
Está a ver a documentação do Apigee e do Apigee Hybrid.
Ver documentação do
Apigee Edge.
Sintomas
As implementações de proxies de API falham com o aviso No active runtime pods na IU do Apigee hybrid.
Mensagens de erro
O aviso Nenhum pod de tempo de execução ativo é apresentado na caixa de diálogo Detalhes junto à mensagem de erro Problemas de implementação em ENVIRONMENT: REVISION_NUMBER na página do proxy da API:
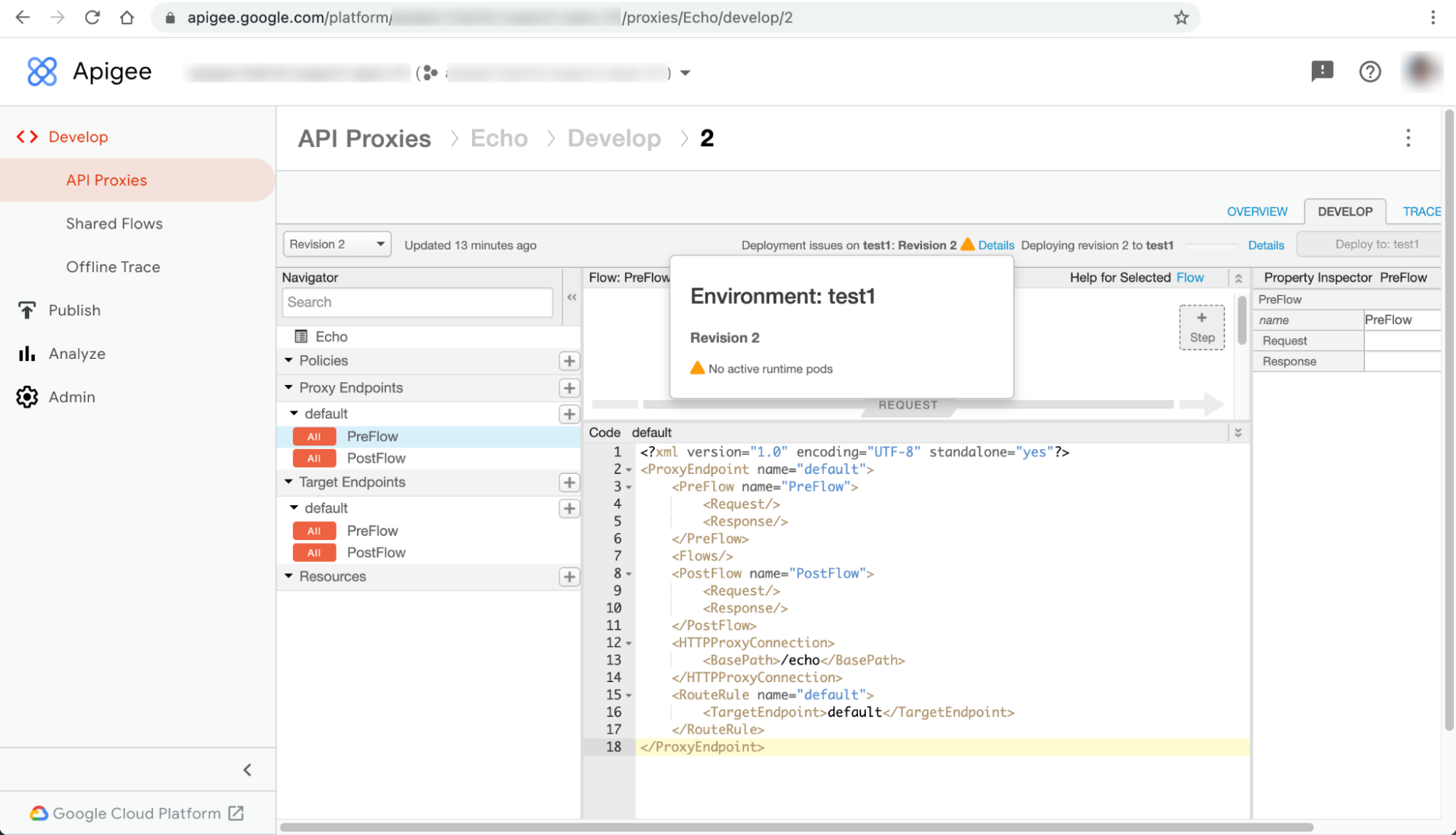
Este problema pode manifestar-se como erros diferentes noutras páginas de recursos da IU. Seguem-se alguns exemplos de mensagens de erro:
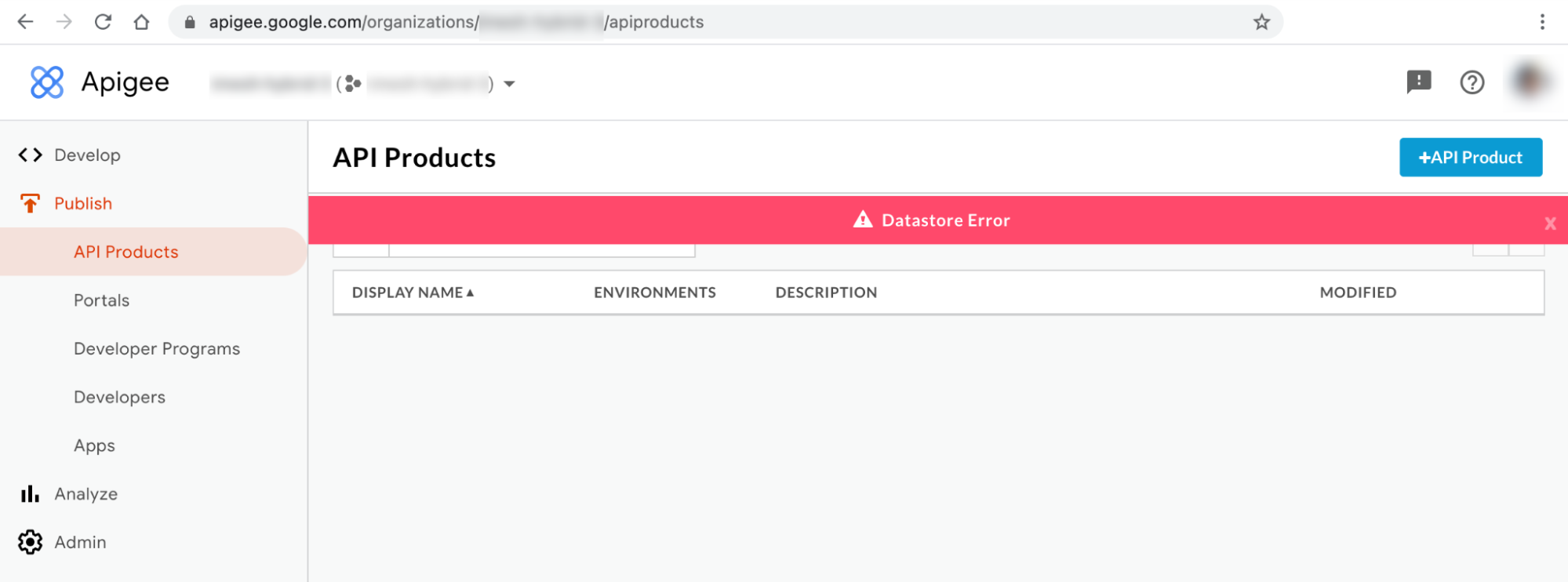
Mensagem de erro da IU híbrida n.º 1: erro de armazenamento de dados
Pode observar o Erro do Datastore nas páginas Produtos da API e Apps da IU híbrida, conforme mostrado abaixo:
Mensagem de erro da IU híbrida n.º 2: erro interno do servidor
Pode observar o Erro interno do servidor na página Programadores da IU, conforme mostrado abaixo:

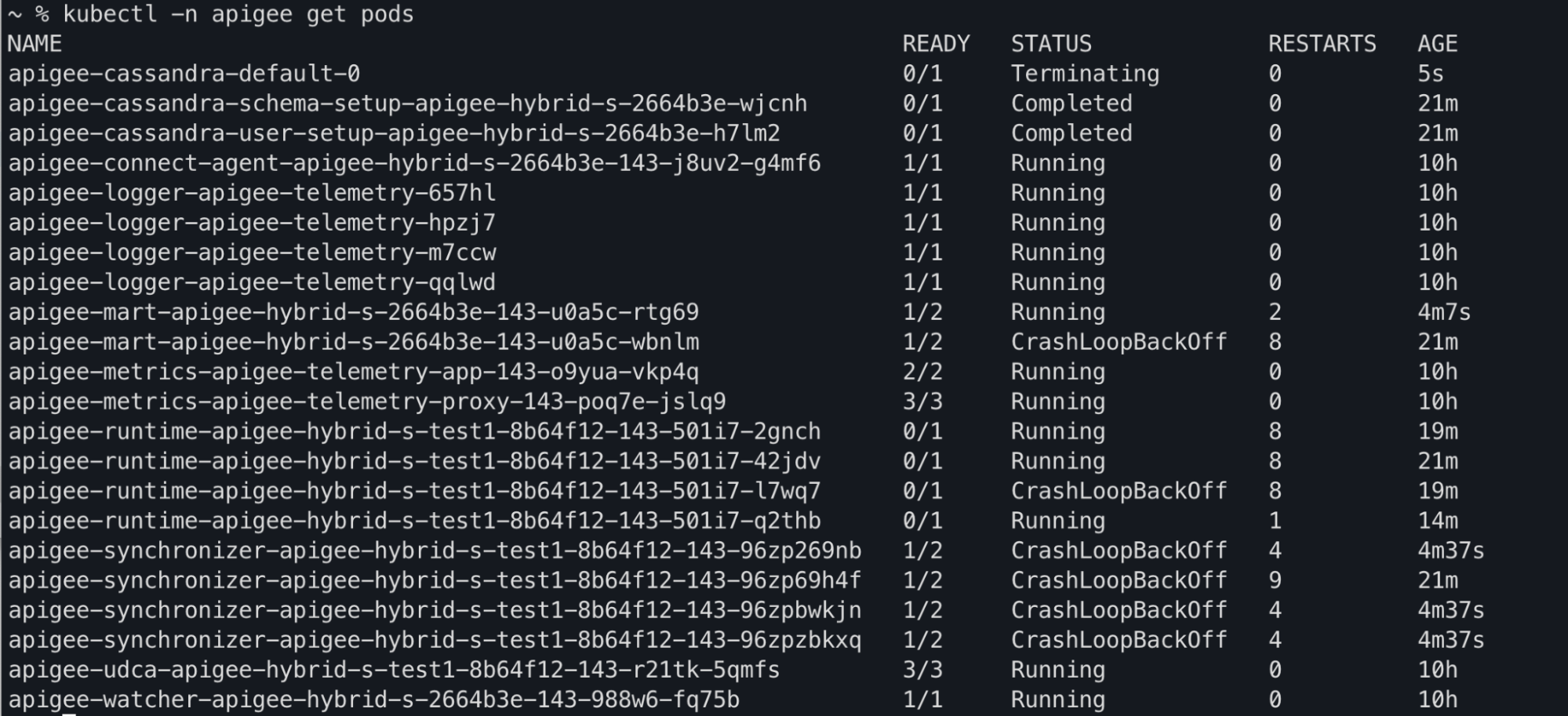
Resultado do comando Kubectl
Pode observar que os estados dos pods apiege-mart, apigee-runtime e apigee-
synchronizer são alterados para CrashLoopBackOff na saída do comando kubectl get pods:
Mensagens de erro do registo de componentes
Vai observar os seguintes erros de falha de teste de atividade nos apigee-runtime
registos de pods nas versões híbridas do Apigee >= 1.4.0:
{"timestamp":"1621575431454","level":"ERROR","thread":"qtp365724939-205","mdc":{"targetpath":"/v1/pr
obes/live"},"logger":"REST","message":"Error occurred : probe failed Probe cps-datastore-
connectivity-liveliness-probe failed due to com.apigee.probe.model.ProbeFailedException{ code =
cps.common.datastoreConnectionNotHealthy, message = Datastore connection not healthy, associated
contexts =
[]}\n\n\tcom.apigee.probe.ProbeAPI.getResponse(ProbeAPI.java:66)\n\tcom.apigee.probe.ProbeAPI.getLiv
eStatus(ProbeAPI.java:55)\n\tsun.reflect.GeneratedMethodAccessor52.invoke(Unknown
Source)\n\tsun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)\n\t
","context":"apigee-service-
logs","severity":"ERROR","class":"com.apigee.rest.framework.container.ExceptionMapper","method":"toR
esponse"}
{"timestamp":"1621575431454","level":"ERROR","thread":"qtp365724939-205","mdc":{"targetpath":"/v1/pr
obes/live"},"logger":"REST","message":"Returning error response : ErrorResponse{errorCode =
probe.ProbeRunError, errorMessage = probe failed Probe cps-datastore-connectivity-liveliness-probe
failed due to com.apigee.probe.model.ProbeFailedException{ code =
cps.common.datastoreConnectionNotHealthy, message = Datastore connection not healthy, associated
contexts = []}}","context":"apigee-service-
logs","severity":"ERROR","class":"com.apigee.rest.framework.container.ExceptionMapper","method":"toR
esponse"}
Vai observar o seguinte Cannot build a cluster without contact points erro
nos registos de pods do Apigee Hybrid nas versões >= 1.4.0:apigee-synchronizer
{"timestamp":"1621575636434","level":"ERROR","thread":"main","logger":"KERNEL.DEPLOYMENT","message":
"ServiceDeployer.deploy() : Got a life cycle exception while starting service [SyncService, Cannot
build a cluster without contact points] : {}","context":"apigee-service-
logs","exception":"java.lang.IllegalArgumentException: Cannot build a cluster without contact
points\n\tat com.datastax.driver.core.Cluster.checkNotEmpty(Cluster.java:134)\n\tat
com.datastax.driver.core.Cluster.<init>(Cluster.java:127)\n\tat
com.datastax.driver.core.Cluster.buildFrom(Cluster.java:193)\n\tat
com.datastax.driver.core.Cluster$Builder.build(Cluster.java:1350)\n\tat
io.apigee.persistence.PersistenceContext.newCluster(PersistenceContext.java:214)\n\tat
io.apigee.persistence.PersistenceContext.<init>(PersistenceContext.java:48)\n\tat
io.apigee.persistence.ApplicationContext.<init>(ApplicationContext.java:19)\n\tat
io.apigee.runtimeconfig.service.RuntimeConfigServiceImpl.<init>(RuntimeConfigServiceImpl.java:75)
\n\tat
io.apigee.runtimeconfig.service.RuntimeConfigServiceFactory.newInstance(RuntimeConfigServiceFactory.
java:99)\n\tat
io.apigee.common.service.AbstractServiceFactory.initializeService(AbstractServiceFactory.java:301)\n
\tat
...","severity":"ERROR","class":"com.apigee.kernel.service.deployment.ServiceDeployer","method":"sta
rtService"}
Vai observar os seguintes erros de falha da sondagem de atividade nos registos do pod apigee-mart nas versões híbridas do Apigee >= 1.4.0:
{"timestamp":"1621576757592","level":"ERROR","thread":"qtp991916558-144","mdc":{"targetpath":"/v1/pr
obes/live"},"logger":"REST","message":"Error occurred : probe failed Probe cps-datastore-
connectivity-liveliness-probe failed due to com.apigee.probe.model.ProbeFailedException{ code =
cps.common.datastoreConnectionNotHealthy, message = Datastore connection not healthy, associated
contexts =
[]}\n\n\tcom.apigee.probe.ProbeAPI.getResponse(ProbeAPI.java:66)\n\tcom.apigee.probe.ProbeAPI.getLiv
eStatus(ProbeAPI.java:55)\n\tsun.reflect.NativeMethodAccessorImpl.invoke0(Native
Method)\n\tsun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)\n\t","conte
xt":"apigee-service-
logs","severity":"ERROR","class":"com.apigee.rest.framework.container.ExceptionMapper","method":"toR
esponse"}
{"timestamp":"1621576757593","level":"ERROR","thread":"qtp991916558-144","mdc":{"targetpath":"/v1/pr
obes/live"},"logger":"REST","message":"Returning error response : ErrorResponse{errorCode =
probe.ProbeRunError, errorMessage = probe failed Probe cps-datastore-connectivity-liveliness-probe
failed due to com.apigee.probe.model.ProbeFailedException{ code =
cps.common.datastoreConnectionNotHealthy, message = Datastore connection not healthy, associated
contexts = []}}","context":"apigee-service-
logs","severity":"ERROR","class":"com.apigee.rest.framework.container.ExceptionMapper","method":"toR
esponse"}Informações sobre o erro No active runtime pods
Na versão 1.4.0 do Apigee hybrid, a funcionalidade de teste de atividade foi adicionada aos pods apigee-runtime e apigee-mart para verificar o estado dos pods do Cassandra. Se todos os pods do Cassandra ficarem indisponíveis, as sondas de atividade dos pods apigee-runtime e apigee-mart falham. Assim, os pods apigee-runtime e apigee-mart entram no estado CrashLoopBackOff , o que faz com que as implementações de proxies de API falhem com o aviso No active runtime pods.
O pod apigee-synchronizer também passa para o estado CrashLoopBackOff devido à indisponibilidade dos pods do Cassandra.
Causas possíveis
Seguem-se algumas possíveis causas deste erro:
| Causa | Descrição |
|---|---|
| Os pods do Cassandra estão inativos | Os pods do Cassandra estão inativos. Por conseguinte, os pods do apigee-runtime não vão conseguir comunicar com a base de dados do Cassandra. |
| Réplica do Cassandra configurada com apenas um pod | Ter apenas um pod do Cassandra pode tornar-se um ponto único de falha. |
Causa: os pods do Cassandra estão inativos
Durante o processo de implementação do proxy de API, os pods apigee-runtime estabelecem ligação à base de dados Cassandra para obter recursos, como mapas de valores-chave (KVMs) e caches, definidos no proxy de API. Se não existirem pods do Cassandra em execução, os pods do apigee-runtime não vão conseguir estabelecer ligação à base de dados do Cassandra. Isto leva à falha da implementação do proxy de API.
Diagnóstico
- Liste os pods do Cassandra:
kubectl -n apigee get pods -l app=apigee-cassandra
Exemplo de saída 1:
NAME READY STATUS RESTARTS AGE apigee-cassandra-default-0 0/1 Pending 0 9m23s
Exemplo de saída 2:
NAME READY STATUS RESTARTS AGE apigee-cassandra-0 0/1 CrashLoopBackoff 0 10m
- Valide o estado de cada pod do Cassandra. O estado de todos os pods do Cassandra deve estar no estado
Running. Se algum dos pods do Cassandra estiver num estado diferente, esse pode ser o motivo deste problema. Execute os seguintes passos para resolver o problema:
Resolução
- Se algum dos pods do Cassandra estiver no estado
Pending, consulte o artigo Os pods do Cassandra estão bloqueados no estado pendente para resolver o problema. - Se algum dos pods do Cassandra estiver no estado
CrashLoopBackoff, consulte o artigo Os pods do Cassandra estão bloqueados no estado CrashLoopBackoff para resolver o problema.Exemplo de saída:
kubectl -n apigee get pods -l app=apigee-runtime NAME READY STATUS RESTARTS AGE apigee-runtime-apigee-hybrid-s-test1-8b64f12-143-501i7-2gnch 1/1 Running 13 43m apigee-runtime-apigee-hybrid-s-test1-8b64f12-143-501i7-42jdv 1/1 Running 13 45m apigee-runtime-apigee-hybrid-s-test1-8b64f12-143-501i7-l7wq7 1/1 Running 13 43m apigee-runtime-apigee-hybrid-s-test1-8b64f12-143-501i7-q2thb 1/1 Running 8 38m
kubectl -n apigee get pods -l app=apigee-mart NAME READY STATUS RESTARTS AGE apigee-mart-apigee-hybrid-s-2664b3e-143-u0a5c-rtg69 2/2 Running 8 28m
kubectl -n apigee get pods -l app=apigee-synchronizer NAME READY STATUS RESTARTS AGE apigee-synchronizer-apigee-hybrid-s-test1-8b64f12-143-96zp269nb 2/2 Running 10 29m apigee-synchronizer-apigee-hybrid-s-test1-8b64f12-143-96zp2w2jp 2/2 Running 0 4m40s apigee-synchronizer-apigee-hybrid-s-test1-8b64f12-143-96zpkfkvq 2/2 Running 0 4m40s apigee-synchronizer-apigee-hybrid-s-test1-8b64f12-143-96zpxmzhn 2/2 Running 0 4m40s
Causa: réplica do Cassandra configurada com apenas um pod
Se a contagem de réplicas do Cassandra estiver configurada para um, só vai estar disponível um pod do Cassandra no tempo de execução. Como resultado, os pods apigee-runtime podem ter problemas de conetividade
se esse pod do Cassandra ficar indisponível durante um determinado período.
Diagnóstico
- Obtenha o conjunto com estado do Cassandra e verifique a contagem de réplicas atual:
kubectl -n apigee get statefulsets -l app=apigee-cassandra
Exemplo de saída:
NAME READY AGE apigee-cassandra-default 1/1 21m
- Se a contagem de réplicas estiver configurada como 1, siga os passos abaixo para aumentá-la para um número superior.
Resolução
As implementações de não produção do Apigee Hybrid podem ter a contagem de réplicas do Cassandra definida como 1. Se a elevada disponibilidade do Cassandra for importante em implementações de não produção, aumente o número de réplicas para 3 para resolver este problema.
Siga estes passos para resolver este problema:
- Atualize o ficheiro
overrides.yamle defina a contagem de réplicas do Cassandra como 3:cassandra: replicaCount: 3
Para obter informações de configuração do Cassandra, consulte a Referência de propriedades de configuração.
- Aplique a configuração acima através do Helm:
Execução de ensaio:
helm upgrade datastore apigee-datastore/ \ --install \ --namespace APIGEE_NAMESPACE \ --atomic \ -f OVERRIDES_FILE \ --dry-run
Instale o gráfico Helm
helm upgrade datastore apigee-datastore/ \ --install \ --namespace APIGEE_NAMESPACE \ --atomic \ -f OVERRIDES_FILE
- Obtenha o conjunto com estado do Cassandra e verifique a contagem de réplicas atual:
kubectl -n get statefulsets -l app=apigee-cassandra
Exemplo de saída:
NAME READY AGE apigee-cassandra-default 3/3 27m
- Obtenha os pods do Cassandra e verifique a contagem de instâncias atual. Se nem todos os pods estiverem prontos e
no estado
Running, aguarde que os novos pods do Cassandra sejam criados e ativados:kubectl -n get pods -l app=apigee-cassandra
Exemplo de saída:
NAME READY STATUS RESTARTS AGE apigee-cassandra-default-0 1/1 Running 0 29m apigee-cassandra-default-1 1/1 Running 0 21m apigee-cassandra-default-2 1/1 Running 0 19m
Exemplo de saída:
kubectl -n apigee get pods -l app=apigee-runtime NAME READY STATUS RESTARTS AGE apigee-runtime-apigee-hybrid-s-test1-8b64f12-143-501i7-2gnch 1/1 Running 13 43m apigee-runtime-apigee-hybrid-s-test1-8b64f12-143-501i7-42jdv 1/1 Running 13 45m apigee-runtime-apigee-hybrid-s-test1-8b64f12-143-501i7-l7wq7 1/1 Running 13 43m apigee-runtime-apigee-hybrid-s-test1-8b64f12-143-501i7-q2thb 1/1 Running 8 38m
kubectl -n apigee get pods -l app=apigee-mart NAME READY STATUS RESTARTS AGE apigee-mart-apigee-hybrid-s-2664b3e-143-u0a5c-rtg69 2/2 Running 8 28m
kubectl -n apigee get pods -l app=apigee-synchronizer NAME READY STATUS RESTARTS AGE apigee-synchronizer-apigee-hybrid-s-test1-8b64f12-143-96zp269nb 2/2 Running 10 29m apigee-synchronizer-apigee-hybrid-s-test1-8b64f12-143-96zp2w2jp 2/2 Running 0 4m40s apigee-synchronizer-apigee-hybrid-s-test1-8b64f12-143-96zpkfkvq 2/2 Running 0 4m40s apigee-synchronizer-apigee-hybrid-s-test1-8b64f12-143-96zpxmzhn 2/2 Running 0 4m40s
Tem de recolher informações de diagnóstico
Se o problema persistir mesmo depois de seguir as instruções acima, recolha as seguintes informações de diagnóstico e, em seguida, contacte o apoio ao cliente do Google Cloud.
- ID de projeto do Google Cloud
- Organização do Apigee Hybrid/Apigee
- Para o Apigee Hybrid:
overrides.yaml, ocultando quaisquer informações confidenciais - Estado do pod do Kubernetes em todos os namespaces:
kubectl get pods -A > kubectl-pod-status`date +%Y.%m.%d_%H.%M.%S`.txt
- Captura de informações do cluster do Kubernetes:
# generate kubernetes cluster-info dump kubectl cluster-info dump -A --output-directory=/tmp/kubectl-cluster-info-dump # zip kubernetes cluster-info dump zip -r kubectl-cluster-info-dump`date +%Y.%m.%d_%H.%M.%S`.zip /tmp/kubectl-cluster-info-dump/*
Referências
- Dimensionar o Cassandra horizontalmente
- Introspeção e depuração de aplicações Kubernetes
- Referência rápida do kubectl