
AI アプリケーションを作成するには、AI ワークロード用に最適化された安全な非公開の Google Kubernetes Engine(GKE)クラスタをプロビジョニングし、Helm チャートを使用してワークロードをデプロイします。このガイドでは、AI アプリケーションのデプロイ用にカスタマイズできる次のテンプレートについて説明します。
AI 事前トレーニング済み推論 GKE クラスタ: 高パフォーマンスのモデル提供に必要な基盤となるインフラストラクチャを作成します。このテンプレートは、AI 推論用に最適化された安全な限定公開 GKE クラスタを設定します。
AI 事前トレーニング済み推論 GKE ワークロード(プレビュー): AI ワークロードの構成を含む Helm チャートをデプロイします。Helm チャートを使用して、vLLM サービング エンジンで事前トレーニング済みの Gemma モデルをデプロイします。ワークロードは、効率的な GPU リソース リクエストと、GPU キャッシュ使用量に基づいてスケーリングする Horizontal Pod Autoscaler(HPA)用に構成されています。
たとえば、クラスタ テンプレートとワークロード テンプレートをデプロイして、次のビジネスニーズに対応できます。
| 例 | ビジネスニーズ | 実装 |
|---|---|---|
| リアルタイム動画分析 | あるセキュリティ会社が、数百台のカメラからの動画ストリームを処理して、異常や特定のオブジェクトをリアルタイムで検出する必要があります。 | GPU 対応ノードプールに動画処理モデルをデプロイします。GPU は、同時動画ストリームの高スループットと低レイテンシの要件を処理できます。 |
| 専門的なドキュメント処理 | 保険会社は、レイアウトや手書きの文字がさまざまな何千もの保険金請求フォームから情報を自動的に抽出する必要があります。 | GKE クラスタを使用してカスタムモデルをホストし、処理中にデータが安全な環境から流出しないようにします。 |
| 大容量のレコメンデーション エンジン | e コマース プラットフォームでは、ホリデー ショッピングのピーク時にユーザーにパーソナライズされたおすすめ商品を提案する必要があります。 | Google Kubernetes Engine Gateway API を使用して、大量のユーザー トラフィックをレコメンデーション モデルに転送します。Gateway API は、レイテンシの低下なしにトラフィックの急増を処理できます。 |
アーキテクチャ
次の図は、テンプレートのコンポーネントと接続を示しています。
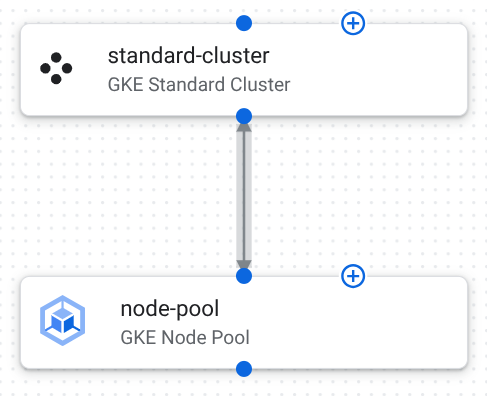
このテンプレートのコンポーネント構成は次のとおりです。
GKE Standard クラスタ: AI ワークロードが実行される安全なプライベート クラスタ。
次の表に、このテンプレートのクラスタ構成を示します。
構成 目的 node_locationsが["us-central1-a", "us-central1-b", "us-central1-c"]に設定されている。us-central1リージョンの 3 つのゾーンにクラスタのノードを分散することで、高可用性と復元力を確保します。enable_intranode_visibilityがtrueに設定されている。VPC フローログで、同じノード内の Pod 間トラフィックの可視性を有効にします。この可視性は、ネットワーク モニタリング、トラブルシューティング、セキュリティ分析に必要です。 gateway_api_configは{"channel":"CHANNEL_STANDARD"}を使用して有効になります。GKE Inference Gateway API を使用すると、Kubernetes サービスへの上り(内向き)トラフィックを管理できます。この API を使用すると、きめ細かいルーティング、高度なロード バランシング、一元化されたポリシーの関連付けを構成できます。 private_cluster_config.enable_private_endpointはfalseに設定されています。private_cluster_config.enable_private_nodesはtrueです。control_plane_endpoints_config.dns_endpoint_config.allow_external_trafficがtrueに設定されている。AI モデルが実行されるワーカーノードにプライベート IP アドレスが割り当てられていることを確認します。これにより、ノードが公共のインターネットから分離されます。GKE コントロール プレーンは、Virtual Private Cloud(VPC)ネットワーク外でクラスタを管理できるように、一般公開されるように構成されています。 release_channelが{"channel":"REGULAR"}に設定されている。GKE クラスタが安定した予測可能なアップデートを受け取り、新機能と信頼性のバランスが取れるようにします。 GKE ノードプール: アプリケーションのコンテナを実行するワーカーノードのグループ。
次の表に、このテンプレートのノードプール構成を示します。
構成 目的 autoscaling.min_node_countは0に設定されています。autoscaling.max_node_countは3に設定されています(デフォルトは100)。AI ワークロードが実行されていない場合、ノードプールは完全にスケールダウンできるため、アイドル期間中の費用を削減できます。スケーリングの上限を設定すると、費用とリソース消費を制御できます。 node_config.guest_acceleratorパラメータが追加されます。gpu_driver_installation_config.gpu_driver_version:は"LATEST"に設定されます。gpu_sharing_configはTIME_SHARINGで有効になります。max_shared_clients_per_gpu:は2に設定されます。AI 推論タスクに NVIDIA L4 GPU を使用することを指定します。必要な GPU ドライバが自動的にインストールされます。複数の小規模なワークロードで単一の GPU を共有できます。 node_config.machine_typeが"g2-standard-8"に変更されました。このマシンタイプは、L4 GPU を補完するように設計されています。vCPU(8 個)とメモリ(32 GB)は、GPU をサポートし、AI 推論アプリケーションを実行するために作成されます。 node_config.oauth_scopesにはhttps://www.googleapis.com/auth/cloud-platformが含まれます。ノードのサービス アカウントは Google Cloud サービスへの広範なアクセス権を持ち、ロギング、モニタリング、コンテナ イメージの pull などのタスクで API を操作できます。 node_config.shielded_instance_config.enable_secure_bootがtrueに設定されている。セキュアブートは、ブートローダーとカーネルの暗号署名を検証してから実行することで、ブートレベルのマルウェアからノードを保護します。
Helm チャートの構成
次の表に、GKE で AI 推論サービスをデプロイしてスケーリングするためにカスタマイズされた Helm チャート構成を示します。
| 構成 | 目的 |
|---|---|
replicaCount: 1 |
単一の初期レプリカを作成します。 |
image.repository: vllm/vllm-openai |
大規模言語モデル(LLM)推論用に最適化されたライブラリである vLLM イメージを使用します。このライブラリは、OpenAI 互換の API を使用して公開されます。 |
model.id: google/gemma-7b-it |
Gemma 7B 指示チューニング済みモデルをサービングするモデルとして定義します。 |
model.hfSecret: hf-secret |
モデルで、安全な認証情報管理のために Kubernetes Secret を使用した認証が必要であることを示します。 |
nvidia.com/gpu: "1" の resources.limits と requests |
各 Pod に専用の GPU が割り当てられるようにします。 |
nodeSelector.cloud.google.com/gke-accelerator: nvidia-l4 |
AI モデル Pod が NVIDIA L4 GPU を搭載した GKE Standard ノードでのみスケジュールされるようにします。これは、費用対効果とパフォーマンスに優れた推論に最適です。 |
hpa.enabled: true |
水平 Pod 自動スケーラーを有効にします。これにより、アプリケーションは targetCPUUtilizationPercentage: 80% に基づいて Pod の数(minReplicas: 1~maxReplicas: 10)を自動的にスケーリングできます。これにより、ピーク時のパフォーマンスと使用率が低いときのコスト効率が確保されます。 |
tensorParallelSize: 1 |
モデルが単一の Pod 内の複数の GPU に分割されていないことを示します。 |
maxModelLen: 512 |
Gemma 7B モデルが処理できる最大シーケンス長を制御します。 |
service.type: ClusterIP |
サービスは、クラスタ内の内部アクセス用に構成されています。 |
pdb.enabled: true と minAvailable: 1 |
高可用性を確保するために、Pod Disruption Budget が有効になっています。ノードのメンテナンスなどの自発的な中断中に、AI モデルのレプリカが少なくとも 1 つ使用可能になります。 |
AI アプリケーションを作成する
AI 事前トレーニング済み推論 GKE クラスタとワークロード テンプレートを使用して、AI アプリケーションをデプロイします。
AI インフラストラクチャをデプロイする
AI 事前トレーニング済み推論 GKE クラスタ テンプレートを構成してデプロイし、AI ワークロードが実行される基盤となるインフラストラクチャを作成します。
AI 事前トレーニング済み推論 GKE クラスタ テンプレートを複製してアプリケーションとしてデプロイします。
選択したデプロイ プロジェクトに GKE クラスタが作成されます。
コンポーネントを構成します。詳しくは以下をご覧ください。
[デプロイ] をクリックします。アプリケーションは数分後にデプロイされます。
[アプリケーションの詳細] パネルで、[出力] タブをクリックします。
アプリケーションの cluster_id を特定します。この情報は、Helm チャートをデプロイするときに使用します。
AI ワークロードをデプロイする
AI 事前トレーニング済み推論 GKE ワークロード テンプレートを使用して、作成したクラスタに AI ワークロードをデプロイします。AI ワークロード構成を含む Helm チャートをデプロイします。
[Google カタログ] ページの [AI 事前トレーニング済み推論 GKE ワークロード] テンプレートで、[新しいアプリケーションを作成] をクリックします。
[名前] フィールドに、アプリケーションの一意の名前を入力します。
[GKE デプロイ ターゲット] 領域で、次の操作を行います。
[プロジェクト リスト] で、AI 事前トレーニング済み推論 GKE クラスタ アプリケーションから GKE クラスタをデプロイしたプロジェクトを選択します。
[リージョン] リストから、GKE クラスタをデプロイしたリージョンを選択します。
[クラスタ] リストから、デプロイされた GKE クラスタを選択します。
[Namespace] リストで、GKE クラスタをデプロイした Namespace を入力します。名前を変更していない場合は、
defaultと入力します。[アプリケーションを作成] をクリックします。
アプリケーションが作成され、構成ファイルが表示されます。
[Helm チャート] パネルで、次の操作を行います。
構成の詳細を確認します。
省略可: 独自のニーズに合わせて構成をカスタマイズします。
Helm チャートをクラスタにデプロイするには、[デプロイ] をクリックします。
詳細な手順については、アプリケーションをデプロイするをご覧ください。
数分後、Helm チャート構成が GKE クラスタにデプロイされます。
次のステップ
- Google テンプレートに基づいて構築することで、このテンプレートを複製してカスタマイズします。
- アプリケーション テンプレートを設計して、独自の構成を定義します。
- Google Cloud アーキテクチャ フレームワークで、一般的なアーキテクチャのベスト プラクティスを特定する。