
כשמבצעים אופטימיזציה של הביצועים של אפליקציה, צריך לקחת בחשבון את השימוש שלה ב-NDB. לדוגמה, אם אפליקציה קוראת ערך שלא נמצא במטמון, הקריאה הזו אורכת זמן. יכול להיות שאפשר להאיץ את האפליקציה על ידי ביצוע פעולות Datastore במקביל לפעולות אחרות, או על ידי ביצוע כמה פעולות Datastore במקביל זו לזו.
ספריית הלקוח של NDB מספקת פונקציות אסינכרוניות רבות (async).
כל אחת מהפונקציות האלה
מאפשרת לאפליקציה לשלוח בקשה ל-Datastore. הפונקציה מחזירה
באופן מיידי אובייקט Future. האפליקציה יכולה לבצע פעולות אחרות בזמן ש-Datastore מטפל בבקשה.
אחרי ש-Datastore מטפל בבקשה, האפליקציה יכולה לקבל את התוצאות מאובייקט Future.
שימוש בממשקי API אסינכרוניים וב-Futures
כמעט לכל פונקציית NDB סינכרונית יש פונקציית _async מקבילה. לדוגמה, ל-put() יש put_async(). הארגומנטים של הפונקציה האסינכרונית תמיד זהים לאלה של הגרסה הסינכרונית. ערך ההחזרה של שיטה אסינכרונית הוא תמיד Future או (עבור פונקציות 'multi') רשימה של Future.
Future הוא אובייקט ששומר על מצב של פעולה שהופעלה אבל אולי עדיין לא הושלמה. כל ממשקי ה-API האסינכרוניים מחזירים אובייקט אחד או יותר מסוג Futures.
אפשר לקרוא לפונקציה Future של get_result() כדי לבקש ממנה את התוצאה של הפעולה שלה. אם התוצאה לא זמינה, הפונקציה Future חוסמת את הפעולה עד שהתוצאה זמינה, ואז מעבירה אותה אליכם.
הפונקציה get_result() מחזירה את הערך שמוחזר על ידי הגרסה הסינכרונית של ה-API.
הערה:
אם השתמשתם ב-Futures בשפות תכנות אחרות, יכול להיות שתחשבו שאפשר להשתמש ב-Future כתוצאה ישירות. אי אפשר לעשות את זה כאן.
בשפות האלה נעשה שימוש ב
futures משתמעים, וב-NDB נעשה שימוש ב-futures מפורשים.
מתקשרים למספר get_result() כדי לקבל את התוצאה של FutureNDB.
מה קורה אם הפעולה מעלה חריגה? זה תלוי במועד שבו מתרחשת החריגה. אם NDB מזהה בעיה בזמן יצירת בקשה (למשל, ארגומנט מסוג שגוי), השיטה _async() מעלה חריגה. אבל אם החריגה מזוהה על ידי שרת Datastore, השיטה _async() מחזירה Future, והחריגה תופעל כשהאפליקציה שלכם תקרא ל-get_result(). אל תדאגו יותר מדי לגבי זה, בסופו של דבר הכל מתנהג בצורה די טבעית. יכול להיות שההבדל הכי גדול הוא שאם יודפס traceback, תראו חלקים מהמנגנון האסינכרוני ברמה הנמוכה.
לדוגמה, נניח שאתם כותבים אפליקציה של ספר אורחים. אם המשתמש מחובר, רוצים להציג דף עם הפוסטים האחרונים בספר האורחים. בדף הזה צריך להופיע גם הכינוי של המשתמש. האפליקציה צריכה שני סוגי מידע: פרטי החשבון של המשתמש המחובר ותוכן הפוסטים בספר האורחים. הגרסה ה'סינכרונית' של האפליקציה הזו עשויה להיראות כך:
יש כאן שתי פעולות קלט/פלט עצמאיות: קבלת הישות Account ואחזור הישויות Guestbook האחרונות. באמצעות ה-API הסינכרוני, הפעולות האלה מתבצעות אחת אחרי השנייה. אנחנו מחכים לקבל את פרטי החשבון לפני שאנחנו מאחזרים את הישויות של ספר האורחים. אבל האפליקציה לא צריכה את פרטי החשבון באופן מיידי. אנחנו יכולים לנצל את זה ולהשתמש בממשקי API אסינכרוניים:
בגרסה הזו של הקוד, קודם נוצרים שני Futures (acct_future ו-recent_entries_future), ואז המערכת מחכה להם. השרת מטפל בשתי הבקשות במקביל.
כל בקשה להפעלת פונקציה _async() יוצרת אובייקט Future ושולחת בקשה לשרת Datastore. השרת יכול להתחיל לטפל בבקשה באופן מיידי. התשובות מהשרת עשויות להתקבל בכל סדר שרירותי. האובייקט Future מקשר בין התשובות לבקשות התואמות שלהן.
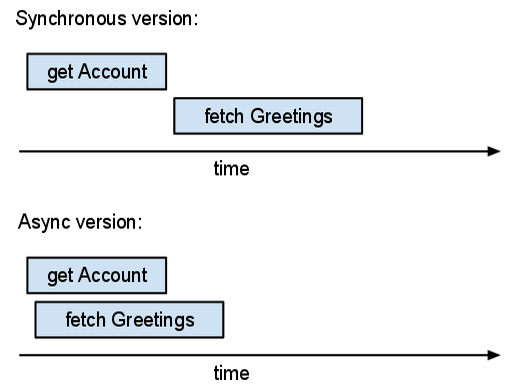
הזמן הכולל (האמיתי) שמושקע בגרסה האסינכרונית שווה בערך לזמן המקסימלי של הפעולות. הזמן הכולל שחלף בגרסה הסינכרונית חורג מסכום זמני הפעולה. אם אתם יכולים להריץ יותר פעולות במקביל, פעולות אסינכרוניות יעזרו לכם יותר.
שימוש ב-Tasklets
טסקלט של NDB הוא קטע קוד שיכול לפעול במקביל לקוד אחר. אם כותבים tasklet, האפליקציה יכולה להשתמש בו בדומה לשימוש בפונקציית NDB אסינכרונית: היא קוראת ל-tasklet, שמחזיר Future; מאוחר יותר, קריאה לשיטת get_result() של Future מקבלת את התוצאה.
Tasklets הם דרך לכתוב פונקציות מקבילות בלי שרשורים. ה-tasklets מופעלים על ידי לולאת אירועים ויכולים להשהות את עצמם כדי לחסום קלט/פלט או פעולה אחרת באמצעות הצהרת yield. המושג של פעולת חסימה מופשט למחלקה Future, אבל tasklet יכול גם yield RPC כדי לחכות לסיום ה-RPC. כשיש ל-tasklet תוצאה, הוא raise חריגה מסוג ndb.Return. לאחר מכן, NDB משייך את התוצאה ל-Future שyield קודם לכן.
כשכותבים טסקלט של NDB, משתמשים ב-yield וב-raise בצורה לא רגילה. לכן, אם תחפשו דוגמאות לשימוש בהם, סביר להניח שלא תמצאו קוד כמו NDB tasklet.
כדי להפוך פונקציה ל-tasklet של NDB:
- מוסיפים את הקישוט
@ndb.taskletלפונקציה, - להחליף את כל הקריאות למאגר נתונים סינכרוני בקריאות למאגר נתונים אסינכרוני,
yield - הפונקציה 'מחזירה' את ערך ההחזרה שלה עם
raise ndb.Return(retval)(לא נדרש אם הפונקציה לא מחזירה כלום).
אפליקציה יכולה להשתמש ב-tasklets כדי לשלוט טוב יותר בממשקי API אסינכרוניים. לדוגמה, נניח שיש לכם את הסכימה הבאה:
...
כשמציגים הודעה, הגיוני להציג את הכינוי של המחבר. הדרך ה'סינכרונית' לאחזור הנתונים כדי להציג רשימה של הודעות עשויה להיראות כך:
לצערנו, הגישה הזו לא יעילה. יכול להיות שתראו את דפוס ה'מדרגות' הבא.
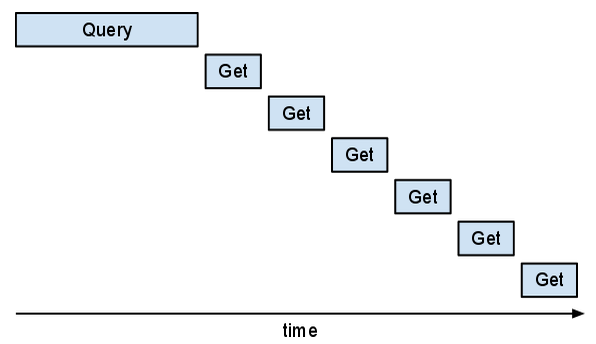
החלק הזה של התוכנית יפעל מהר יותר אם פעולות ה-Get יוכלו לחפוף.
אפשר לשכתב את הקוד כדי להשתמש ב-get_async, אבל קשה לעקוב אחרי הבקשות וההודעות האסינכרוניות ששייכות זו לזו.
האפליקציה יכולה להגדיר פונקציה משלה מסוג async על ידי הפיכתה ל-tasklet. כך תוכלו לארגן את הקוד בצורה פחות מבלבלת.
בנוסף, במקום להשתמש ב-acct = key.get() או ב-acct = key.get_async().get_result(), הפונקציה צריכה להשתמש ב-acct = yield key.get_async().
הפקודה yield אומרת ל-NDB שזה מקום טוב להשהות את ה-tasklet הזה ולאפשר ל-tasklet אחרים לפעול.
הוספת הקישוט @ndb.tasklet
לפונקציית גנרטור גורמת לפונקציה להחזיר Future במקום אובייקט גנרטור. בתוך ה-tasklet, כל yield של Future ממתין לתוצאה של Future ומחזיר אותה.
לדוגמה:
שימו לב: למרות שהפונקציה get_async() מחזירה Future, מסגרת ה-tasklet גורמת לביטוי yield להחזיר את התוצאה של Future למשתנה acct.
הפונקציה map() נקראת callback() כמה פעמים.
אבל הפונקציה yield ..._async() ב-callback()
מאפשרת למתזמן של NDB לשלוח הרבה בקשות אסינכרוניות לפני שהוא מחכה
לסיום של אחת מהן.
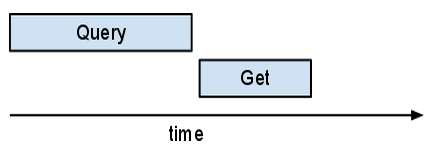
אם תבדקו את זה ב-Appstats, יכול להיות שתופתעו לגלות שהפעולות האלה לא חופפות זו לזו, אלא מתבצעות כולן באותה בקשה. NDB מטמיע autobatcher. ה-autobatcher מאגד כמה בקשות ב-RPC אחד באצווה לשרת; הוא עושה את זה כך שכל עוד יש עוד עבודה לעשות (יכול להיות שעוד קריאה חוזרת תפעל) הוא אוסף מפתחות. ברגע שאחת מהתוצאות נדרשת, הכלי לאיחוד בקשות שולח את ה-RPC של הקבוצה. בניגוד לרוב הבקשות, השאילתות לא "מצורפות".
כשמפעילים tasklet, מרחב השמות שמוגדר לו כברירת מחדל נקבע לפי מה שהיה מוגדר כברירת מחדל כשה-tasklet נוצר, או לפי מה שהוגדר כברירת מחדל על ידי ה-tasklet בזמן ההפעלה. במילים אחרות, מרחב השמות שמוגדר כברירת מחדל לא משויך להקשר ולא מאוחסן בו, ושינוי מרחב השמות שמוגדר כברירת מחדל במשימה אחת לא משפיע על מרחב השמות שמוגדר כברירת מחדל במשימות אחרות, למעט אלה שנוצרו ממנה.
Tasklets, Parallel Queries, Parallel Yield
אתם יכולים להשתמש ב-tasklets כדי שכמה שאילתות יאחזרו רשומות בו-זמנית. לדוגמה, נניח שהאפליקציה שלכם כוללת דף שמציג את התוכן של עגלת קניות ורשימה של מבצעים מיוחדים. יכול להיות שהסכימה תיראה כך:
פונקציה 'סינכרונית' שמקבלת פריטים בעגלת קניות ומבצעים מיוחדים עשויה להיראות כך:
בדוגמה הזו נעשה שימוש בשאילתות כדי לאחזר רשימות של פריטים בעגלת הקניות ושל מבצעים. לאחר מכן, הפונקציה get_multi() מאחזרת פרטים על פריטי המלאי. (הפונקציה הזו לא משתמשת ישירות בערך ההחזרה של get_multi(). היא קוראת ל-get_multi() כדי לאחזר את כל פרטי המלאי למטמון, כדי שאפשר יהיה לקרוא אותם במהירות בהמשך). הפונקציה get_multi משלבת הרבה פעולות אחזור לבקשה אחת. אבל פעולות האחזור של השאילתות מתבצעות אחת אחרי השנייה. כדי שפעולות האחזור האלה יתבצעו בו-זמנית, צריך לחפוף בין שתי השאילתות:
הקריאה get_multi()
עדיין נפרדת: היא תלויה בתוצאות השאילתה, ולכן אי אפשר לשלב אותה עם השאילתות.
נניח שהאפליקציה הזו צריכה לפעמים את העגלה, לפעמים את המבצעים, ולפעמים את שניהם. אתם רוצים לארגן את הקוד כך שתהיה פונקציה להצגת העגלה ופונקציה להצגת המבצעים. אם האפליקציה קוראת לפונקציות האלה יחד, באופן אידיאלי השאילתות שלהן יכולות 'להחפוף'. כדי לעשות את זה, צריך להפוך את הפונקציות האלה ל-tasklets:
הפעולה yield x, y חשובה
אבל קל לפספס אותה. אם אלה היו שתי הצהרות yield נפרדות, הן היו מתבצעות ברצף. אבל yield של טאפל של tasklets הוא parallel yield: ה-tasklets יכולים לפעול במקביל, והפעולה yield מחכה שכולם יסיימו ומוחזרות התוצאות. (בשפות תכנות מסוימות, הפעולה הזו נקראת barrier).
אם תהפכו קטע קוד אחד ל-tasklet, סביר להניח שתרצו לעשות זאת שוב בקרוב. אם אתם מבחינים בקוד 'סינכרוני' שיכול לפעול במקביל ל-tasklet, כדאי להפוך אותו גם ל-tasklet.
אחר כך אפשר להריץ אותו במקביל באמצעות yield מקביל.
אם כותבים פונקציית בקשה (פונקציית בקשה של webapp2, פונקציית תצוגה של Django וכו') שתהיה tasklet, היא לא תפעל כמו שרוצים: היא תניב אבל אז תפסיק לפעול. במצב כזה, צריך להוסיף לפונקציה את הדקורטור @ndb.synctasklet. הדקורטור @ndb.synctasklet דומה לדקורטור @ndb.tasklet, אבל הוא משתנה כדי לקרוא ל-get_result() ב-tasklet. כך ה-tasklet הופך לפונקציה שמחזירה את התוצאה שלה בדרך הרגילה.
Query Iterators ב-Tasklets
כדי לבצע איטרציה על תוצאות של שאילתה ב-tasklet, משתמשים בתבנית הבאה:
זוהי הגרסה שמתאימה ל-tasklet של הקוד הבא:
שלוש השורות המודגשות בגרסה הראשונה הן המקבילה הידידותית ל-tasklet של השורה המודגשת היחידה בגרסה השנייה.
אפשר להשהות Tasklets רק במילת מפתח yield.
לולאת ה-for ללא yield לא מאפשרת להפעיל tasklets אחרים.
יכול להיות שתשאלו למה הקוד הזה משתמש באיטרטור של שאילתות בכלל, במקום לאחזר את כל הישויות באמצעות qry.fetch_async(). יכול להיות שיש באפליקציה כל כך הרבה ישויות שהן לא נכנסות ל-RAM. אולי אתם מחפשים ישות מסוימת ואתם יכולים להפסיק את האיטרציה ברגע שאתם מוצאים אותה, אבל אתם לא יכולים לבטא את קריטריוני החיפוש רק באמצעות שפת השאילתות. אתם יכולים להשתמש באיטרטור כדי לטעון ישויות לבדיקה, ואז לצאת מהלולאה כשאתם מוצאים את מה שאתם רוצים.
Async Urlfetch with NDB
ל-NDB Context יש פונקציית urlfetch() אסינכרונית שפועלת במקביל בצורה טובה עם tasklets של NDB, לדוגמה:
לשירות אחזור של כתובות אתרים יש API משלו לבקשות לא סנכרוניות. הוא בסדר, אבל לא תמיד קל להשתמש בו עם NDB tasklets.
שימוש בעסקאות אסינכרוניות
יכול להיות שגם העסקאות יתבצעו באופן אסינכרוני. אפשר להעביר פונקציה קיימת אל ndb.transaction_async() או להשתמש במעצב @ndb.transactional_async.
בדומה לפונקציות אסינכרוניות אחרות, הפונקציה הזו תחזיר NDB Future:
עסקאות פועלות גם עם tasklets. לדוגמה, אפשר לשנות את הקוד update_counter ל-yield בזמן שממתינים ל-RPCs חוסמים:
שימוש ב-Future.wait_any()
לפעמים רוצים לשלוח כמה בקשות אסינכרוניות ולהחזיר תשובה כשהראשונה מסתיימת. אפשר לעשות את זה באמצעות שיטת המחלקה ndb.Future.wait_any():
לצערנו, אין דרך נוחה להפוך את זה ל-tasklet. פעולת yield מקבילית מחכה שכל פעולות Future יסתיימו, כולל אלה שלא רוצים לחכות להן.