
Créez une application de chat d'IA générative qui utilise la génération augmentée par récupération (RAG) pour fournir des réponses ancrées et précises basées sur les données de votre organisation. Ce guide décrit le modèle d'application RAG d'IA générative avec Cloud SQL, que vous pouvez personnaliser pour l'adapter à vos besoins spécifiques et déployer en tant qu'application.
Par exemple, vous pouvez implémenter ce modèle pour répondre aux besoins commerciaux suivants :
| Exemple | Besoin | Implémentation |
|---|---|---|
| Chatbot de service client | Les entreprises doivent fournir une assistance client instantanée. | Hébergez l'interface de chat sur Cloud Run. Vertex AI traite les embeddings et génère des réponses basées sur la documentation technique stockée sous forme de vecteurs dans Cloud SQL. |
| Assistant RH interne | Les collaborateurs souhaitent pouvoir trouver des informations sur les avantages, les règles de l'entreprise et les procédures internes. | Hébergez l'assistant RH sur Cloud Run. Lorsque les employés interrogent l'outil, Vertex AI récupère les informations pertinentes sur les règles à partir de Cloud SQL pour générer des réponses précises et ancrées dans les sources. |
| Chercheur de documents juridiques | Les équipes juridiques doivent trouver rapidement la jurisprudence ou les clauses contractuelles pertinentes dans de grands référentiels de documents. | Hébergez le portail de recherche sur Cloud Run. Vertex AI résume les précédents pertinents et identifie le langage spécifique des contrats à l'aide de documents juridiques stockés sous forme de vecteurs dans Cloud SQL. |
| Recherche sémantique de produits | Les entreprises de e-commerce souhaitent faciliter la recherche de produits à l'aide de descriptions en langage naturel plutôt que de mots clés exacts. | Hébergez l'interface de recherche sur Cloud Run. Vertex AI traite les descriptions des utilisateurs pour renvoyer les produits les plus pertinents sémantiquement à partir des catalogues de produits stockés sous forme de vecteurs dans Cloud SQL. |
Architecture
L'image suivante montre les composants et les connexions dans l'application :
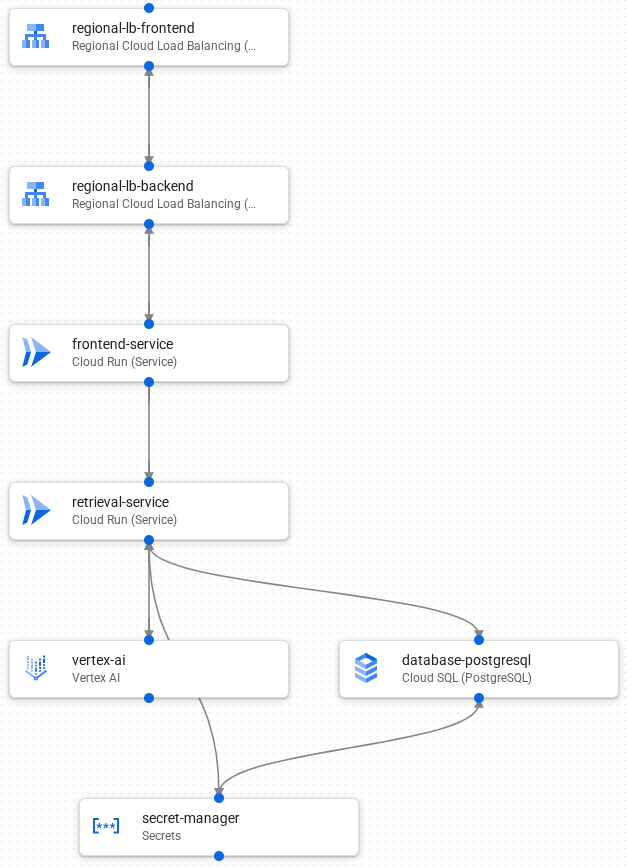
Voici le flux de traitement des requêtes de l'application :
- Chargez des données dans une base de données PostgreSQL dans Cloud SQL.
- Vertex AI crée des embeddings de champs de texte et les stocke sous forme de vecteurs dans la base de données.
- Un frontend Cloud Load Balancing reçoit les requêtes externes et distribue le trafic au backend Cloud Load Balancing.
- Le backend Cloud Load Balancing répartit le trafic vers le service de frontend Cloud Run.
- Le service de frontend communique avec un service de récupération pour passer un appel d'IA générative.
- Le service de récupération utilise Secret Manager pour accéder de manière sécurisée aux clés API et aux identifiants requis pour accéder à Vertex AI et Cloud SQL.
- Le service de récupération convertit la requête en embedding et recherche des vecteurs similaires dans la base de données Cloud SQL.
- Le service de récupération envoie les résultats de la recherche, ainsi que le prompt d'origine, à Vertex AI pour créer une réponse.
Étapes suivantes
- Pour savoir comment dupliquer et personnaliser ce modèle, consultez Guide de démarrage rapide : personnaliser et déployer un modèle Google.
- Définissez vos propres configurations en concevant des modèles d'application.
- Identifiez les bonnes pratiques générales en matière d'architecture avec le Google Cloud Architecture Framework.