
Este documento mostra como começar a usar a ciência de dados em grande escala com o R no Google Cloud. Isto destina-se a pessoas com alguma experiência com R e com blocos de notas Jupyter, e que se sintam confortáveis com SQL.
Este documento centra-se na realização de análises exploratórias de dados através de instâncias do Vertex AI Workbench e do BigQuery. Pode encontrar o código associado num notebook do Jupyter que está no GitHub.
Vista geral
O R é uma das linguagens de programação mais usadas para a modelagem estatística. Tem uma comunidade grande e ativa de cientistas de dados e profissionais de aprendizagem automática (ML). Com mais de 20 000 pacotes no repositório de código aberto da Comprehensive R Archive Network (CRAN), o R tem ferramentas para todas as aplicações de análise de dados estatísticos, ML e visualização. O R tem registado um crescimento constante nas últimas duas décadas devido à expressividade da sua sintaxe e à abrangência das suas bibliotecas de dados e de ML.
Como cientista de dados, pode querer saber como pode usar as suas competências com o R e como também pode tirar partido das vantagens dos serviços na nuvem escaláveis e totalmente geridos para a ciência de dados.
Arquitetura
Neste passo a passo, usa instâncias do Vertex AI Workbench como os ambientes de ciência de dados para realizar a análise exploratória de dados (EDA). Usa o R em dados que extrai neste passo a passo do BigQuery, o armazém de dados na nuvem sem servidor, altamente escalável e rentável da Google. Depois de analisar e processar os dados, os dados transformados são armazenados no Cloud Storage para potenciais tarefas de ML adicionais. Este fluxo é apresentado no diagrama seguinte:

Exemplo de dados
Os dados de exemplo para este documento são o conjunto de dados de viagens de táxi da cidade de Nova Iorque do BigQuery.
Este conjunto de dados público inclui informações sobre os milhões de viagens de táxi que se realizam na cidade de Nova Iorque todos os anos. Neste documento, usa os dados de 2022, que se encontram na tabela bigquery-public-data.new_york_taxi_trips.tlc_yellow_trips_2022 no BigQuery.
Este documento centra-se na EDA e na visualização através do R e do BigQuery. Os passos neste documento preparam-no para um objetivo de ML de prever o valor da tarifa de táxi (o valor antes de impostos, taxas e outros extras), tendo em conta vários fatores sobre a viagem. A criação real do modelo não é abordada neste documento.
Vertex AI Workbench
O Vertex AI Workbench é um serviço que oferece um ambiente JupyterLab integrado com as seguintes funcionalidades:
- Implementação com um clique. Pode usar um único clique para iniciar uma instância do JupyterLab pré-configurada com as mais recentes estruturas de aprendizagem automática e ciência de dados.
- Escalabilidade a pedido. Pode começar com uma configuração de máquina pequena (por exemplo, 4 vCPUs e 16 GB de RAM, como neste documento) e, quando os seus dados ficarem demasiado grandes para uma máquina, pode aumentar a escala adicionando CPUs, RAM e GPUs.
- Google Cloud integração. As instâncias do Vertex AI Workbench estão integradas com Google Cloud serviços como o Google Cloud BigQuery. Esta integração simplifica o processo de carregamento de dados para o pré-processamento e a exploração.
- Preços de pagamento por utilização. Não existem taxas mínimas nem compromissos iniciais. Para mais informações, consulte os preços do Vertex AI Workbench. Também paga pelos Google Cloud recursos que usa nos blocos de notas (como o BigQuery e o Cloud Storage).
Os blocos de notas de instâncias do Vertex AI Workbench são executados em imagens de VMs de aprendizagem avançada. Este documento suporta a criação de uma instância do Vertex AI Workbench que tem o R 4.3.
Trabalhe com o BigQuery através do R
O BigQuery não requer gestão de infraestrutura, pelo que pode concentrar-se na descoberta de estatísticas significativas. Pode analisar grandes quantidades de dados em grande escala e preparar conjuntos de dados para ML usando as capacidades de análise SQL avançadas do BigQuery.
Para consultar dados do BigQuery através do R, pode usar o bigrquery, uma biblioteca R de código aberto. O pacote bigrquery oferece os seguintes níveis de abstração sobre o BigQuery:
- A API de baixo nível fornece wrappers simples sobre a API REST BigQuery subjacente.
- A interface DBI envolve a API de baixo nível e torna o trabalho com o BigQuery semelhante ao trabalho com qualquer outro sistema de base de dados. Esta é a camada mais conveniente se quiser executar consultas SQL no BigQuery ou carregar menos de 100 MB.
- A interface dbplyr permite-lhe tratar as tabelas do BigQuery como frames de dados na memória. Esta é a camada mais conveniente se não quiser escrever SQL, mas quiser que o dbplyr o escreva por si.
Este documento usa a API de baixo nível do bigrquery, sem exigir DBI nem dbplyr.
Objetivos
- Crie uma instância do Vertex AI Workbench com suporte para R.
- Consultar e analisar dados do BigQuery através da biblioteca R bigrquery.
- Prepare e armazene dados para ML no Cloud Storage.
Custos
Neste documento, usa os seguintes componentes faturáveis do Google Cloud:
- BigQuery
- Vertex AI Workbench instances. You are also charged for resources used within notebooks, including compute resources, BigQuery, and API requests.
- Cloud Storage
Para gerar uma estimativa de custos com base na sua utilização prevista,
use a calculadora de preços.
Antes de começar
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. Na Google Cloud consola, aceda à página Workbench.
No separador Instâncias, clique em Criar novo.
Na janela Nova instância, clique em Criar. Para esta explicação passo a passo, mantenha todos os valores predefinidos.
O início da instância do Vertex AI Workbench pode demorar 2 a 3 minutos. Quando estiver pronta, a instância é apresentada automaticamente no painel Instâncias do notebook, e é apresentado um link Abrir JupyterLab junto ao nome da instância. Se o link para abrir o JupyterLab não aparecer na lista após alguns minutos, atualize a página.
Na lista de instâncias, clique em Abrir Jupyterlab. Esta ação abre o ambiente do JupyterLab noutro separador do navegador.
No ambiente JupyterLab, clique em Novo Launcher e, de seguida, no separador Launcher, clique em Terminal.
No painel do terminal, instale o R:
conda create -n r conda activate r conda install -c r r-essentials r-base=4.3.2Durante a instalação, sempre que lhe for pedido que continue, escreva
y. A instalação pode demorar alguns minutos a ser concluída. Quando a instalação estiver concluída, o resultado é semelhante ao seguinte:done Executing transaction: done ® jupyter@instance-INSTANCE_NUMBER:~$Em que INSTANCE_NUMBER é o número exclusivo atribuído à sua instância do Vertex AI Workbench.
Depois de os comandos terminarem a execução no terminal, atualize a página do navegador e, em seguida, abra o Launcher clicando em Novo Launcher.
O separador Launcher mostra opções para iniciar o R num notebook ou na consola, e para criar um ficheiro R.
Clique no separador Terminal e, de seguida, clone o repositório do GitHub vertex-ai-samples:
git clone https://github.com/GoogleCloudPlatform/vertex-ai-samples.gitQuando o comando terminar, vê a pasta
vertex-ai-samplesno painel do explorador de ficheiros do ambiente JupyterLab.No explorador de ficheiros, abra
vertex-ai-samples>notebooks>community>exploratory_data_analysis. É apresentado o bloco de notaseda_with_r_and_bigquery.ipynb.No explorador de ficheiros, abra o bloco de notas
eda_with_r_and_bigquery.ipynb.Este bloco de notas aborda a análise exploratória de dados com R e o BigQuery. Ao longo do resto deste documento, trabalha no bloco de notas e executa o código que vê no bloco de notas do Jupyter.
Verifique a versão do R que o bloco de notas está a usar:
versionO campo
version.stringna saída deve mostrarR version 4.3.2, que instalou na secção anterior.Verifique e instale os pacotes R necessários, se ainda não estiverem disponíveis na sessão atual:
# List the necessary packages needed_packages <- c("dplyr", "ggplot2", "bigrquery") # Check if packages are installed installed_packages <- .packages(all.available = TRUE) missing_packages <- needed_packages[!(needed_packages %in% installed_packages)] # If any packages are missing, install them if (length(missing_packages) > 0) { install.packages(missing_packages) }Carregue os pacotes necessários:
# Load the required packages lapply(needed_packages, library, character.only = TRUE)Autentique
bigrqueryatravés da autenticação fora da banda:bq_auth(use_oob = True)Defina o nome do projeto que quer usar para este bloco de notas substituindo
[YOUR-PROJECT-ID]por um nome:# Set the project ID PROJECT_ID <- "[YOUR-PROJECT-ID]"Defina o nome do contentor do Cloud Storage no qual pretende armazenar os dados de saída substituindo
[YOUR-BUCKET-NAME]por um nome único a nível global:BUCKET_NAME <- "[YOUR-BUCKET-NAME]"Defina a altura e a largura predefinidas para os gráficos que vão ser gerados mais tarde no bloco de notas:
options(repr.plot.height = 9, repr.plot.width = 16)Crie uma declaração SQL do BigQuery que extraia alguns preditores possíveis e a variável de previsão de destino para uma amostra de viagens. A seguinte consulta filtra alguns valores atípicos ou sem sentido nos campos que estão a ser lidos para análise.
sql_query_template <- " SELECT TIMESTAMP_DIFF(dropoff_datetime, pickup_datetime, MINUTE) AS trip_time_minutes, passenger_count, ROUND(trip_distance, 1) AS trip_distance_miles, rate_code, /* Mapping from rate code to type from description column in BigQuery table schema */ (CASE WHEN rate_code = '1.0' THEN 'Standard rate' WHEN rate_code = '2.0' THEN 'JFK' WHEN rate_code = '3.0' THEN 'Newark' WHEN rate_code = '4.0' THEN 'Nassau or Westchester' WHEN rate_code = '5.0' THEN 'Negotiated fare' WHEN rate_code = '6.0' THEN 'Group ride' /* Several NULL AND some '99.0' values go here */ ELSE 'Unknown' END) AS rate_type, fare_amount, CAST(ABS(FARM_FINGERPRINT( CONCAT( CAST(trip_distance AS STRING), CAST(fare_amount AS STRING) ) )) AS STRING) AS key FROM `bigquery-public-data.new_york_taxi_trips.tlc_yellow_trips_2022` /* Filter out some outlier or hard to understand values */ WHERE (TIMESTAMP_DIFF(dropoff_datetime, pickup_datetime, MINUTE) BETWEEN 0.01 AND 120) AND (passenger_count BETWEEN 1 AND 10) AND (trip_distance BETWEEN 0.01 AND 100) AND (fare_amount BETWEEN 0.01 AND 250) LIMIT %s "A coluna
keyé um identificador de linha gerado com base nos valores concatenados das colunastrip_distanceefare_amount.Execute a consulta e obtenha os mesmos dados que um tibble na memória, que é semelhante a um frame de dados.
sample_size <- 10000 sql_query <- sprintf(sql_query_template, sample_size) taxi_trip_data <- bq_table_download( bq_project_query( PROJECT_ID, query = sql_query ) )Veja os resultados obtidos:
head(taxi_trip_data)A saída é uma tabela semelhante à seguinte imagem:

Os resultados mostram estas colunas de dados de viagens:
trip_time_minutesnúmero inteiropassenger_countnúmero inteirotrip_distance_milesduplicarrate_codecaráterrate_typecaráterfare_amountduplicarkeycaráter
Veja o número de linhas e os tipos de dados de cada coluna:
str(taxi_trip_data)O resultado é semelhante ao seguinte:
tibble [10,000 x 7] (S3: tbl_df/tbl/data.frame) $ trip_time_minutes : int [1:10000] 52 19 2 7 14 16 1 2 2 6 ... $ passenger_count : int [1:10000] 1 1 1 1 1 1 1 1 3 1 ... $ trip_distance_miles: num [1:10000] 31.3 8.9 0.4 0.9 2 0.6 1.7 0.4 0.5 0.2 ... $ rate_code : chr [1:10000] "5.0" "5.0" "5.0" "5.0" ... $ rate_type : chr [1:10000] "Negotiated fare" "Negotiated fare" "Negotiated fare" "Negotiated fare" ... $ fare_amount : num [1:10000] 0.01 0.01 0.01 0.01 0.01 0.01 0.01 0.01 0.01 0.01 ... $ key : chr [1:10000] "1221969315200336084" 5007772749405424948" "3727452358632142755" "77714841168471205370" ...Veja um resumo dos dados obtidos:
summary(taxi_trip_data)O resultado é semelhante ao seguinte:
trip_time_minutes passenger_count trip_distance_miles rate_code Min. : 1.00 Min. :1.000 Min. : 0.000 Length:10000 1st Qu.: 20.00 1st Qu.:1.000 1st Qu.: 3.700 Class :character Median : 24.00 Median :1.000 Median : 4.800 Mode :character Mean : 30.32 Mean :1.465 Mean : 9.639 3rd Qu.: 39.00 3rd Qu.:2.000 3rd Qu.:17.600 Max. :120.00 Max. :9.000 Max. :43.700 rate_type fare_amount key Length:10000 Min. : 0.01 Length:10000 Class :character 1st Qu.: 16.50 Class :character Mode :character Median : 16.50 Mode :character Mean : 31.22 3rd Qu.: 52.00 Max. :182.50Apresente a distribuição dos valores de
fare_amountatravés de um histograma:ggplot( data = taxi_trip_data, aes(x = fare_amount) ) + geom_histogram(bins = 100)O gráfico resultante é semelhante ao gráfico na seguinte imagem:
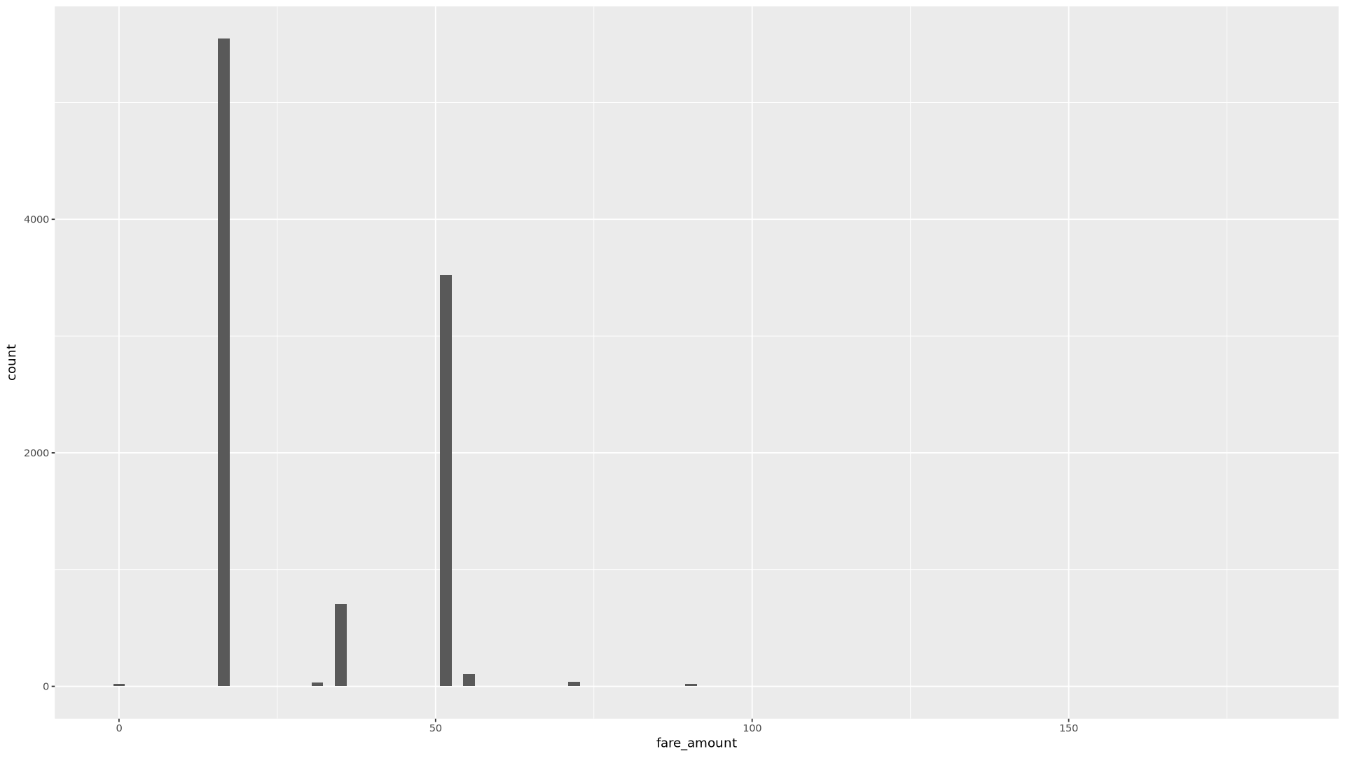
Apresenta a relação entre
trip_distanceefare_amountatravés de um gráfico de dispersão:ggplot( data = taxi_trip_data, aes(x = trip_distance_miles, y = fare_amount) ) + geom_point() + geom_smooth(method = "lm")O gráfico resultante é semelhante ao gráfico na seguinte imagem:
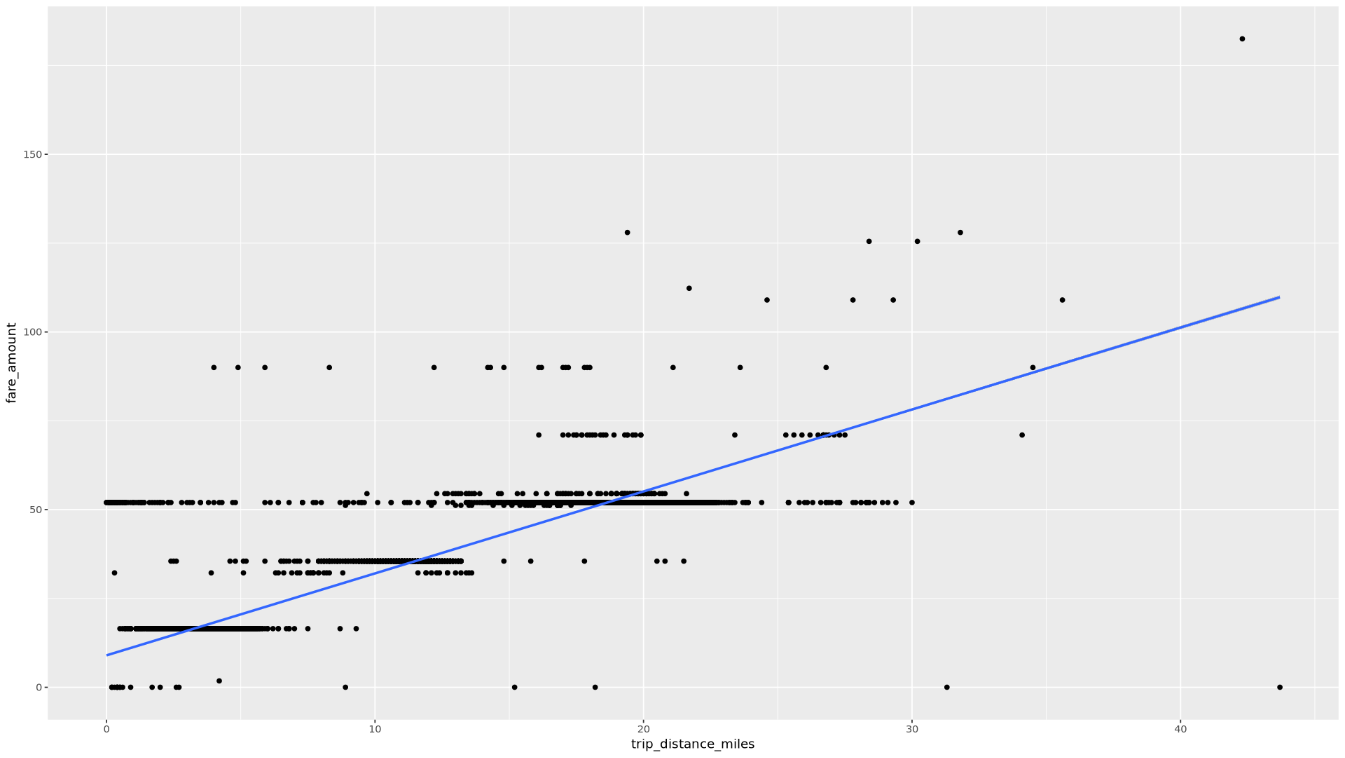
No bloco de notas, crie uma função que encontre o número de viagens e o valor médio da tarifa para cada valor da coluna escolhida:
get_distinct_value_aggregates <- function(column) { query <- paste0( 'SELECT ', column, ', COUNT(1) AS num_trips, AVG(fare_amount) AS avg_fare_amount FROM `bigquery-public-data.new_york_taxi_trips.tlc_yellow_trips_2022` WHERE (TIMESTAMP_DIFF(dropoff_datetime, pickup_datetime, MINUTE) BETWEEN 0.01 AND 120) AND (passenger_count BETWEEN 1 AND 10) AND (trip_distance BETWEEN 0.01 AND 100) AND (fare_amount BETWEEN 0.01 AND 250) GROUP BY 1 ' ) bq_table_download( bq_project_query( PROJECT_ID, query = query ) ) }Invocar a função através da coluna
trip_time_minutesdefinida com a funcionalidade de data/hora no BigQuery:df <- get_distinct_value_aggregates( 'TIMESTAMP_DIFF(dropoff_datetime, pickup_datetime, MINUTE) AS trip_time_minutes') ggplot( data = df, aes(x = trip_time_minutes, y = num_trips) ) + geom_line() ggplot( data = df, aes(x = trip_time_minutes, y = avg_fare_amount) ) + geom_line()O bloco de notas apresenta dois gráficos. O primeiro gráfico mostra o número de viagens por duração da viagem em minutos. O segundo gráfico mostra o valor médio da tarifa das viagens por hora de viagem.
O resultado do primeiro comando
ggploté o seguinte, que mostra o número de viagens por duração da viagem (em minutos):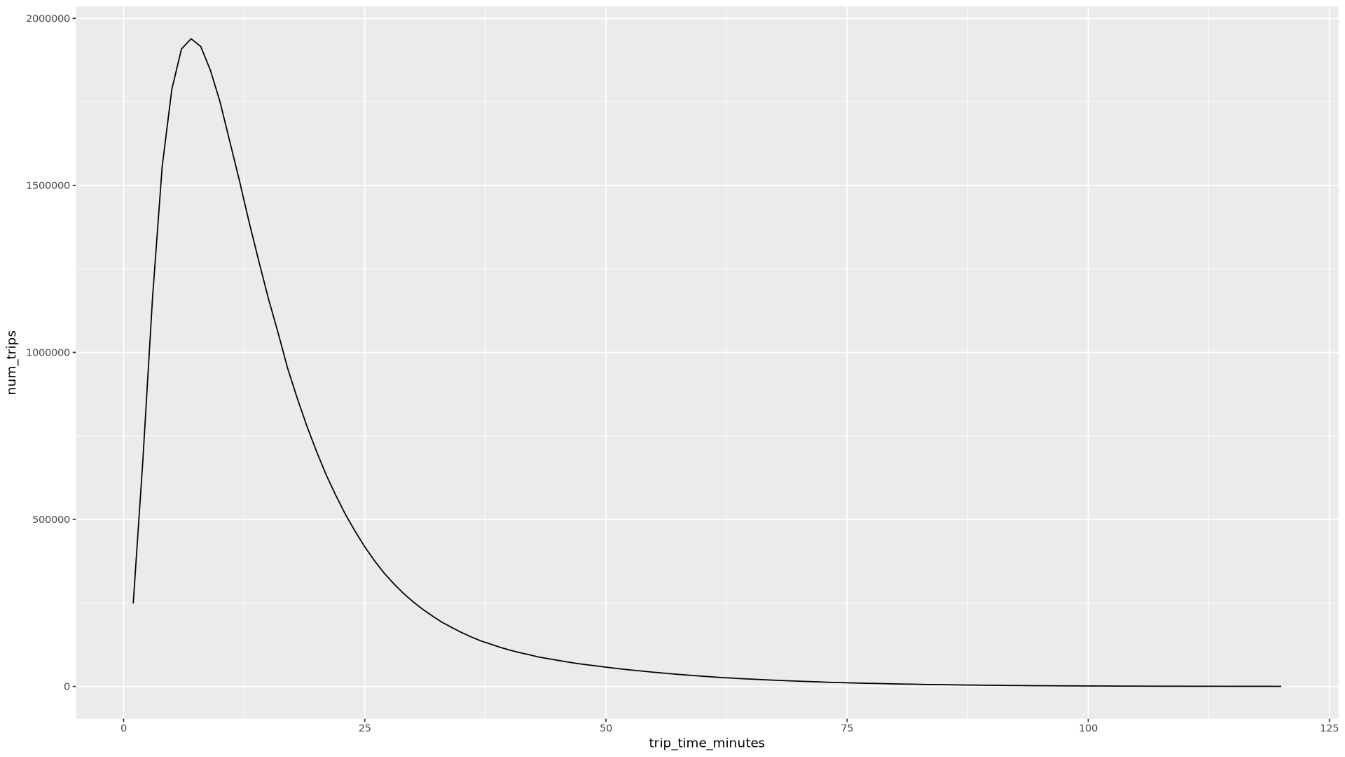
O resultado do segundo comando
ggploté o seguinte, que mostra o valor médio da tarifa das viagens por tempo de viagem: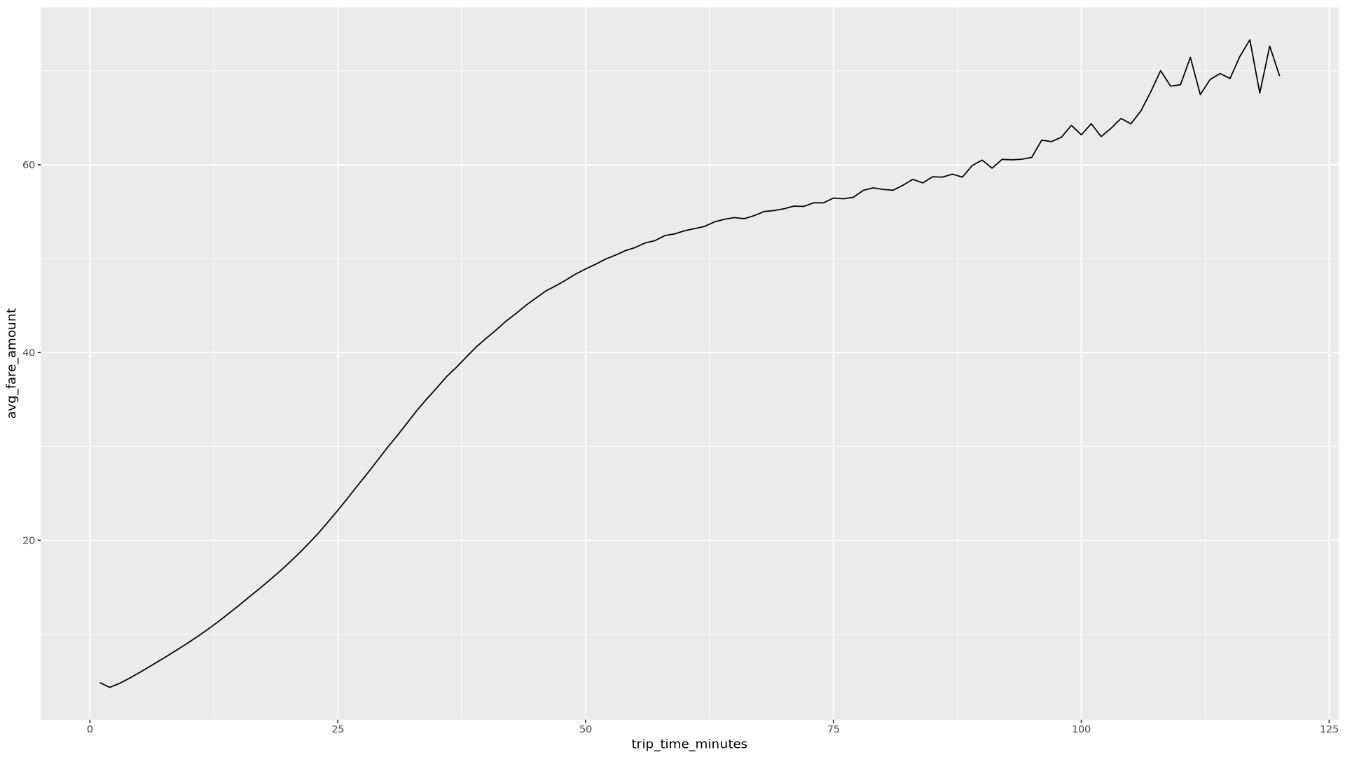
Para ver mais exemplos de visualização com outros campos nos dados, consulte o bloco de notas.
No bloco de notas, carregue os dados de preparação e avaliação do BigQuery para o R:
# Prepare training and evaluation data from BigQuery sample_size <- 10000 sql_query <- sprintf(sql_query_template, sample_size) # Split data into 75% training, 25% evaluation train_query <- paste('SELECT * FROM (', sql_query, ') WHERE MOD(CAST(key AS INT64), 100) <= 75') eval_query <- paste('SELECT * FROM (', sql_query, ') WHERE MOD(CAST(key AS INT64), 100) > 75') # Load training data to data frame train_data <- bq_table_download( bq_project_query( PROJECT_ID, query = train_query ) ) # Load evaluation data to data frame eval_data <- bq_table_download( bq_project_query( PROJECT_ID, query = eval_query ) )Verifique o número de observações em cada conjunto de dados:
print(paste0("Training instances count: ", nrow(train_data))) print(paste0("Evaluation instances count: ", nrow(eval_data)))Aproximadamente 75% do total de instâncias deve estar na formação, com aproximadamente 25% das instâncias restantes na avaliação.
Escreva os dados num ficheiro CSV local:
# Write data frames to local CSV files, with headers dir.create(file.path('data'), showWarnings = FALSE) write.table(train_data, "data/train_data.csv", row.names = FALSE, col.names = TRUE, sep = ",") write.table(eval_data, "data/eval_data.csv", row.names = FALSE, col.names = TRUE, sep = ",")Carregue os ficheiros CSV para o Cloud Storage através da união de comandos
gsutilque são transmitidos ao sistema:# Upload CSV data to Cloud Storage by passing gsutil commands to system gcs_url <- paste0("gs://", BUCKET_NAME, "/") command <- paste("gsutil mb", gcs_url) system(command) gcs_data_dir <- paste0("gs://", BUCKET_NAME, "/data") command <- paste("gsutil cp data/*_data.csv", gcs_data_dir) system(command) command <- paste("gsutil ls -l", gcs_data_dir) system(command, intern = TRUE)Também pode carregar ficheiros CSV para o Cloud Storage através da biblioteca googleCloudStorageR, que invoca a API JSON do Cloud Storage.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
- Saiba como pode usar os dados do BigQuery nos seus blocos de notas R na documentação do bigrquery.
- Saiba mais sobre as práticas recomendadas para a engenharia de ML nas Regras de ML.
- Para uma vista geral dos princípios arquitetónicos e das recomendações específicos das cargas de trabalho de IA e ML no Google Cloud, consulte aperspetiva de IA e ML no Framework Well-Architected.
- Para ver mais arquiteturas de referência, diagramas e práticas recomendadas, explore o Centro de arquitetura na nuvem.
- Jason Davenport | Consultor de programadores
- Firat Tekiner | Senior Product Manager
Crie uma instância do Vertex AI Workbench
O primeiro passo é criar uma instância do Vertex AI Workbench que pode usar para esta explicação passo a passo.
Abra o JupyterLab e instale o R
Para concluir o procedimento passo a passo no bloco de notas, tem de abrir o ambiente do JupyterLab, instalar o R, clonar o repositório do GitHub vertex-ai-samples e, em seguida, abrir o bloco de notas.
Abra o notebook e configure o R
Consulte dados do BigQuery
Nesta secção do bloco de notas, lê os resultados da execução de uma declaração SQL do BigQuery no R e analisa preliminarmente os dados.
Visualize dados com o ggplot2
Nesta secção do bloco de notas, usa a biblioteca ggplot2 em R para estudar algumas das variáveis do conjunto de dados de exemplo.
Processe os dados no BigQuery a partir do R
Quando trabalha com grandes conjuntos de dados, recomendamos que faça o máximo de análise possível (agregação, filtragem, junção, cálculo de colunas, etc.) no BigQuery e, em seguida, recupere os resultados. A execução destas tarefas no R é menos eficiente. A utilização do BigQuery para análise tira partido da escalabilidade e do desempenho do BigQuery, e garante que os resultados devolvidos cabem na memória em R.
Guarde dados como ficheiros CSV no Cloud Storage
A tarefa seguinte consiste em guardar os dados extraídos do BigQuery como ficheiros CSV no Cloud Storage para que os possa usar para outras tarefas de ML.
Também pode usar o bigrquery para escrever dados de R de volta para o BigQuery. Normalmente, a gravação de volta no BigQuery é feita após a conclusão de algum pré-processamento ou geração de resultados a usar para análise adicional.
Limpar
Para evitar incorrer em cobranças na sua conta do Google Cloud pelos recursos usados neste documento, deve removê-los.
Elimine o projeto
A forma mais fácil de eliminar a faturação é eliminar o projeto que criou. Se planeia explorar várias arquiteturas, tutoriais ou inícios rápidos, a reutilização de projetos pode ajudar a evitar exceder os limites de quota de projetos.
O que se segue?
Colaboradores
Autor: Alok Pattani | Consultor de programadores
Outros colaboradores: