
כדי ליצור אפליקציית AI, צריך להקצות אשכול מאובטח ופרטי של Google Kubernetes Engine (GKE) שעבר אופטימיזציה לעומסי עבודה של AI, ואז לפרוס את עומס העבודה באמצעות תרשים helm. במדריך הזה מתוארות התבניות הבאות, שאפשר להתאים אישית כדי לפרוס אפליקציית AI:
אשכול GKE של היקש שעבר אימון מראש על ידי AI: יצירת התשתית הבסיסית שנדרשת לפרסום המודל עם ביצועים גבוהים. התבנית הזו מגדירה אשכול GKE מאובטח ופרטי שמיועד להסקת מסקנות מ-AI.
עומס עבודה של GKE עם מסקנות שנוצרו על ידי AI שעבר אימון מראש (תצוגה מקדימה): פריסה של תרשים helm שכולל את ההגדרה של עומס עבודה של AI. משתמשים בתרשים Helm כדי לפרוס מודל Gemma שאומן מראש באמצעות מנוע ההגשה vLLM. עומס העבודה מוגדר לבקשות יעילות של משאבי GPU ול-Horizontal Pod Autoscaler (HPA) כדי לבצע שינוי גודל על סמך השימוש במטמון של ה-GPU.
לדוגמה, אפשר לפרוס את התבניות של האשכולות ועומסי העבודה כדי לתת מענה לצרכים העסקיים הבאים:
| דוגמה | הצורך העסקי | הטמעה |
|---|---|---|
| ניתוח סרטונים בזמן אמת | חברת אבטחה צריכה לעבד שידורי וידאו ממאות מצלמות כדי לזהות אנומליות או אובייקטים ספציפיים בזמן אמת. | פריסת מודלים לעיבוד וידאו במאגר הצמתים עם GPU. מעבדי GPU יכולים לעבד את הדרישות של נפח נתונים גבוה וזמן אחזור נמוך של סטרימינג של סרטונים בו-זמנית. |
| עיבוד מסמכים מיוחד | חברת ביטוח צריכה לחלץ באופן אוטומטי מידע מאלפי טפסים של תביעות שמגיעים מדי יום, עם פריסות שונות וכתב יד שונה. | משתמשים באשכול GKE כדי לארח מודלים בהתאמה אישית, ומוודאים שהנתונים לא יוצאים מהסביבה המאובטחת במהלך העיבוד. |
| מערכת המלצות עם נפח גבוה | פלטפורמת מסחר אלקטרוני צריכה להציג המלצות מותאמות אישית למוצרים למשתמשים במהלך אירועי קניות של חגים. | משתמשים ב-Google Kubernetes Engine Gateway API כדי לנתב נפחים גדולים של תעבורת משתמשים למודלים של ההמלצות. ממשק Gateway API יכול להתמודד עם עליות חדות בתעבורת הנתונים בלי לפגוע בזמן האחזור. |
ארכיטקטורה
בתמונה הבאה מוצגים הרכיבים והחיבורים בתבנית:
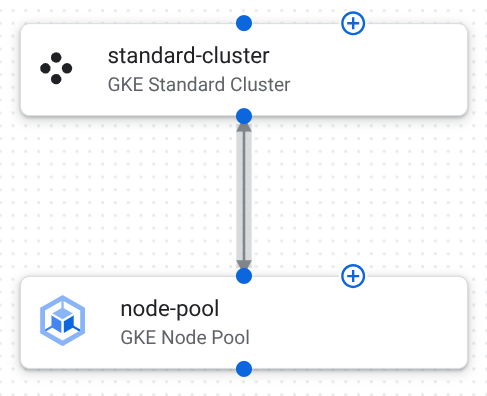
בטבלה הבאה מתוארות הגדרות הרכיבים בתבנית הזו:
אשכול GKE Standard: אשכול מאובטח ופרטי שבו פועל עומס העבודה של ה-AI.
בטבלה הבאה מפורטת הגדרת האשכול בתבנית הזו:
הגדרות אישיות מטרה הערך של node_locationsהוא["us-central1-a", "us-central1-b", "us-central1-c"].הפצת הצמתים של האשכול על פני שלושה אזורים באזור us-central1מבטיחה זמינות גבוהה ועמידות.הערך של enable_intranode_visibilityהואtrue.מאפשרת לראות את התנועה בין הפודים באותו צומת ביומני התנועה של VPC. התובנות האלה נדרשות לצורך מעקב רשתי, פתרון בעיות וניתוח אבטחה. gateway_api_configמופעל באמצעות{"channel":"CHANNEL_STANDARD"}.ממשק ה-API של GKE Inference Gateway עוזר לכם לנהל את תעבורת הכניסה לשירותי Kubernetes. ה-API עוזר לכם להגדיר ניתוב מדויק, איזון עומסים מתקדם וצירוף מרכזי של כללי מדיניות. הערך של private_cluster_config.enable_private_endpointהואfalse.private_cluster_config.enable_private_nodesהואtrue. הערך שלcontrol_plane_endpoints_config.dns_endpoint_config.allow_external_trafficהואtrue.מוודאים שלצמתי העובדים שבהם מודלי ה-AI פועלים יש כתובות IP פרטיות. הפעולה הזו מבודדת את הצמתים שלכם מהאינטרנט הציבורי. מישור הבקרה של GKE מוגדר כך שניתן לגשת אליו באופן ציבורי, כדי שתוכלו לנהל את האשכול מחוץ לרשת הענן הווירטואלי הפרטי (VPC). הערך של release_channelהוא{"channel":"REGULAR"}.העדכונים האלה מבטיחים שהעדכונים של אשכול GKE יהיו יציבים וצפויים, ויוצרים איזון בין תכונות חדשות לבין מהימנות. מאגר צמתים של GKE: קבוצה של צמתים של עובדים שמריצים את הקונטיינרים של האפליקציה.
בטבלה הבאה מתוארות ההגדרות של מאגר הצמתים בתבנית הזו:
הגדרות אישיות מטרה הערך של autoscaling.min_node_countהוא0. הערך שלautoscaling.max_node_countמוגדר כ-3(ברירת המחדל היא100).מאגר הצמתים יכול להצטמצם באופן מלא כשלא מופעלים עומסי עבודה של AI, וכך העלויות יורדות בתקופות שבהן אין פעילות. הגבול העליון של ההתאמה עוזר לשלוט בעלויות ובצריכת המשאבים. הפרמטר node_config.guest_acceleratorנוסף. הערך שלgpu_driver_installation_config.gpu_driver_version:הוא"LATEST". gpu_sharing_configמופעל עםTIME_SHARING. הערך שלmax_shared_clients_per_gpu:הוא2.מציין את השימוש ב-GPUs מסוג NVIDIA L4 למשימות של הסקת מסקנות מ-AI. מנהלי ההתקנים הנדרשים של ה-GPU מותקנים באופן אוטומטי. כמה עומסי עבודה קטנים יכולים לחלוק GPU אחד. הערך של node_config.machine_typeהשתנה ל-"g2-standard-8".סוג המכונה מתוכנן במיוחד כדי להשלים את יחידות ה-GPU מסוג L4. ליבות ה-vCPU (8) והזיכרון (32GB) נוצרים כדי לתמוך ב-GPU ולהריץ את אפליקציות ההסקה של ה-AI. node_config.oauth_scopesכוללhttps://www.googleapis.com/auth/cloud-platform.לחשבון השירות של הצומת יש גישה רחבה לשירותי Google Cloud , והוא מאפשר אינטראקציה עם ה-API למשימות כמו רישום ביומן, מעקב ושליפה של קובצי אימג' בקונטיינר. הערך של node_config.shielded_instance_config.enable_secure_bootהואtrue.האתחול המאובטח עוזר להגן על הצמתים מפני תוכנות זדוניות ברמת האתחול, על ידי אימות החתימות הקריפטוגרפיות של טוען האתחול והליבה לפני שהם מופעלים.
הגדרת תרשים Helm
בטבלה הבאה מפורטות ההגדרות של תרשים ה-Helm, שהותאמו לפריסה ולשינוי של קנה מידה של שירות הסקת מסקנות מ-AI ב-GKE.
| הגדרות אישיות | מטרה |
|---|---|
replicaCount: 1 |
יוצר עותק יחיד ראשוני. |
image.repository: vllm/vllm-openai |
משתמש בתמונה של vLLM, ספרייה שעברה אופטימיזציה להסקת מסקנות של מודלים גדולים של שפה (LLM), שנחשפת באמצעות API שתואם ל-OpenAI. |
model.id: google/gemma-7b-it |
ההגדרה מגדירה את מודל Gemma 7B שעבר כוונון להוראות כמודל שיוצג. |
model.hfSecret: hf-secret |
המודל דורש אימות באמצעות סוד של Kubernetes לניהול מאובטח של פרטי כניסה. |
resources.limits ו-requests במחיר nvidia.com/gpu: "1" |
התכונה הזו מבטיחה שכל פוד יקבל GPU ייעודי. |
nodeSelector.cloud.google.com/gke-accelerator: nvidia-l4 |
התכונה הזו מבטיחה שהפודים של מודל ה-AI יתוזמנו באופן בלעדי בצמתי GKE Standard שמצוידים במעבדי NVIDIA L4 GPU, שהם אידיאליים להסקת מסקנות חסכונית ועם ביצועים גבוהים. |
hpa.enabled: true |
ההגדרה הזו מפעילה את Horizontal Pod Autoscaler (HPA), שמאפשר לאפליקציה לשנות באופן אוטומטי את מספר הפודים (בין minReplicas: 1 ל-maxReplicas: 10) על סמך targetCPUUtilizationPercentage: 80%. הפתרון מבטיח ביצועים טובים בזמן עומסים גבוהים ויעילות בעלויות בזמן שימוש נמוך. |
tensorParallelSize: 1 |
מציין שהמודל לא מפולח בין כמה יחידות GPU בתוך פוד יחיד. |
maxModelLen: 512 |
המדיניות קובעת את האורך המקסימלי של רצף שהמודל Gemma 7B יכול לעבד. |
service.type: ClusterIP |
השירות מוגדר לגישה פנימית בתוך האשכול. |
pdb.enabled: true וגם minAvailable: 1 |
תקציב לשיבוש Pod מופעל כדי להבטיח זמינות גבוהה. לפחות רפליקה אחת של מודל ה-AI שלכם נשארת זמינה במהלך שיבושים מרצון, כמו תחזוקת צמתים. |
יצירת אפליקציית AI
אפשר להשתמש בתבניות AI Pre-trained Inference אשכול GKE ועומס עבודה כדי לפרוס את אפליקציית ה-AI.
פריסת תשתית ה-AI
מגדירים ופורסים את תבנית אשכול GKE של מסקנות AI שאומן מראש כדי ליצור את התשתית הבסיסית שבה פועל עומס העבודה של ה-AI.
משכפלים ופורסים את התבנית AI Pre-trained Inference אשכול GKE כאפליקציה.
אשכול GKE נוצר בפרויקט הפריסה שבחרתם.
מגדירים את הרכיבים. למידע נוסף, קראו את המאמרים הבאים:
לוחצים על פריסה. הפריסה של האפליקציה מתבצעת אחרי כמה דקות.
בחלונית פרטי האפליקציה, לוחצים על הכרטיסייה פלט.
מזהים את cluster_id של האפליקציה. תצטרכו להשתמש במידע הזה כשפורסים את תרשים ה-Helm.
פריסת עומס העבודה של ה-AI
משתמשים בתבנית AI Pre-trained Inference GKE workload כדי לפרוס את עומס העבודה של ה-AI באשכול שיצרתם. תפרסו תרשים Helm שכולל את הגדרות עומס העבודה של ה-AI.
בדף קטלוג Google, בתבנית AI Pre-trained Inference GKE workload (עומס עבודה של GKE להסקת מסקנות שאומן מראש על ידי AI), לוחצים על Create new application (יצירת אפליקציה חדשה).
בשדה שם, מזינים שם ייחודי לאפליקציה.
בקטע GKE Deployment Target (יעד הפריסה של GKE), מבצעים את הפעולות הבאות:
ברשימה Project list, בוחרים את הפרויקט שבו פרסתם את אשכול GKE מהאפליקציה AI Pre-trained Inference GKE cluster.
ברשימה אזור, בוחרים את האזור שבו פרסתם את אשכול GKE.
ברשימה Clusters (אשכולות), בוחרים את אשכול GKE שנפרס.
ברשימה Namespace, מזינים את מרחב השמות שבו פרסתם את אשכול GKE. אם לא שיניתם את השם, מזינים
default.לוחצים על יצירת אפליקציה.
האפליקציה נוצרת ומוצגים קובצי ההגדרות.
בחלונית Helm chart:
בודקים את פרטי ההגדרה.
אופציונלי: אפשר להתאים אישית את ההגדרה לפי הצרכים הייחודיים שלכם.
כדי לפרוס את תרשים ה-Helm לאשכול, לוחצים על Deploy (פריסה).
הוראות מפורטות מופיעות במאמר פריסת אפליקציות.
אחרי כמה דקות, הגדרת תרשים ה-Helm נפרסת באשכול GKE.
המאמרים הבאים
- אפשר לשכפל את התבנית הזו ולהתאים אותה אישית באמצעות יצירת תבניות ב-Google.
- אפשר להגדיר הגדרות משלכם על ידי עיצוב תבניות של אפליקציות.
- כדאי לעיין בGoogle Cloud מסגרת הארכיטקטורה כדי להכיר שיטות מומלצות כלליות לארכיטקטורה.