causa falha na migração.
- Taxas de erro do aplicativo: monitore as taxas de erro e as saídas de erro de todos os elementos do pipeline de fluxo de mudanças.
Limitações
As seções a seguir descrevem as limitações a serem consideradas ao migrar dados do Aerospike para o Bigtable.
Consistência de dados durante a migração
Ao usar a ferramenta asbackup para gerar o backup do Aerospike, os registros modificados durante o processo podem ser excluídos porque ele não oferece suporte a backups atômicos. Essa limitação não afeta a correção porque todas as mudanças aparecem no fluxo de mudanças.
Durante a importação do backup para o Bigtable, cada linha é gravada com um carimbo de data/hora de última atualização (LUT, na sigla em inglês) de 0.
As atualizações do fluxo de alterações são aplicadas sobre o backup importado. As linhas gravadas do fluxo usam o valor da LUT como o carimbo de data/hora da linha do Bigtable. A configuração do coletor faz com que a atualização com uma marcação de tempo mais recente substitua uma mais antiga. Isso garante que qualquer mudança reproduzida do stream substitua a linha correspondente.
Uso da LUT
O processo de migração usa o Aerospike XDR para replicar mudanças e depende da LUT para resolver conflitos. Como as LUTs são baseadas no relógio do sistema do nó, elas podem não ser estritamente monotônicas. Como resultado, um registro desatualizado pode ter uma LUT mais recente e substituir um registro mais recente. Além disso, o conector de origem do Aerospike Kafka (saída) pode não preservar a ordem exata das mensagens ao publicar no Kafka. Como resultado, a LUT serve como marcador de versão autoritativa, garantindo que apenas os registros com a LUT mais recente sejam aplicados ao Bigtable.
Se um registro for atualizado depois que você iniciar o fluxo de alterações, mas antes de gerar o backup, o backup poderá capturar a versão mais recente, enquanto o fluxo contém uma versão mais antiga. Essa versão mais antiga pode substituir temporariamente a mais recente. No entanto, quando o evento de transmissão subsequente com a LUT correta chega, a versão mais recente é restaurada. Para evitar inconsistências, aguarde a estabilização da replicação e a mensagem mais antiga não processada no pipeline ser mais recente que o backup antes de fazer a migração.
Validação de dados
O pipeline de migração não realiza a soma de verificação dos dados em trânsito. Se você precisar de verificações de integridade de dados de ponta a ponta, implemente a validação.
Solução de problemas
As seções a seguir descrevem erros comuns que podem ocorrer durante o processo de migração e fornecem orientações sobre como resolvê-los.
Erros de importação de backup
Durante a importação do backup do Aerospike para o Bigtable, você pode encontrar os seguintes erros:
| Tipo de erro | Causa | Solução |
|---|---|---|
| Arquivo de backup corrompido | Os arquivos de backup estão ilegíveis ou contêm registros corrompidos. O job de importação falha. | Inspecione os arquivos afetados em busca de problemas de integridade. Se for irrecuperável, gere um novo backup e repita a importação. |
| Falhas de gravação do Bigtable | Ocorrem problemas de conectividade ou serviço do Bigtable. A importação não falha. | Os registros com falha são exportados para um arquivo de saída de erro no formato JSON. Reaplique manualmente ou tente novamente o job de importação completa. |
| Dados não compatíveis | O backup contém entradas que não podem ser importadas para o Bigtable. A importação não falha. | Dados sem suporte, como UDFs, são informados como avisos nos registros de jobs. Revise os registros para verificar entradas sem suporte. |
Depois que a importação do backup for concluída e os registros inválidos forem corrigidos, você poderá aplicar o fluxo de mudanças.
Erros de fluxo de alterações
Durante a aplicação do stream de mudanças, podem ocorrer falhas nos seguintes níveis:
- Erros de SMT do replicador:o SMT não transforma os dados produzidos pelo Aerospike.
- Erros de coletor:não é possível aplicar eventos ao Bigtable.
Em ambos os casos, os eventos com falha são redirecionados para um tópico dedicado do Kafka. Você pode registrar os eventos para auditoria ou processá-los usando uma lógica de recuperação personalizada.
A seguir
- Saiba como projetar seu esquema do Bigtable.
- Leia sobre como iniciar a migração para Google Cloud.
- Entenda quais estratégias você tem para transferir grandes conjuntos de dados.