
In diesem Dokument wird beschrieben, wie Sie Logging und Monitoring für Systemkomponenten in Google Distributed Cloud (nur Software) für VMware konfigurieren.
Cloud Logging, Cloud Monitoring und Google Cloud Managed Service for Prometheus sind standardmäßig aktiviert.
Weitere Informationen zu den Optionen finden Sie unter Übersicht über Logging und Monitoring.
Überwachte Ressourcen
Mit überwachten Ressourcen stellt Google Ressourcen wie Cluster, Knoten, Pods und Container dar. Weitere Informationen finden Sie in der Dokumentation zu den Typen überwachter Ressourcen von Cloud Monitoring.
Zum Abfragen von Logs und Messwerten müssen Sie mindestens folgende Ressourcenlabels kennen:
project_id: Projekt-ID des Logging-Monitoring-Projekts des Clusters. Sie haben diesen Wert im Feldstackdriver.projectIDIhrer Clusterkonfigurationsdatei angegeben.location: Eine Google Cloud Region, in der Sie Ihre Cloud Monitoring-Messwerte weiterleiten und speichern möchten. Sie geben die Region während der Installation im Feldstackdriver.clusterLocationIhrer Clusterkonfigurationsdatei an. Wir empfehlen, eine Region auszuwählen, die sich in der Nähe Ihres lokalen Rechenzentrums befindet.Sie geben den Routing- und Speicherort für Cloud Logging-Logs in der Log Router-Konfiguration an. Weitere Informationen zum Log-Routing finden Sie unter Routing und Speicher.
cluster_name: Clustername, den Sie beim Erstellen des Clusters ausgewählt haben.Sie können den
cluster_name-Wert entweder für den Administrator- oder den Nutzercluster abrufen, wenn Sie die benutzerdefinierte Stackdriver-Ressource prüfen:kubectl get stackdriver stackdriver --namespace kube-system \ --kubeconfig CLUSTER_KUBECONFIG --output yaml | grep 'clusterName:'
Dabei gilt:
CLUSTER_KUBECONFIGist der Pfad zur kubeconfig-Datei des Administrator- oder Nutzerclusters, für den der Clustername erforderlich ist.
Routing von Logs und Messwerten
Der Stackdriver Log Forwarder (stackdriver-log-forwarder) sendet Logs von jeder Knotenmaschine an Cloud Logging. Der GKE-Messwert-Agent (gke-metrics-agent) sendet Messwerte von jeder Knoten-VM an Cloud Monitoring. Bevor die Logs und Messwerte gesendet werden, fügt der Stackdriver-Operator (stackdriver-operator) jedem Logeintrag und Messwert den Wert aus dem Feld clusterLocation in der benutzerdefinierten Ressource stackdriver hinzu, bevor sie an Google Cloudweitergeleitet werden. Außerdem werden die Logs und Messwerte dem Google Cloud Projekt zugewiesen, das in der Spezifikation der benutzerdefinierten stackdriver-Ressource (spec.projectID) angegeben ist. Die stackdriver-Ressource ruft Werte für die Felder clusterLocation und projectID aus den Feldern stackdriver.clusterLocation und stackdriver.projectID im Abschnitt clusterOperations} der Clusterressource beim Erstellen des Clusters ab.
Alle Messwerte und Logeinträge, die von Stackdriver-Agents gesendet werden, werden an einen globalen Erfassungs-Endpunkt weitergeleitet. Von dort werden die Daten an den nächstgelegenen erreichbaren regionalen Google Cloud Endpunkt weitergeleitet, um die Zuverlässigkeit des Datentransports zu gewährleisten.
Sobald der globale Endpunkt den Messwert oder Logeintrag empfängt, hängt das weitere Vorgehen vom Dienst ab:
Konfiguration des Logroutings: Wenn der Logging-Endpunkt eine Logmeldung empfängt, leitet Cloud Logging die Meldung über den Log-Router weiter. Die Senken und Filter in der Log Router-Konfiguration bestimmen, wie die Nachricht weitergeleitet wird. Sie können Logeinträge an Ziele wie regionale Logging-Buckets, in denen der Logeintrag gespeichert wird, oder an Pub/Sub weiterleiten. Weitere Informationen zur Funktionsweise des Log-Routings und zur Konfiguration finden Sie unter Routing und Speicher.
Weder das Feld
clusterLocationin der benutzerdefiniertenstackdriver-Ressource noch das FeldclusterOperations.locationin der Clusterspezifikation werden bei diesem Routingprozess berücksichtigt. Bei Logs wirdclusterLocationnur zum Labeln von Logeinträgen verwendet. Das kann beim Filtern im Log-Explorer hilfreich sein.Konfiguration des Messwertroutings: Wenn der Messwertendpunkt einen Messwerteintrag empfängt, leitet Cloud Monitoring den Eintrag automatisch an den vom Messwert angegebenen Ort weiter. Der Standort im Messwert stammt aus dem Feld
clusterLocationin der benutzerdefinierten Ressourcestackdriver.Konfiguration planen: Wenn Sie Cloud Logging und Cloud Monitoring konfigurieren, konfigurieren Sie auch den Log-Router und geben Sie einen geeigneten
clusterLocationmit Standorten an, die Ihren Anforderungen am besten entsprechen. Wenn Sie beispielsweise möchten, dass Logs und Messwerte am selben Ort gespeichert werden, legen SieclusterLocationauf dieselbe Google Cloud -Region fest, die Log Router für Ihr Google Cloud -Projekt verwendet.Konfiguration bei Bedarf aktualisieren: Sie können die Zieleinstellungen für Logs und Messwerte jederzeit aufgrund von Geschäftsanforderungen ändern, z. B. im Rahmen von Notfallwiederherstellungsplänen. Änderungen an der Log Router-Konfiguration im Feld Google Cloud und
clusterLocationder benutzerdefinierten Ressourcestackdriverwerden schnell wirksam.
Cloud Logging verwenden
Sie müssen nichts unternehmen, um Cloud Logging für einen Cluster zu aktivieren.
Sie müssen jedoch das Google Cloud -Projekt angeben, in dem Sie Logs aufrufen möchten. In der Clusterkonfigurationsdatei geben Sie das Google Cloud -Projekt im Abschnitt stackdriver an.
Sie können mit dem Log-Explorer in der Google Cloud -Konsole auf Logs zugreifen. So greifen Sie beispielsweise auf die Logs eines Containers zu:
- Öffnen Sie in der Google Cloud Console den Log-Explorer für Ihr Projekt.
- So finden Sie Logs für einen Container:
- Klicken Sie links oben auf das Drop-down-Menü für den Logkatalog und wählen Sie Kubernetes-Container aus.
- Wählen Sie den Clusternamen, den Namespace und dann einen Container aus der Hierarchie aus.
Logs für Controller im Bootstrap-Cluster ansehen
-
Rufen Sie in der Google Cloud Console die Seite Log-Explorer auf:
Wenn Sie diese Seite über die Suchleiste suchen, wählen Sie das Ergebnis aus, dessen Zwischenüberschrift Logging ist.
Führen Sie die folgende Abfrage im Abfrageeditor aus, um alle Logs für Controller im Bootstrap-Cluster aufzurufen:
"ADMIN_CLUSTER_NAME" resource.type="k8s_container" resource.labels.cluster_name="gkectl-bootstrap-cluster"
Wenn Sie die Logs für einen bestimmten Pod aufrufen möchten, bearbeiten Sie die Abfrage so, dass der Name des Pods enthalten ist:
resource.type="k8s_container" resource.labels.cluster_name="gkectl-bootstrap-cluster" resource.labels.pod_name="POD_NAME"
Cloud Monitoring verwenden
Sie müssen nichts unternehmen, um Cloud Monitoring für einen Cluster zu aktivieren.
Sie müssen jedoch das Google Cloud -Projekt angeben, in dem Sie Messwerte aufrufen möchten.
In der Clusterkonfigurationsdatei geben Sie das Google Cloud -Projekt im Abschnitt stackdriver an.
Mit Metrics Explorer können Sie aus über 1.500 Messwerten auswählen. So greifen Sie auf Metrics Explorer zu:
Wählen Sie in der Google Cloud Console Monitoring aus oder klicken Sie auf die folgende Schaltfläche:
Wählen Sie Ressourcen > Metrics Explorer.
Sie können Messwerte auch in Dashboards in der Google Cloud Console ansehen. Informationen zum Erstellen von Dashboards und zum Ansehen von Messwerten finden Sie unter Dashboards erstellen.
Monitoring-Daten auf Flottenebene ansehen
Eine Übersicht über die Ressourcennutzung Ihrer Flotte mit Cloud Monitoring-Daten, einschließlich Ihrer Google Distributed Cloud-Cluster, finden Sie in der Google Kubernetes Engine-Übersicht in der Google Cloud Console. Weitere Informationen finden Sie unter Cluster über die Google Cloud Konsole verwalten.
Standardmäßige Kontingentlimits in Cloud Monitoring
Für das Google Distributed Cloud-Monitoring gilt standardmäßig ein Limit von 6.000 API-Aufrufen pro Minute pro Projekt. Wenn Sie dieses Limit überschreiten, werden Ihre Messwerte möglicherweise nicht angezeigt. Wenn Sie ein höheres Monitoring-Limit benötigen, fordern Sie dieses über die Google Cloud Console an.
Managed Service for Prometheus verwenden
Google Cloud Managed Service for Prometheus ist Teil von Cloud Monitoring und ist standardmäßig verfügbar. Managed Service for Prometheus bietet unter anderem die folgenden Vorteile:
Sie können Ihr vorhandenes Prometheus-basiertes Monitoring weiterhin verwenden, ohne Ihre Benachrichtigungen und Grafana-Dashboards ändern zu müssen.
Wenn Sie sowohl GKE als auch Google Distributed Cloud verwenden, können Sie dasselbe PromQL für Messwerte in allen Ihren Clustern verwenden. Sie können auch den Tab PROMQL im Metrics Explorer in der Google Cloud Console verwenden.
Managed Service for Prometheus aktivieren und deaktivieren
Ab Google Distributed Cloud-Release 1.30.0-gke.1930 ist Managed Service for Prometheus immer aktiviert. In früheren Versionen können Sie die Stackdriver-Ressource stackdriver bearbeiten, um Managed Service for Prometheus zu aktivieren oder zu deaktivieren. Wenn Sie Managed Service for Prometheus für Clusterversionen vor 1.30.0-gke.1930 deaktivieren möchten, legen Sie spec.featureGates.enableGMPForSystemMetrics in der stackdriver-Ressource auf false fest.
Messwertdaten ansehen
Wenn Managed Service for Prometheus aktiviert ist, haben Messwerte für die folgenden Komponenten ein anderes Format für die Speicherung und Abfrage in Cloud Monitoring:
- kube-apiserver
- kube-scheduler
- kube-controller-manager
- Kubelet und cAdvisor
- kube-state-metrics
- node-exporter
Im neuen Format können Sie die oben genannten Messwerte mit der Prometheus Query Language (PromQL) abfragen.
PromQL-Beispiel:
histogram_quantile(0.95, sum(rate(apiserver_request_duration_seconds_bucket[5m])) by (le))
Grafana-Dashboards mit Managed Service for Prometheus konfigurieren
Wenn Sie Grafana mit Messwertdaten aus Managed Service for Prometheus verwenden möchten, folgen Sie der Anleitung unter Abfrage mit Grafana, um eine Grafana-Datenquelle zu authentifizieren und zu konfigurieren, damit Daten aus Managed Service for Prometheus abgefragt werden können.
Eine Reihe von Beispiel-Grafana-Dashboards ist im Repository anthos-samples auf GitHub verfügbar. So installieren Sie die Beispiel-Dashboards:
Laden Sie die
.json-Beispieldateien herunter:git clone https://github.com/GoogleCloudPlatform/anthos-samples.git cd anthos-samples/gmp-grafana-dashboards
Wenn Ihre Grafana-Datenquelle mit einem anderen Namen als
Managed Service for Prometheuserstellt wurde, ändern Sie das Felddatasourcein allen.json-Dateien:sed -i "s/Managed Service for Prometheus/[DATASOURCE_NAME]/g" ./*.json
Ersetzen Sie dabei [DATASOURCE_NAME] durch den Namen der Datenquelle in Ihrer Grafana, die auf den Prometheus-Dienst
frontendausgerichtet wurde.Rufen Sie die Grafana-Benutzeroberfläche in Ihrem Browser auf und wählen Sie im Menü Dashboards die Option + Importieren aus.
Laden Sie die
.json-Datei hoch oder kopieren Sie den Inhalt der Datei und fügen Sie ihn ein. Klicken Sie dann auf Laden. Wenn der Dateiinhalt geladen wurde, wählen Sie Importieren aus. Optional können Sie vor dem Importieren auch den Dashboard-Namen und die UID ändern.
Das importierte Dashboard sollte erfolgreich geladen werden, wenn Google Distributed Cloud und die Datenquelle richtig konfiguriert sind. Der folgende Screenshot zeigt beispielsweise das von
cluster-capacity.jsonkonfigurierte Dashboard.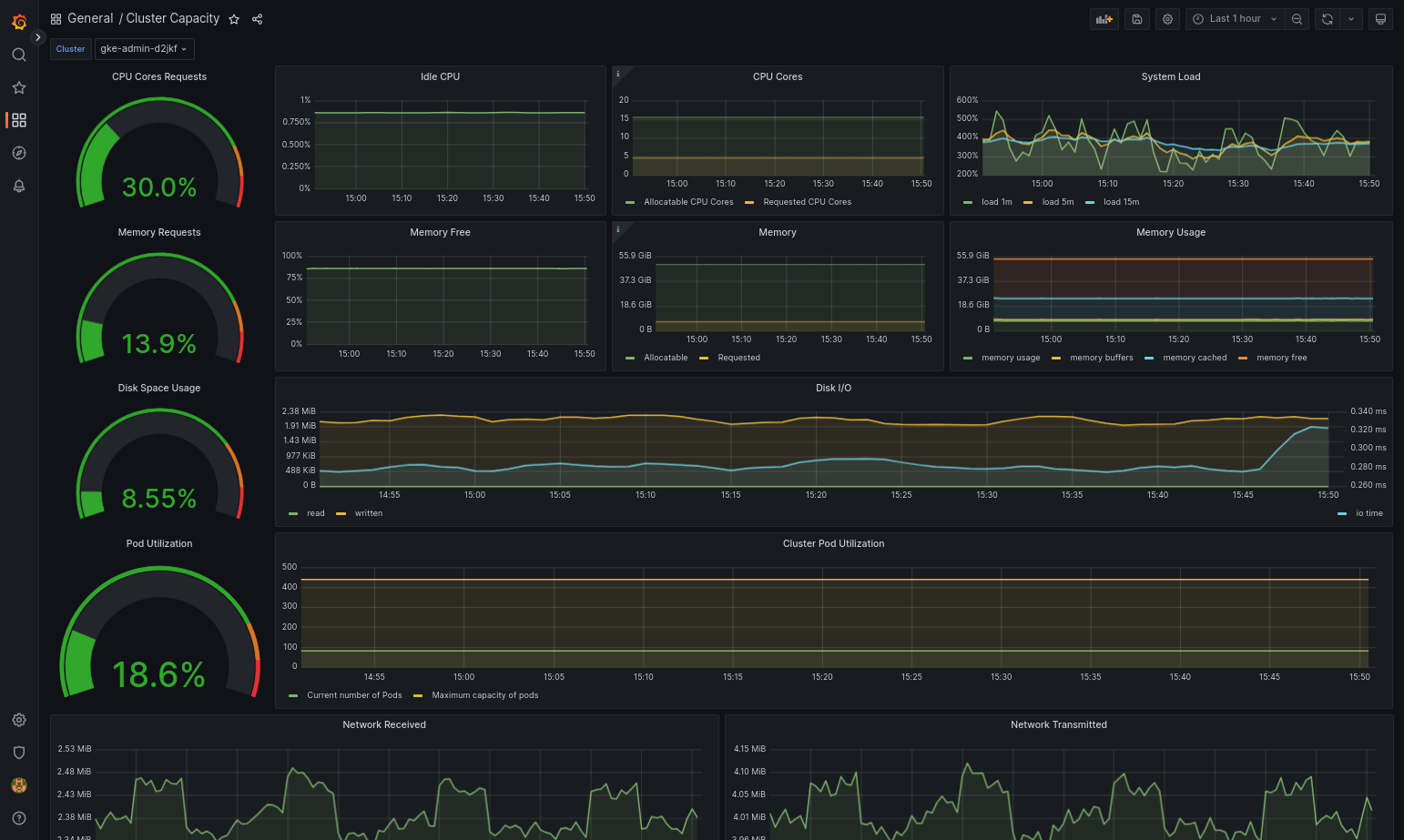
Weitere Informationen
Weitere Informationen zu Managed Service for Prometheus finden Sie unter:
Messwerte der GKE-Steuerungsebene sind mit PromQL kompatibel
Managed Service for Prometheus für Nutzeranwendungen in Google Distributed Cloud verwenden
Prometheus und Grafana verwenden
Ab Version 1.16 sind Prometheus und Grafana in neu erstellten Clustern nicht verfügbar. Wir empfehlen die Verwendung von Managed Service for Prometheus als Ersatz für das clusterinterne Monitoring.
Wenn Sie ein 1.15-Cluster, in dem Prometheus und Grafana aktiviert sind, auf Version 1.16 aktualisieren, funktionieren Prometheus und Grafana weiterhin wie gewohnt, werden aber nicht aktualisiert und erhalten keine Sicherheitspatches.
Wenn Sie alle Prometheus- und Grafana-Ressourcen nach dem Upgrade auf Version 1.16 löschen möchten, führen Sie den folgenden Befehl aus:
kubectl --kubeconfig KUBECONFIG delete -n kube-system \
statefulsets,services,configmaps,secrets,serviceaccounts,clusterroles,clusterrolebindings,certificates,deployments \
-l addons.gke.io/legacy-pg=true
Als Alternative zur Verwendung der in früheren Versionen von Google Distributed Cloud enthaltenen Prometheus- und Grafana-Komponenten können Sie zu einer Open-Source-Community-Version von Prometheus und Grafana wechseln.
Bekanntes Problem
In Nutzerclustern werden Prometheus und Grafana während des Upgrades automatisch deaktiviert. Die Konfigurations- und Messwertdaten gehen jedoch nicht verloren.
Zur Umgehung dieses Problems öffnen Sie nach dem Upgrade monitoring-sample zum Bearbeiten. Setzen Sie enablePrometheus auf true.
Über Grafana-Dashboards auf Monitoring-Messwerte zugreifen
Grafana zeigt Messwerte aus Ihren Clustern an. Zur Anzeige dieser Messwerte müssen Sie auf die Dashboards von Grafana zugreifen:
Rufen Sie den Namen des im
kube-system-Namespace eines Nutzerclusters ausgeführten Grafana-Pods ab:kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] -n kube-system get pods
Dabei ist [USER_CLUSTER_KUBECONFIG] die kubeconfig-Datei des Nutzerclusters.
Der Grafana-Pod hat einen HTTP-Server, der den TCP-localhost-Port 3000 überwacht. Leiten Sie einen lokalen Port zu Port 3000 im Pod weiter, damit Sie sich die Dashboards von Grafana in einem Webbrowser ansehen können.
Nehmen wir an, der Name des Pods lautet
grafana-0. Um Port 50000 zu Port 3000 im Pod weiterzuleiten, geben Sie folgenden Befehl ein:kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] -n kube-system port-forward grafana-0 50000:3000
Gehen Sie in einem Webbrowser zu
http://localhost:50000.Geben Sie auf der Anmeldeseite
adminfür den Nutzernamen und das Passwort ein.Wenn die Anmeldung erfolgreich ist, werden Sie aufgefordert, das Passwort zu ändern. Nachdem Sie das Standardpasswort geändert haben, sollte das Grafana Home Dashboard des Nutzerclusters geladen werden.
Sie können auf andere Dashboards zugreifen, wenn Sie links oben auf der Seite auf das Drop-down-Menü Startseite klicken.
Ein Beispiel für die Verwendung von Grafana finden Sie unter Grafana-Dashboard erstellen.
Auf Benachrichtigungen zugreifen
Der Prometheus Alertmanager erfasst Benachrichtigungen vom Prometheus-Server. Sie können sich diese Benachrichtigungen in einem Grafana-Dashboard ansehen. Dazu müssen Sie auf das Dashboard zugreifen:
Der Container im Pod
alertmanager-0überwacht den TCP-Port 9093. Leiten Sie einen lokalen Port zu Port 9093 im Pod weiter:kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] port-forward \ -n kube-system alertmanager-0 50001:9093
Gehen Sie in einem Webbrowser zu
http://localhost:50001.
Prometheus Alertmanager-Konfiguration ändern
Sie können die Standardkonfiguration von Prometheus Alertmanager ändern, wenn Sie die Datei monitoring.yaml Ihres Nutzerclusters bearbeiten. Sie sollten dies tun, wenn Sie Benachrichtigungen an ein bestimmtes Ziel weiterleiten möchten, anstatt sie im Dashboard zu belassen. In der Prometheus-Dokumentation zur Konfiguration erfahren Sie, wie Sie Alertmanager konfigurieren.
So ändern Sie die Alertmanager-Konfiguration:
Kopieren Sie die Manifestdatei
monitoring.yamldes Nutzerclusters:kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] -n kube-system \ get monitoring monitoring-sample -o yaml > monitoring.yaml
Nehmen Sie Änderungen an den Feldern unter
spec.alertmanager.ymlvor, um den Alertmanager zu konfigurieren. Wenn Sie fertig sind, speichern Sie das geänderte Manifest.Wenden Sie das Manifest auf Ihren Cluster an:
kubectl apply --kubeconfig [USER_CLUSTER_KUBECONIFG] -f monitoring.yaml
Grafana-Dashboard erstellen
Sie haben eine Anwendung bereitgestellt, die einen Messwert bereitstellt, prüft, ob der Messwert verfügbar ist, und prüft, ob Prometheus den Messwert entfernt. Jetzt können Sie den Messwert auf Anwendungsebene einem benutzerdefinierten Grafana-Dashboard hinzufügen.
So erstellen Sie ein Grafana-Dashboard:
- Greifen Sie bei Bedarf auf Grafana zu.
- Klicken Sie im Dashboard auf der Startseite links oben auf das Drop-down-Menü auf Startseite.
- Klicken Sie im Menü auf der rechten Seite auf Neues Dashboard.
- Klicken Sie im Bereich New panel auf Graph. Ein leeres Grafik-Dashboard wird angezeigt.
- Klicken Sie auf Steuerfeldtitel und anschließend auf Bearbeiten. Im unteren Bereich Grafik wird der Tab Messwerte geöffnet.
- Wählen Sie im Drop-down-Menü der Datenquelle die Option Nutzer aus. Klicken Sie auf Abfrage hinzufügen und geben Sie
fooin das Feld Suche ein. - Klicken Sie rechts oben auf die Schaltfläche Zurück zum Dashboard. Ihr Dashboard wird angezeigt.
- Zum Speichern des Dashboards klicken Sie rechts oben auf Dashboard speichern. Wählen Sie einen Namen für das Dashboard aus und klicken Sie auf Speichern.
Prometheus und Grafana deaktivieren
Ab Version 1.16 werden Prometheus und Grafana nicht mehr über das Feld enablePrometheus im Objekt monitoring-sample gesteuert.
Weitere Informationen finden Sie unter Prometheus und Grafana verwenden.
Beispiel: Messwerte auf Anwendungsebene zu einem Grafana-Dashboard hinzufügen
In den folgenden Abschnitten erfahren Sie, wie Sie Messwerte für eine Anwendung hinzufügen. In diesem Abschnitt führen Sie die folgenden Aufgaben aus:
- Eine Beispielanwendung bereitstellen, die einen Messwert namens
fooenthält - Prüfen, ob Prometheus den Messwert verfügbar macht und extrahiert
- Benutzerdefiniertes Grafana-Dashboard erstellen
Beispielanwendung bereitstellen
Die Beispielanwendung wird in einem einzelnen Pod ausgeführt. Der Container des Pods weist den Messwert foo mit einem konstanten Wert von 40 auf.
Erstellen Sie das folgende Pod-Manifest pro-pod.yaml:
apiVersion: v1
kind: Pod
metadata:
name: prometheus-example
annotations:
prometheus.io/scrape: 'true'
prometheus.io/port: '8080'
prometheus.io/path: '/metrics'
spec:
containers:
- image: registry.k8s.io/prometheus-dummy-exporter:v0.1.0
name: prometheus-example
command:
- /bin/sh
- -c
- ./prometheus_dummy_exporter --metric-name=foo --metric-value=40 --port=8080
Wenden Sie dann das Pod-Manifest auf Ihren Nutzercluster an:
kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] apply -f pro-pod.yaml
Prüfen, ob der Messwert verfügbar ist und extrahiert wurde
Der Container im Pod
prometheus-exampleüberwacht den TCP-Port 8080. Leiten Sie einen lokalen Port zu Port 8080 im Pod weiter:kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] port-forward prometheus-example 50002:8080
Führen Sie den folgenden Befehl aus, um zu prüfen, ob die Anwendung den Messwert verfügbar macht:
curl localhost:50002/metrics | grep fooDer Befehl gibt die folgende Ausgabe zurück:
# HELP foo Custom metric # TYPE foo gauge foo 40
Der Container im Pod
prometheus-0überwacht den TCP-Port 9090. Leiten Sie einen lokalen Port zu Port 9090 im Pod weiter:kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] port-forward prometheus-0 50003:9090
Wenn Sie prüfen möchten, ob Prometheus den Messwert erfasst, rufen Sie http://localhost:50003/targets auf. Dadurch sollten Sie zum Pod
prometheus-0unter der Zielgruppeprometheus-io-podsgelangen.Rufen Sie zum Ansehen von Messwerten in Prometheus http://localhost:50003/graph auf. Geben Sie im Feld Suche
fooein und klicken Sie auf Ausführen. Auf der Seite sollte der Messwert angezeigt werden.
Benutzerdefinierte Stackdriver-Ressource konfigurieren
Wenn Sie einen Cluster erstellen, wird von Google Distributed Cloud eine benutzerdefinierte Stackdriver-Ressource automatisch erstellt. Sie können die Spezifikation in der benutzerdefinierten Ressource bearbeiten und die Standardwerte für CPU- und Arbeitsspeicheranforderungen sowie die Limits für eine Stackdriver-Komponente überschreiben. Die Standardspeichergröße und die Speicherklasse lassen sich separat überschreiben.
Standardwerte für Anfragen und Limits für CPU und Arbeitsspeicher überschreiben
So überschreiben Sie diese Standardeinstellungen:
Öffnen Sie die benutzerdefinierte Stackdriver-Ressource in einem Befehlszeileneditor:
kubectl --kubeconfig=KUBECONFIG -n kube-system edit stackdriver stackdriver
Dabei ist KUBECONFIG der Pfad der kubeconfig-Datei für den Cluster. Dies kann entweder ein Administratorcluster oder ein Nutzercluster sein.
Fügen Sie in der benutzerdefinierten Stackdriver-Ressource das Feld
resourceAttrOverrideim Abschnittspechinzu:resourceAttrOverride: POD_NAME_WITHOUT_RANDOM_SUFFIX/CONTAINER_NAME: LIMITS_OR_REQUESTS: RESOURCE: RESOURCE_QUANTITYBeachten Sie, dass das Feld
resourceAttrOverridealle vorhandenen Standardlimits und -anfragen für die angegebene Komponente überschreibt. Die folgenden Komponenten werden vonresourceAttrOverrideunterstützt:- gke-metrics-agent/gke-metrics-agent
- stackdriver-log-forwarder/stackdriver-log-forwarder
- stackdriver-metadata-agent-cluster-level/metadata-agent
- node-exporter/node-exporter
- kube-state-metrics/kube-state-metrics
Eine Beispieldatei sieht so aus:
apiVersion: addons.gke.io/v1alpha1
kind: Stackdriver
metadata:
name: stackdriver
namespace: kube-system
spec:
projectID: my-project
clusterName: my-cluster
clusterLocation: us-west-1a
resourceAttrOverride:
gke-metrics-agent/gke-metrics-agent:
requests:
cpu: 110m
memory: 240Mi
limits:
cpu: 200m
memory: 4.5GiSpeichern Sie die Änderungen und beenden Sie den Befehlszeileneditor.
Prüfen Sie den Status der Pods:
kubectl --kubeconfig=KUBECONFIG -n kube-system get pods | grep gke-metrics-agent
Ein fehlerfreier Pod sieht beispielsweise so aus:
gke-metrics-agent-4th8r 1/1 Running 0 5d19h
Sehen Sie in der Pod-Spezifikation der Komponente nach, ob die Ressourcen richtig festgelegt sind.
kubectl --kubeconfig=KUBECONFIG -n kube-system describe pod POD_NAME
Dabei ist
POD_NAMEder Name des Pods, den Sie gerade geändert haben. z. B.stackdriver-prometheus-k8s-0.Die Antwort sieht in etwa so aus:
Name: gke-metrics-agent-4th8r Namespace: kube-system ... Containers: gke-metrics-agent: Limits: cpu: 200m memory: 4.5Gi Requests: cpu: 110m memory: 240Mi ...
Standardeinstellungen für die Speichergröße überschreiben
So überschreiben Sie diese Standardeinstellungen:
Öffnen Sie die benutzerdefinierte Stackdriver-Ressource in einem Befehlszeileneditor:
kubectl --kubeconfig=KUBECONFIG -n kube-system edit stackdriver stackdriver
Fügen Sie das Feld
storageSizeOverrideim Abschnittspechinzu. Sie können die Komponentestackdriver-prometheus-k8soderstackdriver-prometheus-appverwenden. Der Abschnitt hat dieses Format:storageSizeOverride: STATEFULSET_NAME: SIZE
In diesem Beispiel werden das StatefulSet
stackdriver-prometheus-k8sund die Größe120Giverwendet.apiVersion: addons.gke.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: projectID: my-project clusterName: my-cluster clusterLocation: us-west-1a storageSizeOverride: stackdriver-prometheus-k8s: 120GiSpeichern Sie und beenden Sie den Befehlszeileneditor.
Prüfen Sie den Status der Pods:
kubectl --kubeconfig=KUBECONFIG -n kube-system get pods | grep stackdriver
stackdriver-prometheus-k8s-0 2/2 Running 0 5d19h
Prüfen Sie die Pod-Spezifikation der Komponente, um zu gewährleisten, dass die Speichergröße korrekt überschrieben wird.
kubectl --kubeconfig=KUBECONFIG -n kube-system describe statefulset STATEFULSET_NAME
Die Antwort sieht in etwa so aus:
Volume Claims: Name: my-statefulset-persistent-volume-claim StorageClass: my-storage-class Labels: Annotations: Capacity: 120Gi Access Modes: [ReadWriteOnce]
Standardeinstellungen für Speicherklasse überschreiben
Voraussetzung
Sie müssen zuerst die StorageClass erstellen, die Sie verwenden möchten.
So überschreiben Sie die Standardspeicherklasse für nichtflüchtige Volumes, die von Logging- und Monitoring-Komponenten angefordert werden:
Öffnen Sie die benutzerdefinierte Stackdriver-Ressource in einem Befehlszeileneditor:
kubectl --kubeconfig=KUBECONFIG -n kube-system edit stackdriver stackdriver
Dabei ist KUBECONFIG der Pfad der kubeconfig-Datei für den Cluster. Dies kann entweder ein Administratorcluster oder ein Nutzercluster sein.
Fügen Sie das Feld
storageClassNameim Abschnittspechinzu:storageClassName: STORAGECLASS_NAME
Das Feld
storageClassNameüberschreibt die vorhandene Standardspeicherklasse und gilt für alle Logging- und Monitoring-Komponenten mit angeforderten nichtflüchtigen Volumes. Eine Beispieldatei sieht so aus:apiVersion: addons.gke.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: projectID: my-project clusterName: my-cluster clusterLocation: us-west-1a proxyConfigSecretName: my-secret-name enableVPC:
optimizedMetrics: true storageClassName: my-storage-class Speichern Sie die Änderungen.
Prüfen Sie den Status der Pods:
kubectl --kubeconfig=KUBECONFIG -n kube-system get pods | grep stackdriver
Ein fehlerfreier Pod sieht beispielsweise so aus:
stackdriver-prometheus-k8s-0 1/1 Running 0 5d19h
Prüfen Sie in der Pod-Spezifikation einer Komponente, ob die Speicherklasse korrekt eingerichtet ist.
kubectl --kubeconfig=KUBECONFIG -n kube-system describe statefulset STATEFULSET_NAME
Unter Verwendung des zustandsorientierten Sets
stackdriver-prometheus-k8ssieht die Antwort beispielsweise so aus:Volume Claims: Name: stackdriver-prometheus-data StorageClass: my-storage-class Labels: Annotations: Capacity: 120Gi Access Modes: [ReadWriteOnce]
Optimierte Messwerte deaktivieren
Standardmäßig erfassen die im Cluster ausgeführten Messwert-Agents einen optimierten Satz von Container-, Kubelet- und Kube State Metrics-Messwerten und melden ihn an Stackdriver. Wenn Sie zusätzliche Messwerte benötigen, empfehlen wir Ihnen, einen Ersatz aus der Liste der Messwerte für Google Distributed Cloud zu suchen.
Hier sind einige Beispiele für Ersetzungen, die Sie verwenden können:
| Deaktivierter Messwert | Ersatz |
|---|---|
kube_pod_start_time |
container/uptime |
kube_pod_container_resource_requests |
container/cpu/request_cores container/memory/request_bytes |
kube_pod_container_resource_limits |
container/cpu/limit_cores container/memory/limit_bytes |
So deaktivieren Sie die Standardeinstellung für optimierte Kube-State-Metrics-Messwerte (nicht empfohlen):
Öffnen Sie die benutzerdefinierte Stackdriver-Ressource in einem Befehlszeileneditor:
kubectl --kubeconfig=KUBECONFIG -n kube-system edit stackdriver stackdriver
Dabei ist KUBECONFIG der Pfad der kubeconfig-Datei für den Cluster. Dies kann entweder ein Administratorcluster oder ein Nutzercluster sein.
Setzen Sie das Feld
optimizedMetricsauffalse:apiVersion: addons.gke.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: projectID: my-project clusterName: my-cluster clusterLocation: us-west-1a proxyConfigSecretName: my-secret-name enableVPC:
optimizedMetrics: false storageClassName: my-storage-class Speichern Sie die Änderungen und beenden Sie den Befehlszeileneditor.
Bekanntes Problem: Cloud Monitoring-Fehlerbedingung
(Problem-ID 159761921)
Unter bestimmten Umständen kann der standardmäßige Cloud Monitoring-Pod, der standardmäßig in jedem neuen Cluster bereitgestellt wird, nicht mehr reagieren.
Wenn Cluster aktualisiert werden, können beispielsweise Speicherdaten beschädigt werden, wenn Pods in statefulset/prometheus-stackdriver-k8s neu gestartet werden.
Insbesondere der Monitoring-Pod stackdriver-prometheus-k8s-0 kann in eine Schleife geraten, wenn beschädigte Daten das Schreiben von prometheus-stackdriver-sidecar in den Cluster-Speicher PersistentVolume verhindern.
Sie können den Fehler manuell diagnostizieren und wiederherstellen, indem Sie die folgenden Schritte ausführen.
Cloud Monitoring-Fehler diagnostizieren
Wenn der Monitoring-Pod fehlgeschlagen ist, geben die Logs Folgendes aus:
{"log":"level=warn ts=2020-04-08T22:15:44.557Z caller=queue_manager.go:534 component=queue_manager msg=\"Unrecoverable error sending samples to remote storage\" err=\"rpc error: code = InvalidArgument desc = One or more TimeSeries could not be written: One or more points were written more frequently than the maximum sampling period configured for the metric.: timeSeries[0-114]; Unknown metric: kubernetes.io/anthos/scheduler_pending_pods: timeSeries[196-198]\"\n","stream":"stderr","time":"2020-04-08T22:15:44.558246866Z"}
{"log":"level=info ts=2020-04-08T22:15:44.656Z caller=queue_manager.go:229 component=queue_manager msg=\"Remote storage stopped.\"\n","stream":"stderr","time":"2020-04-08T22:15:44.656798666Z"}
{"log":"level=error ts=2020-04-08T22:15:44.663Z caller=main.go:603 err=\"corruption after 29032448 bytes: unexpected non-zero byte in padded page\"\n","stream":"stderr","time":"2020-04-08T22:15:44.663707748Z"}
{"log":"level=info ts=2020-04-08T22:15:44.663Z caller=main.go:605 msg=\"See you next time!\"\n","stream":"stderr","time":"2020-04-08T22:15:44.664000941Z"}
Wiederherstellung nach dem Cloud Monitoring-Fehler
So stellen Sie Cloud Monitoring manuell wieder her:
Beenden Sie das Clustermonitoring. Den Operator
stackdriverherunterskalieren, um den Monitoring-Abgleich zu verhindern:kubectl --kubeconfig /ADMIN_CLUSTER_KUBCONFIG --namespace kube-system scale deployment stackdriver-operator --replicas 0
Löschen Sie die Arbeitslasten der Monitoring-Pipeline:
kubectl --kubeconfig /ADMIN_CLUSTER_KUBCONFIG --namespace kube-system delete statefulset stackdriver-prometheus-k8s
Löschen Sie die PersistentVolumeClaims (PVCs) der Monitoring-Pipeline:
kubectl --kubeconfig /ADMIN_CLUSTER_KUBCONFIG --namespace kube-system delete pvc -l app=stackdriver-prometheus-k8s
Starten Sie das Clustermonitoring neu. Skalieren Sie den Stackdriver-Operator hoch, um eine neue Monitoring-Pipeline zu installieren und den Abgleich fortzusetzen:
kubectl --kubeconfig /ADMIN_CLUSTER_KUBCONFIG --namespace kube-system scale deployment stackdriver-operator --replicas=1